Alpha GO核心原理
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
1.1 Alpha GO简述
Alpha GO诞生于后来被Google收购的DeepMind公司,是历史上第一个打败人类围棋世界冠军的AI程序。在此之前,人们普遍认为类似围棋这类凝聚了“人类智慧结晶”的领域对于人工智能来讲是不可突破的,因而Alpha GO的出现可以说是意义非凡。
当然,Alpha GO从诞生到最终打败围棋世界冠军也并非是“一蹴而就”的。它幕后的核心作者主要有如下几位:
l Demis Hassabis
Demis既是DeepMind公司的创始人,同时也被人们称为“Alpha GO之父”。他在13岁时曾经获得过国际象棋大师的称号,而围棋则是其在大学时才开始研究的。Demis较早的时候就发现了人工智能一些瓶颈,于是选择神经科学做为博士攻读方向,以期从针对“人类”的研究中获得突破
l David Silver
David博士毕业于加拿大ALBERTA大学,是DeepMind公司的资深研究员。而且Alpha GO发表于Nature上的论文《Mastering the game of GO with deep neural networks and tree search》中,David是第一作者,可见其在Alpha GO的发展过程中起到了非常关键的作用
l Aja Huang
Aja Huang的中文名为“黄士杰”,他是一位台湾人。根据公开资料显示,Aja接触围棋的时间较早,其博士论文《New Heuristics for Monte Carlo Tree Search Applied to the Game of GO》也是研究的这一领域。2012年Aja加入DeepMind并担任高级研究员,彼时Alpha GO项目事实上只有他唯一一个开发工程师(David是项目经理,而Demis是公司老板)。所以后来我们看到Nature上发表的论文中,Aja和David并列第一作者;Alpha GO的几次与人类的世纪大战,也皆是他作为“人肉臂”来完成的比赛,因而他在Alpha GO的发展过程中的重要作用可见一斑

图 ‑ 发表于Nature上的《Mastering the Game of Go with Deep Neural Networks and
Tree Search》论文的作者列表(星号代表两位作者的贡献是一样的)
Alpha GO的主要战绩如下:
2015年10月,以5:0战胜欧洲冠军樊麾(这一消息在2016年才对外公布,在此之前樊麾曾担任Alpha GO的教练)。
2016年3月,以4:1击败李世乭
2016年12月开始,化名“Master”在围棋网络平台横扫各路围棋高手,取得60连胜
2017年5月,在中国乌镇对局世界排名第一的柯洁,并获得3:0全胜战绩
2017年5月,在与柯洁对弈结束后,DeepMind宣布Alpha GO不再参加围棋比赛
2017年10月,Nature杂志上发表了AlphaGO的最新进展——在无需人类输入的条件下,“无师自通”并以100:0击败它的前一个版本
从Alpha GO的如上对战史中,我们可以大概看出它的几个关键阶段:
l 阶段1:AlphaGO早期版本(击败了李世乭)
l 阶段2:AlphaGO Master(击败了柯洁)
l 阶段3:AlphaGO Zero(无师自通击败了它的前辈)
为了让大家可以更好地理解隐藏在Alpha GO背后的技术实现,我们接下来将分为几个小节来做一些更为详细的解析。
1.2 Alpha GO核心原理
我们以Alpha GO早期参与人机大战的版本做为它的阶段1产品。值得一提的是,在此之前Alpha GO在内部已经断断续续地经历了很多次改进,有兴趣的读者可以自行搜索相关资料了解详情。
简单而言,Alpha GO是由如下几个核心部件组成的:
l Policy Network
即价值网络,用于根据当前局面来预测下一步的走棋
l Value Network
即估值网络,用于根据当前局面来预测胜率
l Monte Carlo Tree Search
即蒙特卡洛树搜索,它是Policy Network和Value Network的基础
l Fast Rollout
即快速走子网络,其功能和Policy Network类似,区别在于后者可以在损失一定精度的情况下达到1000倍以上的计算效率提升
在讲解AlphaGO的内部原理之前,读者可以先自己思考一下——如果你是AlphaGO的设计师,那么你能想到的实现方案是什么?
方案1:首先可能想到的是传统的监督学习方案。围棋已经经历了数千年的历史沉淀,不仅名师荟萃,而且我们也可以相对容易地找到各种前人总结的棋谱、著作、围棋比赛对战记录等等,这些无疑都可以作为监督学习的训练数据。
事实上,AlphaGO的更早期版本的确考虑过这种方案。但是据此做出来的围棋程序达到一定水平后就再也上不去了,和人类高手相比还是有很大差距。这其中的原因包括但不限于:
l 围棋的状态空间太过巨大
这既是围棋的难点所在,同时也是它能够吸引人类数千年不间断的开展研究,仍能保持长盛不衰的原因之一。围棋近乎浩瀚的状态空间(250150),使得即便是数千万的人工训练数据也显得“杯水车薪”
l 人类的训练数据存在“思维定式”
这就像我们人类接受围棋培训一下,老师总是会反复你和强调“这里应该这样走子是最好的,这里不应该这样子选择”。遵循人类几千年来总结的围棋经验确实可以让选手少走一些弯路,但同时也扼杀了各种看似凶险,实则有可能“出奇制胜”的“妙招”。在这种情况下,“依葫芦画瓢”的围棋程序能画出个像样的“瓢”就不错了,当然不能指望它能“青出于蓝而胜于蓝”了
那么还有没有其它的解决方案呢?
方案2:既然人工数据可能存在思维定式,那么我们是否可以结合深度强化学习来让围棋程序自学成材呢?
理论上是可行的。因为像围棋这类游戏虽然很难,但相对来讲还是有套路可寻,因而很适合“穷举”的办法——而且计算机不就最擅长做这个事情嘛。
但是“现实总是骨感”的,拦路虎依然是围棋中惊人的状态空间。换句话说,只要状态空间在可承受的范围内,那么类似的游戏事实上是可以找出必胜方案的。举个例子来说,五子棋就已经被证明“先下的人”有必胜的方法了。
既然“穷举”这种最直接的办法行不通,那么有没有可能我们在牺牲一定条件的情况下,帮助程序做些有目的性的“穷举”呢?答案是肯定的,而且这也是AlphaGO的核心原理——前面我们讨论到的Policy Network、Value Network等等核心组件,实际上都是在为这个原理服务。
有意思的是,AlphaGO的这个做法和人类职业棋手的下棋过程是非常相似的。首先,当棋手们看到围棋盘面时,他们会很快地在脑海中得出有哪些区域/走子是需要重点考虑的,而还有哪些区域是基本可以摒弃的——这就是人类通过以往的学习经验得出的“棋感”。当然,这种“第六感”不是围棋特有的。打个比方来说,当我们阅读了大量的英语学习材料和习题后,那么也可能会培养出所谓的“语感”。对于AlphaGO而言,它的“棋感”是由Policy Network体现出来的。因而有些专业人士点评AlphaGO下棋的风格有点像人类,倒是不无道理的(虽然AlphaGO事实上并不“懂”围棋)。
其次,当棋手们确定了大致思考范围后,他们还会做具体的“推演”——也就是我们常说的可以提前想到“N步”以后的棋。对于顶尖的棋手来说,这个N值有可能达到30步以上。和很多其它棋类程序类似,AlphaGO也基于MCTS来完成类似于人的“推演”动作。而且理论上计算机的优势在于它可以一直计算(如果时间允许的话)到一盘棋的结束(赢或者输),从而得到更全面的估算。
AlphaGO的整体框架如下图所示:
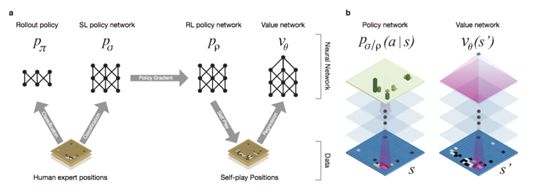
图 ‑ AlphaGO的核心实现框架
引用自《Mastering the Game of Go with Deep Neural Networks and Tree Search》
注:如无特别说明,本小节后面的引用均来自于这篇论文
接下来我们针对AlphaGO中的各个核心组件做逐一解释。
1.3 Policy Network
通过前面的讲解,大家知道了Policy Network在AlphaGO中起到了“棋感”的作用。具体来说,AlphaGO会给出当前棋盘中可选的落子位置的“赢率”。那么这样的策略网络是如何训练出来的呢?主要有3个步骤:
Step1@Policy Network的训练,利用Supervised Learning来完成。Policy Network采用的是13层的卷积神经网络,并通过最后的softmax层来输出棋盘所有空位的概率值。另外,这个CNN的输入值代表了棋盘状态的如下信息:
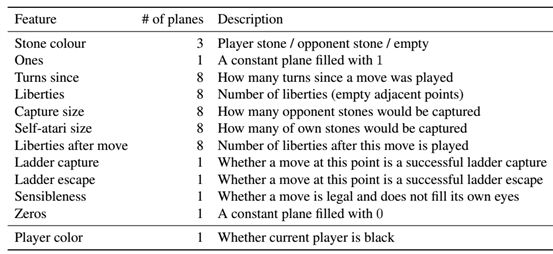
图 ‑ Policy Network的输入特征
这一阶段的训练采用的是有监督学习,数据源来自于KGS围棋平台上职业棋手的3000万步走棋。这样产生的网络用于预测人类高手的下棋手法,可以达到57%的准确率(当时其它围棋程序最高只能达到44.4%)。如下图表格所示:
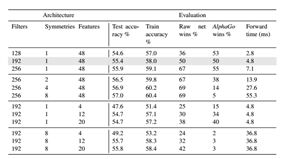
图 ‑ 经过监督学习的PolicyNetwork训练结果
Step2@Policy Network的训练,利用Reinforcement Learning来完成。虽然经过人类职业棋手数据“洗礼”后的Policy Network已经具备一定的能力,但它与真正的高手相比还有非常大的差距。3000万步的走棋对于监督学习来说仍然是不够的,此时我们需要其它手段来进一步提升AlphaGO的水平,这就是增强学习。
RL Policy Network的网络结构和前面的SL Policy Network是一样的,而且初始值也直接采用了后者训练后的终值。在增强学习训练过程中,我们让两个策略网络进行“左右互搏”——这样一来就不再需要人类数据的输入了。另外,AlphaGO采用的是policy gradient reinforcement learning来进行目标优化。关于策略梯度优化的更多细节,大家可以参考本书的其它章节。
经过强化学习后的RL Policy Network,在对抗SL Policy Network时可以取得80%的胜率。在与其它围棋程序的对比测试中,它也有不错的表现(例如85%的概率赢得另一个有名的围棋程序Pachi)。
由于Policy Network走棋耗时较长(3ms),AlphaGO又利用局部特征和线性softmax模型训练出了一个辅助网络,称之为“Rollout Policy Network”。它的作用就是在牺牲一定精度的情况下实现快速走棋(2 µs)。
1.4 Value Network
虽然强化学习产生的RL Policy Network已经可以对抗其它的围棋程序,但在面对人类顶尖高手时还是不够的。所以可以毫不夸张地说Value Network是让AlphaGO走向巅峰的关键。通俗来讲,它的作用就是让程序有能力快速评估当前局面的“赢率”。在围棋比赛中有的棋手会在中途选择“弃子投降”,这多半就是他们已经预估到赢的希望很渺茫了。不过即便是人类,对于棋面的赢率判断也是非常有限的——通常需要比赛进行到靠后阶段才能较准确地判断出来。而AlphaGO所要做的则是对于每种状态都有尽可能准确的赢率判断,这显然是非常困难的。
Value Network和Policy Network的大部分网络结构是一致的,只不过输出层不是概率分布,而是一个预测值标量。在训练数据的选取上,AlphaGO曾尝试从人类对弈产生的完整棋局中进行抽取,但由于它们的相关性太强所以很容易导致过拟合的现象。因而AlphaGO的作法是从self-play产生的3000万盘棋中提取出(棋面,收益)组合用于训练,如此一来才克服了上述的问题。
1.5 MCTS
现在我们已经训练出了非常强大的Policy Network和Value Network了,但是怎么把它们结合起来应用于比赛中呢?这就是MCTS所起的作用了。MCTS并不是AlphaGO的“专利”,事实上在它之前已经有很多围棋智能程序的设计都采用了这个方法。
MCTS主要包含Selection、Expansion、Evaluation和Backup四个阶段,读者可以结合本书的其它章节来做深入学习。这里我们需要重点了解的是它是如何与两个Network联系起来的。关于这个问题,《Mastering the Game of Go with Deep Neural Networks and Tree Search》论文在开篇就言简意赅地提出了(不得不说Nature上的很多文章都是“惜字如金”,“一语中的”):
“The game of Go has long been viewed as the most challenging of classic games for artificial intelligence due to its enormous search space and the difficulty of evaluating board positions and moves…”
紧接着它给出了AlphaGO所采用的解决方案,其中针对Value Network的描述是:
“First, the depth of the search may be reduced by position evaluation: truncating the search tree at state s and replacing the subtree below s by an approximate value function v(s) ≈ v∗(s) that predicts the outcome from state s”
同时还有对Policy Network对于降低搜索空间广度的描述:
“Second, the breadth of the search may be reduced by sampling actions from a policy p(ajs) that is a probability distribution over possible moves a in position s”
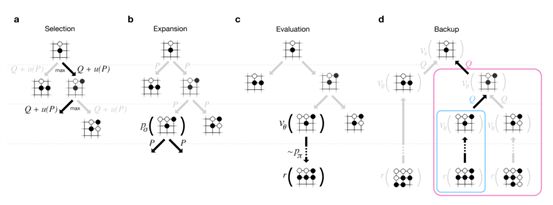
图 ‑ MCTS在AlphaGO中的应用
所以答案已经比较清楚了——MCTS在做树搜索的过程中综合考虑了Policy Network,从而有效降低了搜索面,而后它利用fast rollout network来针对各个候选位置进行快速推演。在后者的执行过程中,它还借助于value network来提前得到预计的终值,这样一来也就避免了过深的网络搜索。最后经过多轮的模拟和值更新后,Alpha GO才会选择出下一步的最佳走棋位置。