深度学习笔记(三)
几个经典的网络架构:
1.Alexnet
Alexnet是2012年在比赛中夺冠的一个网络。  它有几个缺点:(1)11x11的filter,大刀阔斧的提取特征,这样是不好的,卷积核一般是越小越好
它有几个缺点:(1)11x11的filter,大刀阔斧的提取特征,这样是不好的,卷积核一般是越小越好
(2)步长为4,过大;
(3)没有加pad填充。
Alexnet是一个8层的网络,有5层的卷积和3层的全连接。
2.Vgg
Vgg是一个2014年出现的网络,它有不同的几个版本,下图中红色框起来的是比较主流的一个版本。它所有的卷积核大小都是3x3的,都是细粒度的进行特征提取,且它的层数有16层或者19层。Vgg还有个特点,当池化的时候会损失一些信息,它会通过特征图的个数翻倍的形式来进行弥补。它的缺点是网络训练的时间较长,假如Alexnet网络的训练时间是8小时,则Vgg网络的训练时间要长达3天。
但是有个问题,Vgg为什么只用到16层,为什么不用17层、20层?因为在实验过程中发现一个问题,所谓的深度学习,从本质上理解,应该是越深越好,但事实上却不是如此。随着卷积层的增加,不一定所有的卷积层做的效果都好,因为它是在之前提取的特征基础上再去提取特征,并不一定能够百分百保证提取的特征比之前的好。这个问题的出现也就给我们带来了Resnet残差网络。
3.Resnet残差网络(Residual Network)
深层网络遇到的问题就是,当网络层数越高的时候,无论在训练集还是在测试集上的错误率都比层数更少的网络要高。当在20层的基础上再加36层时,肯定会有提取特征不好的,会拉高整个网络的错误率。需要达到的效果就是,既要把网络层数堆叠起来,还不能让那些效果比较差的层影响网络的作用。
解决办法:对网络层进行选择,保留能够促进网络效果的层,舍弃对网络起抑制作用的层,但并不是直接不要那些效果不好的层。2015年,Resnet网络的作者提出了同等映射,也就是加进来的那些层,即使它效果不好,那么把它的权重参数设为0,让它为0就行。
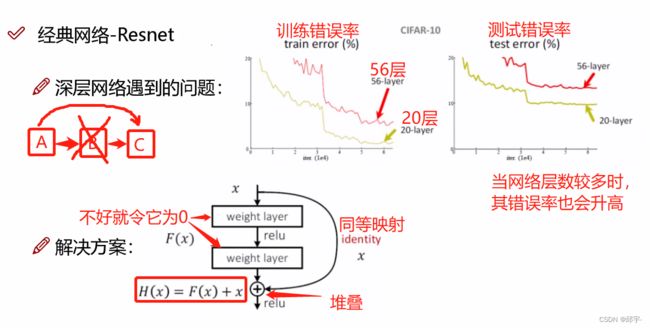 假如有A、B、C三个层,如果B的效果不好,让它为0的话,那么A和C就断开了,但是如果将A同等映射到C,则B的有无并不会影响整个网络。
假如有A、B、C三个层,如果B的效果不好,让它为0的话,那么A和C就断开了,但是如果将A同等映射到C,则B的有无并不会影响整个网络。
 传统网络层数越高,错误率越高;Resnet网络层数高,错误率反而较低.
传统网络层数越高,错误率越高;Resnet网络层数高,错误率反而较低.
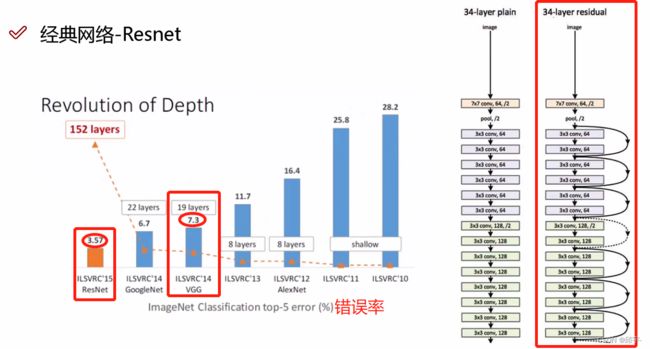 与VGG相比,VGG的错误率是7.3,而Resnet的错误率降到了3.57。
与VGG相比,VGG的错误率是7.3,而Resnet的错误率降到了3.57。
 建议将Resnet网络理解为特征提取,不建议将它当成一个分类网络。因为它是分类还是回归,决定于损失函数和层的连接方式。它能够应用到各种各样的框架当中,物体检测、物体追踪、分类、检索,相当于是通用的一个网络结构,最高能到101层。
建议将Resnet网络理解为特征提取,不建议将它当成一个分类网络。因为它是分类还是回归,决定于损失函数和层的连接方式。它能够应用到各种各样的框架当中,物体检测、物体追踪、分类、检索,相当于是通用的一个网络结构,最高能到101层。
4.感受野
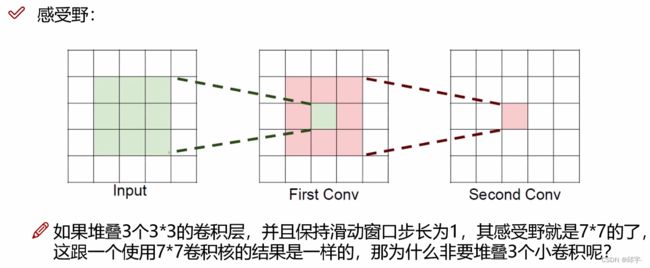
假如输入大小是5x5,经过3x3的filter,步长为1的卷积后得到一个3x3的特征图,然后再用3x3的filter二次卷积得到1x1的特征,那么其感受野就是5x5。
一般情况下,希望感受野越大越好。

5.RNN递归神经网络(Recurrent Neural Network)
如果有一组时序的数据,t1、t2、t3、t4......tn时刻,它们之间有时间的相关性,相当于在数据集中加入了一个时间序列,但是网络训练过程中是不考虑时间关系的。
RNN网络的基本出发点就是前一个时刻训练出来的中间特征也会对后一个时刻产生影响,数据之间在时序上呈现一个相关性,那么在特征上也会呈现一个相关性。
 如图所示,在中间的隐层,当t1时刻的数据传入后,经过隐层会产生一个输出,同时又会将t1时刻数据产生的中间特征再和t2时刻的数据一同输入到隐层,再产生一个输出和一个中间特征,继续再和t3时刻的数据一同输入隐层......如此往复循环。
如图所示,在中间的隐层,当t1时刻的数据传入后,经过隐层会产生一个输出,同时又会将t1时刻数据产生的中间特征再和t2时刻的数据一同输入到隐层,再产生一个输出和一个中间特征,继续再和t3时刻的数据一同输入隐层......如此往复循环。
CNN主要用于计算机视觉CV中,RNN主要用在自然语言处理NLP中。
当我们用RNN网络时,一般情况下只选择最后层的输出结果,因为它包含了前面所有时刻的中间特征。
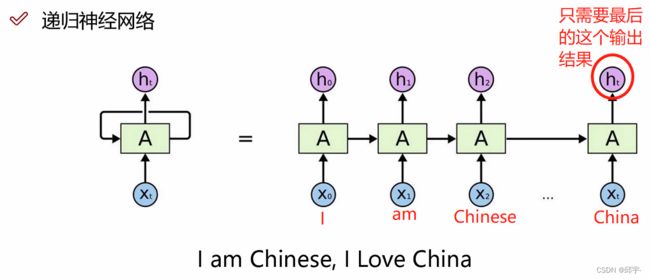 WordVector:先把输入数据转换成对应的一个特征向量,并且按照时间顺序从前到后进行排列。
WordVector:先把输入数据转换成对应的一个特征向量,并且按照时间顺序从前到后进行排列。
RNN网络的一个弊端:如果一个序列从t1、t2、t3......t10000,有10000个时间序列数据,那么最后一个结果会把前面所有的中间特征都考虑进来,然而前面的中间结果并不一定都是重要的,一旦数据量过大,得到的结果就不够准确。
6.LSTM网络
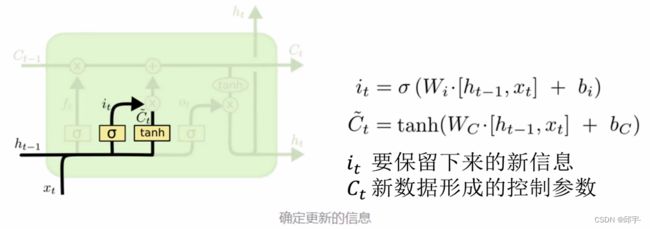
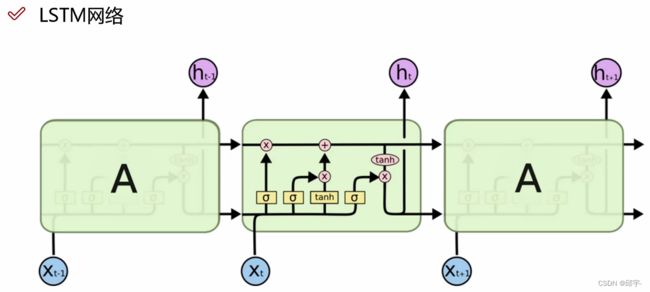
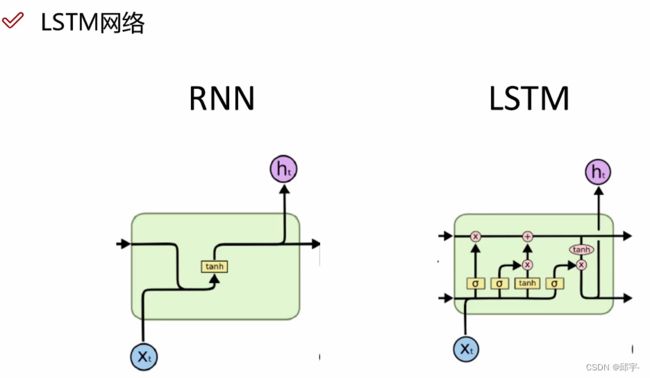 在LSTM网络中,能够忘记掉一些中间特征。LSTM是在RNN基础上进行改进的,加上了一个c控制参数和一个门控制单元,可以降低模型的复杂度。
在LSTM网络中,能够忘记掉一些中间特征。LSTM是在RNN基础上进行改进的,加上了一个c控制参数和一个门控制单元,可以降低模型的复杂度。




自然语言处理-词向量模型-Word2Vec
1.词向量模型通俗解释
先来考虑一个问题:如何能将文本向量化?要注意两点:第一点,顺序必须正确,出现的位置不同;第二,相近的词应该表示相同的含义,比如自然语言处理和NLP是同一个意思。
当我们描述一个人时,要综合身高、体重、年龄、性别、爱好等等各项指标。在自然语言处理中也是一样的,一个词向量的维度都是较高的,基本上在50维~300维之间,想让计算快一点,50维也足够,想让计算更精确一点,则可考虑使用300维的。

只要有了这个向量,向量和向量之间就可以做相似度的计算,余弦距离、欧氏距离都可以。

可以用相似度来判断哪些词之间是相近的,哪些词是相反的。前提是需要把所有的词向量都构建好 。
通常,数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖。

如图所示是一个50维的词向量,我们只需要将向量训练出来,知道它在空间当中是有意义的就可以,剩下的怎么评估、怎么去衡量、怎么去认识它都交给计算机就足够了。

假设现在已经拿到了一份训练好的词向量,其中每个词都表示为50维的向量:

如果在热度图中显示,结果如下:

在结果中可以发现,相似的词在特征表达中比较相似,也就是说明词的特征是有实际意义的!

2.词向量模型中的输入和输出

输入第一个词和第二个词,输出第三个词。假如有100个词组成的语料库,看哪个词的可能性是最高的,其实就是一个分类任务。
 但是单纯的一个词是不能输入到神经网络中的。
但是单纯的一个词是不能输入到神经网络中的。
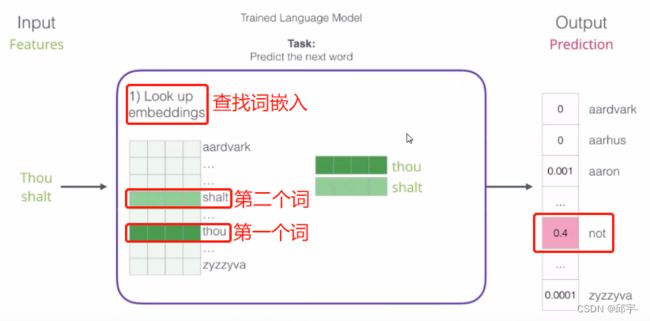 在一个词库表中,每个词被表示成一个四维向量。现在输入一个词,需要到词库表中查找它对应的一个词向量。词库表开始时是随机初始化的,比如所有文本中一共包含1000个词,现在把这1000个词列出来,然后跟神经网络权重参数的初始化一样,随机构造一些初始值,这样每个词就得到一个随机初始化的向量。神经网络中,前向传播计算loss函数,反向传播通过loss函数来更新权重参数。在词向量中,不光会更新整个神经网络模型的参数矩阵,连同输入也会一起进行更新,相当于一开始的词库表是随机进行初始化的,随着训练的进行,每一次都会把训练的数据(即输入的词向量)再进行更新。在这个过程中,神经网络能够学习到怎么样的词向量表达,计算机能够把它的下一个词猜得更准确。
在一个词库表中,每个词被表示成一个四维向量。现在输入一个词,需要到词库表中查找它对应的一个词向量。词库表开始时是随机初始化的,比如所有文本中一共包含1000个词,现在把这1000个词列出来,然后跟神经网络权重参数的初始化一样,随机构造一些初始值,这样每个词就得到一个随机初始化的向量。神经网络中,前向传播计算loss函数,反向传播通过loss函数来更新权重参数。在词向量中,不光会更新整个神经网络模型的参数矩阵,连同输入也会一起进行更新,相当于一开始的词库表是随机进行初始化的,随着训练的进行,每一次都会把训练的数据(即输入的词向量)再进行更新。在这个过程中,神经网络能够学习到怎么样的词向量表达,计算机能够把它的下一个词猜得更准确。
3.构建训练数据
训练数据不用局限于我们手里的文本,一切可利用的文本,只要是正常逻辑的都可以当作训练数据。
构建训练数据:

在文本数据中也是一样的,对于一个长篇的数据集,自己指定滑动窗口和每次平移几个单位。然后把每次训练的数据组合在一起,就得到了我们的训练数据。
4.不同模型对比
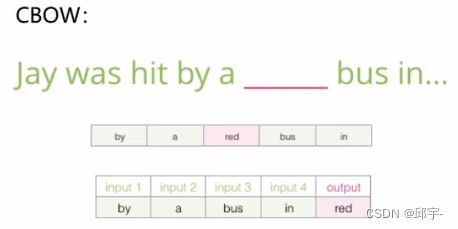
(1)CBOW
输入是上下文,输出是中间的一个词。构建一组数据。
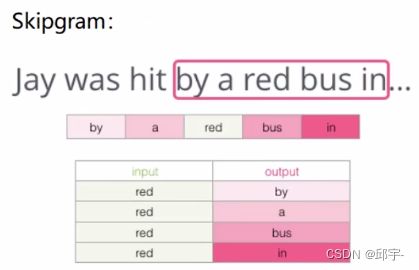
(2)Skipgram
输入是中间的一个词,输出是上下文。构建四组数据。
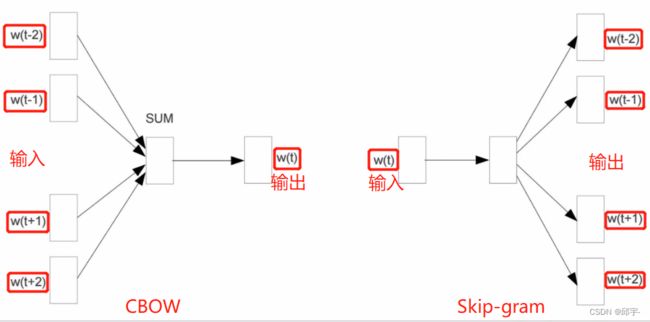 训练过程:Skip-gram模型所需训练数据集
训练过程:Skip-gram模型所需训练数据集
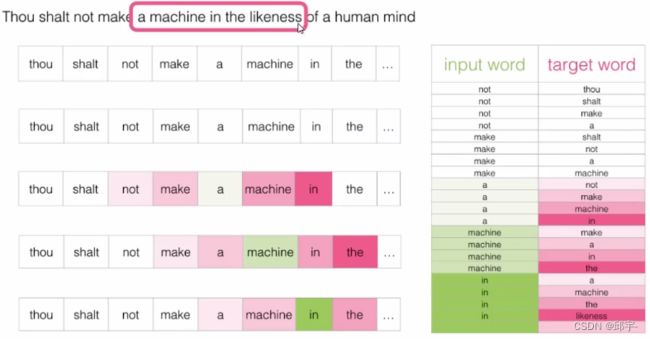
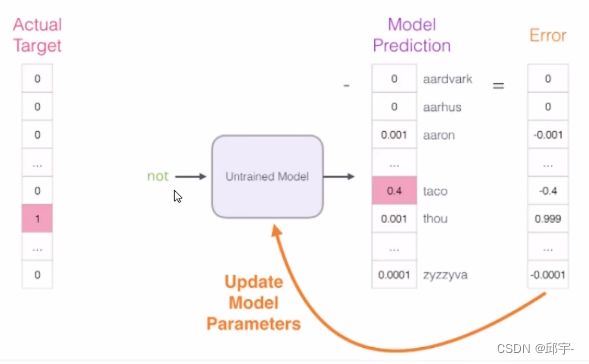
通过前向传播得到loss function,loss function中计算error值。然后通过error值来看反向传播该怎么走,权重参数该怎么更新。
如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,解决办法:
初始方案:输入两个单词,看他们是不是前后对应的输入和输出,也就相当于一个二分类任务。
 首先,输入一个词A,然后预测可能是它上下文的词B;然后再将预测出来的词B与词A一同输入神经网络中,判断B是A后面的词的可能性有多大。
首先,输入一个词A,然后预测可能是它上下文的词B;然后再将预测出来的词B与词A一同输入神经网络中,判断B是A后面的词的可能性有多大。
出发点非常好,但是此时训练集构建出来的标签全是1,无法进行较好的训练。

5.负采样方案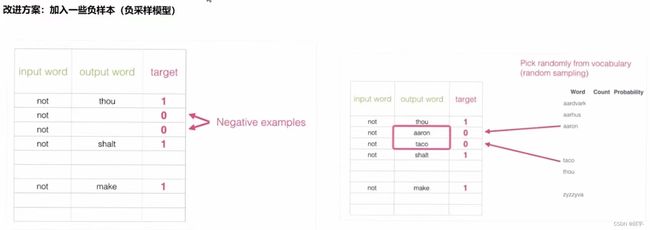
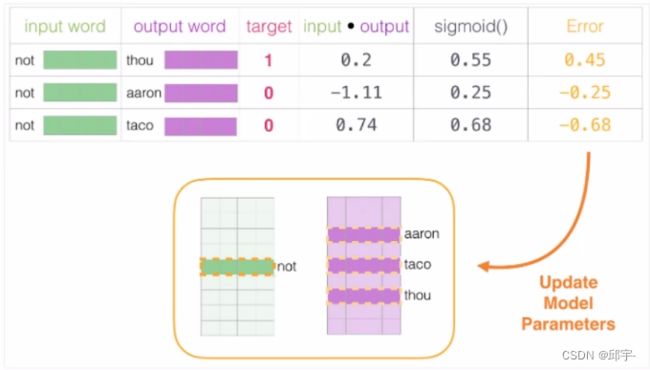
人为的创建一些不是语料库当中上下文的词,则它们的标签都为0,将这些词叫做负样本。其他的是上下文,标签为1的叫做正样本。
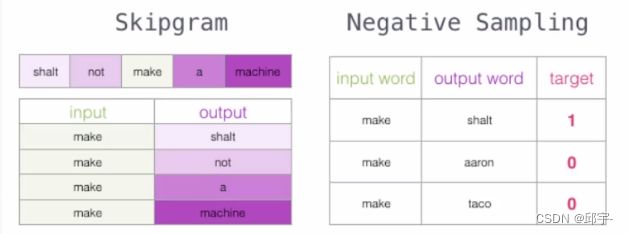
6.词向量训练过程
(1)初始化词向量矩阵


(2)通过神经网络反向传播来计算更新,此时不光更新权重参数矩阵W,也会更新输入数据。