论文阅读《KnowPrompt: Knowledge-aware Prompt-tuning withSynergistic Optimization for Relation Extractio》
论文链接KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
Introduction
现有关系抽取存在的问题:
基于微调的关系抽取方法:
(1)性能严重依赖耗时和劳动密集型的注释数据,难以很好地泛化。
(2)预训练模型与下游任务存在GAP。
基于提示微调的关系抽取方法:
(1)确定合适的提示模板需要领域专业知识
(2) 用输入实体自动构建高性能提示往往需要额外的生成和验证计算成本。
(3)关系标签的长度发生变化时,标签词搜索过程的计算复杂度非常高,通常以指数的方式依赖于类别的数量。
(4)类别的表达器(verbalizer)非常难以设计,例如__ℎ 和 :__ℎ,难以指定合适的标签词。
本文提供的思路:
(1)利用可学习的虚拟答案词,通过注入语义知识来表示关系标签,而不是常规的从词汇中的一个标签词映射到特定类别的verbalizer 。
(2)将实体周围的可学习虚拟类型词赋值为弱化类型标记符,这些词由关系标签中维护的先验知识初始化。
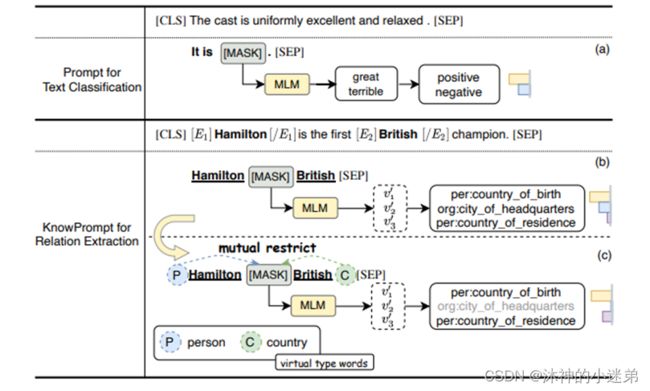
Method – 实体信息注入 & 关系信息注入
因为之前已经看过不少有关prompt的论文了,一般prompt可以通过基线模型、模板、表达器、目标函数四个角度来看。
而prompt的优势就是少样本学习和可解释性。
基线模型

主要是roberta
模板(软硬结合、搜索、利用先验知识获得潜在实体类型范围)
本文提出了虚拟类型词,利用主语和宾语的分布来初始化虚拟类型词。也是一种引入外部知识的方法。

文中给出的对应于表格1的例子:
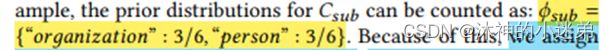
表达器(离散、搜索)
假设在PLMs的词汇表空间中存在一个虚拟答案词,它可以表示关系的隐含语义。
我们将MLM的head layer扩展为虚拟答案词集合,以完全表示对应的关系标签y。将关系类别概率用虚拟答案词集合重构。


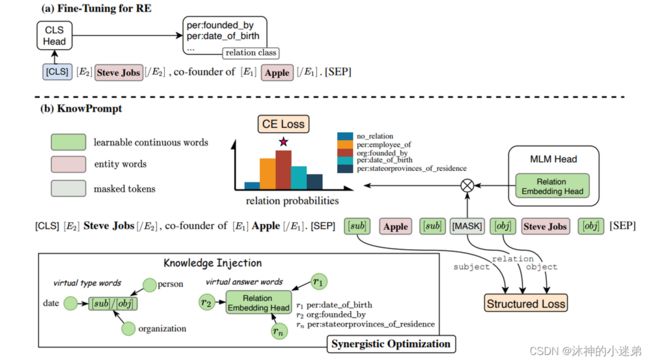 整个过程
整个过程
 虚拟类型词和虚拟答案词的生成示例
虚拟类型词和虚拟答案词的生成示例
Method - 环境提示校准 & 隐式结构约束
环境提示校准
虚拟类型和答案词是基于知识初始化的,但它们在潜在变量空间中可能不是最优的。它们应该与周围的语境相关联。需要通过感知上下文进一步优化,以校准它们的表示。
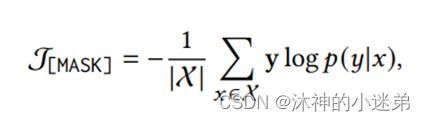
隐式结构约束
为了将结构化知识集成到知识提示符中,我们采用附加的结构化约束来优化提示符。利用LMs中虚拟类型词和虚拟答案词的输出嵌入参与计算。
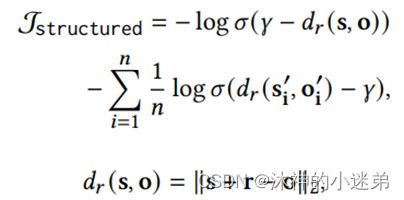
[MASK]位置分配正确的虚拟答案词,并随机采样主体实体或客体实体,并将其替换为不相关的实体,以构建负三元组。
Experiment
实验效果的话大致就是讲首先与传统微调、嵌入知识的预训练语言模型和其他提示微调比起来关系抽取的效果更好,其次prompt方法适合小样本学习,再就是虚拟标签词在3维空间与真实类别的语义距离近,然后就是消融实验证明每一个模块有效。
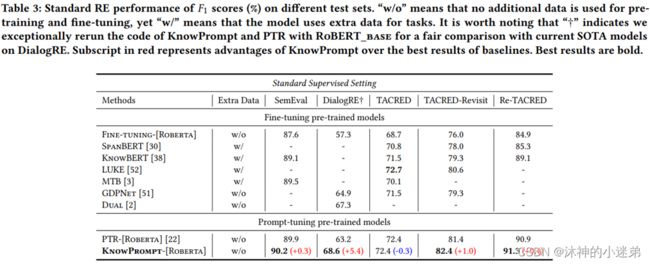
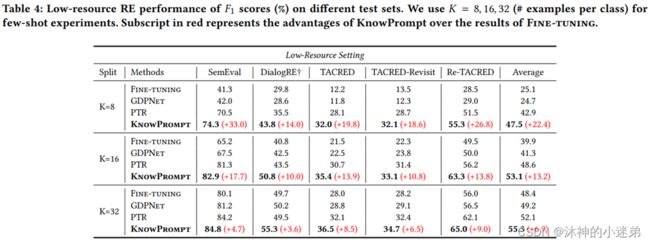
消融实验

虚拟答案词的可视化(看一下在与虚拟答案词语义比较接近的词有哪些)
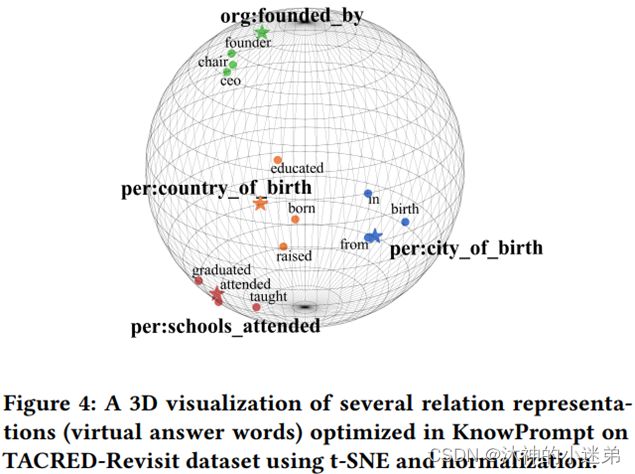
Comparison
knowprompt与ptr做对比
PTR: Prompt Tuning with Rules for Text Classification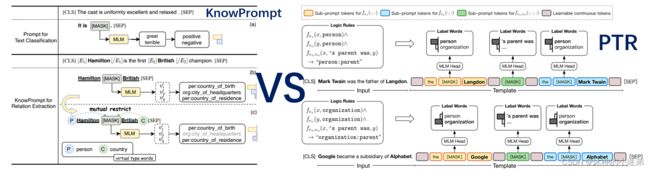
PTR中规则方法,强迫多个掩码预测会混淆多标签预测。
PTR还对每个关系做了类别(sub-prompt),细粒度实体识别标注(如FewRel 100类别,并且是一种pipeline做法)
可以从这篇文章中得到的收获
提示学习不是简单的完形填空,要针对每个任务设计策略。
虚拟词方法的出现代表着语言模型可解决任务的范围进一步扩大。
其实这篇文章应该是浙大之前的工作的一个延续:
AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction
主要的思想还是把关系的标签分解,然后作为提示学习表达器的标签词。
并且这一系列工作现在已经有了更新更好的结果:
Relation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning
总结
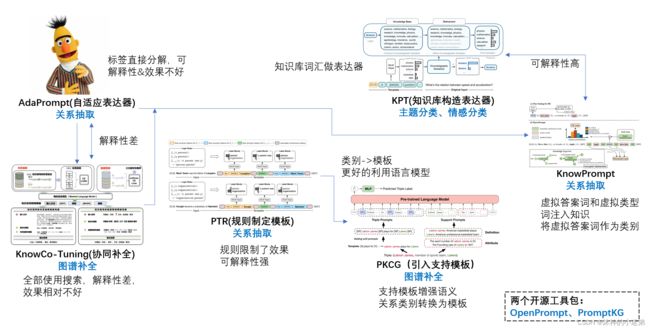
笔者对自己读过的一些prompt论文的一个想法。
排名不分先后,总结了一些做补全和做关系抽取的prompt方法,大家感兴趣的可以搜对应的论文。