CBAM: Convolutional Block Attention Module

Paper link:
CBAM: Convolutional Block Attention Modulearxiv.org
Code link:
Jongchan/attention-modulegithub.com
Abstract
本文提出了卷积块的注意力模块(Convolutional Block Attention Module),简称CBAM,该模块是一个简单高效的前向卷积神经网络注意力模块。给定一张特征图,CBAM沿着通道(channel)和空间(spatial)两个单独的维度依次推断注意力图,然后将注意力图和输入特征图相乘,进行自适应特征细化。因为CBAM是一个轻量级的通用模块,可以无缝的集成到任何CNN架构中,几乎对效率,算力没有影响,能够实现端到端的训练。
关键词:目标识别 注意力机制 卷积神经网络
Introduction
卷积神经网络凭借其强大的特征提取和表达能力,在计算机视觉任务中取得了很好的应用效果,为了进一步提升CNNs的性能,近来的方法会从三个方面考虑:深度,宽度,基数。
在深度方面的探索由来已久,VGGNet证明,堆积相同形状的卷积块能取得不错的效果,基于同样的思想,ResNet在堆积的基础上,加入skip connection,通过残差学习,在保证性能不退化的基础上,大大加深了网络层数。

ResNet中的块
在网络宽度方面,GoogleNet是一个重要尝试,该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),增加了网络的宽度。
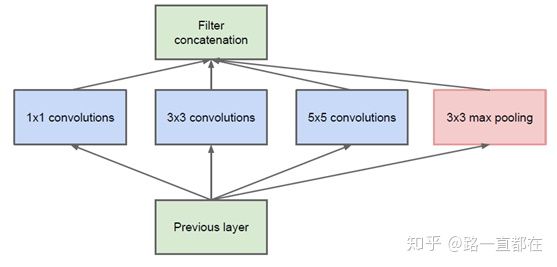
GoogLeNet之Inception V1
在网络基数方面,Facebook家的ResNeXt是一个很好的工作,何为基数(cardinality)呢?Cardinatity指的是一个block中所具有的相同分支的数目。ResNeXt通过一系列实验证明了,加大基数能够达到甚至超越加大宽度和深度的效果,具有更强的特征表现能力。
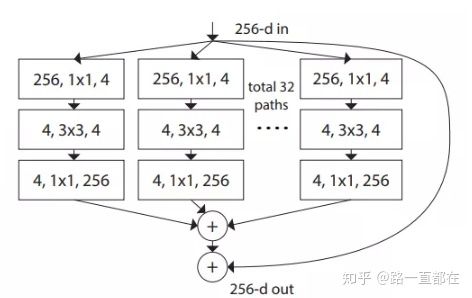
ResNeXt中的块
Background Knowledge
作者在这三种方法之外,提出了一个新的思路,注意力机制。最近几年,在计算机视觉领域,颇有点"万物皆可attention"的意思,涌现了很多基于attention的工作,在我前不久的文章里,也介绍了一个基于multi-task和attention的工作,如果您想了解更多,可以点击阅读
路一直都在:End-to-End Multi-Task Learning with Attentionzhuanlan.zhihu.com
为了方便理解,还是简单介绍一下注意力机制。从总体上说,注意力机制分为三个方面:空间域,通道域和混合域。本文是通道域和空间域,简单说明一下。
*这方面的知识,多有参考下列文章,如涉及侵权,请联系我删除
https://blog.csdn.net/paper_reader/article/details/81082351blog.csdn.net
- 空间域( Spatial Domain)
空间域的设计思路是通过注意力机制,更关注的是位置特性。将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息。如下图所示,(a)列是原始图片信息,第一个数字7较为正常,第二个数字5做了一定的旋转处理,第三个数字6加入了噪声;(b)列是经过空间转换模块学习到的bounding box,表明在转换时要将哪些关键信息进行保留;(c)列是经过空间转换模块后得到的特征图,与原始输入相比,旋转的图片被复原,有噪声的区域也被略去,于是再通过(c)列进行识别。

2. 通道域(Channel Domain)
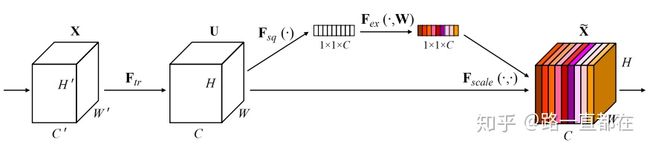
通道域的核心思想是,对经过卷积得到的特征图的每一层,乘以不同的权重,表示该层表示的特征对于关键信息的关联程度和重要程度,相应的,权重越大,表示该层表示的信息对于关键信息越重要,关联程度越高;权重越小,表示该层表示的信息对于关键信息越不重要。SeNet是典型的注意力机制模型,得到一个C维卷积层后,通过挤压函数,激励函数,尺度函数,得到每一维的权重,对应乘到不同通道的值上,得到新的特征。
CBAM(Convolutional Block Attention Module)
由上文可知,注意力机制不仅告诉你应该关注哪里,而且还会提升关键区域的特征表达。这也与识别的目标一致,只关注重要的特征而抑制或忽视无关特征。这样的思想,促成了本文提出的CBAM网络(Convolutional Block Attention Module)。如下图所示,依次用到注意力机制中的通道域模块和空间域模块,通过这两个模块,得到细化后的feature。网络具有了学习“What”和“Where”的能力,让网络更好的知道哪些信息需要强调,哪些信息需要抑制。

接下来详细说一下CBAM的过程:
给定一个中间特征图,属性为高H,宽W,维度C,作为输入,F可以用下式表示:
![]()
CBAM依次得到一个一维的通道注意力图Mc和一个二维的空间注意力图Ms,整个流程可以概括为:
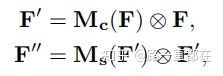
其中,⊗表示对应元素相乘操作。下面分别看一下通道域的注意力模块和空间域的注意力模块实现过程。
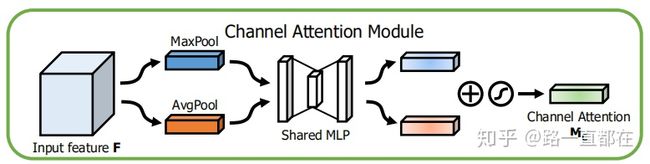
- Channel attention module.
核心思想:利用特征的通道间关系,生成通道注意图
输入:C维 feature map
输出:1x1xC channel attention map
步骤:
(1)对于输入feature map,分别进行平均池化和最大值池化聚合空间信息,得到两个C维池化特征图,F_avg和F_max。
(2)将F_avg和F_max送入包含一个隐层的多层感知器MLP里,得到两个1x1xC的通道注意力图。其中,为了减少参数量,隐层神经元的个数为C/r,r也被称作压缩比。
(3)将经过MLP得到的两个通道注意力图进行对应元素相加,激活,得到最终的通道注意力图Mc。
公式表示:
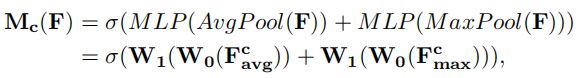
Channel Attention Module
几个答疑:
(1)为什么要对输入特征进行平均池化和最大池化两种处理方式?
为了更好的聚合feature map的信息并减少参数量,池化是必不可少的步骤,对于空间信息的聚合,目前普遍采用的是平均池化的方法,但作者认为,最大池化会收集到不同于平均池化的,关于不同目标特征的表示,这对于后续得到更精细的注意力通道图是有帮助的。实验也表明,对于平均池化和最大池化的综合运用,是有助于性能提升的。

(2)MLP的结构是如何设计的?
本文用到的是只有一层hidden layer的MLP,非常简单,以W0和W1分别表示隐层权重和输出层权重,那么属性可以表示为:
![]()
此外,W0和W1的参数是共享的。
综上,通道注意力模块更关注的是“What”属性,也就是什么是对于后续处理有意义的。经过Channel Attention Module之后,我们得到的是一个1x1xC的通道注意力图,图上每一维的权重,表示该维对应的feature map层中,对于关键信息的重要程度和关联程度。
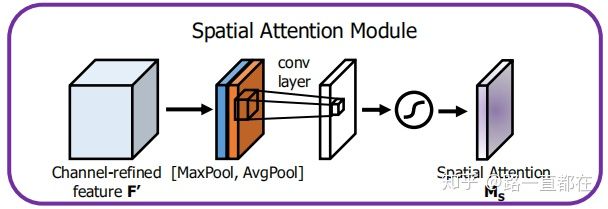
- Spatial attention module.
核心思想:利用特征间的空间关系生成空间注意图
输入:Channel-refined feature F’(经过通道注意力图细化后的feature map)
输出:HxW的spatial map
步骤:
(1)对于F’首先沿着通道方向进行最大池化和平均池化,得到两个二维的feature map F_avg和F_max,属性都是1xHxW,将得到的两个feature map进行维度拼接(concatenate),得到拼接后的feature map。
(2)对于拼接后的feature map,利用size为7x7的卷积层生成空间注意力图Ms。
公式表示:
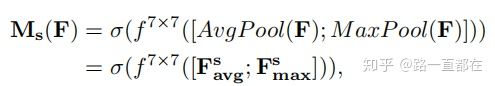
几个答疑:
(1)为什么要沿着维度通道进行平均池化和最大池化?
作者借鉴ICLR2017的论文《Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer》,认为沿着通道轴应用池化操作可以有效地突出显示含有关键信息的区域。作者的实验也支持这一观点。
(2)维度拼接(Concatenate)具体操作过程?
Concatenate的具体操作是将两个size相同的feature map,在维度方向进行拼接,拼接完成后,新的特征图的通道会是原来两个特征图通道之和。这种操作是进行特征融合的普遍做法。
综上,空间注意力模块更关注的是“Where”,即哪些位置有关键信息,这对于前面的关注“What”的通道注意力模块是一个补充,成为网络的左膀右臂。
- Arrangement of attention modules
我们介绍了通道注意力模块和空间注意力模块,两个模块用什么方式组合是最优的呢?并行还是连续,不同的组合方式会影响网络的表现,作者做了一系列实验表明,顺序排列比并行排列的结果更好。
Experiments
接下来看一下实验部分,由于我的侧重点是分类,所以主要看一下CBAM在分类上的表现。
CBAM模块非常容易和CNN网络结构融合,如下图所示是将CBAM融入到ResNet中

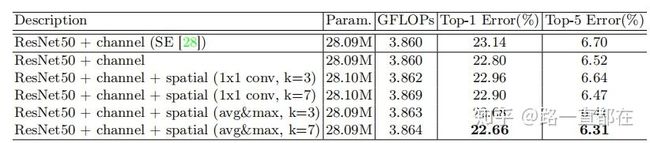
- 不同空间注意力方法的比较
前文讨论过,在空间注意力模块,要在维度方向进行最大池化和平均池化,通过下图实验结果可以看到,维度方向的池化操作效果更好
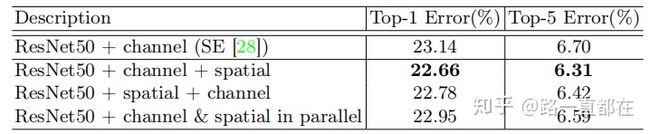
- 不同排列方式的比较
关于通道注意力模块和空间注意力模块的排列方式,作者进行了实验,结果表明,相比并行排列的方式,顺序排列方式性能更佳。
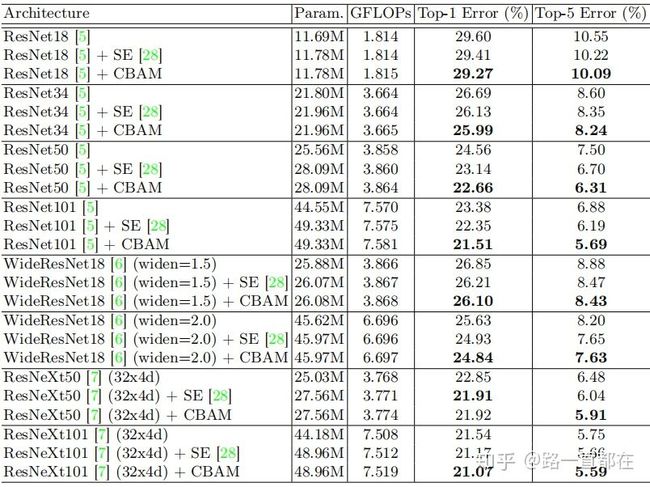
- 在ImageNet-1K上的图像分类效果
融合了CBAM的网络,有了更好的表现
Conclusion
CBAM融合了注意力机制中的两种常见表示,通道域的注意力机制和空间域的注意力机制,通过将两种模块顺序组合,两者相互补充,使得网络具有了知晓“What”和“Where”的能力,即知道在哪些位置上的哪些特征,是关键且重要的信息。通过这样的方式,进一步提升了CNNs的特征提取和表示能力,而且CBAM可以无缝的嵌入各种CNNs结构中,对于计算机视觉任务有很好的表现。
本文的主要贡献点在于:
- 提出了一种简单而有效的注意模块(CBAM),可广泛应用于提高CNNs的表示能力。
- 通过详实的实验来验证注意力模块的有效性。
- 通过和各种CNNs的无缝嵌入,实现了各项计算机视觉任务上的性能提升。
转载链接:https://zhuanlan.zhihu.com/p/83665899