基于keras的疫情预测模型的设计与实现
博主采用消融实验,通过LSTM,Seq2Seq+LSTM,LSTM+Attention,Seq2Seq+Attention+LSTM,CNN+BiLSTM+Attention五种模型框架对环境污染数据集进行实验,结果如下:
LSTM模型实现
结构图解
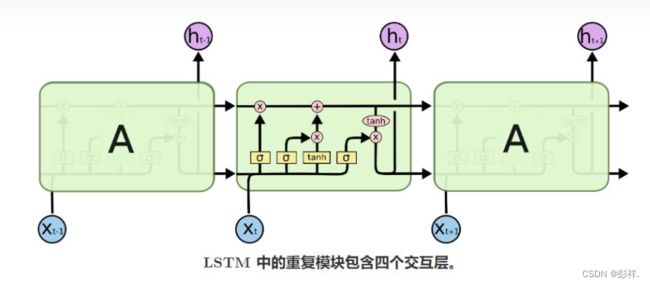
代码实现
def generate_lstm_model(self,n_input, n_out, n_features):
self.model = Sequential()
self.model.add(LSTM(50, activation='relu', input_shape=(n_input, n_features)))
self.model.add(Dropout(0.3))
self.model.add(Dense(n_out))
self.model.summary()
# 模型编译
self.model.compile(optimizer='adam', loss='mse')
return self.model
模型结构

实验结果
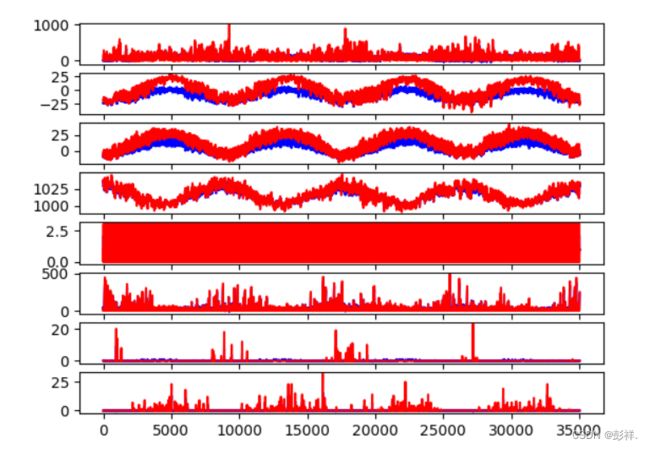
Test RMSE: 16.235
Seq2Seq模型实现
结构图解
首先我们需要了解一些基础概念,博主的大框架使用的是Seq2Seq:

实例介绍
使用Keras建立Seq2Seq模型的基本方法如下:
from tensorflow.keras.layers.recurrent import GRU
from tensorflow.keras.layers.wrappers import TimeDistributed
from tensorflow.keras.models import Sequential, model_from_json
from tensorflow.keras.layers.core import Dense, RepeatVector
def build_model(input_size, seq_len, hidden_size):
"""建立一个 sequence to sequence 模型"""
model = Sequential()
model.add(GRU(input_dim=input_size, output_dim=hidden_size, return_sequences=False))
model.add(Dense(hidden_size, activation="relu"))
model.add(RepeatVector(seq_len))
model.add(GRU(hidden_size, return_sequences=True))
model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear")))
model.compile(loss="mse", optimizer='adam')
return model
下面以时间序列为例来讲解各网络层,各参数的含义:
参数讲解
假设我们的输入有4个时间步,要预测未来的3个时间步,也就是每一个时间样本有4个时间切片,为了简单起见我们就以简单的单变量为例,每个时间步下1个特征也就是序列数据本身,然后标签也是时间样本,每个时间样本下3个时间切片,每个时间切片下也是一个特征,样本的构造大概长这个样子,以1个样本为例:
input
[[1]] [[2]] [[3]] [[4]]
output:
[[5]] [[6]] [[7]]
则代码如下:
model = Sequential()
model.add(GRU(input_dim=(4,1), output_dim=hidden_size, return_sequences=False))#输入序列格式为4步长,一变量,输出实为隐藏层个数
model.add(Dense(hidden_size, activation="relu"))
model.add(RepeatVector(3)) ## seq_len和我们预测未来多少个时间步有关,上面我们用历史的4个时间步长的数据来预测未来的3个时间步,则repeat 3次,即会将步长改为3
model.add(GRU(hidden_size, return_sequences=True))
model.add(TimeDistributed(Dense(output_dim=1, activation="linear")))
#由于上面将步长改为3了,这里我们只需要设置输出变量数为一即可,单变量为1,多变量则改为相应值即可
self.model.add(TimeDistributed(Dense(units=n_out, activation="linear")))
self.model.add(Flatten())#扁平层将(None,1,8)变为(None,1*8)
self.model.summary()
model.compile(loss="mse", optimizer='adam')
TimeDistributed和Dense的使用
下面代码是keras里面给出的解释:
# as the first layer in a model
model = Sequential()
model.add(TimeDistributed(Dense(8), input_shape=(10, 16)))
# now model.output_shape == (None, 10, 8)
从上述代码中可以发现,TimeDistributed和Dense一起配合使用,主要应用于一对多,多对多的情况。
input_shape = (10,16),表示步长是10,每一步的维度为16,(即:每一个数据的属性长度为16))
首先使用TimeDistributed(Dense(8),input_shape = (10,16))把每一步的维度为16变成8,不改变步长的大小
若该层的批输入形状然后(50, 10, 16),则这一层之后的输出为(50, 10, 8)
RepeatVector的使用
这个是keras官网给出的解释
model = Sequential()
model.add(Dense(32, input_dim=32))
# now: model.output_shape == (None, 32)
# note: `None` is the batch dimension
model.add(RepeatVector(3))
# now: model.output_shape == (None, 3, 32)
解释:如果输入的形状为(None,32),经过添加RepeatVector(3)层之后,输出变为(None,3,32),RepeatVector会改变我们的步长,不改变我们的每一步的维数(即:属性长度)
代码实现
def generate_seq2seq_model(self,n_input, n_out, n_features):
self.model = Sequential()
self.model.add(LSTM(50,input_shape=(n_input, n_features)))
self.model.add(Dense(10, activation="relu"))
# 使用 "RepeatVector" 将 Encoder 的输出(最后一个 time step)复制 N 份作为 Decoder 的 N 次输入
self.model.add(RepeatVector(1))#此为步长
# Decoder(第二个 LSTM)
self.model.add(LSTM(50,return_sequences=True))
# TimeDistributed 是为了保证 Dense 和 Decoder 之间的一致
self.model.add(TimeDistributed(Dense(units=n_out, activation="linear")))
self.model.add(Flatten())#扁平层将(None,1,8)变为(None,1*8)
self.model.summary()
self.model.compile(loss="mse", optimizer='adam')
return self.model
模型结构
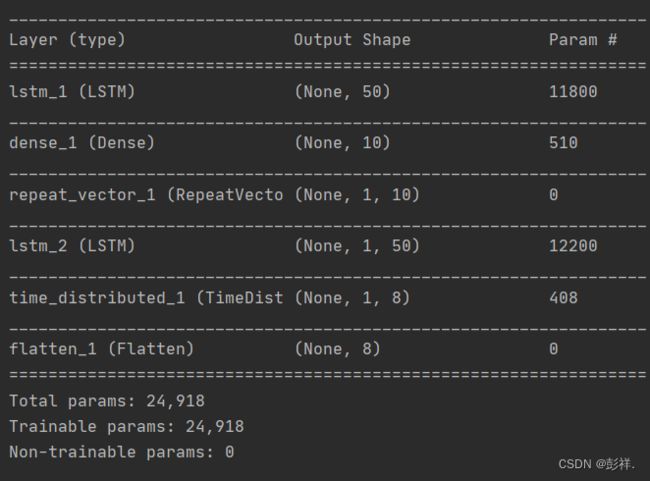
实验结果
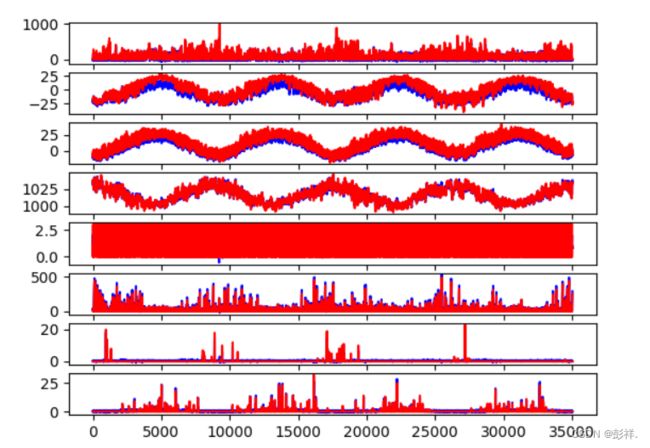
Test RMSE: 17.565
LSTM+Attention模型实现
代码实现
注意力模型的实现需要我们定义一个注意力块,其主要完成的是一个维度转换并进行求权重值的作用。
def attention_block(self,inputs,time_step):
# batch_size, time_steps, lstm_units -> batch_size, lstm_units, time_steps
a = Permute((2, 1))(inputs)
# batch_size, lstm_units, time_steps -> batch_size, lstm_units, time_steps
a = Dense(time_step, activation='softmax')(a)
# batch_size, lstm_units, time_steps -> batch_size, time_steps, lstm_units
a_probs = Permute((2, 1), name='attention_vec')(a)
# 相当于获得每一个step中,每个特征的权重
output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')
return output_attention_mul
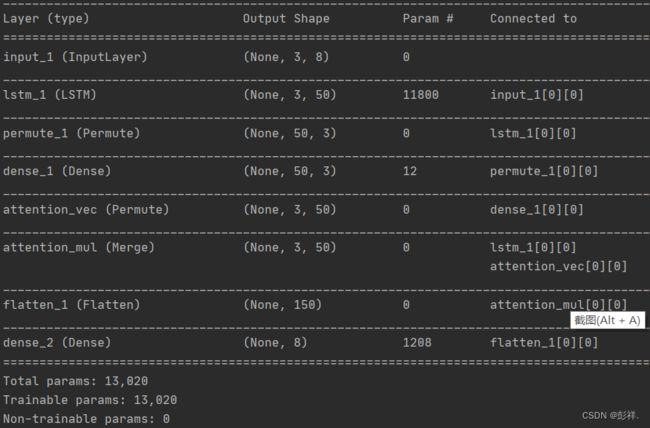
def generate_attention_model(self, n_input, n_out, n_features):
inputs = Input(shape=(n_input, n_features,))
# (batch_size, time_steps, input_dim) -> (batch_size, input_dim, lstm_units)
lstm_out = LSTM(50, return_sequences=True)(inputs)
attention_mul = self.attention_block(lstm_out,n_input)
# (batch_size, input_dim, lstm_units) -> (batch_size, input_dim*lstm_units)
attention_mul = Flatten()(attention_mul)
output = Dense(n_out, activation='sigmoid')(attention_mul)
model = Model(inputs=[inputs], outputs=output)
model.summary()
model.compile(loss="mse", optimizer='adam')
return model
模型结构
实验结果
迭代20次后效果不错:当然使用了注意力机制后,在获得了准确性的同时,也需要进行计算的消耗,时间复杂度提升,导致运行时间也加长。
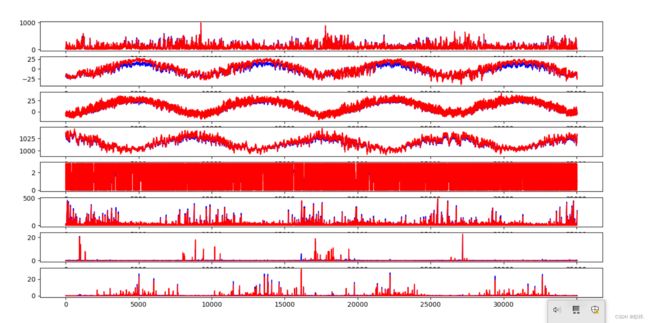
最终的结果:Test RMSE: 13.438
Seq2Seq+Attention+LSTM模型构建
结构图解
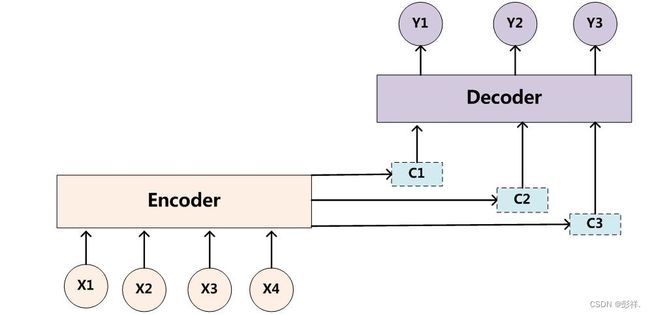
该模型实际为Seq2Seq与Attention两者的结合体。
代码实现
def generate_seq2seq_attention_model(self, n_input, n_out, n_features):
inputs = Input(shape=(n_input, n_features,))
lstm_out1 = LSTM(50, return_sequences=True)(inputs)
attention_mul = self.attention_block(lstm_out1, n_input)
# (batch_size, input_dim, lstm_units) -> (batch_size, input_dim*lstm_units)
attention_mul = Flatten()(attention_mul)
output1 = Dense(n_out, activation='sigmoid')(attention_mul)
repeatVector=RepeatVector(1)(output1)
lstm_out2 = LSTM(50, return_sequences=True)(repeatVector)
output2=TimeDistributed(Dense(n_out))(lstm_out2)
flatten=Flatten()(output2)
model = Model(inputs=[inputs], outputs=flatten)
model.summary()
model.compile(loss="mse", optimizer='adam')
return model
网络模型结构

实验结果
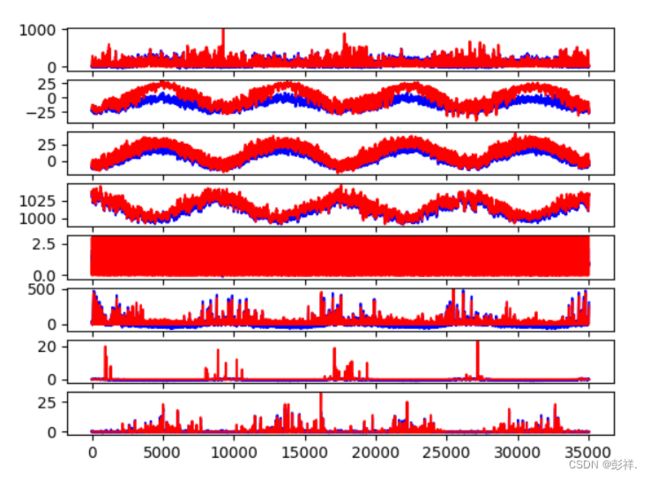
Test RMSE: 20.571
CNN+LSTM+Attention模型实现
代码实现
注意力模块使用的是之前的
def cnn_lstm_attention_model(self, n_input, n_out, n_features):
inputs = Input(shape=(n_input, n_features))
x = Conv1D(filters=64, kernel_size=1, activation='relu')(inputs) # , padding = 'same'
x = Dropout(0.3)(x)
# lstm_out = Bidirectional(LSTM(lstm_units, activation='relu'), name='bilstm')(x)
# 对于GPU可以使用CuDNNLSTM
lstm_out = Bidirectional(LSTM(50, return_sequences=True))(x)
lstm_out = Dropout(0.3)(lstm_out)
attention_mul = self.attention_block(lstm_out, n_input)
attention_mul = Flatten()(attention_mul)
output = Dense(n_out, activation='sigmoid')(attention_mul)
model = Model(inputs=[inputs], outputs=output)
model.summary()
model.compile(loss="mse", optimizer='adam')
return model
模型结构
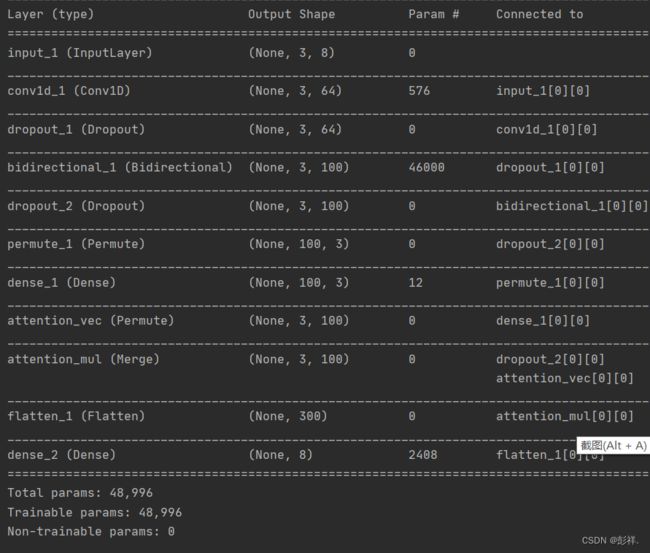
实验结果
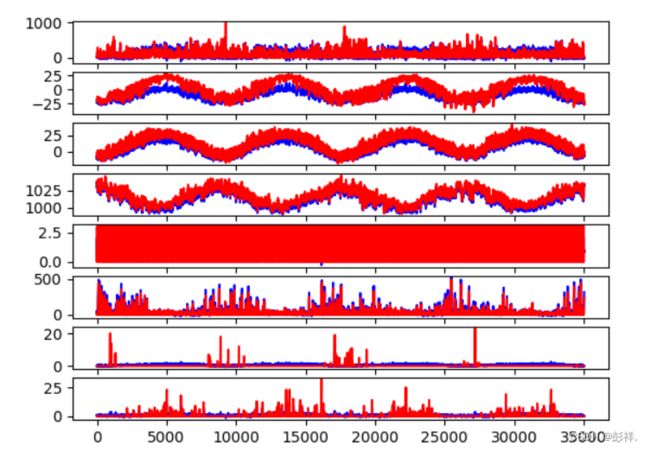
Test RMSE: 15.296