集成学习 Adaboost(python实现)
参考资料
- 理论原理部分参考刘建平老师的博客集成学习之Adaboost算法原理小结
- 算法参数选择与调整上参考刘建平老师的博客scikit-learn Adaboost类库使用小结
算法实现
导入包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
数据准备
- 这里使用
sklearn.datasets中make_gaussian_quantiles函数生成分类数据。具体使用方法参考机器学习算法的随机数据生成
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征,协方差系数为2
X1, y1 = make_gaussian_quantiles(cov=2.0,n_samples=500, n_features=2,n_classes=2, random_state=1)
# 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3,协方差系数为2
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,n_samples=400, n_features=2, n_classes=2, random_state=1)
#讲两组数据合成一组数据
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
X.shape()
可视化
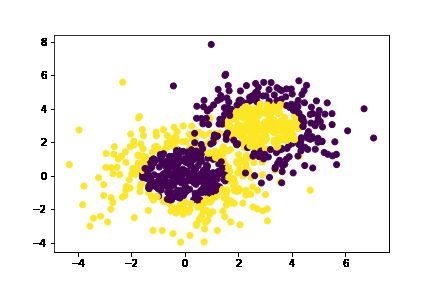
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
输出:
构建Adaboost模型
- 我们把参数分为两类,第一类是Boosting框架的重要参数,第二类是弱学习器即CART回归树的重要参数。
调整Boosting框架参数
- 从步长(learning rate) 和 迭代次数(n_estimators) 入手。一般来说,开始选择一个较小的步长来网格搜索最好的迭代次数。
迭代次数调整
- 将步长初始值设置为0.5。对于迭代次数进行网格搜索
# 决策树参数
estimatorCart_1 = DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5)
from sklearn.model_selection import GridSearchCV
# 迭代次数的网格搜索
param_1 = [{'n_estimators':range(100,201,10)}]
search_1 = GridSearchCV(estimator = AdaBoostClassifier(estimatorCart_1,algorithm="SAMME",learning_rate=0.5),
param_grid = param_1, cv = 10,
scoring = 'roc_auc',
return_train_score = True)
search_1.fit(X,y)
print(search_1.best_params_,search_1.best_score_)
# 将迭代次数(n_estimators)固定下来
输出:
{'n_estimators': 160} 0.9632592592592595
- 由此将迭代次数固定,即
'n_estimators' = 160。
调整CART回归树参数
- 决策树最大深度
max_depth和内部节点再划分所需最小样本数min_samples_split进行网格搜索。
最大深度调整
- 决策树最大深度在
[4,5,6,7,8]间搜索 - 内部节点再划分所需最小样本数在
[3,9,12,15,18,21]间搜索
from sklearn.model_selection import cross_validate
score = 0
for i in range(4,10,1): # 决策树最大深度循环
for j in range(3,22,3): #决策树内部节点再划分所需最小样本数循环
bdt=AdaBoostClassifier(DecisionTreeClassifier(max_depth=i,min_samples_split=j,min_samples_leaf=5),
algorithm="SAMME",
learning_rate=0.5,
n_estimators=160)
cv_result = cross_validate(bdt,X,y,return_train_score=False,cv=10)
cv_value_vec = cv_result["test_score"]
cv_mean = np.mean(cv_value_vec)
if cv_mean>=score:
# 交换最优解
score = cv_mean
tree_depth = i
samples_split = j
score, tree_depth, samples_split
# 将深度决策树深度固定下来
输出:
(0.9166666666666667, 6, 9)
所需最小样本数调整
- 决策树深度6是一个比较合理的值,先它固定下来。
- 对于内部节点再划分所需最小样本数
min_samples_split,暂时不能一起定下来,因为这个还和决策树其他的参数存在关联。 - 下面我们再对内部节点再划分所需最小样本数
min_samples_split和叶子节点最少样本数min_samples_leaf一起调参。
score = 0
for i in range(2,101,10): #决策树内部节点再划分所需最小样本数循环
for j in range(3,22,3): #决策树叶子节点最少样本数
bdt=AdaBoostClassifier(DecisionTreeClassifier(max_depth=tree_depth,min_samples_split=i,min_samples_leaf=j),
algorithm="SAMME",
learning_rate=0.5,
n_estimators=160)
cv_result = cross_validate(bdt,X,y,return_train_score=False,cv=10)
cv_value_vec = cv_result["test_score"]
cv_mean = np.mean(cv_value_vec)
if cv_mean>=score:
# 交换最优解
score = cv_mean
samples_split = i
samples_leaf = j
#固定决策树内部节点再划分所需最小样本数循环与叶子节点最少样本数
score, samples_split, samples_leaf
输出:
(0.918888888888889, 80, 3)
获得最优模型
# 确定最优模型
final_model = AdaBoostClassifier(DecisionTreeClassifier(max_depth=tree_depth,
min_samples_split=samples_split,
min_samples_leaf=samples_leaf),
algorithm="SAMME",
learning_rate=0.5,
n_estimators=160)
final_model.fit(X,y)
预测并可视化
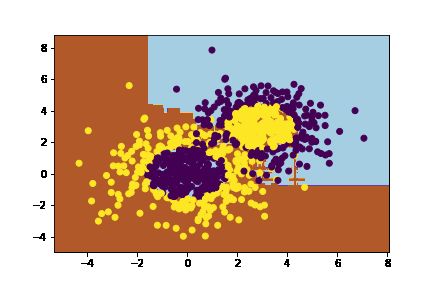
# 预测情况
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = final_model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:, 0], X[:, 1], marker='o', c=y)
plt.show()
输出:
结语
- 这里提供完整代码下载