目标检测(四):SSD之Pytorch源码解读
读完 SSD 的论文内容能大致了解这一算法的核心思想和算法流程,但要将其应用到实际问题上还需要去读代码。论文给出的 SSD 源码是用 Caffe 框架实现的,但自己使用 Caffe 搭建 SSD 的环境实在是太复杂了 (师弟说他用了半个月的时间都没有弄好,到处都是坑坑坑,最后还是用了搭建好的付费服务器),且 Caffe 这个框架着实有点 outdate,所以我就准备看下 Tensorflow 或 Pytorch 的实现。恰好某站上有个超细节的up主录制了 Pytorch 实现 SSD 的视频,而且项目所需恰好也是Pytorch~~有同样需求的盆友可以去看下该up主的视频,链接:Pytorch 搭建自己的SSD目标检测平台(Bubbliiiing 深度学习 教程)
除此之外,Github 上也有星星数很高的基于 Tensorflow 的实现,链接如下:
- code----Caffe实现
- code----Tensorflow实现
- code----Pytorch实现1
- code----Pytorch实现2,这个就是上述视频链接对应的源码。(2021.11.1——源码已更新,本文用到的不是目前github上的最新源码)
目录
-
- 一、预测
-
- 1. 提取特征:VGG主干层 + Extra 层
-
- 1.1 VGG 部分
- 1.2 Extra 部分
- 2. 处理特征:从特征中获取预测结果
-
- 2.1 db 的生成及可视化
- 2.2 实现 分类 & 回归
- 2.3 获取 分类 & 回归的结果
- 3. 特征解码:从预测结果中得到预测框
- 4. 预测过程及效果展示
-
- 4.1 CPU 预测效果展示
- 4.2 实际预测过程
- 二、训练
-
- 1. gt box与default boxes的匹配过程
- 2. 计算损失函数
- 3. 整体训练过程
-
- 3.1 数据增强
- 3.2 数据集的生成
- 3.3 训练
- 三、训练自己的 SSD
-
- 1. 构造数据集
- 2. 训练
- 3. 预测
- 四、总结
这篇记录用的源码是上面第四个链接中的,我是直接下载了压缩包,解压后用Pycharm打开的,整体结构如下图所示:

下面是按照网络结构和 SSD 的预测流程展示的代码,一些基本的操作以注释写在了代码中,还有一些我不太了解的点,就单独列了出来作为学习记录。
一、预测

根据上述结构图和论文中的描述,SSD 是由两部分构成的,一个是基础网络 VGG-16,另一个是 Extra 的卷积层,分别从这两部分中提取出六个特征图参与分类和回归任务:
# 用于分类和回归的特征层:
feature_layer = [conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11_2]
# 对应的特征图尺寸:
feature_shape = [38x38x512, 19x19x1024, 10x10x512, 5x5x256, 3x3x256, 1x1x256]
1. 提取特征:VGG主干层 + Extra 层
1.1 VGG 部分
VGG 主干层的贡献是 conv4_3 和 conv7 的特征图,论文中提到
- 将 VGG 的全连接层 fc6 和 fc7 更改为 3 × 3 3\times3 3×3 和 1 × 1 1\times1 1×1 的卷积层
conv6和conv7; - 将池化层
pool5由 2 × 2 s t r i d e = 2 2\times2\ stride=2 2×2 stride=2 更改为 3 × 3 s t r i d e = 1 3\times3\ stride=1 3×3 stride=1;
因此,只需要对原始 VGG 网络进行相应地修改即可,对应代码在上面目录中的路径为:ssd-pytorch-master\nets\vgg.py。
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
# 该代码用于获得 VGG 主干网络的输出,即进行特征提取。
# base 为基本操作列表。卷积或池化后尺寸计算为(n-k+2p)/s+1
base = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M', 512, 512, 512]
'''
随着base的循环,特征层变化如下:
input 300,300,3 ->
conv1_1 300,300,64 ->
conv1_2 300,300,64 ->
Pooling1 150,150,128 ->
conv2_1 150,150,128 ->
conv2_2 150,150,128 ->
Pooling2 75,75,128 ->
conv3_1 75,75,256 ->
conv3_2 75,75,256 ->
conv3_3 75,75,256 ->
Pooling3 38,38,256 -> 这里使用了ceil_mode=True的最大池化, 目的是保留最后的单数边,因为输入是75x75。
conv4_1 38,38,512 ->
conv4_2 38,38,512 ->
conv4_3 38,38,512 -> 用作分类和回归的第一个有效特征图
Pooling4 19,19,512 -> 此池化层及以上的 kernel_size=2, stride=2
conv5_1 19,19,512 ->
conv5_2 19,19,512 ->
conv5_3 19,19,512 ->
Pooling5 19,19,512 -> 这里是因为池化层5的 kernel_size=3,stride=1,padding=1
conv6 19,19,1024 -> 这里 padding=6, dilation=6, 用于模拟全连接层
conv7 19,19,1024 -> 用作分类和回归的第二个有效特征图
'''
# 将带有卷积、池化操作的特征层添加到列表 layers 中。
def vgg(i):
layers = []
in_channels = i # 变量 i 代表的是输入图片的通道数,通常为3
for v in base: # 遍历列表 base
if v == 'M': # M 表示最大池化,核大小为 2,步长为 2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # 将最大池化操作添加到列表 layers 中
elif v == 'C': # C 表示 ceil_mode=True 的最大池化,作用是保留单数边。
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else: # 数字表示卷积+ReLU激活函数
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1) # 卷积操作时padding=1
layers += [conv2d, nn.ReLU(inplace=True)] # 将卷积操作添加到列表 layers 中
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # 注意这里的stride=1,因此pool5的输出仍是19x19
# dilation能够在不进行pooling的情况下(保持图像尺寸)扩大感受野,对3x3的卷积核,膨胀后感受野变为13x13。
# 那么经过空洞卷积后特征图的大小为(19-13+2x6)/1+1=19,即尺寸未发生变化。
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) # 利用dilation=6模拟全连接层增大深度
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
这部分有两个想要细说的点。
ceil_mode属性
第一个是列表 base 中的最大池化操作 C。刚看到的时候会比较懵,其他的最大池化都是 M,也就是标准最大池化,而这个 C 是啥子?其实它对应的操作是 ceil_mode=True 的 maxpooling,这里的 ceil_mode 是最大池化的一个属性,该属性在输入尺寸为偶数的时候没有影响;但当输入尺寸为奇数时,ceil_model = True / False 会产生不同的结果。
比如对 5 × 5 5\times5 5×5 的特征图进行 kernel_size=2, stride=2 的最大池化操作:
- 当
ceil_mode=False时,剩余的最后一行和最后一列像素将不会进行最大池化,此时输出尺寸为 2 × 2 2\times2 2×2;
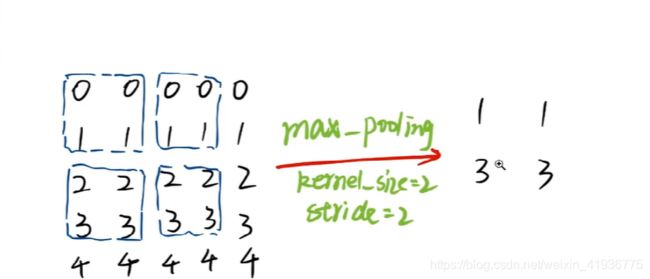
- 当
ceil_mode=True时,剩余的最后一行和最后一列像素仍会进行最大池化,此时输出尺寸为 3 × 3 3\times3 3×3。
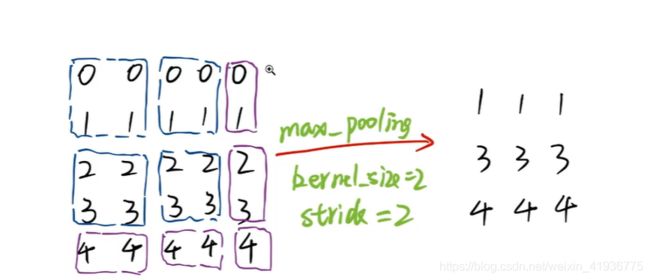
所以可以把 ceil_mode 这个属性理解为是否保留单数边(也就是不足 kernel_size 的边),也可以将两种不同的模式理解为向上或向下取整。
关于为什么在 Pooling3 中采用 ceil_mode=True:
代码开头的注释部分给出了每一层输出的 feature_shape,注意 conv3_3 的输出是 75 × 75 75\times75 75×75,池化的参数是 kernel_size=2,stride=2,像刚刚举的例子,如果这里采用标准最大池化,那显然输出就不会是 38 × 38 38\times38 38×38。
空洞卷积
第二个地方是
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) # 利用dilation=6模拟全连接层增大深度
这里采用了空洞卷积(也就是膨胀卷积),dilation=6 是指膨胀率为 6,目的是通过这一操作来模拟原始 VGG 的全连接层。
首先 conv6 的输入是 19 × 19 × 512 19\times19\times512 19×19×512,我们希望在增加深度的同时保持特征图的大小,而空洞卷积的作用就是在不减小特征图尺寸的情况下以更大的感受野提取更多信息。其次注意到 conv6 的输出为 19 × 19 × 512 19\times19\times512 19×19×512,即保持了特征图的尺寸。
关于空洞卷积的原理可以看下某乎上的回答 如何理解空洞卷积(dilated convolution)?,个人觉得很有用的。先放个到处可见的图:
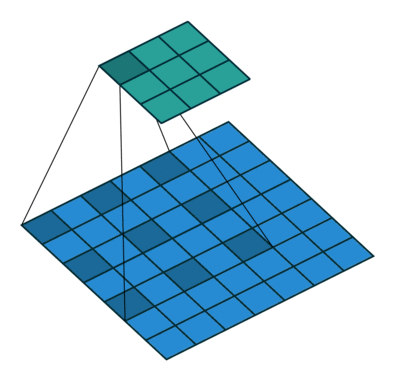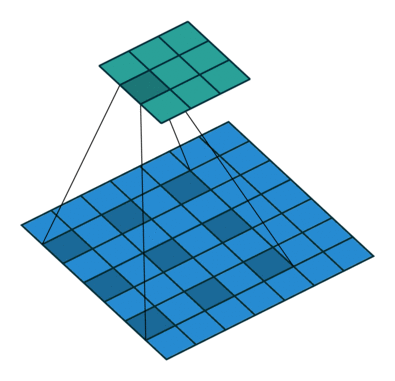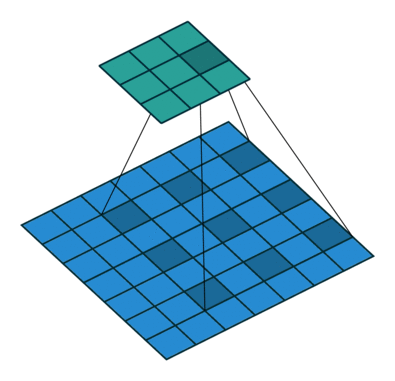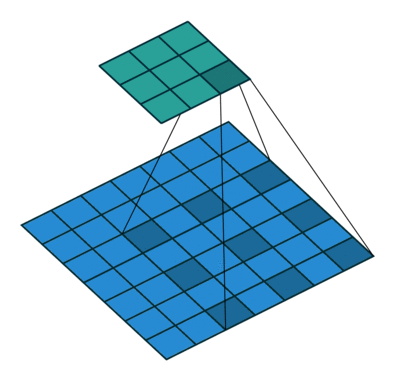
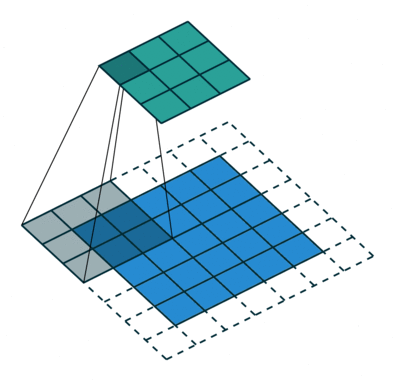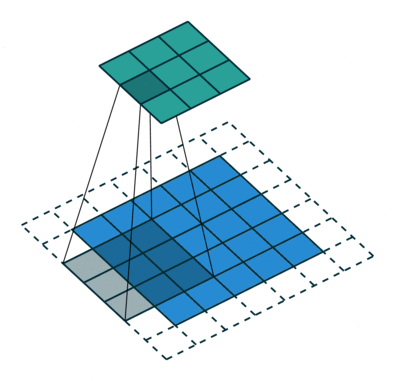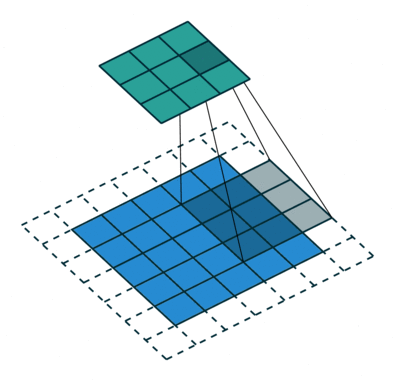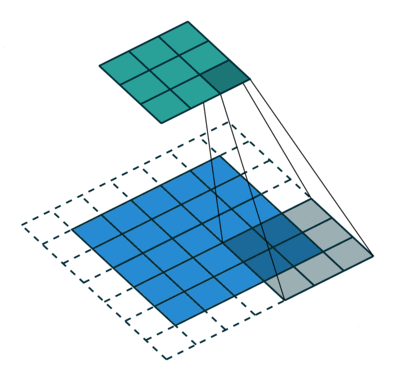
首先需要明确空洞卷积不是简单的在像素之间 padding 空白的像素,上图和上上图分别演示了 kernel_size=3x3 的标准卷积和 dilation=2 的空洞卷积。直白点讲,空洞卷积是在已有的像素上略掉一些像素,或者保持输入不变但在卷积核的参数中设置部分为 0 的权重,从而达到增大感受野的目的。
以 conv6 的输入为例,kernel_size=3x3, dilation=6 相当于将卷积核增大为 13 × 13 13\times13 13×13。
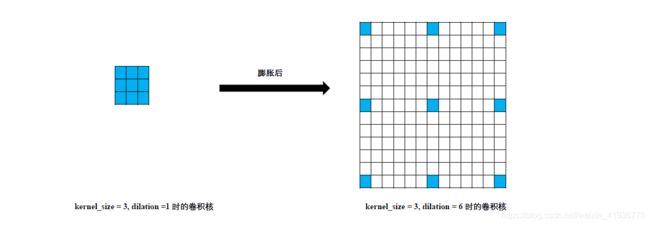
再根据 feature_shape=19x19, stride=2,padding=6,可以计算出 conv6 后的特征图大小为:
19 − 13 + 2 × 6 1 + 1 = 19 \frac{19-13+2\times6}{1}+1=19 119−13+2×6+1=19
(可能这种理解方式不太正确,希望大家可以不吝赐教~~)
1.2 Extra 部分
SSD 在 VGG 后新增了四个卷积层用于提取特征,因此我们需要将新增部分的卷积、池化等操作添加到操作列表 layers 中。
实现代码:ssd-pytorch-master\nets\ssd.py ----> add_extras()
# 向 VGG 网络中新增的特征层,用于实现多尺度特征图
'''
conv8_1 19,19,1024 ->
conv8_2 10,10,512 -> 用于回归和分类的第三个有效特征图
conv9_1 10,10,512 ->
conv9_2 5,5,256 -> 用于回归和分类的第四个有效特征图
conv10_1 5,5,256 ->
conv10_2 3,3,256 -> 用于回归和分类的第五个有效特征图
conv11_1 3,3,256 ->
conv11_2 1,1,256 用于回归和分类的第六个有效特征图
'''
def add_extras(i, batch_norm=False):
# 将卷积、池化等操作添加到列表layers中
layers = []
in_channels = i
# Block 8
# 19,19,1024 -> 10,10,512 用于回归和分类的第三个有效特征图
layers += [nn.Conv2d(in_channels, 256, kernel_size=1, stride=1)] # 压缩通道数,获得 19,19,256
layers += [nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)] # 注意stride=2,获得10,10,512
# Block 9
# 10,10,512 -> 5,5,256 用于回归和分类的第四个有效特征图
layers += [nn.Conv2d(512, 128, kernel_size=1, stride=1)] # 获得 10,10,128
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)] # 注意stride=2,获得 5,5,256
# Block 10
# 5,5,256 -> 3,3,256 用于回归和分类的第五个有效特征图
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] # 获得 5,5,128
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] # 无padding,stride=1,获得 3,3,256
# Block 11
# 3,3,256 -> 1,1,256 用于回归和分类的第六个有效特征图
layers += [nn.Conv2d(256, 128, kernel_size=1, stride=1)] # 获得 3,3,128
layers += [nn.Conv2d(128, 256, kernel_size=3, stride=1)] # 无padding,stride=1,获得 1,1,256
return layers
2. 处理特征:从特征中获取预测结果
上一部分的代码构建了 SSD 特征提取网络,并从中抽取了六个特征图,所以这部分就分析下如何利用这六个特征图来得到最终的预测结果,也就是如何将它们用于分类预测和回归预测。
先回顾下 SSD 的预测流程:
- 为了获取预测框,首先要对六个特征图的每点处预设 default boxes,但预设的数量不是相同的,具体设置为
mbox=[4, 6, 6, 6, 4, 4],即在[conv4_3, conv10_2, conv11_2]的特征图每点设置 4 个 default boxes,在[conv7, conv8_2, conv9_2]的特征图每点设置 6 个 default boxes,根据特征图的尺寸feature_shape = [38x38, 19x19, 10x10, 5x5, 3x3, 1x1],容易计算出 default boxes 的数量为 8732 8732 8732,所以这本质上是密集采样。 - 其次对图像中的多个目标,需要判断预设的 default boxes 是否真实的包含目标以及目标的类别(分类预测);对真实包含目标的 default boxes,需要进行调整以获取最终的预测框(回归预测)。因此在获得特征图后需要再进行两个 3 × 3 3\times3 3×3 的卷积,分别用于回归预测和分类预测。
- 对于 分类预测,假设目标类别数为
num_classes,对于特征图 k,用到的 3 × 3 3\times3 3×3 卷积数为mbox[k] * num_classes; - 对于 回归预测,每个框由中心点 ( x , y ) (x,y) (x,y) 以及宽高 ( w , h ) (w,h) (w,h) 这四个参数决定,所以对于特征图 k,用到的 3 × 3 3\times3 3×3 卷积数为
mbox[k] * 4;
这里的卷积数即特征图经卷积之后的通道数。
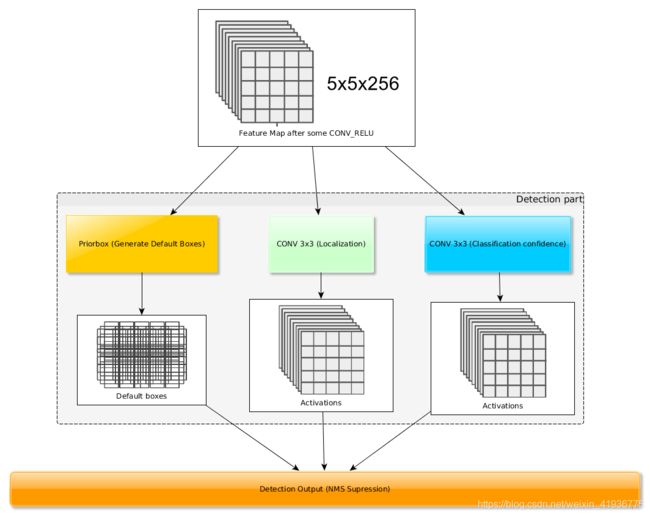
- 对于 分类预测,假设目标类别数为
因此我们可以计算出特征图经过回归和分类后所获得的预测框的尺寸:
| 特征层 | feature_shape | # def | 回归卷积 | 分类(21类)卷积 | 预测框 |
|---|---|---|---|---|---|
| conv4_3 | (38,38,512) | 4 | (38,38,16) | (38,38,84) | (38,38,16) |
| conv7 | (19,19,1024) | 6 | (19,19,24) | (19,19,126) | (19,19,24) |
| conv8_2 | (10,10,512) | 6 | (10,10,24) | (10,10,126) | (10,10,24) |
| conv9_2 | (5,5,256) | 6 | (5,5,24) | (5,5,126) | (5,5,24) |
| conv10_2 | (3,3,256) | 4 | (3,3,16) | (3,3,84) | (3,3,16) |
| conv11_2 | (1,1,256) | 4 | (1,1,16) | (1,1,84) | (1,1,16) |
2.1 db 的生成及可视化
default boxes 概念就不写了,但是不要忘记我们最后获得的预测框都是基于这些 default boxes 的,预测框的本质实际上就是对 default boxes 的调整。那么 SSD 中密密麻麻的 default boxes 是如何生成的呢?
首先给出这些 default boxes 的参数:
| layer | feature | min size | max size | step |
|---|---|---|---|---|
| conv4_3 | 38 × 38 38\times38 38×38 | 30 30 30 | 60 60 60 | 8 |
| conv7 | 19 × 19 19\times19 19×19 | 60 60 60 | 111 111 111 | 16 |
| conv8_2 | 10 × 10 10\times10 10×10 | 111 111 111 | 162 162 162 | 32 |
| conv9_2 | 5 × 5 5\times5 5×5 | 162 162 162 | 213 213 213 | 64 |
| conv10_2 | 3 × 3 3\times3 3×3 | 213 213 213 | 264 264 264 | 100 |
| conv11_2 | 1 × 1 1\times1 1×1 | 264 264 264 | 315 315 315 | 300 |
这里的 step 指的是输入图像的大小和特征图大小之间的比例,可以认为是特征图的缩放程度。
参数设置代码:ssd-pytorch-master\utils\config.py
Config = {
'num_classes': 21, # 训练前一定要修改num_classes,不然会出现shape不匹配!
# ----------------------------------------------------#
# min_dim有两个选择,一个是300、一个是512。
# 这里的SSD512不是原版的SSD512,原版的SSD512的比SSD300多一个预测层;
# 修改起来比较麻烦,所以up主只修改了输入大小,这样也可以用比较大的图片训练,对于小目标有好处;
# 当min_dim = 512时,'feature_maps': [64, 32, 16, 8, 6, 4]
# 当min_dim = 300时,'feature_maps': [38, 19, 10, 5, 3, 1]
# ----------------------------------------------------#
'min_dim': 300, # 'min_dim': 512,
'feature_maps': [38, 19, 10, 5, 3, 1], # 'feature_maps': [64, 32, 16, 8, 6, 4],
'steps': [8, 16, 32, 64, 100, 300], # 特征图相比原始输入图像的缩放尺度 300/38=7.89 近似=8
# ----------------------------------------------------#
# min_sizes、max_sizes可用于设定先验框的大小,默认的是根据voc数据集设定的,大多数情况下都是通用的!
# 如果想要检测小物体,可以修改,一般调小浅层先验框的大小就行了!因为浅层负责小物体检测!
# 比如min_sizes = [21,45,99,153,207,261],max_sizes = [45,99,153,207,261,315]
# ----------------------------------------------------#
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
# conv4_3,conv10_2,conv11_2 中去掉了宽高比为3和1/3的default box
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
参数设置完成后,就可以在特征图上设置 default boxes 了,这里需要注意的地方是:
- default boxes 的宽高比设置为
ar = {1, 2, 3, 1/2, 1/3},对应的宽和高分别计算为 w k = s k a r , h k = s k a r w_k=s_k\sqrt{a_r},\ h_k=\frac{s_k}{\sqrt{a_r}} wk=skar, hk=arsk;宽高比为 1 时另设一尺度为 s k ′ = s k s k + 1 s_k'=\sqrt{s_ks_{k+1}} sk′=sksk+1 的 default box,所以一共是 六种 尺度不同的 default box; [conv4_3, conv10_2, conv11_2]中去掉了宽高比为[3, 1/3]的两种 default box,即特征图每点处只有 4 个 default boxes;[conv7, conv8_2, conv9_2]的特征图中设置了 6 个 default boxes。
default boxes 生成代码:ssd-pytorch-master\utils\Vision_for_prior.py
from itertools import product
from math import sqrt
import matplotlib.pyplot as plt
import numpy as np
from utils.config import Config
# default boxes 的生成
mean = [] # 存储生成的 default boxes,即中心点,宽和高四个参数
for k, f in enumerate(Config["feature_maps"]): # 遍历特征图尺寸以获取 default boxes
x, y = np.meshgrid(np.arange(f), np.arange(f)) # 按照特征图尺寸将输入图像划分为网格,x,y 为点坐标
x = x.reshape(-1) # reshape 为一行
y = y.reshape(-1)
for i, j in zip(y, x):
# print(x,y)
# 300/8=37.5 四舍五入=38
f_k = Config["min_dim"] / Config["steps"][k] # 根据输入尺寸和 step 将第k个特征图划分为同等大小的网格区域
cx = (j + 0.5) / f_k # 计算每一个网格的中心
cy = (i + 0.5) / f_k
# 宽高比=1 对应两种 default boxes;
# 第一种是较小的正方形 default box
s_k = Config["min_sizes"][k] / Config["min_dim"]
mean += [cx, cy, s_k, s_k]
# 第二种是获得尺度为sqrt(s_k * s_k+1)的较大的正方形 default box
s_k_prime = sqrt(s_k * (Config["max_sizes"][k] / Config["min_dim"]))
mean += [cx, cy, s_k_prime, s_k_prime]
# 此外还有另外四种宽高比{2,3,1/2,1/3}对应的长方形 default boxes
for ar in Config["aspect_ratios"][k]:
mean += [cx, cy, s_k * sqrt(ar), s_k / sqrt(ar)]
mean += [cx, cy, s_k / sqrt(ar), s_k * sqrt(ar)]
mean = np.clip(mean, 0, 1) # 为避免 mean 中存储的参数超出[0,1]区间,因此将最大最小值指定为 1,0
# -1维代表 default[cx,cy,w,h],4 代表参数个数
mean = np.reshape(mean, [-1, 4]) * Config["min_dim"] # 将 default boxes 的比例转化为在图像中的真实大小
# 下面的内容是 3*3 特征图中 default boxes 的可视化
linx = np.linspace(0.5 * Config["steps"][4], Config["min_dim"] - 0.5 * Config["steps"][4], # [50,250] 以100为间隔
Config["feature_maps"][4])
liny = np.linspace(0.5 * Config["steps"][4], Config["min_dim"] - 0.5 * Config["steps"][4],
Config["feature_maps"][4])
print("linx:", linx)
print("liny:", liny)
centers_x, centers_y = np.meshgrid(linx, liny)
'''
centers_x = [[ 50. 150. 250.]
[ 50. 150. 250.]
[ 50. 150. 250.]]
centers_y = [[ 50. 50. 50.]
[150. 150. 150.]
[250. 250. 250.]]
'''
fig = plt.figure()
ax = fig.add_subplot(111)
plt.ylim(-100, 500)
plt.xlim(-100, 500)
plt.scatter(centers_x, centers_y)
step_start = 8708
step_end = 8712
# step_start = 8728
# step_end = 8732
box_widths = mean[step_start:step_end, 2]
box_heights = mean[step_start:step_end, 3]
prior_boxes = np.zeros_like(mean[step_start:step_end, :])
prior_boxes[:, 0] = mean[step_start:step_end, 0]
prior_boxes[:, 1] = mean[step_start:step_end, 1]
prior_boxes[:, 0] = mean[step_start:step_end, 0]
prior_boxes[:, 1] = mean[step_start:step_end, 1]
# 获得先验框的左上角和右下角
prior_boxes[:, 0] -= box_widths / 2
prior_boxes[:, 1] -= box_heights / 2
prior_boxes[:, 2] += box_widths / 2
prior_boxes[:, 3] += box_heights / 2
rect1 = plt.Rectangle([prior_boxes[0, 0], prior_boxes[0, 1]], box_widths[0], box_heights[0], color="r", fill=False)
rect2 = plt.Rectangle([prior_boxes[1, 0], prior_boxes[1, 1]], box_widths[1], box_heights[1], color="r", fill=False)
rect3 = plt.Rectangle([prior_boxes[2, 0], prior_boxes[2, 1]], box_widths[2], box_heights[2], color="r", fill=False)
rect4 = plt.Rectangle([prior_boxes[3, 0], prior_boxes[3, 1]], box_widths[3], box_heights[3], color="r", fill=False)
ax.add_patch(rect1)
ax.add_patch(rect2)
ax.add_patch(rect3)
ax.add_patch(rect4)
plt.show()
print(np.shape(mean))
下图是 3 × 3 3\times3 3×3 特征图中某一点处的四个 default boxes,两个正方形和两个长方形。

2.2 实现 分类 & 回归
实现代码:ssd-pytorch-master\nets\ssd.py --> get_ssd(phase, num_classes, confidence=0.5, nms_iou=0.45)。
def get_ssd(phase, num_classes, confidence=0.5, nms_iou=0.45):
'''
add_vgg指的是vgg主干特征提取网络 vgg(i),该网络的最后一个特征层是conv7后的结果,shape为19,19,1024
为了更好的提取出特征用于预测,SSD网络会继续进行下采样,add_extras是新增下采样的部分。
vgg,extra_layers分别是主干层和新增层的操作列表
'''
vgg, extra_layers = add_vgg(3), add_extras(1024)
loc_layers = [] # 存放用于回归的层
conf_layers = [] # 存放用于分类的层
# 对主干层的特征分类和回归
vgg_source = [21, -2]
'''
在add_vgg(3)获得的特征层里,第21层和-2层可以用来进行回归预测和分类预测,分别是conv4_3(38,38,512)和conv7(19,19,1024);
这是因为每个卷积层后还有一个激活层,所以conv4_3对应的是add_vgg[21],conv7对应的是add_vgg[-2];
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出下标和数据,一般用在for循环当中;
enumerate(vgg_source)=[(0,21),(1,-2)].
'''
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
mbox[k] * 4, kernel_size=3, padding=1)] #
conf_layers += [nn.Conv2d(vgg[v].out_channels, #
mbox[k] * num_classes, kernel_size=3, padding=1)]
'''
conv4_3(38,38,512):回归后输出(38,38,16),分类后输出(38,38,84)
conv7(19,19,1024):回归后输出(19,19,24),分类后输出(19,19,126)
'''
'''
对新增层的特征分类和回归;
在add_extras获得的特征层里,第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测:
feature_shape 分别为(10,10,512),(5,5,256),(3,3,256),(1,1,256)
'''
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, mbox[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, mbox[k]
* num_classes, kernel_size=3, padding=1)]
'''
add_vgg和add_extras,一共获得了6个有效特征层,shape分别为:
(38,38,512), (19,19,1024), (10,10,512), (5,5,256), (3,3,256), (1,1,256)
然后用SSD()将上面的层进行连接;
vgg, extra_layers, (loc_layers, conf_layers)存放的是每一层的卷积、激活、池化操作,注意是操作。
'''
SSD_MODEL = SSD(phase, vgg, extra_layers, (loc_layers, conf_layers), num_classes, confidence, nms_iou)
return SSD_MODEL
2.3 获取 分类 & 回归的结果
实现代码:ssd-pytorch-master\nets\ssd.py --> class SSD(nn.Module)
# 在该类中将vgg,extra_layers,loc_layers,conf_layers进行连接
# __init__()方法是类的“构造函数”,负责在对象初始化时进行一系列的构建操作
class SSD(nn.Module):
def __init__(self, phase, base, extras, head, num_classes, confidence, nms_iou):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = Config
self.vgg = nn.ModuleList(base) # ModuleList 可以使用一个forward存储多个model,这里是主干层
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras) # 新增层
self.priorbox = PriorBox(self.cfg)
with torch.no_grad():
self.priors = Variable(self.priorbox.forward())
self.loc = nn.ModuleList(head[0]) # 回归层
self.conf = nn.ModuleList(head[1]) # 分类层
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, confidence, nms_iou)
# 该函数进行卷积层的连接
def forward(self, x):
sources = list() # 存储有效特征层的输出
loc = list() # 存储回归结果
conf = list() # 存储分类结果
# 不断进行卷积,直到获得conv4_3, shape为(38,38,512)
for k in range(23): # Pooling4 之前的层:卷积+激活+池化
x = self.vgg[k](x)
# conv4_3的内容需要进行L2标准化,目的是获得更好的结果,然后将L2标准化后的conv4_3的输出添加到sources中
s = self.L2Norm(x)
sources.append(s)
'''
继续进行卷积直到获得conv7, shape为(19,19,1024);
conv7是vgg(i)的倒数第二层,因此从23层开始--> 倒数第二层len(self.vgg);
然后将conv7的输出添加到sources中.
'''
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
'''
在add_extras获得的特征层里,第1层、第3层、第5层、第7层可以用来进行回归预测和分类预测;
shape分别为(10,10,512), (5,5,256), (3,3,256), (1,1,256);
由于add_extras(i, batch_norm=False)中没有进行激活操作,所以这里要进行ReLU.
'''
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
'''
使用loc_layers和conf_layers对获得的6个有效特征层进行回归预测和分类预测,将结果添加到loc和conf中;
zip()返回打包为元组的列表,将回归层和分类层分别添加到loc、conf中;
permute()实现维度换位. Pytorch中数据以NCHW存储,为了方便处理换位为NHWC,通道数放在最后;
contiguous()把数据变成在内存中连续分布的形式.
'''
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
'''
view(m,n=-1)函数作用是调整Tensor形状,拼接成m行,-1是自适应调整;
横着拼接:torch.cat((A,B),1);竖着拼接:torch.cat((A,B),0);
整体目的是进行reshape方便堆叠.
'''
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
'''
loc 会 reshape 为(batch_size,num_anchors,4),表示每张特征图中每个default box的调整参数;
conf 会 reshape 为(batch_size,num_anchors,self.num_classes,表示每张特征图中每个default box的种类;
如果用于预测的话,会添加上detect用于对先验框解码,获得预测结果;
不用于预测的话,直接返回网络的回归预测结果和分类预测结果用于训练.
'''
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc predicts
self.softmax(conf.view(conf.size(0), -1, self.num_classes)), # conf predicts
self.priors
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes), #
self.priors
)
return output
3. 特征解码:从预测结果中得到预测框
前面已经介绍了 default boxes 的生成以及如何利用这些 default boxes 进行回归和分类预测,下一步就是从回归和分类的结果中将预测框提取出来。经过层层卷积,回归和分类的预测结果是以特征的形式存储的,而我们希望最终展现在图像上的是边框的形式,所以可以把获取预测框的过程理解为特征的解码。
在上一段代码的最后提到,如果将回归和分类的结果用于预测,那么就需要调用 Detect 这个层,该层实际上的作用就是将回归和分类的结果进行解码,从而获得预测框。
实现代码:ssd-pytorch-master\nets\ssd_layers.py --> class Detect(Function)
class Detect(Function):
def __init__(self, num_classes, bkg_label, top_k, conf_thresh, nms_thresh):
self.num_classes = num_classes
self.background_label = bkg_label
self.top_k = top_k
self.nms_thresh = nms_thresh
if nms_thresh <= 0:
raise ValueError('nms_threshold must be non negative.')
self.conf_thresh = conf_thresh
self.variance = Config['variance']
# loc_data为回归预测结果, conf_data为分类预测结果, prior_data为先验框
def forward(self, loc_data, conf_data, prior_data):
# --------------------------------#
# 先转换成cpu下运行
# --------------------------------#
loc_data = loc_data.cpu()
conf_data = conf_data.cpu()
# --------------------------------#
# num的值为batch_size,传入图像的数量,一般传入一张
# num_priors为先验框的数量 ssd300:8732
# --------------------------------#
num = loc_data.size(0)
num_priors = prior_data.size(0)
# 用于存放输出,eg:(1,21,top_k,5)
output = torch.zeros(num, self.num_classes, self.top_k, 5)
# --------------------------------------#
# 将分类预测结果reshape为(num,num_priors,self.num_classes),eg:(1,8732,21)
# 再进行转置,eg:(1,21,8732)
# --------------------------------------#
conf_preds = conf_data.view(num, num_priors, self.num_classes).transpose(2, 1)
# 对每一张图片进行处理
# 正常预测的时候只有一张图片,所以只会循环一次
for i in range(num):
# --------------------------------------#
# 利用回归预测结果对先验框解码(或者说是调整)获得预测框
# 解码后,获得的结果的shape为 (num_priors, 4)
# --------------------------------------#
decoded_boxes = decode(loc_data[i], prior_data, self.variance) # 调整后的先验框
conf_scores = conf_preds[i].clone() # 取出类别得分
# --------------------------------------#
# 获得每一个类对应的分类结果
# num_priors,
# --------------------------------------#
for cl in range(1, self.num_classes):
# --------------------------------------#
# 对每一类进行非极大值抑制NMS
# 首先利用阈值进行判断,然后取出阈值满足的得分
# 目的是去除重叠或得分低的先验框,保留得分高(即最精确)的框
# --------------------------------------#
c_mask = conf_scores[cl].gt(self.conf_thresh)
scores = conf_scores[cl][c_mask]
if scores.size(0) == 0:
continue
l_mask = c_mask.unsqueeze(1).expand_as(decoded_boxes)
# --------------------------------------#
# 将满足阈值的预测框取出来,-1的作用是动态调整
# --------------------------------------#
boxes = decoded_boxes[l_mask].view(-1, 4)
# --------------------------------------#
# 利用这些预测框进行非极大抑制,top_k=200
# --------------------------------------#
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
output[i, cl, :count] = torch.cat((scores[ids[:count]].unsqueeze(1), boxes[ids[:count]]), 1)
return output
这里涉及到 ssd-pytorch-master\utils\box_utils.py 中的两个方法:
解码函数 decode()
# -------------------------------------------------------------------#
# Adapted from https://github.com/Hakuyume/chainer-ssd
# 利用预测结果对先验框进行调整:
# 前两个参数用于调整中心的xy轴坐标,后两个参数用于调整先验框宽高
# priors[:, :2]表示先验框的中心,loc[:, :2]预测结果的中心,priors[:, 2:]先验框的长和宽
# variances=[0.1,0.2]
# -------------------------------------------------------------------#
def decode(loc, priors, variances):
boxes = torch.cat((
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:], # 调整后的中心
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1) # 调整后的宽高
boxes[:, :2] -= boxes[:, 2:] / 2 # 计算框的左上角
boxes[:, 2:] += boxes[:, :2] # 计算框的右下角
return boxes
非极大值抑制函数 nms()
# 该部分用于进行非极大抑制,即筛选出一定区域内得分最大的框。
# -------------------------------------------------------------------#
def nms(boxes, scores, overlap=0.5, top_k=200):
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0:
return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0)
idx = idx[-top_k:]
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
count = 0
while idx.numel() > 0:
i = idx[-1]
keep[count] = i
count += 1
if idx.size(0) == 1:
break
idx = idx[:-1]
torch.index_select(x1, 0, idx, out=xx1)
torch.index_select(y1, 0, idx, out=yy1)
torch.index_select(x2, 0, idx, out=xx2)
torch.index_select(y2, 0, idx, out=yy2)
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w * h
rem_areas = torch.index_select(area, 0, idx)
union = (rem_areas - inter) + area[i]
IoU = inter / union
idx = idx[IoU.le(overlap)]
return keep, count
4. 预测过程及效果展示
实现代码:ssd-pytorch-master\predict.py
"""
predict.py有几个注意点
1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
具体流程可以参考get_dr_txt.py,在get_dr_txt.py即实现了遍历还实现了目标信息的保存。
2、如果想要进行检测完的图片的保存,利用r_image.save("img.jpg")即可保存,直接在predict.py里进行修改即可。
3、如果想要获得预测框的坐标,可以进入detect_image函数,在绘图部分读取top,left,bottom,right这四个值。
4、如果想要利用预测框截取下目标,可以进入detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值
在原图上利用矩阵的方式进行截取。
5、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入detect_image函数,在绘图部分对predicted_class进行判断,
比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。
"""
from PIL import Image
from ssd import SSD
ssd = SSD()
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = ssd.detect_image(image)
# r_image.save("img.jpg")
r_image.show()
4.1 CPU 预测效果展示
在运行该文件之前,首先需要下载权值文件 ssd_wights.pth 并将其放在 model_data 下:
训练所需的ssd_weights.pth可以在百度云下载。
链接: https://pan.baidu.com/s/1ltXCkuSxKRJUsLi0IoBg2A
提取码: uqnw
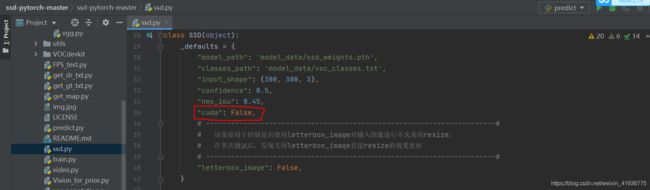
然后运行 predict.py 文件,输入img/street.jpg 就可以得到一张检测后的图像。如果环境不是 GPU 的话,需要进行如下改动才能成功预测:
- 将
ssd-pytorch-master\ssd.py中的'cuda': True更改为'cuda': False;
- 然后修改
ssd-pytorch-master\nets\ssd_layers.py中的Detect类。目的是为了避免报错:
RuntimeError: Legacy autograd function with non-static forward method is deprecated. Please use new-style autograd function with static forward method.
- 报错原因在于 PyTorch在1.3版本及之后,规定 forward 方法必须是静态方法,而原代码中
Detect类的forward方法并不是静态方法,所以需要进行部分修改;- 首先修改
forward方法,该方法内只需进行部分改动(下图蓝色背景内的),剩余没有贴出来的代码就是不需要改动的。@staticmethod作用就是将forward方法注册为静态方法;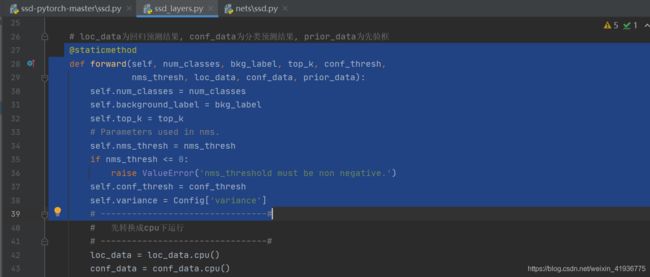
- 其次修改调用
Detect类的代码,即ssd-pytorch-master\nets\ssd.py中的两个地方:

- 首先修改
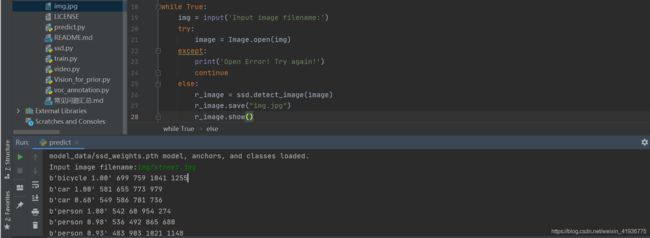
这样在 CPU 环境下也可以进行预测了。看下运行结果:
关于上面的代码修改,大家可以参考 Single-Shot-Object-Detection-Updated 这里面的代码修改自己的。配置不同的情况下,可能大家出的问题也不相同,多百度多查资料总会解决的。
4.2 实际预测过程
实现代码:ssd-master-pytorch\ssd.py
# --------------------------------------------#
# 使用自己训练好的模型预测需要修改2个参数
# model_path和classes_path都需要修改!
# 如果出现shape不匹配,一定要注意训练时的config里面的
# num_classes、model_path和classes_path参数的修改
# --------------------------------------------#
class SSD(object):
# 初始化参数
_defaults = {
"model_path": 'model_data/ssd_weights.pth', # 训练好的权值存放路径
"classes_path": 'model_data/voc_classes.txt', # 数据集的分类
"input_shape": (300, 300, 3),
"confidence": 0.5,
"nms_iou": 0.45,
"cuda": False, # False表示CPU,True即GPU
# ---------------------------------------------------------------------#
# 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize,
# 在多次测试后,发现关闭letterbox_image直接resize的效果更好
# ---------------------------------------------------------------------#
"letterbox_image": False,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults: # 判断参数是否在初始化字典中
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
# ---------------------------------------------------#
# 初始化SSD
# ---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
self.class_names = self._get_class()
self.generate()
# ---------------------------------------------------#
# 获得所有的分类
# ---------------------------------------------------#
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
# ---------------------------------------------------#
# 载入模型
# ---------------------------------------------------#
def generate(self):
# -------------------------------#
# 计算总的类的数量
# -------------------------------#
self.num_classes = len(self.class_names) + 1
# -------------------------------#
# 载入模型与权值
# -------------------------------#
model = ssd.get_ssd("test", self.num_classes, self.confidence, self.nms_iou)
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.load_state_dict(torch.load(self.model_path, map_location=device))
self.net = model.eval()
if self.cuda:
self.net = torch.nn.DataParallel(self.net)
cudnn.benchmark = True
self.net = self.net.cuda()
print('{} model, anchors, and classes loaded.'.format(self.model_path))
# 画框设置不同的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
# ---------------------------------------------------#
# 检测图片
# ---------------------------------------------------#
def detect_image(self, image):
image_shape = np.array(np.shape(image)[0:2]) # 默认(300,300,3)
# ---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别,上面说不添加灰条时效果反而更好。。
# ---------------------------------------------------------#
if self.letterbox_image:
crop_img = np.array(letterbox_image(image, (self.input_shape[1], self.input_shape[0])))
else:
crop_img = image.convert('RGB')
crop_img = crop_img.resize((self.input_shape[1], self.input_shape[0]), Image.BICUBIC)
photo = np.array(crop_img, dtype=np.float64) # 将图像转化为numpy.array形式
with torch.no_grad():
# ---------------------------------------------------#
# 图片预处理,photo - MEANS 归一化,
# transpose调整存储方式,把NHWC转变为NCHW,
# ---------------------------------------------------#
photo = Variable(
torch.from_numpy(np.expand_dims(np.transpose(photo - MEANS, (2, 0, 1)), 0)).type(torch.FloatTensor))
if self.cuda:
photo = photo.cuda()
# ---------------------------------------------------#
# 传入网络进行预测,因为在模型中添加了detect和nms
# 所以这里的preds是经过处理的
# ---------------------------------------------------#
preds = self.net(photo)
top_conf = []
top_label = []
top_bboxes = []
# ---------------------------------------------------#
# preds的shape为 1, num_classes, top_k, 5
# 表示在num_classes中得分最高的top_k个框的5个参数
# 下面进行置信度筛选
# ---------------------------------------------------#
for i in range(preds.size(1)): # 遍历所有类,i=0即背景
j = 0
while preds[0, i, j, 0] >= self.confidence:
# ---------------------------------------------------#
# score为当前预测框的得分,大于0.5就保留该框
# label_name为预测框的种类
# ---------------------------------------------------#
score = preds[0, i, j, 0]
label_name = self.class_names[i - 1]
# ---------------------------------------------------#
# pt的shape为4, 当前预测框的左上角右下角
# ---------------------------------------------------#
pt = (preds[0, i, j, 1:]).detach().numpy()
coords = [pt[0], pt[1], pt[2], pt[3]]
top_conf.append(score) # 保留得分
top_label.append(label_name) # 保留标签
top_bboxes.append(coords) # 保留预测框(也就是坐标值)
j = j + 1
# -------------------------------------#
# 如果不存在满足阈值的预测框,直接返回原图
# 也就是那些先验框中并没有真实包含物体
# -------------------------------------#
if len(top_conf) <= 0:
return image
# -------------------------------------#
# 对结果进行解码
# -------------------------------------#
top_conf = np.array(top_conf)
top_label = np.array(top_label)
top_bboxes = np.array(top_bboxes)
top_xmin, top_ymin, top_xmax, top_ymax = np.expand_dims(top_bboxes[:, 0], -1), np.expand_dims(top_bboxes[:, 1],
-1), np.expand_dims(
top_bboxes[:, 2], -1), np.expand_dims(top_bboxes[:, 3], -1)
# -----------------------------------------------------------#
# 去掉灰条部分
# -----------------------------------------------------------#
if self.letterbox_image:
boxes = ssd_correct_boxes(top_ymin, top_xmin, top_ymax, top_xmax,
np.array([self.input_shape[0], self.input_shape[1]]), image_shape)
else:
top_xmin = top_xmin * image_shape[1]
top_ymin = top_ymin * image_shape[0]
top_xmax = top_xmax * image_shape[1]
top_ymax = top_ymax * image_shape[0]
boxes = np.concatenate([top_ymin, top_xmin, top_ymax, top_xmax], axis=-1)
# -----------------------------------------------------------#
# 绘图代码
# -----------------------------------------------------------#
font = ImageFont.truetype(font='model_data/simhei.ttf',
size=np.floor(3e-2 * np.shape(image)[1] + 0.5).astype('int32'))
thickness = max((np.shape(image)[0] + np.shape(image)[1]) // self.input_shape[0], 1)
for i, c in enumerate(top_label):
predicted_class = c
score = top_conf[i]
# -----------------------------------------------------------#
# 预测框的位置
# -----------------------------------------------------------#
top, left, bottom, right = boxes[i]
top = top - 5
left = left - 5
bottom = bottom + 5
right = right + 5
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(np.shape(image)[0], np.floor(bottom + 0.5).astype('int32'))
right = min(np.shape(image)[1], np.floor(right + 0.5).astype('int32'))
# 画框框
label = '{} {:.2f}'.format(predicted_class, score) # 标签
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font) # 标签大小
label = label.encode('utf-8')
print(label, top, left, bottom, right)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[self.class_names.index(predicted_class)])
draw.rectangle(
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[self.class_names.index(predicted_class)])
draw.text(text_origin, str(label, 'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image
二、训练
1. gt box与default boxes的匹配过程
根据论文内容,在训练时首先需要确定图像中的每一个 gt box 与哪些 default boxes 是相匹配的,那么这个 gt box 包含的目标就由这些 default boxes 负责检测出来。
在匹配结束后,我们就可以依照 gt box 来调整这些 default boxes 从而获得预测框,那么 从 gt boxes 到获得预测框的这一过程就是编码过程。
在上一部分我们提到了解码,即从 SSD 的预测结果提取预测框的真实位置信息,这两个过程是互逆的。
实现代码:ssd-master-pytorch\utils\box_utils.py
def jaccard(box_a, box_b):
# -------------------------------------#
# 返回的inter的shape为[A,B]
# 代表每一个真实框和先验框的交矩形
# -------------------------------------#
inter = intersect(box_a, box_b)
# -------------------------------------#
# 计算先验框和真实框各自的面积
# -------------------------------------#
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2] - box_b[:, 0]) *
(box_b[:, 3] - box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
# -------------------------------------#
# 每一个真实框和先验框的交并比IoU[A,B]
# -------------------------------------#
return inter / union
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
# ----------------------------------------------#
# 计算所有的先验框和真实框的重合程度
# ----------------------------------------------#
overlaps = jaccard(
truths,
point_form(priors)
)
# ----------------------------------------------#
# 所有真实框和先验框的最好重合程度
# best_prior_overlap [truth_box,1]
# best_prior_idx [truth_box,0]
# ----------------------------------------------#
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# ----------------------------------------------#
# 所有先验框和真实框的最好重合程度
# best_truth_overlap [1,prior]
# best_truth_idx [1,prior]
# ----------------------------------------------#
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
# ----------------------------------------------#
# 用于保证每个真实框都至少有对应的一个先验框
# ----------------------------------------------#
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
# ----------------------------------------------#
# 获取每一个先验框对应的真实框[num_priors,4]
# ----------------------------------------------#
matches = truths[best_truth_idx]
# Shape: [num_priors]
conf = labels[best_truth_idx] + 1
# ----------------------------------------------#
# 如果重合程度小于threshold则认为是背景
# ----------------------------------------------#
conf[best_truth_overlap < threshold] = 0
# ----------------------------------------------#
# 利用真实框和先验框进行编码
# 编码后的结果就是网络应该有的预测结果
# ----------------------------------------------#
loc = encode(matches, priors, variances)
# [num_priors,4]
loc_t[idx] = loc
# [num_priors]
conf_t[idx] = conf
def encode(matched, priors, variances):
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
g_cxcy /= (variances[0] * priors[:, 2:])
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh) / variances[1]
return torch.cat([g_cxcy, g_wh], 1)
2. 计算损失函数
在得到预测结果后,我们就可以利用 gt boxes 来计算损失函数了。根据论文内容,SSD 的损失函数是由位置损失loc_l 和 置信度损失loc_c的加权和组成的,因此在计算损失时要注意两个损失之间的差异。其次是针对正负样本不均衡的问题需要采用难负例挖掘策略,也就是需要限制负样本的数量。
实现代码:ssd-master-pytorch\nets\ssd_training.py --> class MultiBoxLoss()
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
use_gpu=True, negatives_for_hard=100.0):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.negatives_for_hard = negatives_for_hard
self.variance = Config['variance']
def forward(self, predictions, targets):
# --------------------------------------------------#
# 取出预测结果的三个值:回归信息,置信度,先验框
# --------------------------------------------------#
loc_data, conf_data, priors = predictions
# --------------------------------------------------#
# 计算出batch_size(传入的图像数量)和先验框的数量
# --------------------------------------------------#
num = loc_data.size(0)
num_priors = (priors.size(0))
# --------------------------------------------------#
# 创建一个tensor进行处理
# --------------------------------------------------#
loc_t = torch.zeros(num, num_priors, 4).type(torch.FloatTensor)
conf_t = torch.zeros(num, num_priors).long()
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
priors = priors.cuda()
for idx in range(num):
# 从targets中传入真实框与标签
truths = targets[idx][:, :-1]
labels = targets[idx][:, -1]
if len(truths) == 0:
continue
# 传入先验框
defaults = priors
# --------------------------------------------------#
# 利用真实框和先验框进行匹配。
# 如果真实框和先验框的重合度较高,则认为匹配上了。
# 该先验框用于负责检测出该真实框。
# --------------------------------------------------#
match(self.threshold, truths, defaults, self.variance, labels, loc_t, conf_t, idx)
# --------------------------------------------------#
# 转化成Variable
# loc_t (num, num_priors, 4)
# conf_t (num, num_priors)
# --------------------------------------------------#
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
# 所有conf_t>0的地方,代表内部包含物体
pos = conf_t > 0
# --------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# num_pos (num, )
# --------------------------------------------------#
num_pos = pos.sum(dim=1, keepdim=True)
# --------------------------------------------------#
# 取出所有的正样本,并计算loss
# pos_idx (num, num_priors, 4)
# --------------------------------------------------#
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False) # smoothL1,仅使用正样本
# --------------------------------------------------#
# batch_conf (num * num_priors, num_classes)
# loss_c (num, num_priors)
# --------------------------------------------------#
batch_conf = conf_data.view(-1, self.num_classes)
# 这个地方是在寻找难分类的先验框
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
loss_c = loss_c.view(num, -1)
# 难分类的先验框不把正样本考虑进去,只考虑难分类的负样本
loss_c[pos] = 0
# --------------------------------------------------#
# loss_idx (num, num_priors)
# idx_rank (num, num_priors)
# --------------------------------------------------#
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
# --------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# num_pos (num, )
# neg (num, num_priors)
# --------------------------------------------------#
num_pos = pos.long().sum(1, keepdim=True)
# 限制负样本数量
num_neg = torch.clamp(self.negpos_ratio * num_pos, max=pos.size(1) - 1)
num_neg[num_neg.eq(0)] = self.negatives_for_hard
neg = idx_rank < num_neg.expand_as(idx_rank)
# --------------------------------------------------#
# 求和得到每一个图片内部有多少正样本
# pos_idx (num, num_priors, num_classes)
# neg_idx (num, num_priors, num_classes)
# --------------------------------------------------#
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 选取出用于训练的正样本与负样本,计算loss
conf_p = conf_data[(pos_idx + neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos + neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
N = torch.max(num_pos.data.sum(), torch.ones_like(num_pos.data.sum()))
# 归一化
loss_l /= N
loss_c /= N
return loss_l, loss_c
3. 整体训练过程
3.1 数据增强
实现代码:ssd-master-pytorch\nets\ssd_training.py --> class Generator()
class Generator(object):
def __init__(self, batch_size,
lines, image_size, num_classes,
):
self.batch_size = batch_size
self.lines = lines
self.image_size = image_size
self.num_classes = num_classes - 1
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5, random=True):
"""
实时数据增强的随机预处理
能够增强模型的鲁棒性,即对不同大小,形状的目标都能很好的进行检测
"""
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]])
if not random:
# resize image
scale = min(w / iw, h / ih)
nw = int(iw * scale)
nh = int(ih * scale)
dx = (w - nw) // 2
dy = (h - nh) // 2
image = image.resize((nw, nh), Image.BICUBIC)
new_image = Image.new('RGB', (w, h), (128, 128, 128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image, np.float32)
# correct boxes
box_data = np.zeros((len(box), 5))
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)]
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
return image_data, box_data
# 调整图片大小
new_ar = w / h * rand(1 - jitter, 1 + jitter) / rand(1 - jitter, 1 + jitter)
scale = rand(.25, 2)
if new_ar < 1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
# 放置图片
dx = int(rand(0, w - nw))
dy = int(rand(0, h - nh))
new_image = Image.new('RGB', (w, h),
(np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255)))
new_image.paste(image, (dx, dy))
image = new_image
# 是否翻转图片 以0.5的概率水平翻转图像
flip = rand() < .5
if flip:
image = image.transpose(Image.FLIP_LEFT_RIGHT)
# 色域变换
hue = rand(-hue, hue)
sat = rand(1, sat) if rand() < .5 else 1 / rand(1, sat)
val = rand(1, val) if rand() < .5 else 1 / rand(1, val)
x = cv2.cvtColor(np.array(image, np.float32) / 255, cv2.COLOR_RGB2HSV)
x[..., 0] += hue * 360
x[..., 0][x[..., 0] > 1] -= 1
x[..., 0][x[..., 0] < 0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x[:, :, 0] > 360, 0] = 360
x[:, :, 1:][x[:, :, 1:] > 1] = 1
x[x < 0] = 0
image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB) * 255
# 调整目标框坐标
box_data = np.zeros((len(box), 5))
if len(box) > 0:
np.random.shuffle(box)
box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dx
box[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dy
if flip:
box[:, [0, 2]] = w - box[:, [2, 0]]
box[:, 0:2][box[:, 0:2] < 0] = 0
box[:, 2][box[:, 2] > w] = w
box[:, 3][box[:, 3] > h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w > 1, box_h > 1)] # 保留有效框
box_data = np.zeros((len(box), 5))
box_data[:len(box)] = box
return image_data, box_data
3.2 数据集的生成
实现代码:ssd-master-pytorch\nets\ssd_training.py --> class Generator()
def generate(self, train=True):
while True:
shuffle(self.lines) # 当所有行均被读取后,对行进行打乱
lines = self.lines
inputs = []
targets = []
for annotation_line in lines:
if train: # 将那些行传入到这个函数进行实时数据增强
img, y = self.get_random_data(annotation_line, self.image_size[0:2])
else:
img, y = self.get_random_data(annotation_line, self.image_size[0:2], random=False)
# 将框的位置参数转化为小数形式
boxes = np.array(y[:, :4], dtype=np.float32)
boxes[:, 0] = boxes[:, 0] / self.image_size[1]
boxes[:, 1] = boxes[:, 1] / self.image_size[0]
boxes[:, 2] = boxes[:, 2] / self.image_size[1]
boxes[:, 3] = boxes[:, 3] / self.image_size[0]
boxes = np.maximum(np.minimum(boxes, 1), 0)
y = np.concatenate([boxes, y[:, -1:]], axis=-1)
inputs.append(np.transpose(img - MEANS, (2, 0, 1))) # 将操作后的图像添加到inputs中
targets.append(y) # 将操作后的标签添加到targets中
if len(targets) == self.batch_size:
tmp_inp = np.array(inputs) # 将图像转化为numpy数组
tmp_targets = targets
inputs = []
targets = []
yield tmp_inp, tmp_targets
3.3 训练
实行代码:ssd-master-pytorch\train.py
import time
import warnings
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.nn.init as init
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchsummary import summary
from tqdm import tqdm
from nets.ssd import get_ssd
from nets.ssd_training import Generator, MultiBoxLoss
from utils.config import Config
from utils.dataloader import SSDDataset, ssd_dataset_collate
warnings.filterwarnings("ignore")
# ------------------------------------------------------------------------#
# 这里看到的train.py和视频上不太一样
# up主重构了一下train.py,添加了验证集,这样训练的时候可以有个参考。
# 训练前注意在config.py里面修改num_classes
# 训练世代、学习率、批处理大小等参数在本代码靠下的if True:内进行修改。
# -------------------------------------------------------------------------#
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_epoch(net, criterion, epoch, epoch_size, epoch_size_val, gen, genval, Epoch, cuda):
loc_loss = 0
conf_loss = 0
loc_loss_val = 0
conf_loss_val = 0
net.train()
print('Start Train')
with tqdm(total=epoch_size, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen): # 对 batch 进行遍历
if iteration >= epoch_size: # 最大迭代次数超过世代数时直接跳出循环
break
images, targets = batch[0], batch[1] # 取出对应的图片和标签
with torch.no_grad():
# 将图片和标签转化为变量形式
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)).cuda() for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
# ----------------------#
# 前向传播,将图像传入到网络中
# ----------------------#
out = net(images)
# ----------------------#
# 清零梯度
# ----------------------#
optimizer.zero_grad()
# ----------------------#
# 计算损失:位置损失+置信度损失
# ----------------------#
loss_l, loss_c = criterion(out, targets)
loss = loss_l + loss_c
# ----------------------#
# 反向传播
# ----------------------#
loss.backward()
optimizer.step()
loc_loss += loss_l.item()
conf_loss += loss_c.item()
pbar.set_postfix(**{'loc_loss': loc_loss / (iteration + 1),
'conf_loss': conf_loss / (iteration + 1),
'lr': get_lr(optimizer)})
pbar.update(1)
net.eval()
print('Start Validation')
with tqdm(total=epoch_size_val, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
for iteration, batch in enumerate(genval):
if iteration >= epoch_size_val:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)).cuda() for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
out = net(images)
optimizer.zero_grad()
loss_l, loss_c = criterion(out, targets)
loc_loss_val += loss_l.item()
conf_loss_val += loss_c.item()
pbar.set_postfix(**{'loc_loss': loc_loss_val / (iteration + 1),
'conf_loss': conf_loss_val / (iteration + 1),
'lr': get_lr(optimizer)})
pbar.update(1)
# 打印训练过程
# 每经一个epoch,保存一次训练的权重
total_loss = loc_loss + conf_loss
val_loss = loc_loss_val + conf_loss_val
print('Finish Validation')
print('Epoch:' + str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.4f || Val Loss: %.4f ' % (total_loss / (epoch_size + 1), val_loss / (epoch_size_val + 1)))
print('Saving state, iter:', str(epoch + 1))
torch.save(model.state_dict(), 'logs/Epoch%d-Total_Loss%.4f-Val_Loss%.4f.pth' % (
(epoch + 1), total_loss / (epoch_size + 1), val_loss / (epoch_size_val + 1)))
# ----------------------------------------------------#
# 检测精度mAP和pr曲线计算参考视频
# https://www.bilibili.com/video/BV1zE411u7Vw
# ----------------------------------------------------#
if __name__ == "__main__":
# -------------------------------#
# 是否使用Cuda:没有GPU可以设置成False
# -------------------------------#
Cuda = True
# -------------------------------#
# Dataloder的使用
# -------------------------------#
Use_Data_Loader = True
model = get_ssd("train", Config["num_classes"])
# ------------------------------------------------------#
# 载入预训练好的权值文件,看README,百度网盘下载
# 能够加快模型的训练(迁移学习的思想)
# ------------------------------------------------------#
model_path = "model_data/ssd_weights.pth"
print('Loading weights into state dict...')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
annotation_path = '2007_train.txt' # 存放了图像的信息
# ----------------------------------------------------------------------#
# 验证集的划分在train.py代码里面进行
# 2007_test.txt和2007_val.txt里面没有内容是正常的。训练不会使用到。
# 当前划分方式下,验证集和训练集的比例为1:9
# ----------------------------------------------------------------------#
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines) # 将数据乱序
np.random.seed(None)
num_val = int(len(lines) * val_split)
num_train = len(lines) - num_val
# 损失函数
criterion = MultiBoxLoss(Config['num_classes'], 0.5, True, 0, True, 3, 0.5, False, Cuda)
net = model.train()
if Cuda:
net = torch.nn.DataParallel(model) # 用多个GPU来加速训练
cudnn.benchmark = True # 增加程序运行效率
net = net.cuda()
# ------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以加快训练速度
# 也可以在训练初期防止权值被破坏。
# Init_Epoch为起始世代
# Freeze_Epoch为冻结训练的世代
# Unfreeze_Epoch总训练世代
# 提示OOM或者显存不足请调小Batch_size
# ------------------------------------------------------#
if True:
lr = 5e-4
Batch_size = 16
Init_Epoch = 0
Freeze_Epoch = 50
optimizer = optim.Adam(net.parameters(), lr=lr) # 优化器
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.92) # 设置学习率变化规律
if Use_Data_Loader:
train_dataset = SSDDataset(lines[:num_train], (Config["min_dim"], Config["min_dim"]), True)
gen = DataLoader(train_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=ssd_dataset_collate)
val_dataset = SSDDataset(lines[num_train:], (Config["min_dim"], Config["min_dim"]), False)
gen_val = DataLoader(val_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=ssd_dataset_collate)
else:
# Generator会利用2007_train.txt生成需要的图像和标签,即数据集
gen = Generator(Batch_size, lines[:num_train], (Config["min_dim"], Config["min_dim"]),
Config["num_classes"]).generate(True)
gen_val = Generator(Batch_size, lines[num_train:], (Config["min_dim"], Config["min_dim"]),
Config["num_classes"]).generate(False)
for param in model.vgg.parameters():
param.requires_grad = False
epoch_size = num_train // Batch_size
epoch_size_val = num_val // Batch_size
for epoch in range(Init_Epoch, Freeze_Epoch):
fit_one_epoch(net, criterion, epoch, epoch_size, epoch_size_val, gen, gen_val, Freeze_Epoch, Cuda)
lr_scheduler.step()
if True:
lr = 1e-4
Batch_size = 8
Freeze_Epoch = 50
Unfreeze_Epoch = 100
optimizer = optim.Adam(net.parameters(), lr=lr)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.92)
if Use_Data_Loader:
train_dataset = SSDDataset(lines[:num_train], (Config["min_dim"], Config["min_dim"]), True)
gen = DataLoader(train_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=ssd_dataset_collate)
val_dataset = SSDDataset(lines[num_train:], (Config["min_dim"], Config["min_dim"]), False)
gen_val = DataLoader(val_dataset, shuffle=True, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=ssd_dataset_collate)
else:
gen = Generator(Batch_size, lines[:num_train], (Config["min_dim"], Config["min_dim"]),
Config["num_classes"]).generate(True)
gen_val = Generator(Batch_size, lines[num_train:], (Config["min_dim"], Config["min_dim"]),
Config["num_classes"]).generate(False)
for param in model.vgg.parameters():
param.requires_grad = True
epoch_size = num_train // Batch_size
epoch_size_val = num_val // Batch_size
for epoch in range(Freeze_Epoch, Unfreeze_Epoch):
fit_one_epoch(net, criterion, epoch, epoch_size, epoch_size_val, gen, gen_val, Unfreeze_Epoch, Cuda)
lr_scheduler.step()
三、训练自己的 SSD
1. 构造数据集
这部分是依照 VOC 的格式,用了自己找的肿瘤图像来构造数据集:

-
Annotations 文件夹:存放标签文件。主要关注红框中的内容,包括需要检测的类别名称 LST,以及边界框位置信息。
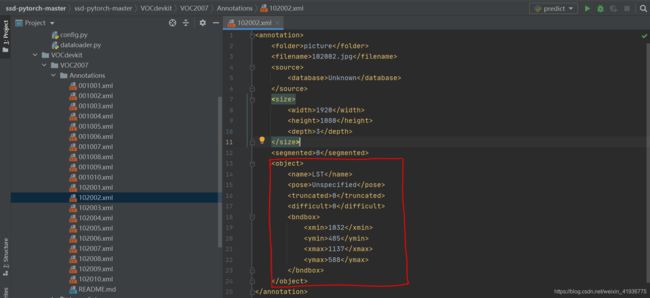
-
JPEGImages:存放图像文件。
-
ImageSets/Main:存放索引文件,即标签文件和图像文件的名称。主要关注
train.txt,这里的索引文件是由voc2ssd.py生成的。如果运行后提示:
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: './VOCdevkit/VOC2007/Annotations'
这是pycharm运行目录的问题,最简单的方法是将该文件复制到根目录后运行。
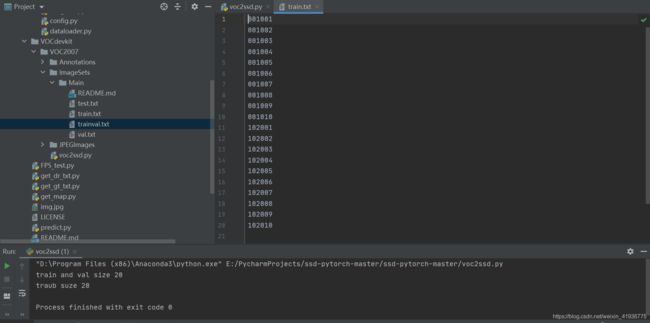
-
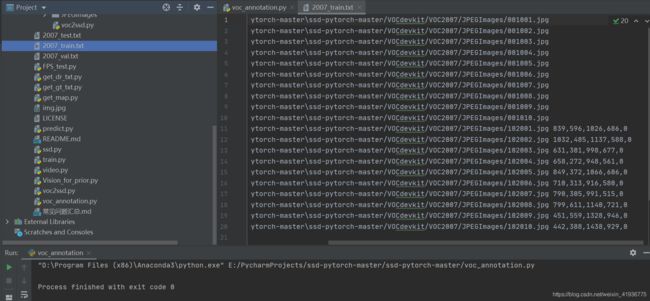
在得到索引文件后,需要用主文件夹下的
voc_annotations.py来调用这些索引文件并生成新的用于训练的 txt 文件,在生成的2007_train.txt中会包含图像文件的名称以及目标所在的位置信息。 这里需要注意的是在运行voc_annotations.py之前需要修改classes为自己的类别,否则生成的2007_train.txt中不会包含目标位置信息。
2. 训练
当数据集构造完成后,就可以运行 train.py 进行训练了,训练之前记得修改 classes 为自己的类别以及config.py中的 num_classes。训练完成之后权重会保存在主文件夹下的 log 目录下。
3. 预测
使用上述自己训练好的模型进行预测时,只需修改根目录下 ssd.py 文件中的 model_path 和 classes_path,然后运行 predict.py。
四、总结
用了一周多的时间也就看了一遍代码,而且是不完整且不完全看得懂。路漫漫其修远兮,还要更加努力才行哇。
关于这份代码我还没有自己尝试训练,下一步就是拿自己的数据集去试试效果,回头再来补充内容吧。