论文阅读-DeepRhythm: Exposing DeepFakes with Attentional Visual Heartbeat Rhythms
DeepRhythm
一、论文信息:
- 题目:DeepRhythm: Exposing DeepFakes with Attentional Visual Heartbeat Rhythms
- 作者团队:

- 会议:ACM MM2020
二、背景
血液在流过脸部时会引起皮肤颜色的微小变化,这种变化肉眼无法看到,但通过视频中帧的像素点变化可以检测到。所以推测假的视频中的心率变化跟真的视频中的心率变化不一致。



三、网络结构
作者设计了这样一个网络结构,该网络结构主要包括了两部分:第一部分是运动放大时空表示模块(Motion-Magnified Spatial-Temporal Representation),第二部分是双时空注意力网络(Dual-Spatial-Temporal Attentional Network)。
第一部分:Motion-Magnified Spatial-Temporal Representation 这部分是在一种叫做时空表征STR( Spatial-Temporal Representation )的提取心率的方法上进行改进的,作者在这里为了方便观察像素点的变化情况,加入了运动放大方法。
这部分是在一种叫做时空表征STR( Spatial-Temporal Representation )的提取心率的方法上进行改进的,作者在这里为了方便观察像素点的变化情况,加入了运动放大方法。
该模块分为三个步骤:
1.从视频切出来的帧中找到脸的部位,然后移除掉眼部和背景部分(此处是因为该网络是观察皮肤上面的血液流动,眼睛和背景的像素点变化是干扰,故移除);
2.利用运动放大方法,计算运动方法之后的图像;
Motion Magnification
3.将运动放大后的每个通道上(R,G,B三个通道)的图片切patchs,然后对每个patch进行平均池化,这个每个patch在池化之后得到一个值,这个每个通道的所有patch池化之后的结果最右边所示的类似于心电图的图像,也就是运动放大时空映射(MMST Map)。上图中的红绿蓝分别代表彩色图片的每个通道。
第二部分:Dual-Spatial-Temporal Attentional Network

此图片为双时空注意力网络的的详细结构,该部分主要由两部分构成:
第一部分:双空间注意力模块
该模块有prior spatial attention(先验空间注意)和adaptive spatial attention(适应性空间注意)两部分相加组成。
先验空间注意力模块是从切好的patch中选择六块,剩余的设为空,分别是额头和脸颊,因为这些部位抗干扰能力强,检测效果明显,将这六个部位做平均池化,得到的结果就是先验空间注意力模块的结果;
适应性空间注意力是为了消除环境因素的影响,设计了一个空间注意力网络来生成适应性空间注意力。因为即使是同一人脸在不同情况下也具有不同的ROI块,该网络一部分是一个卷积操作,输入上一步得到的MMST Map,然后经过64个 15x1 的卷积核,然后接上后面的batch norm和 max pooling,得到一个映射Sa。
此时双空间注意力模块提取到的就是将先验空间注意力的结果与适应性空间注意力模块结果的和。即S=Sa+Sp。
第二部分:双时间注意力模块
该模块由block-level temporal attention(块级时间注意力) 和frame-level temporal attention(帧级时间注意力)两部分相加组成。T=Tb+Tf。
首先上一步得到的MMST Map是一个有序的特征,将该特征输入到一个需要训练的LSTM网络来表示脸部区域在时间上的变化,此时的输出就代表了块层面的时间注意力;
然后训练一个分类器来对每个帧的篡改可能性进行打分,此处使用的是Meso-4架构,包括了四个卷积和两个全连接。
此时双时间注意力模块提取到的就是帧层面的时间注意力结果与块层面的时间注意力结果的和。
最后将双空间注意力模块的结果乘以双时间注意力模块结果的转置,然后加上第一部分提取到的MMST Map,作为最终经过分类器的特征输入。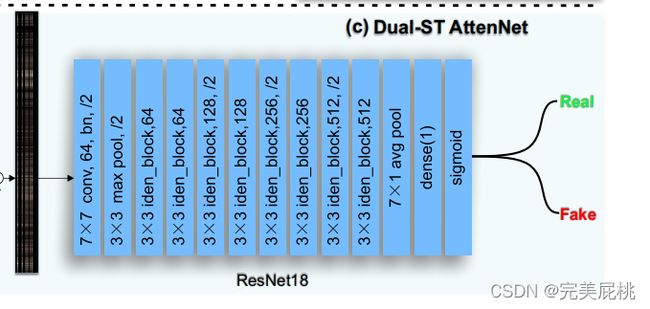
最后的分类器就是一个ResNet18,来判断真假。
四、实验

这个数据集比较奇怪,用FF++但是没用其中的一些其他方法,只用deepfakes,face2face,faceswap这三种方法加上deepfake detection文件夹中的数据,进行了数据增强以达到平衡。
效果:

在自己数据集上面训,自己数据集上面测的效果挺好,甚至能达到比较离谱的百分之百精度,但是跨数据集效果就一般了,只有六十多的精度,可能换成AUC进行衡量能达到百分之七十多。