迁移学习:自己预训练的resnet18模型在Unet上的实现(pytorch版)(有待完善)
文末有resnet18网络结构
下面上一张unet的网络结构
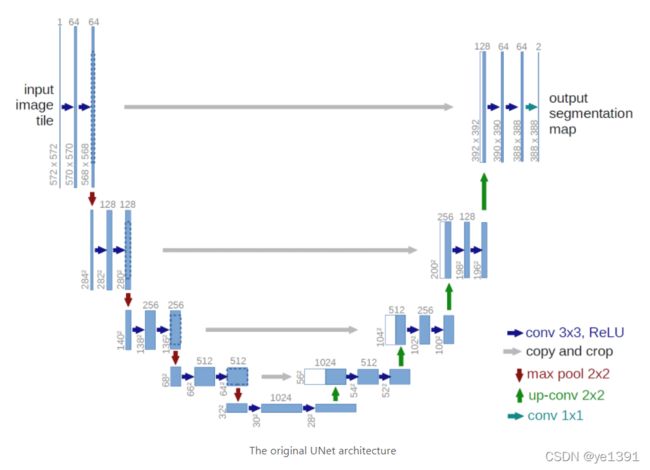
然后根据以上的网络结构图,搭建pytorch模型
def Conv2RELU(inchannels, outchannels, kernel, padding):
return nn.Sequential(
nn.Conv2d(inchannels, outchannels, kernel, padding=padding),
nn.ReLU(inplace=True),
)
class UnetResNet(nn.Module):
def __init__(self, n_class, out_size):
super().__init__()
self.out_size = out_size
# if the imageNet pretrained model is needed, please set the augment "pretrained" equals to True
self.backbone = models.resnet18(pretrained=False)
self.baseLayer = list(self.backbone.children())
self.layer0 = nn.Sequential(*self.baseLayer[:3])
self.layer1 = nn.Sequential(*self.baseLayer[3:5])
self.layer2 = self.baseLayer[5]
self.layer3 = self.baseLayer[6]
self.layer4 = self.baseLayer[7]
self.layerup3 = nn.ConvTranspose2d(512, 256, 2, 2)
self.layerup2 = nn.ConvTranspose2d(256, 128, 2, 2)
self.layerup1 = nn.ConvTranspose2d(128, 64, 2, 2 )
self.layerupConV3 = nn.Conv2d(512, 256, 3)
self.layerupConV2 = nn.Conv2d(256, 128, 3)
self.layerupConV1 = nn.Conv2d(128, 64, 3)
self.ReLu = nn.ReLU()
self.endlayer = nn.Conv2d(64, n_class, 1)
def Crop(self, encode_features, x):
_, _, H, W = x.shape
return torchvision.transforms.CenterCrop([H, W])(encode_features)
def ConvBlock(self, layer, x):
conv = self.ReLu(layer(x))
return self.ReLu(conv)
def forward(self, input_x):
layer0 = self.layer0(input_x)
layer1 = self.layer1(layer0)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
x = self.layerup3(layer4)
layer3skip = self.Crop(layer3, x)
x = torch.cat([x, layer3skip], dim=1)
x = self.ConvBlock(self.layerupConV3, x)
x = self.layerup2(x)
layer2skip = self.Crop(layer2, x)
x = torch.cat([x, layer2skip], dim=1)
x = self.ConvBlock(self.layerupConV2, x)
x = self.layerup1(x)
layer1skip = self.Crop(layer1, x)
x = torch.cat([x, layer1skip], dim=1)
x = self.ConvBlock(self.layerupConV1, x)
x = self.endlayer(x)
out = F.interpolate(x, self.out_size)
return out载入预训练模型时使用一下的操作
# 4.create model
model = UnetResNet(num_class, [512, 512]).to(device)
#model = ResNetUSCL(base_model='resnet18', out_dim=256, pretrained=pretrained)
state_dict = torch.load(state_dict_path)
new_dict = {k: state_dict[k] for k in list(state_dict.keys())
if not (k.startswith('l')
| k.startswith('fc'))} # # discard MLP and fc
model_dict = model.state_dict()
model_dict.update(new_dict)
model.load_state_dict(model_dict, strict=False)
# frozen the pretrained model parameters
for Pname in model.baseLayer:
for param in Pname.parameters():
param.requires_grad = False以下resnet18的网络结构
list(base_model.children())
[Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False),
BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),
ReLU(inplace),
MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False),
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
),
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
),
Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
),
Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
),
AvgPool2d(kernel_size=7, stride=1, padding=0),
Linear(in_features=512, out_features=1000, bias=True)]summary(base_model, input_size=(3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------