Win10+VMware+CentOS+Hadoop+Spark+Python+Java一站式配置环境
@TOC(未完结)
目录
软件下载
对于VMware,大家可以自行寻找下载资源。
- 查询自己需要的Hadoop与Java版本是否配套查询地址,在这里我使用的是Hadoop-3.3.1,Spark-3.2.0和Java-1.8.0;
- Hadoop下载地址;
- Spark下载地址;
- CentOS下载地址,在这里我选择的是CentOS-7-x86_64-Everything-2009.iso;
配置虚拟机1
具体安装过程不加赘述,提醒一点就是注意虚拟内存的设置,后期复制虚拟机后内存占用空间会很大。
安装完成后,开始配置虚拟机。
网络配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
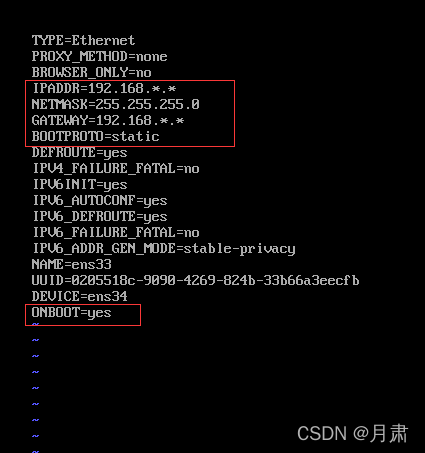
如图进行修改。
重启虚拟机
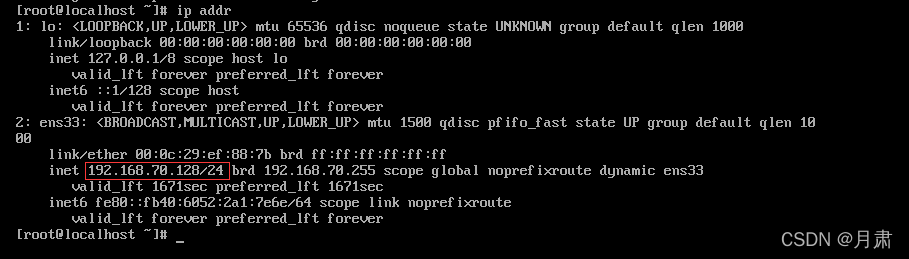
ip addr
记住这个IP地址
在Windows系统下查找C:\Windows\System32\drivers\etc\hosts
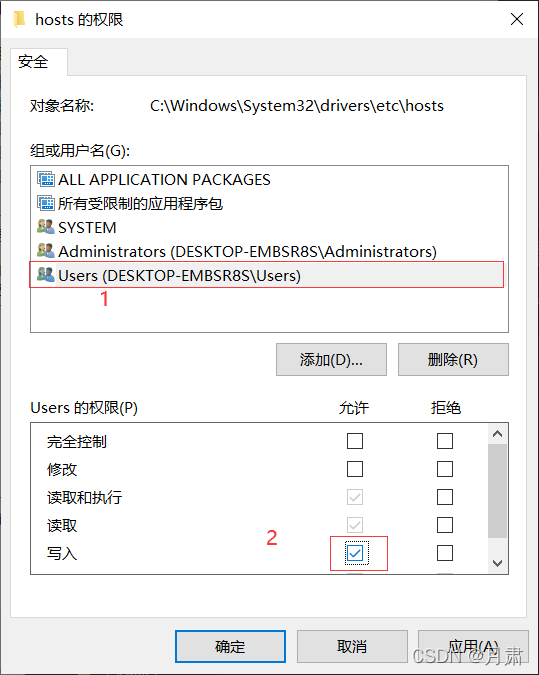
不过这里hosts不能直接修改,我们可以hosts右键进入属性->安全->编辑,更改写入权限
加入自己的IP地址

我命名为host1。
完成,在Windows命令行敲入ssh root@host1,再输入自己的密码就可以通过Windows命令行管理Linux系统。

注意,当删除原有虚拟机而又重新安装一个虚拟机时,如果前后两者命名相同,则需要进入C://User/用户名/.ssh内把known_hosts文件删除,再在Windows命令行中敲入ssh指令重新生成加密文件。
安装Cockpit
yum install cockpit
安装完成后
systemctl enable --now cockpit.socket
firewall-cmd --permanent --zone=public --add-service=cockpit
firewall-cmd --reload
完成后在浏览器地址栏输入
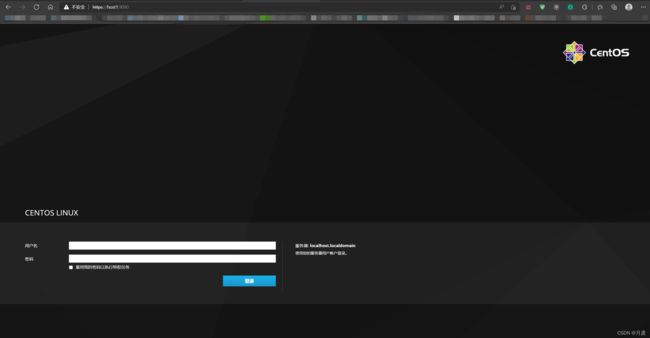
这样我们就借用浏览器拥有了一个图形界面。
安装Java
yum list installed |grep java-
yum search java|grep jdk
yum install java-1.8.0-openjdk
yum install java-1.8.0-openjdk-devel.x86_64
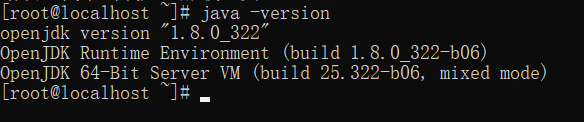
检查安装是否成功
java -version
拷贝、解压Hadoop和Spark
使用sftp,在Windows命令行下输入
sftp root@host1 #host1同上是我的IP地址,请根据自己的情况修改。
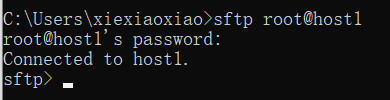
按照自己的爱好将两个压缩包传至对应的文件夹,这里我选择新建两个文件夹
mkdir /Hadoop
mkdir /Spark
完成后
cd ..
ls

接下来要跨平台传输文件了
put D:\BrowserDownload\spark-3.2.0-bin-hadoop3.2.tgz /Spark
put D:\BrowserDownload\hadoop-3.3.1.tar.gz /Hadoop
检查文件是否传输成功

退出sftp,重新进入Linux系统。
ssh root@host1
完成后解压两个文件
cd /Spark
tar -xvf spark-3.2.0-bin-hadoop3.2.tgz
cd /Hadoop
tar -xvf hadoop-3.3.1.tar.gz
配置Spark与Hadoop
vi /etc/profile
插入环境变量
export JAVA_HOME=/etc/alternatives/java_sdk
export HADOOP_HOME=/Hadoop/hadoop-3.3.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export SPARK_HOME=/Spark/spark-3.2.0-bin-hadoop3.2
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export LD_LIBRARY_PATH=$JAVA_LIBRARY_PATH
export PATH=$PATH:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
这里面有Python和JupyterNotebook的路径,是因为我需要用,不需要的也可以不加。
生效
source /etc/profile
安装Python
据大佬1交代Python3.9不好安装,所以安装Python3.7。
这一段的安装很有意思,愣是给我整出了七进七出的感觉。
问题1:yum install jupyter下载到某个包之后不动了,解决方法是删除pythonyum remove python3,然后重新安装pythonyum install python3,注意!注意!这里不要更新pip,执行yum install jupyter时也不要后缀镜像,就让它慢慢下。
问题2:执行完下述所有语句(除了更新pip)后提示无可用版本/版本过低,执行更新pippip3 install --upgrade pip,之后重新执行下述所有语句。
yum install -y gcc openssl-devel bzip2-devel libffi-devel zlib-devel
yum install python3
yum install python3-devel
pip3 install --upgrade pip
pip3 install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
pip3 install jupyter_nbextensions_configurator -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install jupyter_contrib_nbextensions -i https://pypi.tuna.tsinghua.edu.cn/simple
jupyter contrib nbextension install --user
jupyter nbextensions_configurator enable --user
设置Jupyter Notebook(可选)
mkdir -p /Spark/source/pyspark
jupyter notebook --generate-config
然后进入Python
python3
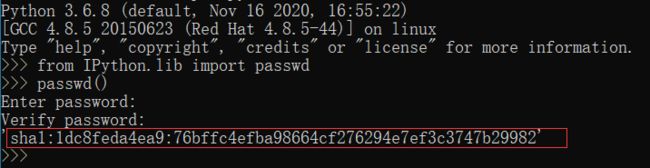
进入Python后
from IPython.lib import passwd
passwd()
记住这个哈希值
退出Python
exit()
修改Jupyter Notebook设置
vi /root/.jupyter/jupyter_notebook_config.py
这里需要修改一堆内容一个一个查找太慢了,所以就直接添加语句
c.NotebookApp.allow_root = True
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.notebook_dir = '/Spark/source'
c.NotebookApp.open_browser = False
c.NotebookApp.password = '上面生成的密码加密字符串,以sha1:开头'
完成后添加IP地址
vi /etc/hosts

配置Spark
pip3 install spark
关闭防火墙服务
systemctl stop firewalld.service
systemctl disable firewalld.service
/Spark/spark-3.2.0-bin-hadoop3.2/sbin/start-master.sh
pyspark --master spark://主机名:7077&
这里也会出现问题,提示/etc/alternatives/java_sdk/bin/java没能找到,还有坏的数组啥的,这里需要创建文件夹/etc/alternatives/java_sdk/bin/然后把/etc/alternatives里的java复制到/etc/alternatives/java_sdk/bin/里,然后再执行spark命令。
运行pyspark --master spark://Host1:7077&后,浏览器访问Jupyter Notebook:
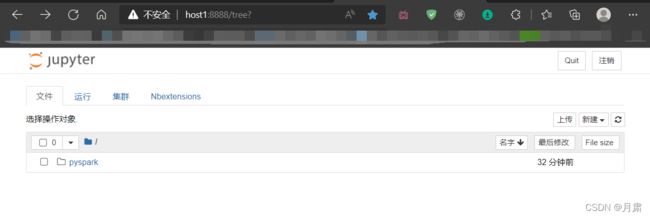
值得一提的是,在浏览器的终端控制下,需要输入pyspark的所有路径才能执行,此时会出现如下图片:
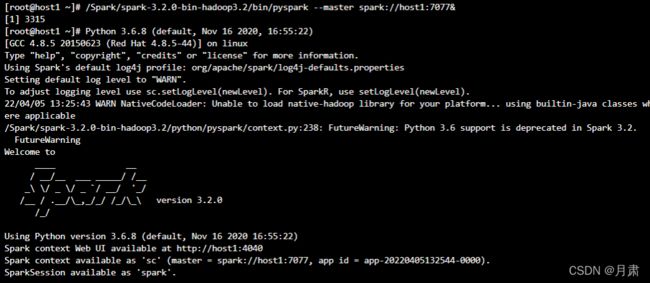
vi /Spark/spark-3.2.0-bin-hadoop3.2/conf/spark-env.sh

vi /Spark/spark-3.2.0-bin-hadoop3.2/conf/workers
配置Hadoop
cd /Hadoop/hadoop-3.3.1/etc/hadoop
vi core-site.xml
插入
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://Host1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/Hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
configuration>

vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/Hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/Hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>host1:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.blocksizename>
<value>16777216value>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
property>
configuration>
vi /Hadoop/hadoop-3.3.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/etc/alternatives/java_sdk
建立文件:vi /Hadoop/hadoop-3.3.1/etc/hadoop/workers
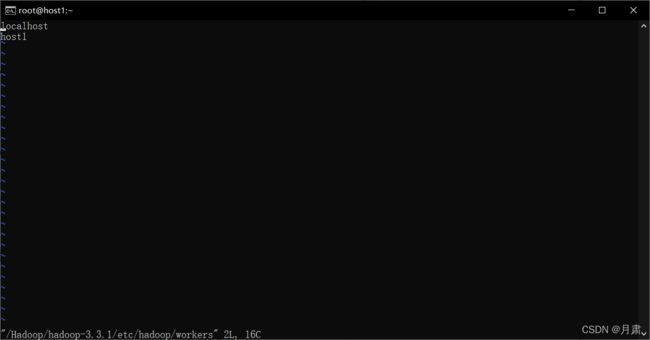
建立权限
vi /etc/profile.d/my_env.sh
插入
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使生效source /etc/profile
配置ssh免密登录
ssh-keygen -t rsa
三次回车后
cd ~/.ssh
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub >> authorized_keys
/Hadoop/hadoop-3.3.1/bin/hdfs namenode -format
/Hadoop/hadoop-3.3.1/sbin/start-dfs.sh
这里要是提示缺权限的话,就vi /etc/profile,把下面复制进去
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile
yum install net-tools
netstat -tlpn
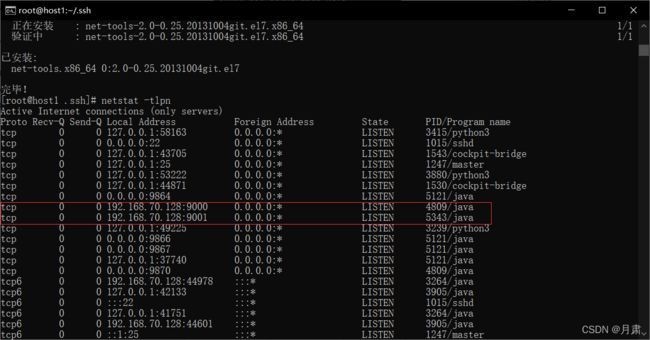
Hadoop成功启动
hadoop fs -mkdir /sparkdata
hadoop fs -chmod -R 777 /sparkdata
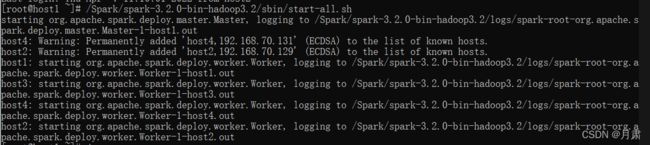
/Spark/spark-3.2.0-bin-hadoop3.2/sbin/start-all.sh
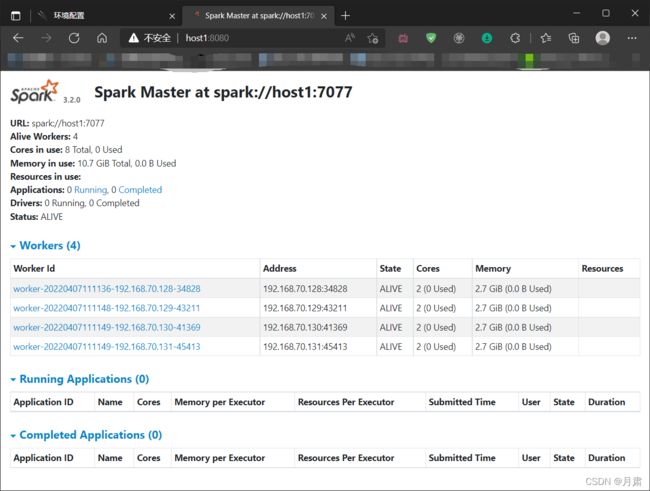
浏览器进入
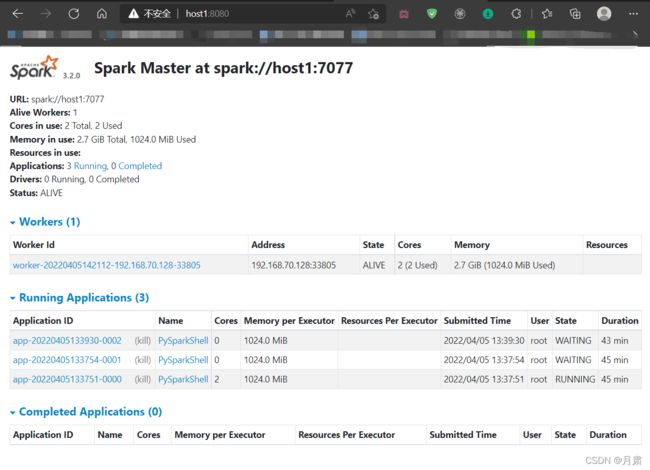
在这里我们可以看到Spark运行每个job的过程和DAG图
浏览器进入
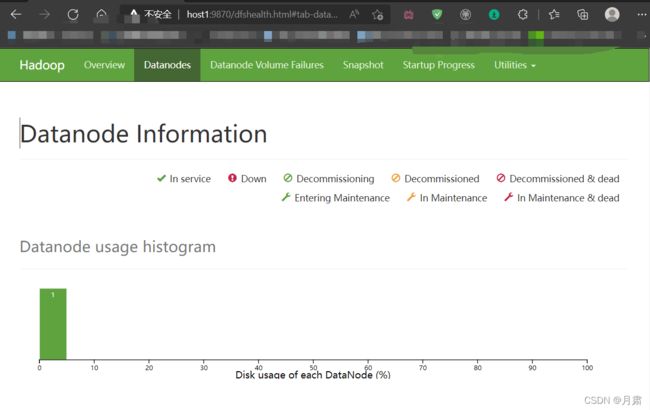

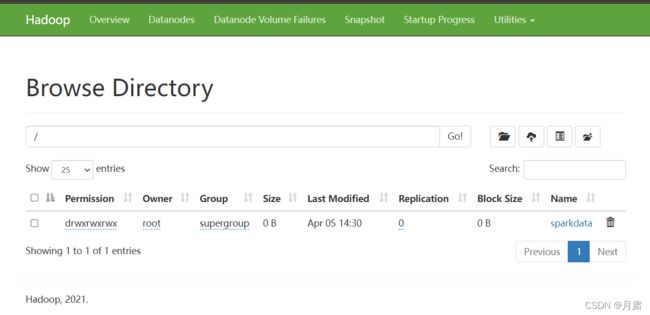
这里我们可以浏览每个节点的信息,同时可以上传文件至hdfs系统。
浏览器进入
进入Jupyter Notebook
在这里我给出一段测试代码
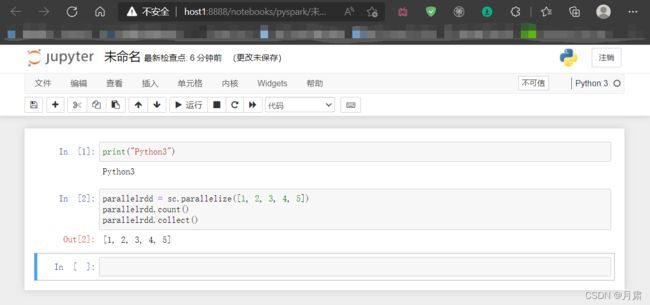
如果第一个print函数成功运行,第二个一直显示内核正忙(kernel connected)的话重启虚拟机就完事儿了。
到这里我们Python配置Spark就完成了。
复制虚拟机
在C:\Windows\System32\drivers\etc\hosts文件中添加:
192.168.70.128 Host1
192.168.70.129 Host2
192.168.70.130 Host3
192.168.70.131 Host4
在这里数量的多少与个人使用和喜好有关,我整了4个。

编辑/etc/hosts文件
IP地址根据虚拟机实际地址设置:
192.168.70.128 host1
192.168.70.129 host2
192.168.70.130 host3
192.168.70.131 host4
编辑/Spark/spark-3.2.0-bin-hadoop3.2/conf/workers
host1
host2
host3
host4
编辑/Hadoop/hadoop-3.3.1/etc/hadoop/workers
host1
host2
host3
host4
完成后关闭虚拟机。
在VMware中右键虚拟机->管理->克隆
参考大佬配置 ↩︎ ↩︎
重复以上操作
 整体没有更新完,有空了再更新>_
整体没有更新完,有空了再更新>_