【第2重磅】王者荣耀「绝悟」升级,全英雄池解禁
深度强化学习实验室
本文转载自 “新智元”
作者:QJP、小匀
编辑:DeepRL
11月28日,由腾讯 AI Lab 与王者荣耀联合研发的策略协作型 AI「绝悟」推出升级版本「绝悟完全体」 。新算法将AI可用英雄池数量从40个增至100+个,还优化了禁选英雄博弈策略,其相关研究已被 AI 顶级会议 NeurIPS 2020 与顶级期刊 TNNLS 收录。
2018年的KPL秋季总决赛上,一个名叫「绝悟」的低调王者露面了。
这不是人类玩家,而是一个AI。先来看看有多强?
AI达摩红buff处的一次漂亮的蹲点,直接用大招将赵云推上墙然后跟闪现秒杀出乎了所有人的预料。
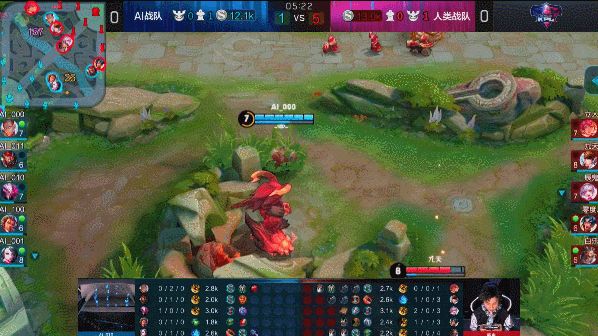
等等!这波有点眼熟……好像在BA.一诺身上见过?
没错,TS.暖阳也有过这样的操作!

不仅如此,还有一波偷师Hero.久诚的潇洒操作:AI干将莫邪与AI达摩无敌配合,秒了对方,同时被敌方项羽牛魔两人近身竟有条不紊逃生,极其亮眼。
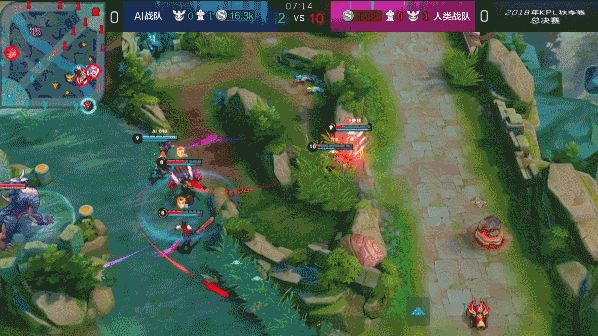
最终,AI战队凭借着优秀的团队配合逆风翻盘,赢得比赛!
「绝悟」是由腾讯 AI Lab 与王者荣耀联合研发的策略协作型 AI,代表了腾讯在深度强化学习、多智能体决策上的国际级AI研究水平。
11月28日,腾讯宣布,「绝悟」推出升级版本——「绝悟完全体」。
没错,更强!
而且,限时开放!在王者荣耀 App ,公众可与之对战,亲身体验 AI 在复杂策略、团队协作与微观操作方面的强大能力。
体验时间为 11 月 14 日至 30 日,绝悟在 20 个关卡的能力不断提升,最强的20级于11月28日开放,接受 5v5 组队挑战。
40个到100+,英雄池完全解禁
这次升级版本带来了:
1. 创新算法突破了可用英雄限制(英雄池数量从40增为100+),让 AI 完全掌握所有英雄的所有技能,能应对高达10的15次方的英雄组合数变化;
2. 优化了禁选英雄(BanPick,简称BP)博弈策略,能综合自身技能与对手情况等多重因素派出最优英雄组合。
在王者荣耀中,若每个职业都有4个紫色熟练度英雄,你就能解锁「全能高手」称号。但因为练习时间与精力限制,很少有人能精通所有英雄。
但「绝悟」做到了。技术团队一年内让 AI 掌握的英雄数从1个增加到100+个,完全解禁英雄池,此版本因此得名「绝悟完全体」。
绝悟AI能力演进路线,从MOBA 新手玩家到职业顶尖水平:
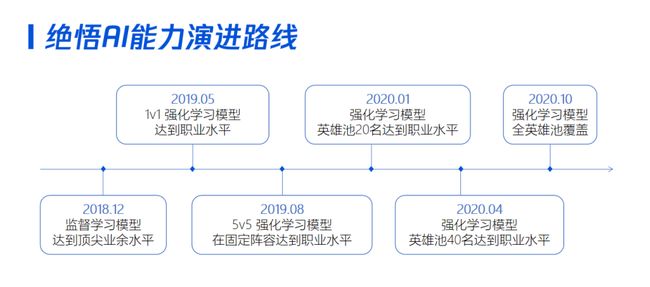
绝悟:前有强兵开路,后有军师辅佐,一代宗师终练成
与此版本相关的强化学习相关研究被AI顶级学术会议 NeurIPS 2020 收录,监督学习(SL)相关研究被顶级期刊 TNNLS 收录,体现了腾讯国际一流的 AI 研究与应用能力。
NeurIPS 2020 入选论文:「使用深度强化学习朝着无限制MOBA游戏AI迈进」
由于MOBA游戏本身的复杂性,现有的工作无法很好地解决智能体阵容组合数随着英雄池扩大而爆炸增长的问题,例如,OpenAI的Dota AI仅支持17名英雄。至今,无限制的完整MOBA游戏还远没有被任何现有的AI系统所掌握。

为了应对多英雄组合问题,技术团队先采用引入「老师分身」模型,每个AI老师在单个阵容上训练至精通,再引入一个 AI 学生模仿学习所有的AI老师,最终让「绝悟」掌握了所有英雄的所有技能,成为一代宗师。
团队的长期目标,就是要让「绝悟」手握强兵,学会所有英雄的技能,且每个英雄都能达到顶尖水平,因此在技术上做了三项重点突破:
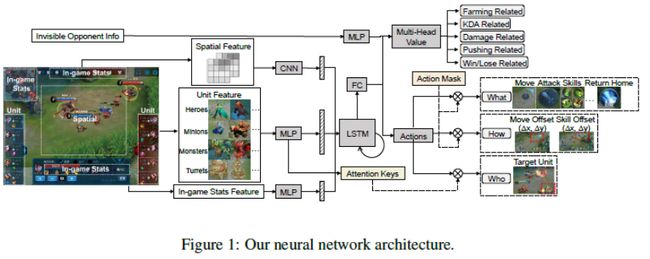 图:网络结构
图:网络结构
首先构建了一个最佳神经网络模型,让模型适配MOBA类任务、表达能力强、还能对英雄操作精细建模。模型综合了大量AI方法的优势,具体而言,在时序信息上引入长短时记忆网络(LSTM)优化部分可观测问题,在图像信息上选择卷积神经网络(CNN)编码空间特征,用注意力(Attention)方法强化目标选择,用动作过滤(Action Mask)方法提升探索效率,用分层动作设计加快训练速度,用多头值估计(Multi-Head Value)方法降低估计方差等。
其次,团队研究出了拓宽英雄池,让「绝悟」掌握所有英雄技能的训练方法——CSPL(Curriculum Self-Play Learning,课程自对弈学习)。
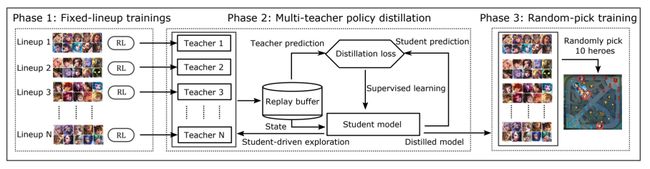 图:CSPL流程图。设计思想:任务由易到难,模型从简单到复杂,知识逐层深入
图:CSPL流程图。设计思想:任务由易到难,模型从简单到复杂,知识逐层深入
第三,团队还搭建了大规模训练平台——腾讯开悟(aiarena.tencent.com),依托项目积累的算法经验、脱敏数据及腾讯云的算力资源,为训练所需的大规模运算保驾护航。
英雄池的规模是OpenAI的2.4倍,英雄组合复杂度提升了2.1*10^11倍。
团队人员还邀请了《王者荣耀》职业玩家来和他们的AI对抗,这些职业玩家被鼓励使用他们擅长的英雄以及尝试不同的游戏策略进行测试。
在10周的一个时间内,总共对打了42场,AI赢了40场。
2020年5月1号到2020年5月5号,研究人员还将AI部署到《王者荣耀》和玩家公开对抗, 为了严格评估AI是否能够对抗多样化的高水平策略,只有符合要求的顶尖玩家可以参与(玩家可以反复参与)。
最终,该AI与顶尖玩家对抗了642,047局,AI赢得了其中的627,280局(胜率97.7,置信区间[0.9766, 0.9774])。而对比其它的公开游戏AI测试:AphaStar和OpenAI各打了90和7,257场,且对参与者没有游戏水平的要求。
团队同时研发了监督学习(SL)方法,针对大局观和微操策略同时建模,让绝悟同时拥有优秀的长期规划和即时操作,达到了非职业玩家的顶尖水平。今年11月14日起开放的绝悟第1到19级,就有多个关卡由监督学习训练而成。
第二篇被顶级期刊 TNNLS 收录的论文是:「探究在王者荣耀中使用监督学习达到人类高手水平」
这篇文章提出了 JueWu-SL(绝悟监督学习版本)--首个利用监督学习在MOBA游戏中达到人类高手水平的AI系统。

论文中首次提出了将多模态特征表征游戏状态,利用深度卷积和全连接神经网络来同时对大局观和微观策略进行建模,并且还提出了一种基于场景采样的数据预处理方法,使得在不同的场景下AI智能体的能力都有所提高。
通常来说,监督学习是构建AI智能体的第一步,并且在很多游戏中都能直接借助监督学习使得智能体达到人类高手水平。
在MOBA游戏中,由于经验丰富的人类玩家通常会在开始行动前,先判断游戏局势。因此,有效的动作(标签)如果被正确提取,应该本身就包含了顺序信息。
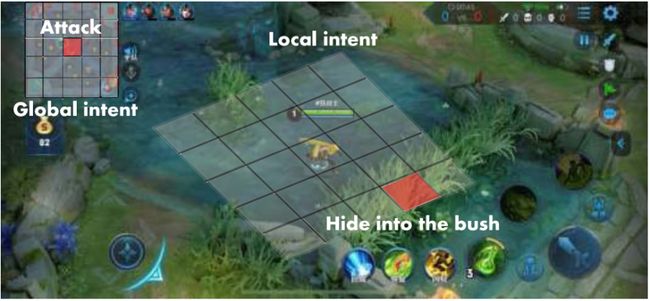 图1:大局观的多视角意图标签
图1:大局观的多视角意图标签
从这个意义上讲,人类专家的游戏知识可以以监督的方式被“提取”。
具体来说,假设有准确标注的标签,其中包含了智能体的策略和具体行动,以及每个时间片上每次团战的精确表达,那么在有充足的训练数据的情况下,监督学习就能潜在地提取到从团战到标签的有效映射。
然而,这种映射的提取非常困难,因为要同时建模玩家的大局观和微操策略。
研究者邀请了一只荣耀王者水平的高分段玩家组成的队伍与JueWu-SL进行了反复测试,结果如下:
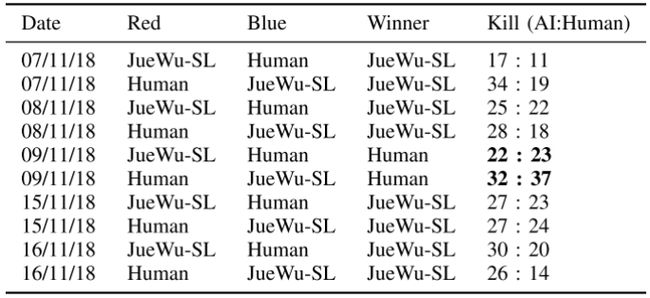
从上图中可以看到,AI取得了绝大部分的胜利。
需要说明的是,其中第5、6局,人类采用了入侵野区然后中路推进的战术,迅速拉开经济和经验,使得AI落败。为了应对这个问题,研究者进一步对野区进行了精细化的数据场景分割采样。而后续4局AI都取得了胜利,对局观察发现AI已经学会如何应对入侵野区的打法。
 图:达摩蹲草埋伏击杀赵云
图:达摩蹲草埋伏击杀赵云
大量的实验表明,这是监督学习AI智能体首次在MOBA游戏达到人类业余顶尖高手水平。
JueWu-SL 能提供后续MOBA游戏AI研究很多启示。比如,网络结构可用于强化学习模型的策略网络。并且该模型可以用于强化学习模型初始化,也能作为对手帮助强化学习训练。未来,研究者还可以考虑将监督学习和强化学习结合来进一步改进AI能力。
长远来看,监督学习+强化学习正是推动AI终极目标—通用人工智能问题的利器。
至此,绝悟前有强兵开路,后有军师辅佐,不折不扣的一代宗师终练成。
来源:https://mp.weixin.qq.com/s/wDb77DbKTpDIZ09vQs5mzg
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5: 万字总结 || 强化学习之路
总结6:万字总结 || 多智能体强化学习(MARL)大总结
总结7:深度强化学习理论、模型及编码调参技巧
总结8:深度强化学习理论、模型及编码调参技巧
总结9:分层强化学习(HRL)全面总结
完
第88篇:2019年-57篇深度强化学习文章汇总
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)
