U-Net基于TensorRT部署
1. 网络训练
本项目采用的代码为pytorch-Unet,链接为:https://github.com/milesial/Pytorch-UNet。 该项目是基于原始图像的比例作为最终的输入,这个对于数据集中图像原始图片大小不一致的情况可能会出现训练问题(显存不够用)。
2. 重点代码解析
train.py
parser = argparse.ArgumentParser(description='Train the UNet on images and target masks',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
# 训练的epoch大小
parser.add_argument('-e', '--epochs', metavar='E', type=int, default=5,
help='Number of epochs', dest='epochs')
# 每次训练的batch size
parser.add_argument('-b', '--batch-size', metavar='B', type=int, nargs='?', default=1,
help='Batch size', dest='batchsize')
parser.add_argument('-l', '--learning-rate', metavar='LR', type=float, nargs='?', default=0.0001,
help='Learning rate', dest='lr')
# retrain 的权重文件
parser.add_argument('-f', '--load', dest='load', type=str, default=False,
help='Load model from a .pth file')
# 输入大小占原始图像大小的比例
parser.add_argument('-s', '--scale', dest='scale', type=float, default=0.5,
help='Downscaling factor of the images')
# 验证集占全部数据集的比例大小
parser.add_argument('-v', '--validation', dest='val', type=float, default=10.0,
help='Percent of the data that is used as validation (0-100)')网络结构
# n_classes是指分割的类别,bilinear是指上采样是否使用双线性插值
net = UNet(n_channels=3, n_classes=1, bilinear=False)数据加载
dataset = BasicDataset(dir_img, dir_mask, img_scale, mask_suffix="_mask")
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train, val = random_split(dataset, [n_train, n_val])
train_loader = DataLoader(train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True)
val_loader = DataLoader(val, batch_size=batch_size, shuffle=False, num_workers=8, pin_memory=True, drop_last=True)优化器以及损失函数
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min' if net.n_classes > 1 else 'max', patience=2)
if net.n_classes > 1:
criterion = nn.CrossEntropyLoss()
else:
criterion = nn.BCEWithLogitsLoss()unet-model.py
图为unet的网络结构图,与原始论文中所描述的网络结构有一些出入。
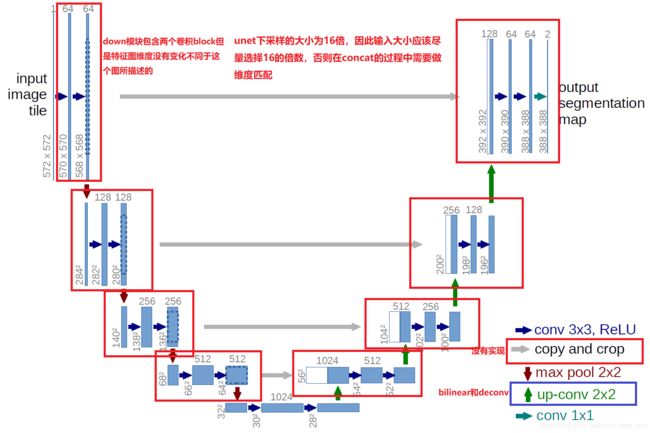
总体结构
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)基本模块
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
# 两个卷积block组成对特征图大小没有做什么改变
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)下采样
nn.MaxPool2d(2), # 改变特征图维度
DoubleConv(in_channels, out_channels)上采样
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
# 针对输入维度可能不是2的整数倍的填充处理,在concat操作之前
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)注意:可以在utils/dataset.py文件中,将替换newW, newH = int(scale * w), int(scale * h)替换为newW, newH=960, 640,设置网络的输入为固定大小,有利于后续网络的部署。
3. tensorrt-unet代码(测试环境Jetson TX2, Jetpack 4.4)
3.1 生成unet的onnx格式网络模型
由于tensorrt里面还没有实现bilinear双线性插值上采样操作,所以选择使用deconv作为上采样的unet网络结构。
依赖:
- torch >= 1.2.0
- onnx >=1.5
from network import UNet # 这个是Pytorch-Unet项目里面网络结构
import torch
import onnx
# gloabl variable
model_path = "weight/unet_deconv.pth"
if __name__ == "__main__":
# input shape尽量选择能被2整除的输入大小
dummy_input = torch.randn(1, 3, 640, 960, device="cuda")
# [1] create network
model = UNet(n_channels=3, n_classes=1, bilinear=False)
model = model.cuda()
print("create U-Net model finised ...")
# [2] 加载权重
state_dict = torch.load(model_path)
model.load_state_dict(state_dict)
print("load weight to model finised ...")
# convert torch format to onnx
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model,
dummy_input,
"unet_deconv.onnx",
verbose=True,
input_names=input_names,
output_names=output_names)
print("convert torch format model to onnx ...")
# [4] confirm the onnx file
net = onnx.load("unet_deconv.onnx")
# check that the IR is well formed
onnx.checker.check_model(net)
# print a human readable representation of the graph
onnx.helper.printable_graph(net.graph)3.2 onnx-tensorrt转换
可以通过onnx-tensorrt项目工具将unet的onnx模型转换为tensorrt的engine。(如果不需要实现int8量化推理,十分推荐使用该方法得到tensorrt的engine)
3.3运行测试
inference.py文件
import os
import sys
import time
# from PIL import Image
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
# TensorRT logger singleton
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
class TRTInference(object):
"""Manages TensorRT objects for model inference."""
def __init__(self, trt_engine_path, onnx_model_path, trt_engine_datatype=trt.DataType.FLOAT, batch_size=1):
"""Initializes TensorRT objects needed for model inference.
Args:
trt_engine_path (str): path where TensorRT engine should be stored
uff_model_path (str): path of .uff model
trt_engine_datatype (trt.DataType):
requested precision of TensorRT engine used for inference
batch_size (int): batch size for which engine
should be optimized for
"""
# Initialize runtime needed for loading TensorRT engine from file
self.trt_runtime = trt.Runtime(TRT_LOGGER)
# TRT engine placeholder
self.trt_engine = None
# Display requested engine settings to stdout
print("TensorRT inference engine settings:")
print(" * Inference precision - {}".format(trt_engine_datatype))
print(" * Max batch size - {}\n".format(batch_size))
# If we get here, the file with engine exists, so we can load it
if not self.trt_engine:
print("Loading cached TensorRT engine from {}".format(
trt_engine_path))
self.trt_engine = engine_utils.load_engine(
self.trt_runtime, trt_engine_path)
# This allocates memory for network inputs/outputs on both CPU and GPU
self.inputs, self.outputs, self.bindings, self.stream = \
engine_utils.allocate_buffers(self.trt_engine)
# Execution context is needed for inference
self.context = self.trt_engine.create_execution_context()
def infer(self, full_img, output_shapes, new_width, new_height):
"""Infers model on given image.
Args:
image_path (str): image to run object detection model on
"""
assert new_width > 0 and new_height > 0, "Scale is too small"
# resize and transform to array
scale_img = cv2.resize(full_img, (new_width, new_height))
print("scale image shape:{}".format(scale_img.shape))
# scale_img = np.array(scale_img)
# HWC to CHW
scale_img = scale_img.transpose((2, 0, 1))
# 归一化
if scale_img.max() > 1:
scale_img = scale_img / 255
# 扩增通道数
# scale_img = np.expand_dims(scale_img, axis=0)
# 将数据成块
scale_img = np.array(scale_img, dtype=np.float32, order='C')
# Copy it into appropriate place into memory
# (self.inputs was returned earlier by allocate_buffers())
np.copyto(self.inputs[0].host, scale_img.ravel())
# Output shapes expected by the post-processor
# output_shapes = [(1, 11616, 4), (11616, 21)]
# When infering on single image, we measure inference
# time to output it to the user
inference_start_time = time.time()
# Fetch output from the model
trt_outputs = do_inference(
self.context, bindings=self.bindings, inputs=self.inputs,
outputs=self.outputs, stream=self.stream)
print("network output shape:{}".format(trt_outputs[0].shape))
# Output inference time
print("TensorRT inference time: {} ms".format(
int(round((time.time() - inference_start_time) * 1000))))
# Before doing post-processing, we need to reshape the outputs as the common.do_inference will
# give us flat arrays.
outputs = [output.reshape(shape) for output, shape in zip(trt_outputs, output_shapes)]
# And return results
return outputs
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
predict.py
根据实际情况需要设置的参数:
- engine_file_path:engine的文件路径
- onnx_file_path:onnx文件路径
- new_width, new_height: 输入的宽和高
- trt_engine_datatype:engine的精度支持fp32和fp16
- image_path:测试图片路径
import tensorrt as trt
import numpy as np
import cv2
import utils.inference as inference_utils # TRT/TF inference wrappers
if __name__ == "__main__":
# 1. 网络构建
# Precision command line argument -> TRT Engine datatype
TRT_PRECISION_TO_DATATYPE = {
16: trt.DataType.HALF,
32: trt.DataType.FLOAT
}
# datatype: float 32
trt_engine_datatype = TRT_PRECISION_TO_DATATYPE[16]
# batch size = 1
max_batch_size = 1
engine_file_path = "best_une_deconv.trt"
onnx_file_path = "best_unet_deconv.onnx"
new_width, new_height = 960, 640
output_shapes = [(1, new_height, new_width)]
trt_inference_wrapper = inference_utils.TRTInference(
engine_file_path, onnx_file_path,
trt_engine_datatype, max_batch_size,
)
# 2. 图像预处理
image_path = "example.jpg"
img = cv2.imread(image_path)
# inference
trt_outputs = trt_inference_wrapper.infer(img, output_shapes, new_width, new_height)[0]
# 输出后处理
out_threshold = 0.5
print("the size of tensorrt output : {}".format(trt_outputs.shape))
output = trt_outputs.transpose((1, 2, 0))
# 0/1像素值
output[output > out_threshold] = 255
output[output <= out_threshold] = 0
output = output.astype(np.uint8)
result = cv2.resize(output, (img.shape[1], img.shape[0]))
cv2.imwrite("best_output_deconv.jpg", result)这样就可以完成u-net网络在tensorrt框架下加速推理。以下是经过tensorrt加速推理后的输出结果。
