【Deepstream之YoloX部署】
github: egbertYeah/yolox_deepstream (github.com)
0. 目标检测算法YoloX
YoloX是旷视科技于2021年提出的目标检测算法,本文主要介绍YoloX在deepstream环境下如何推理部署,对于算法的改进点以及性能不进行过多的分析。
paper: YOLOX: Exceeding YOLO Series in 2021
code:Yolox
1. 测试环境
该项目是在Jetson Nano的Jetpack 4.6上采用Deepstream6.0镜像测试,因此训练部署时,只需要满足以下的版本要求应该即可:
- tensorrt >=7.2
- Deepstream >= 5.0
- Pytorch-YoloX训练测试的requirements
2. 转ONNX模型
在YoloX的项目中提供了export_onnx.py脚本用于到处ONNX模型,具体转换过程可参考对应的Redame。
导出ONNX模型之后,可使用netron工具查看ONNX模型的网络结构。主要需要注意输入与输出是否正确。

默认情况下,输入的name应该是"images",维度应该是[1, 3, 640, 640],输出的name应该是"output",维度应该是[1, 8400, 85]。
解释一下,这些数字的含义,在输入中: 1表示batch-size,3表示输入图像的通道数,640和640表示网络输入的大小;而在输出中:1表示的是batch-size的大小,8400表示的是预测框的个数,85等于80+4+1,其中80表示数据集的类别数,4表示预测框的位置信息,1表示该预测框是前景还是背景。
3. 生成tensorrt的engine文件
在第2步中,我们得到了onnx模型,第3步是如何生成tensorrt的engine文件用来推理。
在介绍如何转engine之前,需要重点说一下YoloX项目的分支问题,现有的YoloX项目中包含两个分支,一个分支是main,另一个分支是0.1.1rc0, 这两个分支在图像预处理上有些许的差别【血盆大坑】,具体差异如下:
首先是main分支的yolox.cpp的代码
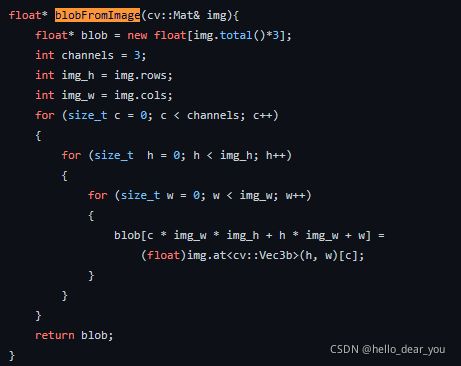
然后是0.1.1rc0分支的yolox.cpp的代码
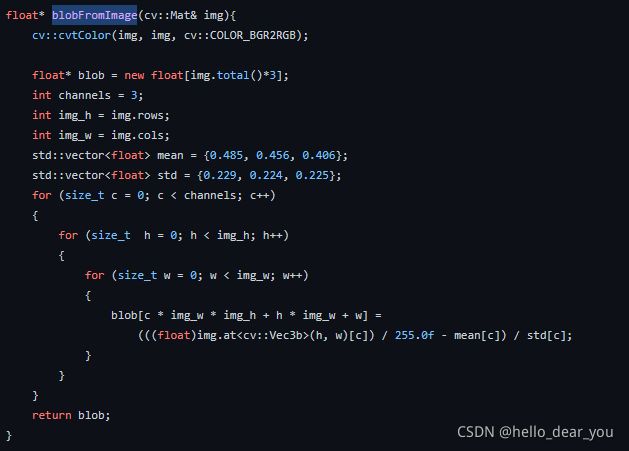
不知道大家有没有看出这两个函数之间的差异,先回顾一下,Yolo系列目标检测算法图像预处理的过程,我画了一个图描述的大致过程

通过对比,我们可以知道在main版本中的图像归一化过程并没有进行像素值归一化和像数值标准化这两步,这个非常重要,也非常坑【这一步主要是对deep stream在部署上有很大的影响】。
现在大家明确自己采用的是哪个版本的Yolox,然后我们接下来看看如何将ONNX文件转成engine。本文提供三种方式转换engine文件
3.1 使用torch2trt工具转换engine
这种方式是Yolox项目中提供说明的,具体可以参考readme.
3.2 使用trtexec工具转换engine
trtexec工具是TensorRT中自带的一个转换engine的工具,具体介绍可参考链接。然后我这里给出我使用的命令:
trtexec --onnx="path to onnx file" --fp16 --workspace=10240 --saveEngine="path to engine save"3.3 使用onnx-tensorrt工具转换engine
onnx-tensorrt项目是一个常用onnx转engine的工具,具体如何编译安装以及使用请参考这个项目的readme。
4. deepstream部署
之前有写过deepstream SDK中自带Yolov3的分析,有兴趣可以看看了解Yolo系列网络如何在deepstream进行部署。Deepstream的Yolov3使用流程(JetPack4.4环境下)
YoloX在deep stream上部署主要是编写一个后处理插件,如同Yolov3中的 nvdsinfer_custom_impl_Yolo一样,具体我们可以仿造Yolov3的和Yolox项目中tensorrt的C++推理代码Yolox.cpp文件。哈哈哈,我已经完成了这部分的修改,具体代码请查看GitHub。
既然代码有了,就说明一下如何使用和一些细节信息把!!!
首先,第一步是编译nvdsinfer_custom_impl_YoloX文件夹下的插件生成so动态库。这里面有几处需要修改的地方:
#define NMS_THRESH 0.45 // NMS的阈值
#define BBOX_CONF_THRESH 0.3 // 分类置信度的阈值
static const int NUM_CLASSES = 1; // 数据集中的类别数
static const int INPUT_W = 640; // 网络输入的宽高
static const int INPUT_H = 640;
static const int IMAGE_W = 2048; // 这个宽高需要与streammux插件设置的宽高相同(重点)
static const int IMAGE_H = 3072;
const char* INPUT_BLOB_NAME = "images";// engine input和output的name与onnx文件相同
const char* OUTPUT_BLOB_NAME = "output";重点需要验证的属性包括:NUM_CLASSES,IMAGE_W, IMAGE_H, 以及 INPUT_BLOB_NAME和OUTPUT_BLOB_NAME。
通过上面修改之后,make得到so动态链接库。
第二步,是修改config_infer_primary.txt文件,内容如下
[property]
gpu-id=0
- 这里需要重点说一下,如果你采用的是main版本的,一定要将net-scale-factor设置为1,而如果你采用另一个版本需要采用net-scale-factor=0.0039215697906911373。【这个就是图像预处理过程中是否做没做像素值归一化和标准化的区别,也是之前强调的】
# net-scale-factor=0.0039215697906911373
net-scale-factor=1
# 0:RGB 1:BGR
model-color-format=0
- engine的路径
model-engine-file=yolox_s_loulan.trt
- 与数据集类别对应的label文件和类别数
labelfile-path=labels.txt
num-detected-classes=1batch-size=1
interval=0
gie-unique-id=1# primary
process-mode=1# Detector
network-type=0# FP16
network-mode=2# 0:Group Rectange 1:DBSCAN 2:NMS 3:DBSCAN+NMS 4:None
cluster-mode=4
- maintain-aspect-ratio表示resize过程是否保存输入宽高比
maintain-aspect-ratio=1
scaling-filter=1
scaling-compute-hw=0
- 这个需要指定后处理的so动态库路径,以及后处理的函数接口
parse-bbox-func-name=NvDsInferParseCustomYolox
custom-lib-path=nvdsinfer_custom_impl_yolox/libnvdsinfer_custom_impl_yolox.so[class-attrs-all]
pre-cluster-threshold=0.3
第三步,是修改deepstream_app_config.txt的配置信息,主要修改的是如下几部分:
[source0]
enable=1
# 1:camera(v4l2) 2: single uri 3:multi uri 4:rtsp 5 camera(CSI) only for Jetson
type=2
uri=file://./sample_1080p_h264.mp4
num-sources=1
gpu-id=0
cudadec-memtype=0
select-rtp-protocol=4使用uri参数指定需要推理的视频文件路径
[streammux]
gpu-id=0
live-source=0
batch-size=1
batched-push-timeout=40000
width=2048
height=3072
enable-padding=1
nvbuf-memory-type=0重点需要修改width和height参数,在这里设置的width和height需要与后处理插件代码中的IMAGE_W, IMAGE_H大小对应。
最后,采用如下的命令进行推理
deepstream-app -c deepstream_app_config.txt至此,我们完成的YoloX在deep stream上的推理,撒花!!!!