机试题笔记
第一题:整数对最小和
1.1题目描述:
给定两个整数数组array1、array2,数组元素按升序排列。假设从array1、array2中分别取出一个元素可构成一对元素,现在需要取出k对元素,并对取出的所有元素求和,计算和的最小值
注意:两对元素如果对应于array1、array2中的两个下标均相同,则视为同一对元素。
输入描述:
输入两行数组array1、array2,每行首个数字为数组大小size(0 < size <= 100);
0 < array1[i] <= 1000
0 < array2[i] <= 1000
接下来一行为正整数k
0 < k <= array1.size() * array2.size()
输出描述:
满足要求的最小和
示例1
输入
3 1 1 2
3 1 2 3
2
输出
4
说明
用例中,需要取2对元素
取第一个数组第0个元素与第二个数组第0个元素组成1对元素[1,1];
取第一个数组第1个元素与第二个数组第0个元素组成1对元素[1,1];
求和为1+1+1+1=4,为满足要求的最小和
1.2解题思路:
将元素对的值,存入一个集合,对集合进行排序,然后取前k个的和
1.3代码实现
public static int arraydoubleres(){
//输入
Scanner sc=new Scanner(System.in);
String str1=sc.nextLine();
String str2=sc.nextLine();
int k=sc.nextInt();
//m代表最后输出的和
int m=0;
//将一行的字符串转换成整数数组
int[] str11=getarray(str1);
int[] str22=getarray(str2);
//创建一个集合,将元素对的和存入集合
ArrayList arraylist=new ArrayList<>(str11.length*str22.length);
for (int i:str11) {
for(int j:str22){
arraylist.add(i+j);
}
}
//对元素排队的方法之一:可以是将集合转成数组,然后进行排序
// Integer[] res = new Integer[arraylist.size()];
// arraylist.toArray(res);
// Arrays.sort(res);
//对集合进行排序,需要用到Collections
Collections.sort(arraylist);
for(int i=0;i 第二题:TLV编码
2.1题目描述
TLV编码是按 Tag Length Value格式进行编码的
一段码流中的信元用tag标识,tag在码流中唯一不重复
length表示信元value的长度
value表示信元的值
码流以某信元的tag开头 ,tag固定占一个字节
length固定占两个字节,字节序为小端序
现给定tlv格式编码的码流以及需要解码的信元tag
请输出该信元的value
输入码流的16机制字符中,不包括小写字母
且要求输出的16进制字符串中也不要包含字符字母
码流字符串的最大长度不超过50000个字节
输入描述
第一行为第一个字符串 ,表示待解码信元的tag
输入第二行为一个字符串, 表示待解码的16进制码流
字节之间用空格分割
输出描述
输出一个字符串,表示待解码信元以16进制表示的value
例子:
输入:
31
32 01 00 AE 90 02 00 01 02 30 03 00 AB 32 31 31 02 00 32 33 33 01 00 CC
输出
32 33
说明:
需要解析的信源的tag是31
从码流的起始处开始匹配,tag为32的信元长度为1(01 00,小端序表示为1)
第二个信元的tag为90 其长度为2
第三个信元的tag为30 其长度为3
第四个信元的tag为31 其长度为2(02 00)
所以返回长度后面的两个字节即可
为 32 33
2.2解题思想
遍历字符数组
2.3代码实现
public static StringBuilder TLV(){
System.out.println("-------------");
Scanner sc=new Scanner(System.in);
String tag=sc.nextLine();
String str=sc.nextLine();
String[] str1=str.split(" ");
StringBuilder res=new StringBuilder();
for(int i=0;i2.4注意点
Stringbuffer和StringBuild的区别
StringBuffer与StringBuilder都提供了一系列插入、追加、改变字符串里的字符序列的方法,它们的用法基本相同,只是StringBuilder是线程不安全的,StringBuffer是线程安全的。如果只是在单线程中使用字符串缓冲区,则StringBuilder的效率会高些,但是当多线程访问时,最好使用StringBuffer。
综上,在执行效率方面,StringBuilder最高,StringBuffer次之,String最低,对于这种情况,一般而言,如果要操作的数量比较小,应优先使用String类;如果是在单线程下操作大量数据,应优先使用StringBuilder类;如果是在多线程下操作大量数据,应优先使用StringBuilder类。
16进制和10进制的转换
1.10进制转成16进制
Integer x = 666;
String hex = x.toHexString(x);
System.out.println(hex);打印出来的信息是“29a”,需要注意这里转换完的hex是字符串,值是16进制的一个数
2.16进制转成10进制
String hex = "fff";
Integer x = Integer.parseInt(hex,16);
System.out.println(x);打印的值为4095。
String hex = "0xfff";
Integer x = Integer.parseInt(hex.substring(2),16);//从第2个字符开始截取
System.out.println(x);打印结果也是4095
第三题:GPU最多一次执行n个任务
3.1题目描述:
为了充分发挥Gpu算力, 需要尽可能多的将任务交给GPU执行, 现在有一个任务数组, 数组元素表示在这1s内新增的任务个数, 且每秒都有新增任务, 假设GPU最多一次执行n个任务, 一次执行耗时1s, 在保证Gpu不空闲的情况下,最少需要多长时间执行完成。
输入描述
第一个参数为gpu最多执行的任务个数 取值范围1~10000
第二个参数为任务数组的长度 取值范围1~10000
第三个参数为任务数组 数字范围1~10000
输出描述
执行完所有任务需要多少秒
例子
输入
3
5
1 2 3 4 5
输出
6
说明,一次最多执行3个任务
最少耗时6s
例子2
输入
4
5
5 4 1 1 1
输出
5
说明,一次最多执行4个任务 最少耗时5s
3.2解题思路
这道题要细心读题,因为我最开始没理解题目意思,理解成最开始有n个任务,每个任务执行需要几秒,问最后所有任务执行完需要多久。
这道题的题目是这样的:
输入
4
5
5 4 1 1 1
输出
5
解释
gup每次可以执行4个任务
- 第一秒的时候有5个新的任务生成,gup可以执行其中的4个,还剩下一个没有执行
- 第二秒的时候有4个新的任务生成,有一个任务上一秒没有执行,所以还有5个任务没有执行,Gup可以执行其中的4个,剩下一个没有执行
- 第三秒的时候有1个新的任务,有一个任务上一秒没有执行,所以还有2个任务没有执行,gup可以执行这两个任务,没有剩余任务
- 第四秒的时候有1个新的任务,gup可以执行这个任务,没有剩余任务
- 第五秒的时候有1个新的任务,gup可以执行这个任务,没有剩余任务
所以最后花费时间为5秒
3.3代码实现
public static int gup(){
System.out.println("_______------");
Scanner sc=new Scanner(System.in);
int n=Integer.parseInt(sc.nextLine().trim());
int len=Integer.parseInt(sc.nextLine().trim());
String st=sc.nextLine();
System.out.println("_______------");
String[] str=st.split(" ");
int[] works=new int[len];
for(int i=0;in){
more=i+more-n;
}else{
more=0;
}
}
if(more>0){
time+=more/n;
if(more%n!=0){
time++;
}
}
System.out.println(time);
sc.close();
return time;
} 3.4注意
方法parseInt() :
parseInt() 方法用于将字符串参数作为有符号的十进制整数进行解析。
如果方法有两个参数, 使用第二个参数指定的基数,将字符串参数解析为有符号的整数。
//s -- 十进制表示的字符串。
//parseInt(String s): 返回用十进制参数表示的整数值。
static int parseInt(String s)
//parseInt(int i): 使用指定基数的字符串参数表示的整数 (基数可以是 10, 2, 8, 或 16 等进制数)
//radix -- 指定的基数。
static int parseInt(String s, int radix)例如:
public class Test{
public static void main(String args[]){
int x =Integer.parseInt("9");
double c = Double.parseDouble("5");
int b = Integer.parseInt("444",16);
//9
System.out.println(x);
//5.0
System.out.println(c);
//1092
System.out.println(b);
}
}第四题:身高排序
4.1题目描述
小明今年升学到了小学1年纪
来到新班级后,发现其他小朋友身高参差不齐
然后就想基于各小朋友和自己的身高差,对他们进行排序
请帮他实现排序
输入描述
第一行为正整数 h和n
04.2算法思想
使用两个数组,然后排序
4.3代码实现
// 小明身高排序
public static int[] statureclose(){
Scanner sc=new Scanner(System.in);
String[] nums=sc.nextLine().split(" ");
int xiaoming=Integer.parseInt(nums[0]);
int n=Integer.parseInt(nums[1]);
String str=sc.nextLine();
String[] classmates=str.split(" ");
int[] res=new int[n];
int[] temp=new int[n];
for(int m=0;mtemp[j]){
int flag0=temp[i];
temp[i]=temp[j];
temp[j]=flag0;
int flag1=res[i];
res[i]=res[j];
res[j]=flag1;
}else if(temp[i]==temp[j]){
if(res[i]>res[j]){
int flag0=temp[i];
temp[i]=temp[j];
temp[j]=flag0;
int flag1=res[i];
res[i]=res[j];
res[j]=flag1;
}
}
}
}
return res;
} 以上排序使用了冒泡排序
// 小明身高排序
public static int[] statureclose(){
Scanner sc=new Scanner(System.in);
String[] nums=sc.nextLine().split(" ");
int xiaoming=Integer.parseInt(nums[0]);
int n=Integer.parseInt(nums[1]);
String str=sc.nextLine();
String[] classmates=str.split(" ");
int[] res=new int[n];
int[] temp=new int[n];
for(int m=0;m=0&&flag0=0&&flag0=0&&flag0==temp[j]){
if(flag1 以上使用直接插入排序,赋值的时候就排序了
public static int[] statureclose(){
Scanner sc=new Scanner(System.in);
String[] nums=sc.nextLine().split(" ");
int xiaoming=Integer.parseInt(nums[0]);
int n=Integer.parseInt(nums[1]);
String str=sc.nextLine();
String[] classmates=str.split(" ");
int[] res=new int[n];
int[] temp=new int[n];
res[0] = Integer.parseInt(classmates[0]);
temp[0] = Math.abs(res[0] - xiaoming);
for(int i=1;i=0&&flag0=0&&flag0==temp[j]){
if(flag1 以上改进版直接插入排序,赋值的时候就排序了
使用ArrayList
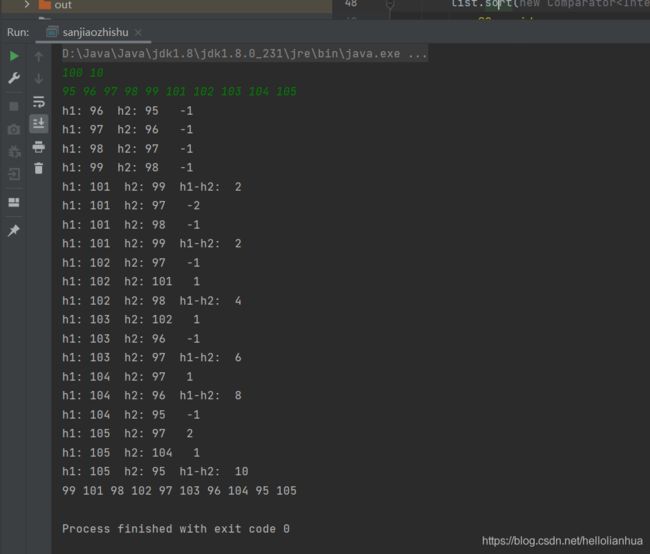
别人的答案,反正我是没有想到,现在还不是太理解sort这个重写的原理,把Compatrator的这个匿名类,打印了一下,大佬可以帮忙解释一下
Scanner in = new Scanner(System.in);
String[] split1 = in.nextLine().split(" ");
int h = Integer.parseInt(split1[0]);
String[] split2 = in.nextLine().split(" ");
ArrayList list = new ArrayList<>();
for (String s : split2) {
list.add(Integer.parseInt(s));
}
list.sort(new Comparator() {
@Override
public int compare(Integer h1, Integer h2) {
int d1 = h - h1;
int d2 = h - h2;
if ((d1 >0?d1:-d1)==(d2 >0?d2:-d2)){
return h1-h2;
}else return (d1 >0?d1:-d1)-(d2 >0?d2:-d2);
}
});
StringBuilder builder = new StringBuilder();
for (Integer integer : list) {
builder.append(integer).append(" ");
}
System.out.println(builder.toString().trim());
in.close();
}
返回的是比值,我看sort的底层,一层一层的有些绕,欢迎大佬指点一下。
4.4注意点
代码写少了,一个直接插入排序,写了很久找了很久的错误。所以要留心细节,同时在有计时的考试中选自己熟悉的算法,节约时间。
第五题:字符去重并按照ASCII码值从小到大排列
5.1题目描述
给定两个字符串
从字符串2中找出字符串1中的所有字符
去重并按照ASCII码值从小到大排列
输入字符串1长度不超过1024
字符串2长度不超过100
字符范围满足ASCII编码要求,按照ASCII由小到大排序
输入描述:
bach
bbaaccddfg
输出
abc
2
输入
fach
bbaaccedfg
输出
acf5.2解题思路
按照题意,先找到str2含有的字符,然后排序
5.3代码实现
public static void TreeSetExample(){
Scanner sc=new Scanner(System.in);
String str1=sc.nextLine();
String str2=sc.nextLine();
String[] s1=str1.split("");
TreeSet treeset=new TreeSet<>();
for (String i:s1)
{
if(str2.contains(i)){
treeset.add(i);
}
}
for (String re:treeset
) {
System.out.print(re);
}
} 5.4注意
5.4.1Java数组和字符串的相互转换
字符串转换为数组
)Java String 类中的 toCharArray() 方法将字符串转换为字符数组,具体代码如下所示。
String str = "123abc";
char[] arr = str.toCharArray(); // char数组
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]); // 输出1 2 3 a b c
}2)Java.lang 包中有 String.split() 方法,Java 中通常用 split() 分割字符串,返回的是一个数组。
String str = "123abc";
String[] arr = str.split("");
for (int i = 0; i < arr.length; i++) { // String数组
System.out.print(arr[i]); // 输出 1 2 3 a b c
}数组转换为字符串
1)char 字符数组转化为字符串,使用 String.copyValueOf(charArray) 函数实现,具体代码如下所示。
char[] arr = { 'a', 'b', 'c' };
String string = String.copyValueOf(arr);
System.out.println(string); // 输出abc2)String 字符串数组转化为字符串,代码如下所示。
String[] arr = { "123", "abc" };
StringBuffer sb = new StringBuffer();
for (int i = 0; i < arr.length; i++) {
sb.append(arr[i]); // String并不拥有append方法,所以借助 StringBuffer
}
String sb1 = sb.toString();
System.out.println(sb1); // 输出123abc一般使用append
Java深入了解TreeSet - 易之盛 - 博客园 (cnblogs.com)
5.4.2contains(i)
str2.contains(i)ArrayList底层实现contains方法的原理。 - 码农教程 (manongjc.com)
第六题:对数据进行分类
6.1题目描述:
对一个数据a进行分类
分类方法是 此数据a(4个字节大小)的4个字节相加对一个给定值b取模
如果得到的结果小于一个给定的值c则数据a为有效类型
其类型为取模的值
如果得到的结果大于或者等于c则数据a为无效类型
比如一个数据a=0x01010101 b=3
按照分类方法计算 (0x01+0x01+0x01+0x01)%3=1
所以如果c等于2 则此a就是有效类型 其类型为1
如果c等于1 则此a是无效类型
又比如一个数据a=0x01010103 b=3
按分类方法计算(0x01+0x01+0x01+0x03)%3=0
所以如果c=2则此a就是有效类型 其类型为0
如果c等于0 则此a是无效类型
输入12个数据
第一个数据为c 第二个数据为b
剩余10个数据为需要分类的数据
请找到有效类型中包含数据最多的类型
并输出该类型含有多少个数据
输入描述
输入12个数据用空格分割
第一个数据为c 第二个数据为b
剩余10个数据为需要分类的数据
输出描述
请找到有效类型中包含数据最多的类型
并输出该类型含有多少个数据
实例:
输入
3 4 256 257 258 259 260 261 262 263 264 265
输出
3
说明
这10个数据4个字节相加后的结果分别是
1 2 3 4 5 6 7 8 9 10
故对4取模的结果为
1 2 3 0 1 2 3 0 1 2
c是3所以012都是有效类型
类型为1和2的有3个数据
类型为0和3的只有两个
例子2
输入
1 4 256 257 258 259 260 261 262 263 264 265
输出
26.2解题思路
先把int类型的10进制数,转换成字节,以16位的形式,再将4个字节的内容相加。对于计数一般可以用map。
6.3代码实现
public static void fenlei(){
Scanner sc=new Scanner(System.in);
String[] nums=sc.nextLine().trim().split("\\s+");
int c=Integer.parseInt(nums[0]);
int b=Integer.parseInt(nums[1]);
HashMap hashMap=new HashMap<>();
for(int i=2;imax){
max=i;
}
}
System.out.println("jieguo");
System.out.println(max);
}
//将10进制的数转换成字节,并将字节的值相加
public static int jinzhi(int n){
int sum=0;
for(int i=0;i<4;i++){
System.out.println((n>>(i*8))&0xFF);
sum+=(n>>(i*8))&0xFF;
}
System.out.println("_____________");
System.out.println(sum);
return sum;
} 6.4注意
6.4.1向右移8位
(n>>(i*8))&0xFF同样的效果如下:
(byte) (x >> (i * 8))Java中的三个移位运算符:">>","<<",">>>"
1. ">>"表示将一个二进制表示的数字进行右移操作,如n>>2,相当于将数字n右移两位,也就是将n除以4的结果。
2."<<"表示将一个二进制表示的数字进行左移操作,如n<<2,相当于将数字n左移两位,也就是将n乘4的结果。
在执行以上位移操作时,由于计算机中使用补码存储数字,对于正数来说,补码等于原码,所以直接进行相应的左移或者右移操作,并在高位或者低位补上即可,特别要注意的是,右移操作时,低位直接舍去;而左移操作时舍去高位会发生溢出使结果出错。如:有一个八位二进制数0100 1010,右移两位变为0001 0010,相当于原数除以4;左移两位变为0010 1000结果溢出。
对于负数来说,补码等于原码按位取反后,末位加1,且最高位为符号位。这时进行位移操作,当右移时高位补充符号位即补1,左移时低位补0。如八位二进制数1100 0100,左移一位后为1000 1000,右移一位后为1110 0010,原数为-60,左移后为-120,右移后为-30。
3.">>>"表示无符号数的右移操作,因为忽视符号位,所以在高位一律补0。
首先解释一下0xFF,这代表的是十六进制数FF即1111 1111,对应十进制即为255,当一个数n对这个 0xFF 作 & 操作时,相当于求n除以256所得的余数,也就是相当于n%256
设一个十六位二进制数1010 1100 0100 0001要作&FF操作,即将这两个数按位“与”
1010 1100 0100 0001
0000 0000 1111 1111
所的结果为0000 0000 0100 0001
可以看到这个数即为1010 1100 0100 0001除以256的余数。
同理&0x03、&0x0F即为求一个数除以4、除以16所得的余数。
6.4.1位移原文链接:https://blog.csdn.net/u012198209/article/details/79627665
6.4.2HashMap
HashMap
hashMap.put(res,hashMap.containsKey(res)?hashMap.get(res)+1:1); hashMap.values()Map集合的特点:
1、Map集合一次存储两个对象,一个键对象,一个值对象
2、键对象在集合中是唯一的,可以通过键来查找值
HashMap特点:
1、使用哈希算法对键去重复,效率高,但无序
2、HashMap是Map接口的主要实现类
第七题:最长的指定瑕疵度的元音子串
7.1题目描述
开头和结尾都是元音字母(aeiouAEIOU)的字符串为元音字符串,其中混杂的非元音字母数量为其瑕疵度。比如:
‘a’,‘aa'是元音字符串,其瑕疵度为0
’aiur'不是元音字符串(结尾不是元音字符)
第八题:从根节点到最小的叶子节点的路径
8.1题目描述
第九题:词语接龙
import java.util.ArrayList;
import java.util.Scanner;
import java.util.TreeSet;
import java.util.concurrent.BrokenBarrierException;
/**
* Created with IntelliJ IDEA.
* Author: Amos
* E-mail: [email protected]
* Date: 2020/11/30
* Time: 12:42
* Description:
*/
public class Demo16 {
public static void main(String[] args) {
/*
单词接龙的规则是
可用于接龙的单词 首字母必须要与前一个单词的尾字母相同
当存在多个首字母相同的单词时,取长度最长的单词
如果长度也相等,则取字典序最小的单词
已经参与接龙的单词不能重复使用
现给定一组全部由小写字母组成的单词数组
并指定其中一个单词为起始单词
进行单词接龙
请输出最长的单词串
单词串是单词拼接而成的中间没有空格
输入描述
输入第一行为一个非负整数
表示起始单词在数组中的索引k
0<=k list = new ArrayList<>();
for (int i = 0; i < N; i++) {
list.add(in.nextLine());
}
StringBuilder builder = new StringBuilder();
String head = list.get(k);
builder.append(head);
list.remove(k);
String tail = head.substring(head.length() - 1);
while (true) {
TreeSet set = new TreeSet<>();
for (int i = 0; i < list.size(); i++) {
String word = list.get(i);
if (word.startsWith(tail)) {
set.add(word);
}
}
if (set.size() == 0) break;
String first = set.pollFirst();
int len = first.length();
String aim = "";
for (String s : set) {
if (s.length() > len) {
len = s.length();
aim = s;
}
}
String into = len != first.length() ? aim : first;
tail = into.substring(into.length() - 1);
builder.append(into);
list.remove(into);
}
System.out.println(builder.toString());
in.close();
}
} 第十题:连续出现次数第k多的字母的次数
会错意版本
public static void chongfuzichuan(){
Scanner in = new Scanner(System.in);
String line = in.nextLine();
int k = in.nextInt();
HashMap map = new HashMap<>();
char[] chars = line.toCharArray();
if (chars.length == 0) {
System.out.println(-1);
}
StringBuilder strbuild=new StringBuilder();
strbuild.append(chars[0]);
int count=1;
HashMap hashmap=new HashMap<>();
for (int i=1;i arrayList=new ArrayList<>();
for (String c:hashmap.keySet()
) {
arrayList.add(c+":"+hashmap.get(c));
System.out.println(c+":"+hashmap.get(c));//AA:2
//AAA:3
//B:1
}
arrayList.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o1.split(":")[1].compareTo(o2.split(":")[1]);
}
});
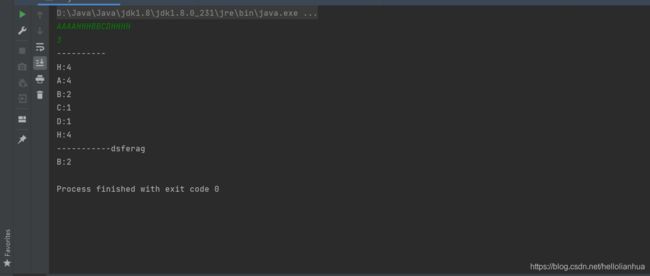
if(arrayList.size() 运行结果如下
真正的题意与解题方法
import java.util.*;
/**
* Created with IntelliJ IDEA.
* Author: Amos
* E-mail: [email protected]
* Date: 2020/12/5
* Time: 17:39
* Description:
*/
public class Demo17 {
public static void main(String[] args) {
/*
给定一个字符串
只包含大写字母
求在包含同一字母的子串中
长度第K长的子串
相同字母只取最长的子串
输入
第一行 一个子串 1 map = new HashMap<>();
char[] chars = line.toCharArray();
if (chars.length == 0) {
System.out.println(-1);
return;
}
char cur = chars[0];
int count = 1;
map.put(cur, count);
for (int i = 1; i < chars.length; i++) {
char c = chars[i];
if (c == cur) count++;
else {
cur = c;
count = 1;
}
map.put(cur, map.containsKey(cur) ?
map.get(cur) > count ? map.get(cur) : count :
count);
}
ArrayList list = new ArrayList<>();
for (Map.Entry entry : map.entrySet()) {
list.add(entry.getKey() + "-" + entry.getValue());
}
list.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o2.split("-")[1].compareTo(o1.split("-")[1]);
}
});
if (k > list.size()) System.out.println(-1);
else System.out.println(list.get(k - 1).split("-")[1]);
in.close();
}
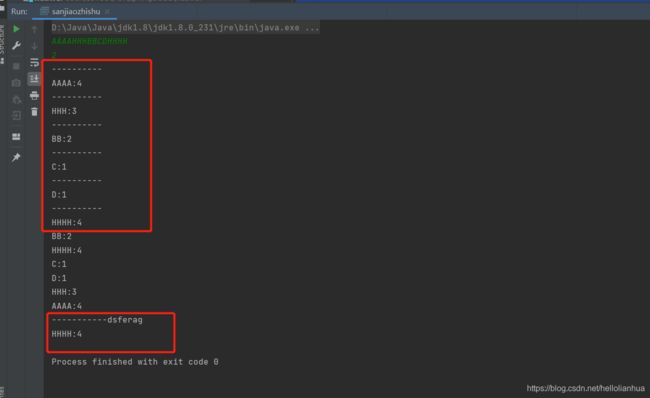
} 意识到自己错了,过后的修改代码
public static void chongfuzichuan(){
Scanner in = new Scanner(System.in);
String line = in.nextLine();
int k = in.nextInt();
char[] chars = line.toCharArray();
if (chars.length == 0) {
System.out.println(-1);
}
HashMap hashmap=new HashMap<>();
int count=1;
hashmap.put(chars[0],count);
for (int i=1;ihashmap.get(chars[i-1])){
hashmap.put(chars[i-1],count);
}
}else{
hashmap.put(chars[i-1],count);
}
count=1;
if(i==chars.length-1){
hashmap.put(chars[i],count);
}
}
}
ArrayList arrayList=new ArrayList<>();
for (char c:hashmap.keySet()
) {
arrayList.add(c+":"+hashmap.get(c));
System.out.println(c+":"+hashmap.get(c));//AA:2
//AAA:3
//B:1
}
arrayList.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o1.split(":")[1].compareTo(o2.split(":")[1]);
}
});
if(arrayList.size() 运行结果