Poly-YOLO 学习
关于
Poly-YOLO建立在YOLOv3的原始思想的基础上,并消除了它的两个弱点:标签重写和anchor分配不平衡。
标签重写:由于YOLO系列都是基于图像cell栅格作为单元进行检测,以416*416大小的图像为例,在图像分辨率随着卷积下降到13*13的特征图大小时,这时候特征图一个像素点的感受野是32*32大小的图像patch,YOLOV3在训练时候,如果出现相同两个目标的中心位于同一个cell,且分配给同一个anchor,那么前面一个目标就会被后面目标重写,也就是说两个目标由于中心距离太近以至于在特征图上将采样成为同一个像素点的时候,这时候其中有个目标会被重写而无法进行到训练当中。结果导致,网络训练时会忽略一些目标,导致正样本数量非常少,特别是存在于分辨率比较低的特征图中。
Anchor分配不平衡:yolov3中采用kmeans算法聚类得到特定的9个anchor,并且以每三个为一组,大输出图检测小物体,中等输出图和小输出图层检测大物体)。一个特定的GroundTruth框与哪个scale的anchor匹配度最高,就会被指定给哪个scale,正常情况下应该是不同大小的物体会被这三组anchor分配到不同预测层进行预测。但是这种分配机制只适用于标准分布M~ U(0,r),然而,在实际问题中,目标框大小不会分布的这么理想化,就会造成某些尺度的特征层未被充分利用。
1)标签重写改进
1、增加输入图片分辨率大小;
2、增加输出特征图大小实现。
Poly-YOLO作者的做法是增加输出特征图大小。
2)Anchor分配问题的改进
KMeans聚类算法详解:KMeans聚类算法详解 - 知乎“如果把人工智能比作一块大蛋糕,监督学习只是上面的一层奶油“。日常生活中,从人脸识别、语音识别到搜索引擎,我们看到越来越多人工智能领域的算法逐渐走向落地。尽管全球每日新增数据量以PB或EB级别增长,但是…
https://zhuanlan.zhihu.com/p/184686598
对于kmean聚类带来的问题,有两种解决办法:
-
kmean聚类流程不变,但是要避免出现小物体被分配到小输出特征图上面训练和大物体被分配到大输出特征图上面训练问题,具体就是首先基于网络输出层感受野,定义三个大概范围尺度,然后设置两道阈值,强行将三个尺度离散化分开;然后对bbox进行单独三次聚类,每次聚类都是在前面指定的范围内选择特定的bbox进行,而不是作用于整个数据集。主要是保证kmean仅仅作用于特定bbox大小访问内即可,就可以避免上面问题了。但是缺点也非常明显,如果物体大小都差不多,那么几乎仅仅有一个输出层有物体分配预测,其余两个尺度在那里空跑,浪费资源。
-
就只有一个输出层,所有物体都是在这个层预测即可。可以避免kmean聚类问题,但是为了防止标签重写,故把输出分辨率调高,此时就完美了。作者实际上采用的是1/4尺度输出,属于高分辨率输出,重写概率很低。
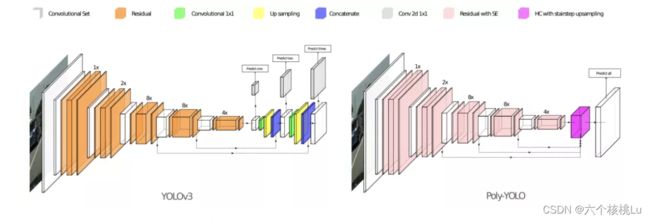
根据上图可以发现:
(1) 网络方面,为了减少参数量,首先减少了通道数目,同时为了提高性能,引入了squeeze-and-excitation(SE)单元来加强特征
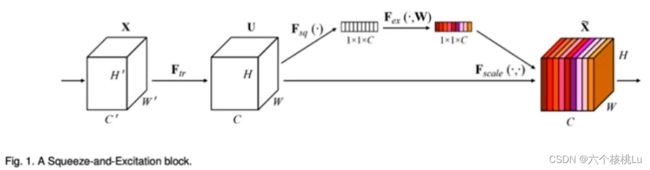
通过对卷积得到的C个feature map进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将该分数分别施加到对应的通道上,得到其结果,就在原有的基础上只添加了一个模块。通过(SE)块和提高输出分辨率,降低了计算速度。由于速度是YOLO的主要优势,作者在特征提取阶段减少了卷积滤波器的数量,即设置为原始数的75%。
(2) 和YOLOv3的最大区别是输出层是一个,但是也采用了多尺度融合方式
(3) neck部分提出了hypercolumn+stairstep上采样操作
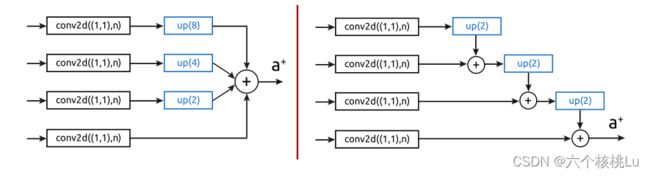
左侧是HC方案插图,右侧是带有阶梯的HC
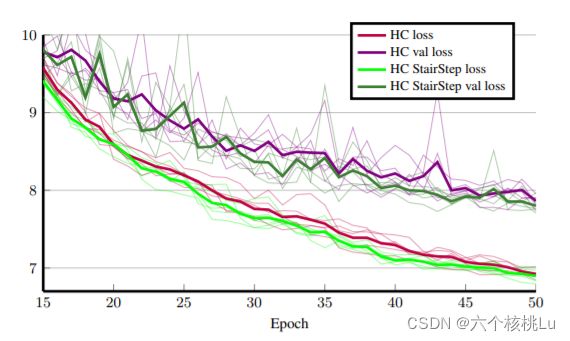
损失函数如上图,显示了使用标准超柱技术和阶梯超柱技术在损失方面的差异,细线表示特定的学习运行,粗线表示运行的平均值
使用Poly-YOLO进行实例分段
1)多边形框原则
通过不规则四边形检测更精确地检测YOLO,证明了四边形检测的扩展收敛速度更快,还证明了基于四角逼近的分类方法比基于矩形逼近的分类方法具有更高的精度。
该方法的局限性在于检测到的顶点数目固定,即4个。在这里,引入了一种多边形表示,它能够检测具有不同数量顶点的对象,而不需要使用会降低处理速度的循环神经网络。为了了解边界盒检测和基于多边形的检测质量之间的实际区别。
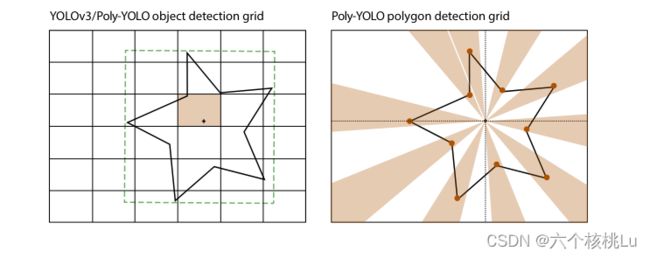
左图:矩形网格,取自YOLOv3。对象的边界框有其中心的单元格可以预测其边界框的坐标。右图:Poly-YOLO中基于圆形扇区的网格,用于多边形顶点的检测。网格的中心与对象的包围框的中心重合。然后,每个圆形扇形负责检测特定顶点的极坐标。没有顶点的扇区,其置信度应该等于零。
2)与Poly-YOLO集成
检测边界多边形的思想是普遍的,可以很容易地集成到一个任意的神经网络。一般来说,需要修改三个部分:数据准备的方式、体系结构和丢失函数。在Poly-YOLO,输出层中卷积滤波器的数量必须更新。当我们只检测box时,最后一层输出维度为n=![]() (
(![]() + 5),
+ 5),![]() =9 (anchor个数),
=9 (anchor个数),![]() 为类别数。对基于多边形的目标检测进行集成,得到n=
为类别数。对基于多边形的目标检测进行集成,得到n=![]() (
(![]() + 5+ 3
+ 5+ 3![]() ),
),![]() 为每个多边形检测到的顶点数的最大值。
为每个多边形检测到的顶点数的最大值。
损失函数: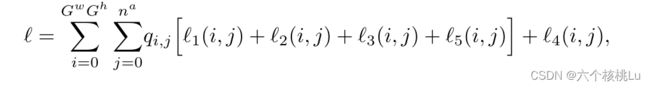
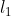 (i, j) 是对边界框中心的预测的损失,
(i, j) 是对边界框中心的预测的损失, (i, j) 是对框的尺寸的损失,
(i, j) 是对框的尺寸的损失,![]() (i, j) 是置信度损失,
(i, j) 是置信度损失,![]() (i, j) 是类预测损失,
(i, j) 是类预测损失,![]() (i, j) 是由距离,角度和顶点置信度预测组成的边界多边形的损失,
(i, j) 是由距离,角度和顶点置信度预测组成的边界多边形的损失,![]() ∈{0,1}是一个常数,指示第i个单元格和第j个锚点是否包含标签。
∈{0,1}是一个常数,指示第i个单元格和第j个锚点是否包含标签。

论文地址:https://arxiv.org/pdf/2005.13243.pdf
源代码:IRAFM AI / Poly-YOLO · GitLab
参考文章:Poly-YOLO:更快,更精确的检测(主要解决Yolov3两大问题,附源代码)
参考视频:AI论技第一期《目标检测模型 Poly-YOLO详解与应用》_哔哩哔哩_bilibili