Yolo-v3算法改进-Poly-Yolo-v3
论文名称:Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3
论文地址:https://arxiv.org/abs/2005.13243v2
本文很有意思,实用性很强,是本人比较推荐的论文。因为各大算法评价性能都是在比赛数据上测试的,但是在实际项目数据上可能就不太好用了,主要原因是实际项目数据有自己的特点,如果完全照搬,效果可能不那么好。本文所提出的改进版本yolo就是在特定场景下所提出的改进算法,分析问题的思路非常好,值得学习。
1 yolov3存在的问题
(1) 标签被重写问题
 标签重写是指由于yolo特有的网格负责预测bbox的特点,可能会出现两个物体分配给了同一个anchor,导致仅仅有一个物体被保留负责预测,另一个物体被当做背景忽略了。当输入分辨率越小,物体越密集,物体的wh大小非常接近时候,标签重写现象比较严重。如上图所示,红色表示被重写的bbox,可以看出27个物体有10个被重写了。
标签重写是指由于yolo特有的网格负责预测bbox的特点,可能会出现两个物体分配给了同一个anchor,导致仅仅有一个物体被保留负责预测,另一个物体被当做背景忽略了。当输入分辨率越小,物体越密集,物体的wh大小非常接近时候,标签重写现象比较严重。如上图所示,红色表示被重写的bbox,可以看出27个物体有10个被重写了。
具体来说,以416 416大小的图像为例,在图像分辨率随着卷积下降到13 * 13的特征图大小时,这时候特征图一个像素点的对应是3232大小的图像patch。而YOLOV3在训练时候,如果出现相同两个目标的中心位于同一个cell,且分配给同一个anchor,那么前面一个目标就会被后面目标重写,也就是说两个目标由于中心距离太近以至于在特征图上将采样成为同一个像素点的时候,这时候其中有个目标会被重写而无法进行到训练当中。
这种现象在coco数据上不明显的原因是bbox分布比较均匀,不同大小物体会分配到不同预测层,标签重写概率比较低。但是在很多实际应用中,比如工业界的特定元件检测时候,物体排布非常紧密,且大小几乎一致,此时就可能会出现标签重写问题了,作者论文指出在Cityscapes数据上该现象也比较明显。
(2) kmean计算anchor存在的问题
yolo系列采用kmean算法聚类得到特定要求的9个anchor,并且以每三个为一组,用于大输出图(检测小物体),中等输出图和小输出图层(检测大物体)的默认anchor。可以看出不同大小的物体会被这三组anchor分配到不同预测层进行预测。
但是这种kmean算法得出的结果是有问题的,在实际项目中也发现了。前面说过大部分特定场景的目标检测数据集,并不是和coco自然场景一样,啥尺度都有,实际项目中大部分物体都是差不多大的,或者说仅仅有特定的几种尺度,此时采用kmean这一套流程就会出现:几乎一样大的物体被强制分到不同层去预测,这个训练方式对网络来说非常奇怪,因为物体和物体之间wh可能就差了一点点,居然强制分层预测,这明显不合理。本文作者生成的仿真数据其实也是这个特点。
作者论文指出,kmean这种设置,仅仅在: [公式] 情况下采用合理的。其中r是输入图片分辨率,例如416。该式子的意思是物体的大小分布是满足边界为0到r的均匀分布,也就是说在416x416图片上,各种大小尺度的bbox都会存在的情况下,kmean做法是合理的。但是可能大部分场景都是: [公式] 即均值为0.5r,标准差为r的物体分布,如果按照默认的kmean算法对anchor的计算策略,那么由于大部分物体都是中等尺寸物体,会出现其余两个分支没有得到很好训练,或者说根本就没有训练,浪费网络。
(3) 仿真分析
为了说明上面问题,作者假设两个box:m1和m2;前者与放置在高速公路上的摄像头的车牌检测任务相连接,模拟全部是小物体检测任务,后者与放置在车门前的摄像头的人检测任务相连接,模拟全部是大物体检测任务。对于这样的任务,我们可以获得大约 [公式] ,因为这些牌将会覆盖小的区域,而 [公式] 因为人类将会覆盖大的区域。
对于M1场景,基本都是小物体,采用kmean会强制区分不同大小物体分配到三个层预测,那么就会出现小物体被分配到小输出特征图上面训练,那么首先标签重写问题会出现;并且小输出特征图检测小物体是比较困难的,可能会丢失。 对于M2场景,基本都是大物体,会出现大物体被分配到大输出特征图上面训练,那么会出现由于物体过大在浅层特征图上检测效果比较差,也就是常说的语义信息不够。
不仅仅有上面存在的问题,我们通常知道物体在哪个尺度检测,应该要和网络的输出感受野相匹配才是最佳的,无数论文已经验证了这个道理,例如s3fd等等。前面说的大输出特征图检测小物体,小输出特征图检测大物体,也是基于感受野的原则来定义的。作者分析了yolov3三个输出层的感受野大概是(85 × 85, 181 × 181, 365 × 365)。在物体大小都差不多情况下,强行采用kmean策略分配anchor,明显就已经不符合感受野的设定了,效果肯定不是最好的。
作者支持yolov3中反应的high APsmall,但是中等尺度和大输出物体检测性能不佳,可能就是由于上面出现的问题导致的。
2 解决办法
对于标签重新问题,没有啥特别好的办法,只能通过要么增加输入图片分辨率大小;要么增加输出特征图大小实现。本文的做法是增加输出特征图大小。
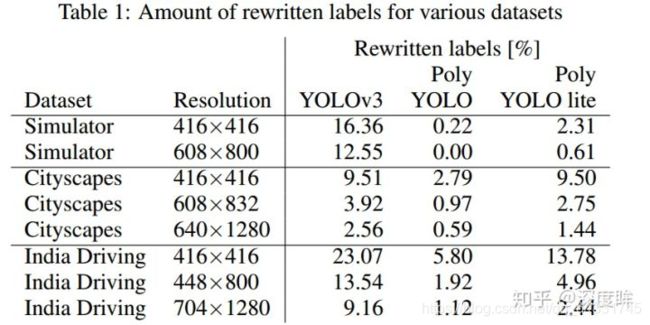
原始的yolov3,输入大小是输出特征图的8/16和32倍,通过上述数据可以发现标签重写比例蛮高的。而通过增加输出特征图大小后可以显著降低重写比例。
而对于kmean聚类带来的问题,有两种解决办法:
(1) kmean聚类流程不变,但是要避免出现小物体被分配到小输出特征图上面训练和大物体被分配到大输出特征图上面训练问题,具体就是首先基于网络输出层感受野,定义三个大概范围尺度,然后设置两道阈值,强行将三个尺度离散化分开;然后对bbox进行单独三次聚类,每次聚类都是在前面指定的范围内选择特定的bbox进行,而不是作用于整个数据集。主要是保证kmean仅仅作用于特定bbox大小访问内即可,就可以避免上面问题了。但是缺点也非常明显,如果物体大小都差不多,那么几乎仅仅有一个输出层有物体分配预测,其余两个尺度在那里空跑,浪费资源。
(2) 就只有一个输出层,所有物体都是在这个层预测即可。可以避免kmean聚类问题,但是为了防止标签重写,故把输出分辨率调高,此时就完美了。作者实际上采用的是1/4尺度输出,属于高分辨率输出,重写概率很低。
3 poly-yolo
基于前面的思想,作者设计的网络如下:

一些细微的网络改动就不说了,作者开源了代码,可以直接看出来。
(1) 网络方面,为了减少参数量,首先减少了通道数目,同时为了提高性能,引入了SE单元来加强特征
(2) 和yolov3的最大区别是输出层是一个,但是也采用了多尺度融合方式
(3) neck部分提出了hypercolumn+stairstep上采样操作
其示意图如下所示:
 左边是标准的hypercolumn操作,右边是作者提出的。实验表明右边的方式更好,因为loss更低。
左边是标准的hypercolumn操作,右边是作者提出的。实验表明右边的方式更好,因为loss更低。
 通过上述参数设置,作者设计的neck和head较轻,共有37.1M的参数,显著低于YOLOv3的61.5M,Poly-YOLO比YOLOv3的精度更高,在可训练参数减少40%的情况下,mAP精度大概也提高了40%。。同时为了进一步提速,作者还设计了lite版本,参数仅仅16.5M,精度和yolov3差不多
通过上述参数设置,作者设计的neck和head较轻,共有37.1M的参数,显著低于YOLOv3的61.5M,Poly-YOLO比YOLOv3的精度更高,在可训练参数减少40%的情况下,mAP精度大概也提高了40%。。同时为了进一步提速,作者还设计了lite版本,参数仅仅16.5M,精度和yolov3差不多
作者还强调了,本文设计的仅仅是一种思想,如果采用最新的骨架网络替换,应该可以得到一个更加高效,精度更高的poly yolov3版本。
对于采用poly yolov3进行实例分割,本文不打算分析,因为我关心的是论文所提出的两个问题以及解决办法而已。性能如下:
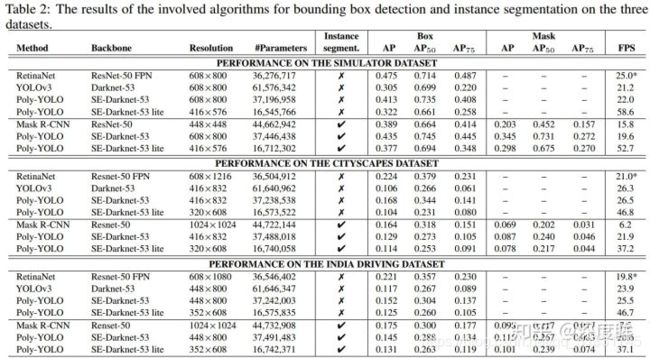
总结下:yolov3由于特殊的网格预测模式,当物体比较密集且大小差不多时候,会存在大量的标签重写现象;并且在该场景下基于kmean计算得到的anchor会出现物体预测尺度和感受野不符的问题,导致整个优化过程不是最优的。针对上述问题,作者提出采用单尺度预测,且维持高输出分辨率特征图的策略来解决上述问题。为了加速和进一步提高性能,采用了se单元、hypercolumn+stairstep上采样特征聚合方式来加强特征提取能力。从而实现了在参数大幅减少情况下,mAP提升解决40%。可以说本文是为了特定场景应用所提出的改进,不一定适合coco这种自然场景物体分布均匀的场景。