Global attention与 Soft attention ——论文笔记
论文:Effective Approaches to Attention-based Neural Machine Translation 地址: https://www.aclweb.org/anthology/D15-1166/
1-2节:首先,介绍了Neural machine translation 模型,机器翻译系统是一个神经网络,它直接模拟将源句子x1,…,xn翻译成目标句子y1,…,xn的条件概率,同一时刻只输出一个单词(或字母)。因此概率公式为:

(概率乘积在取log的情况下是相加)。
每个时刻的输出概率公式为:
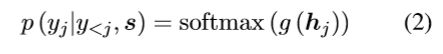
g是一个转换函数。其中hj是一个隐层状态,计算公式:

hj由前一个隐状态和输入得到。
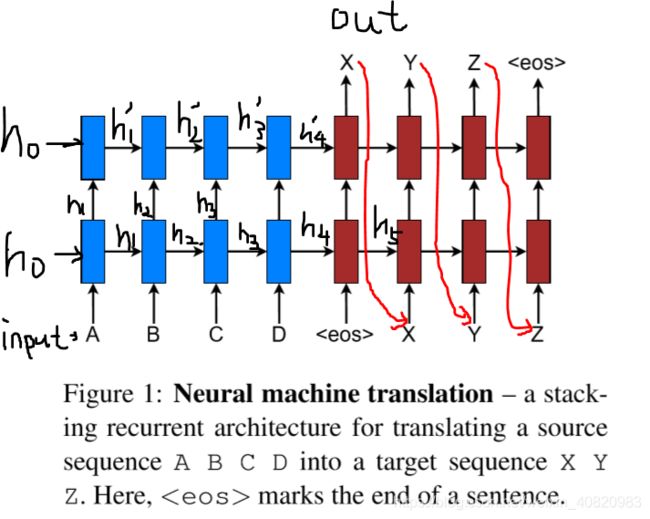
Neural machine translation 模型如下图所示,输入为ABCD等单词序列,输出为XYZ等,eoc为句子结束符号。在标准的模型中,上一时刻的输出X,作为下一时刻的输入。蓝色是encoder的双层RNN,下层的输出作为上层的输入。红色是decoder的双层RNN。
在本文中,注意力隐藏状态ht~,由上下文向量ct和目标隐藏状态ht组合而来:

最终,注意力隐藏状态经过softmax产生预测分布(我们想要的预测结果):

下面讲如何计算ct。
3节: 全局注意力机制 Global attention

全局注意力机制中,encoder端的所有隐藏状态hs都参与到ct的计算中,at是它们的权值,权重越大代表这个位置的输入越重要。
at计算公式如下,由hs和decoder端的隐藏状态ht做align(对齐、匹配、求相关性)得到,下式是为了归一化。

其中,score是一个基于内容的函数(content-based funtion),可以用以下方式得到:
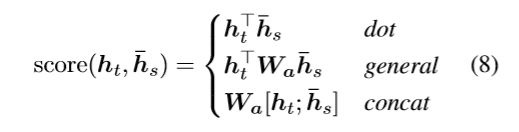
局部注意力机制(Local attention) :

考虑到并不是所有的输入单词都对当前这个输出有影响,为了减少不必要的计算,只选择一部分的隐藏状态用来计算ct。这个选择窗口为![]() ,pt是输入序列中的某一个位置,D为窗口大小(人为设定)。为了确定pt,有两种方法:
,pt是输入序列中的某一个位置,D为窗口大小(人为设定)。为了确定pt,有两种方法:
Monotonic alignment (local-m):假设输入与输出的位置是一一对应的(单调对齐),t位置的输入对t位置的预测影响最大,则pt=t
Predictive alignment (local-p) : ,s是输入序列的长度,wp vp是训练的参数。该式使得pt在[0,s]范围内。为了使点尽量靠近pt,设置一个以pt为中心的高斯分布:
,s是输入序列的长度,wp vp是训练的参数。该式使得pt在[0,s]范围内。为了使点尽量靠近pt,设置一个以pt为中心的高斯分布:

s是以pt为中心的窗口内的点。方差为D/2。
3.3 Input-feedingApproach

就是把上一次的预测作为下一次的输入,对后续的预测继续产生影响。