Java初级知识复习-2021.12.27~2022.02.09
文章目录
- Java语法基础1
-
- 1、Java简介
-
- Java三大版本含义
- Java的特性和核心优势
- 2、Java开发环境配置
-
- Java应用程序的运行机制
- 开发环境搭建
- 3、Java基础语法
- 4、Java基本数据类
- 5、Java修饰符
-
- 访问权限修饰符:
- 非访问权限修饰符
- 接口修饰符
- 6、Java运算符
- 7、Java对象和类简介
-
- 类
- 对象
- Java语法基础2
-
- 1、Java流程结构
-
- 基础结构
- 选择结构
- switch选择结构
- 循环语句
- 2、Java数组
- 3、枚举
- 面向对象
-
- 1、理解面向对象
- 2、类与对象
- 3、构造方法
- 封装
-
- 1、包
- 2、访问权限修饰符
- 3、接口与实现
- 继承
-
- 1、继承的语法
- 2、向上转型
- 3、final关键字
- 多态
-
- 1、理解多态
- 2、多态的表现形式(3种)
-
- 多态的编译和运行
- 3、重载与重写
- 抽象类与接口
-
- 1、抽象类和方法
- 2、接口定义与使用
- 3、抽象类和接口
- 集合框架
-
- 1、集合的基本概念
- 2、集合的使用
- 3、列表List
- 4、集合Set
- 5、映射Map
- 6、迭代器iterators
-
- Iterator接口
- 集合工具类Collections(注意不是Collection接口)
- 数组工具类 Arrays
- 如何选用集合?
- 7、理解java泛型概念
- 8、学会在函数和类定义时使用泛型
-
- 泛型类
- 泛型接口
- 泛型方法
-
- 泛型方法的基本用法
- 泛型方法与可变参数
- 9、java序列化
-
- 序列化定义
- 实现序列化的方式
- 使用Serializable接口实现序列化
- 序列化版本号serialVersionUID
- 序列化的总结
- 字符串
-
- 1、字符串的不可变
- 2、字符串操作
-
- 字符串初始化赋值和输出
- 合并
- 比较
- 获取
- 判断某一子字符串是否包含在该字符之中
- 替换
- 3、StringBuffer和StringBuilder
- 重要的JDK类库
-
- 1、Object类
-
- Object类提供了11个方法
- 2、Java日期时间
-
- Date类
- DateFormat类
- 3、BigDecimal类
-
- BigDecimal构造方法
- BigDecimal类成员方法
- BigDecimal应用例子
- 4、其他重要的JDK库
- IO
-
- 1、输入、输出流的定义与使用
- 2、文件的操作
- 3、Reader和Writer
- 4、IO流典型用途
- 数据库编程
-
- 1、JDBC的使用
-
- 程序员,JDBC,JDBC驱动的关系及说明
- JDBC总结
-
- JDBC可以做三件事:与数据库建立连接、发送操作数据库的语句、处理结果
- JDBC连接数据库的步骤:
- JDBC连接数据库相关的知识总结
- 2、数据库连接池
-
- 数据库连接池技术的优点
- 数据库连接池
-
- (1)C3P0数据库连接池
- (2)DBCP数据库连接池
- (3)Druid数据库连接池
- 3、JDBC事务
-
- MySQL事务
- JDBC事务处理
- Java异常
-
- 1、异常的定义与使用
- 2、常用异常(Exception)类型
- 3、finally关键字
- Socket网络编程
-
- 1、理解TCP、UDP协议
- 2、Java Socket编程
-
- 服务器接收客户端发送数据的例子
- 多线程
-
- 1、理解多线程的概念
- 2、能够使用多线程并发编程
-
- 线程创建
- 总结 ❤
- 静态代理
- 线程状态(5个)
- 停止线程
- 线程休眠
- 线程礼让
- 3、了解JAVA锁机制
-
- 死锁
- 线程通信
- 4、JDK线程池的使用
- 注解
-
- 1、 注解的定义与使用
-
- Java内置的注解
- 利用反射获取注解
- WebService
-
- 1、什么是WebService?什么是Soap?
- 2、如何编写WebService的服务器端与客户端
- 3、 调用ESB的soap报文的N种方式
-
- WebService调用ESB的方式
Java语法基础1
1、Java简介
Java并不是一种语言,Java是一个完整的平台,有一个庞大的库,其中包含了很多可重用的代码和一个提供诸如安全性、跨操作系统的可移植性以及自动垃圾收集等服务的执行环境。
Java面型对象的三大基本特征:封装、集成和多态。 其中封装性实现了模块化和信息隐藏;继承性实现了代码的复用,用户可以建立自己的类库;多态就是同一消息可以根据发送对象的不同而采用多种不同的行为方式。
Java三大版本含义
- JavaSE(Java Standard Edition):标准版本,定位在个人计算机上使用。
- JavaEE(Java Enterprise Edition):企业版,定位在服务器端的应用。【主流】
- JavaME(Java Micro Edition):微型版,定位在消费性电子产品的应用上。
Java的特性和核心优势
Java核心优势:跨平台和可移植性
特性:简单性、可移植性、面向对象、解释型、网络技能、高性能、健壮性、多线程、安全性、动态性、体系结构中立。
2、Java开发环境配置
-
JDK(Java Development Kit):java开发工具包,包含JRE,以及增加编译器和调试器,等于程序开发的文件。Java的集成开发环境(IDE)如Eclipse、IDEA等都依赖于JDK,需要配置环境变量。(开发的包,编写java程序的程序员使用的软件)
JRE(Java Runtime Environment):包含Java虚拟机、库函数、运行Java应用程序所必须的文件。(运行的包,运行java程序的用户使用的软件)
JVM(Java Virtual Machine):虚拟的用于执行bytecode字节码的虚拟计算机,和操作系统打交道。(虚拟机)
通过JVM,程序避免了直接和操作系统打交道,只需要和虚拟机打交道就可以,这是实现跨平台的一个核心机制。 -
JDK=JRE+JAVA开发工具
JRE=JVM+lib类库 -
JAVA_HOME是当jdk版本改变的时候直接去修改这里边的环境变量,不用修改Path里的环境。
Java应用程序的运行机制
Java首先利用文本编辑器编写Java源程序,源文件的后缀名为.java;再利用 编译器(javac) 将源程序变异成字节码文件,字节码文件的后缀名为.class;最后利用 虚拟机(解释器,java) 解释执行。
Java运行原理:
(1)编写java源程序,扩展名.java;
(2)cmd窗口输入:javac 源文件名.java,对源代码进行编译,生成class字节码文件;
(3)输入命令:java HelloWorld,对class字节码文件解释运行。
开发环境搭建
- 下载JDK,解压,运行
- 设置环境变量:
(1)将JDK/bin目录添加到Path环境变量中:环境变量 - Path变量后追加:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;- 点击确认
(2)新建环境变量 - 变量名JAVA_HOME - 变量值是JDK的安装路径 - 点击确认
新建CLASSPATH变量 - 变量值写
%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
- 检验是否配置成功:运行cmd,输入
java -version,若出现相应的java版本,则配置成功。或者输入javac指令,看能否识别到该指令
3、Java基础语法
- 标识符:由程序员指定的名字
命名规范:区分大小写;由字母、数字、下划线、美元符组成,不能用数字开头;关键字不能作为标识符; - 关键字:是java中已经定义好的字符序列,不能挪作它用。foreach、each、in不是java的关键字
- 保留字:只有goto和const
- 分隔符:分号(;)、左右大括号({})、和空白
- 变量:
声明格式:数据类型[] 变量名[ = 初始值];
根据作用域不同,分为成员变量和局部变量。 - 常量:就是那些内容不能被修改的白能量,与变量一样需要初始化,并一旦初始化就不能修改。
声明格式:final 数据类型 变量名 = 初始值;
常量有三种:静态常量(public static final)、成员常量(final)和局部变量(局部函数里的final)
4、Java基本数据类
Java中共有8中基本数据类型:4种整型、2种浮点类型、1种字符类型、1种布尔类型。
基本数据类型:byte、short、int、long、float、double、char、boolean
对应的包装类:Byte、Short、Integer、Long、Float、Double、Character、Boolean
布尔类型数据只有true和false两个值,不能用0和1表示。
- 整型类型默认是int;浮点型默认是double;
- long类型的数据后需要加(l或L);float类型需要加f或F
- 数值转换:数据类型之间可以相互转换;布尔类型不能与他们之间进行转换;自动转换(小范围转换成大范围)和强制转换(被转换的数据前需要加上
(目标类型)) - 引用数据类型:包含类、接口和数组声明数据类型。
5、Java修饰符
是类、方法或常量前面的修饰符
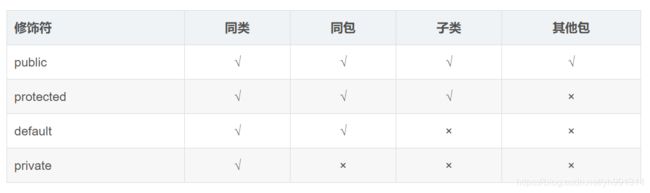
访问权限修饰符:
- public:共有访问。对所有的类都可见。
- protected:保护型访问。对同一个包可见,对不同的包的子类可见。
- default:默认访问权限。只对同一个包可见,注意对不同的包的子类不可见。
- private:私有访问。只对同一个类可见,其余都不见。
public > protected > default > private
非访问权限修饰符
- static 修饰符,用来创建类方法和类变量。
- final 修饰符,用来修饰类、方法和变量,final 修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
- abstract修饰符,用来创建抽象类和抽象方法。
- synchronized 用于多线程的同步。
- volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。指定该变量可以同时被几个线程控制和修改,保证两个不同的线程总是看到某个成员变量的同一个值。
- transient:序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
接口修饰符
(1)接口修饰符只能用public、default和abstract,不能用final、static修饰。接口默认修饰为abstract。
(3)接口中方法修饰符只能用 public和abstract修饰。默认为public abstract。
6、Java运算符
- 见学习笔记
- instanceo:判断某个对象或参数是否属于某个类或类型
7、Java对象和类简介
面向对象程序设计是由对象组成的,每个对象包含对用户公开的特定功能部分和隐藏的实现部分。
类:是一种共性的概念;
对象:是一个具体的,可以使用的事物;
类
类是构造对象的模板或蓝图。由类构造对象的过程称为创建类的实例。
- 一个子类只能有一个父类;
- 子类继承了父类中所有方法和属性,只不过私有的你访问不到而已;
对象
首先产生类(类是生产对象的蓝图),之后才能产生对象
- 创建对象步骤:
String name;//1. 声明
name = new String("hello world.")//2. 实例化
只要出现了关键字new,就开辟了内存
//类名称 对象名称 = new 类名称();
//如:
Person lihua = new Person();
//对象名称.属性名称/方法名称
//如:
lihua.name;
lihua.eat();
- 空对象:引用变量没有通过new分配内存空间,就是空对象,用null表示
String name=null; - this关键字:this值得是对象本身。可以使用
this.属性或this.方法调用当前正在创建的对象属性或方法。使用this调用其他构造方法时,this语句一定是该构造方法的第一条语句。
Java语法基础2
1、Java流程结构
基础结构
Java中的基础结构就是顺序结构,也就是程序在执行的时候从上至下去执行
public static void main(String[] args) {
System.out.println("1");
System.out.println("2");
System.out.println("3");
System.out.println("4");
}
选择结构
//1 判断
if(表达式){
表达式为true时就是我们执行的方法
}
//2 选择
if(布尔表达式){
表达式为true执行此处
}else{
表达式为false执行此处代码
}
//3 多选
if(布尔表达式){
表达式为true执行此处
}else if(布尔表达式){
表达式为true执行此处
}else if(布尔表达式){
表达式为true执行此处
}else if(布尔表达式){
表达式为true执行此处
}else{
表达式为flase执行此处
}
//4 嵌套
switch选择结构
switch搭配case进行选择的判断,它也是属于一种多选的选择结构
switch种的变量类型可以是byte、short、int、char、或者String
case后面只能跟一个:byte、short、int、char、或者字符串
switch中只有遇到break语句才会跳出
switch(expression){
case value:
//语句
break;//可选
case value:
//语句
break;//可选
case value:
//语句
break;//可选
defalut://可选
}
循环语句
- while循环
只要表达式为true就会一直执行下去 大部分情况下,我们需要对循环进行结束 少部分情况下的循环需要一直进行下去,比如服务器的请求响应监听等
while循环可能会导致死循环,会让程序崩溃
while(布尔表达式){
表达式为true时进行执行
}
- do…while循环
- while与do…while的区别
(1)while先判断后执行,do…while是先执行后判断
(2)do…while中do中的方法体必须执行一次,这是他们的主要区别
do{
代码执行
}while(布尔表达式);
- for循环:
for(变量初始化;布尔表达式;变量更新){
//代码语句
}
其他内容:
//1. 每个Java应用程序都必须有一个main方法。并且java中的所有函数都属于某个类的方法,因此main方法必须得有一个外壳类。
public class Test{
public static void main(String[] args){
//内容
}
}
//2. java基本的数据结构:
/**
(1)判断分支语句:if、if-else、else if
(2)循环语句:while、do-while、for
(3)多重选择:switch
(4)跳转语句:break、continue
**/
/**
关键字public为访问控制修饰符;
java中的全部内容必须放在类中。
**/
枚举类型不是java中的基本数据类型。
2、Java数组
数组是一种数据结构,用来存储同一类型值得集合。通过一个整型下标可以访问数组中得每一个值。
- 数组定义与初始化
int[] a;
int[] b = new int[10];
for(int i=0;i<10;i++){
b[i] = i+1;
}
int[] c = {1,2,3,4,5};
//打印数组中得所有值的简便方法:利用Arrays类的toString方法,将数组元素转换成字符串,打印出来。比如[1,2,3,4,5,6,7,8,9,10]
System.out.println(Arrays.toString(b));
- 在java种允许数组的长度为0:
new c[0]。
在编写一个方法时,若结果为数组,且可能出现结果为空的方法时,就可以使用该语法new一个长度为0的数组进行返回。注意:长度为0与null是不同的。
- 数组拷贝
- 使用方法1:
Arrays.copyOf(str1, length);
其中第二个参数length是新数组的长度,这个方法通常用来增加数组的大小。若数组元素类型是数值型,则多余的元素将被赋值为0;若类型为布尔,则多余元素的数据将被赋值为false。相反,若长度小于原始数组长度,则只拷贝最前面的数据元素。 - 使用方法2:
Arrays.copyOf(str1, start, end)
其中start起始下标,包含这个值;end终止下标:不包含这个值,这个值有可能大于str1.length
int[] str1 = {1,2,3,4,5};
int str2 = Arrays.copyOf(str1, 9);
-
命令行参数
main方法中也有一个参数args,且数据类型为String类型的数组。表明main、方法讲接收一个字符串数组,也就是命令行参数。程序名并没有存储在args里。如:java test -h world,则args中内容为args[0]="-h",args[1]=“world”。 -
数组排序:可以使用Arrays类的sort方法
int[] a = new int[`0];
Arrays.sort(a);//该方法使用了优化的快排
//Math.random方法会返回一个0~1之间的随机浮点数。用n乘以这个浮点数,就可以得到从0到n-1之间的一个随机数
int randomNumber = (int)Math.random()*n;
- 查找元素,返回对应的下标值
//采用二分法查找值v,若查找成功,返回对应下标值;否则返回一个负数r
static int binarySearch(type[] a, type v)
- equals:判断两个数组值是否相等
3、枚举
枚举类型enum:有时候,变量的取值只在一个有限的集合内。可以用枚举类型来自定义有限个命名以及命名所对应的值。
例如:
//枚举类型,使用关键字enum
enum Size{
SMALL, MEDIUM, LARGR
}
这里要注意,值一般是大写的字母,多个值之间以逗号分隔。
- 比较两个枚举类型的值时,永远不需要调用equals,直接使用“
==”即可。 - 所有枚举类型都是Enum类的子类,他们继承了这个类的许多方法。
(1) 比如最有用的toString,这个方法可以返回枚举常量名,如Size.SAMALL.toString(),返回“SMALL”
(2) 每个枚举类型都有一个静态的values方法,它将返回一个包含全部枚举值的数组,如Size.values(),就返回的是字符串数组[“SMALL”, “MEDIUM”, “LARGR”]。
(3)ordinal方法返回enum声明中枚举常量的位置,位置从0开始计数,如Size.MEDIUM.ordinal(),返回1。
(4)valueOf(enumName, name)返回指定名字,给定类的枚举常量。
valueOf(String str):返回枚举类中对象名是str的对象,如果没有对象名为str的对象,则抛异常。
public class EnumDemo {
public static void main(String[] args){
//直接引用
Day day =Day.MONDAY;
//enum中的values方法与valueOf方法
Day[] days2 = Day.values();
System.out.println("day2:"+Arrays.toString(days2));
Day day = Day.valueOf("MONDAY");
System.out.println("day:"+day);
}
}
//定义枚举类型
enum Day {
MONDAY, TUESDAY, WEDNESDAY,
THURSDAY, FRIDAY, SATURDAY, SUNDAY
}
输出:
day2:[MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY]
day:MONDAY
- 枚举实现原理:实际上在使用关键字
enum创建枚举类型并编译后,编译器会为我们生成一个相关的类,这个类继承了Java API中的java.lang.Enum类,也就是说通过关键字enum创建枚举类型在编译后事实上也是一个类类型而且该类继承自java.lang.Enum类。
面向对象
1、理解面向对象
什么是面向对象?
答:面向对象就是将具体的问题处理实现过程过程封装成类,方便我们使用。降低了耦合,提高了可维护性。
面向对象中,不必关心对象的具体实现,只要能满足用户的需求即可。OOP(面向对象中),数据被放在第一位,然后再考虑操作数据的算法。
面向过程: 根据业务逻辑从上到下写代码
面向对象: 将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程
面向对象三个基本特性:封装性、继承性和多态性。
封装:对外部访问者隐藏了对象的内部细节,只保留有限的对外接口。
继承:子类拥有父类全部特征和行为。
多态:子类继承父类之后,可以继承父类的所有内筒你切可以有不同的状态或表现行为。
2、类与对象
类里边封装了一类对象的数据和操作,是构造对象的模板或蓝图。
对象是类的具体化。
3、构造方法
封装
封装是将数据和行为组合再一个包里。
1、包
包中定义了一组相关类型供用户调用。
常用的包:
- java.lang包:该包提供了Java语言进行程序设计的基础类,它是默认导入的包。该包里面的Runnable接口和Object、Math、String、StringBuffer、System、Thread以及Throwable类需要重点掌握,因为它们应用很广。
- java.util包:该包提供了包含集合框架、遗留的集合类、事件模型、日期和时间实施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)。
2、访问权限修饰符
public:所有包
protected:同一包,父子不同包
default:同一包
private:同一类
3、接口与实现
接口只描述类具有什么功能,但不给出每个功能的具体实现。
一个类可以实现一个或多个接口。
接口的特性:
接口不能使用new实例化一个接口;
可以声明接口的变量,接口变量必须引用实现了接口的类对象;
instanceof可以用来检查一个对象是否属于某个特定的类,也可以检查一个对象是否实现了某个特定的接口。
继承
通过一个类来建立另外一个类的过程被称为继承。
1、继承的语法
extends:一个子类只能继承一个父类。
子类自动拥有父类的非私有属性和方法(构造函数不能被继承)。
实例化:相同父类的子类拥有共享的父类非私有方法(覆盖的就不是共享的了!),属性都是自己的
2、向上转型
- 向上转型:为了调用父类的私有方法和构造函数以及父类的非public属性
将子类对象转换成父类类型:Pet pet=new Dog();
类型转换为自动转换, 因为子类的功能比父类更加强大,相当于让一个能力强的对象去做一件简单的事情,因此可以自动转换完成
向上转型:子类对象赋值给父类对象引用。使用格式:父类类型 变量名 = new 子类类型()
好处:提高了代码的扩展性。 - 向下转型
将父类对象转换为子类类型,例如:
Pet pet=new Pet();
Dog dog=(Dog)pet;
此类型转换为强制转换, 因为反之,父类的功能要弱于子类,因此需要强制转换
向下转型:父类对象引用强制转换为子类对象引用。使用格式:子类类型 变量名 = (子类类型)父类类型
好处:可以使用子类特有功能。
3、final关键字
final表示不可修改final修饰类:该类不可以被继承,同时类里的方法不能被重写,不能被abstract修饰。但其成员变量还是可以通过get、set方法修改的。final修饰方法:该方法不能被子类覆盖final常量:表示一个不可改变的值,不能被再次赋值- 静态变量:
static,表示定义一个类级别的变量,但是值可以修改
构造方法:用来初始化类的实例变量,构造方法名必须与类名相同并且没有返回值,在创建对象之后会自动调用。
多态
1、理解多态
多态的三个前提条件:(1)继承、(2)覆盖(或重写)、(3)声明的变量类型是父类类型,但实例指向子类实例。
多态体现为父类引用变量可以指向子类对象。
定义格式:父类类型 变量名=new 子类类型();
比如:
List myList = new ArrayList();
List是java.util包中的一个定义集合对象的接口,ArrayList是实现List接口的实现类。
**使用List mylist =new ArrayList();定义对象时,比使用ArrayList mylist =new ArrayList();易于扩展;**如当你在使用中发现ArrayList类型的对象不能满足你的使用要求时,你可以改成其他的实现List接口的对象类修改你的对象,如mylist = new LinkedList();这样就不需要再定义新的对象了。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
2、多态的表现形式(3种)
(1)普通类多态定义的格式:父类类型 变量名 = new 子类类型()。
class Father {
int num = 4;
}
class Son extends Father {
int num = 5;
}
//普通类多态形式
Father father = new Son();
(2)抽象类多态定义的格式
abstract class Father {
abstract void method();
}
class Son extends Father {
public void method() {
System.out.println("abstract");
}
}
//抽象类多态表现形式
Father father = new Son();
(3)接口多态定义的格式
interface Father {
public void method();
}
class Son implements Father{
public void method() {
System.out.println("implements")
}
}
//接口多态的表现形式
Father father = new Son();
多态的编译和运行
(1)成员变量:编译和运行都看左边。
(2)成员方法:编译看左边,运行看右边。
3、重载与重写
- 重载Overload:函数名相同,参数类型或个数不同。
- 覆盖(重写)Override:用于继承关系,函数名相同参数个数也相同。
- 在继承一个类的时候,可以覆盖父类方法(一模一样),也可以对父类方法直接重载。
抽象类与接口
1、抽象类和方法
抽象类:类前添加 abstract
abstract class ClassA{
//定义了一个抽象类 ClassA
}
抽象方法:返回值类型前加 abstract
其它修饰符 abstract 返回值类型 方法名(参数类型 参数名,....);
- 抽象类和其他类一样可以有构造方法
2、接口定义与使用
关键字:interface
当一个子类需要实现接口又继承抽象类的时候,先使用extends先继承,再用implements来实现接口
一个抽象类可以使用implements实现多个接口
一个接口可以使用extends来继承多个父接口
例如:
interface A {// 定义了接口
public static final String MSG = "Hello";// 全局常量
// 抽象方法
public abstract void print();
}
3、抽象类和接口
-
抽象类:
抽象类中的静态方法,即使没有子类也是可以直接被使用的(类调用)
抽象类中可以没有抽象方法,但一个类中有抽象方法这个类一定是抽象类 -
接口:
接口声明的变量默认都是final的;
接口中所有方法都可以认为是抽象的(jdk1.7之前)
接口只能被public和abstract修饰(接口名与文件名相同);接口中的方法默认是public abstract的,接口中的属性默认都是public static final的
接口可以继承接口 -
抽象类与接口区别:
抽象类中可以定义一些子类的公共方法,子类只需要添加新的功能,不需要重复写已经存在的方法;
而接口中只是对方法的申明和常量的定义。
集合框架
集合框架: 用于存储数据的容器。
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。
任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算法。
特点:
(1)对象封装数据,对象多了也需要存储。集合用于存储对象。
(2)对象的个数确定可以使用数组,对象的个数不确定的可以用集合。因为集合是可变长度的。
1、集合的基本概念
集合: 就是用于存储数据的容器
集合和数组的区别
- 数组是固定长度的;集合可变长度的。
- 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。
- 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
数据结构: 就是容器中存储数据的方式
2、集合的使用
所有集合都位于 java.util 包下。java集合类主要由两个接口派生而出:Collection 和 Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。
- Collection一次存一个元素,是单列集合;
- Map一次存一对元素,是双列集合。Map存储的一对元素:键-值,键(key)与值(value)之间由对应(映射)关系。
Collection集合主要有List和Set两大接口:
- List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引。元素可以重复。
- Set:无序(存入和取出顺序有可能不一致),不可以存储重读氟元素。必须保证元素唯一性。
3、列表List
List是元素有序并且可以重复的集合。
List的主要实现:ArrayList, LinkedList, Vector。
List常用方法

ArrayList、LinkedList、Vector 的区别
| ArrayList | LinkedList | Vector | |
|---|---|---|---|
| 底层实现 | 数组 | (双向)链表 | 数组 |
| 同步性及线程安全性 | 不同步、非线程安全 | 不同步、非线程安全 | 同步、线程安全 |
| 特点 | 查询快、增删慢 | 查询慢、增删快 | 查询快、增删慢 |
| 默认容量 | 10 | / | 10 |
| 扩容机制 | 1.5倍 | / | 2倍 |
4、集合Set
Set集合元素无序(存入和取出的顺序不一定一致),并且没有重复对象。
Set的主要实现类:HashSet、TreeSet
Set常用方法
5、映射Map
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口,从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
Map常用方法

HashMap、HashTable、TreeMap的区别
- HashMap基于哈希表实现
- HashTable:与HashMap类似,但线程安全,这意味着同一时刻多个线程可以同时写入HashTable并且不会导致数据不一致
- TreeMap基于红黑树实现
6、迭代器iterators
Iterator接口
Iterator接口,用于遍历集合元素的接口。
在Iterator接口中定义了三个方法:
hasNext()如果仍有元素可以迭代,则返回true。next()返回迭代的下一个元素。remove()从迭代器指向的 collection 中 移除迭代器返回的最后一个元素(可选操作)。
为了便于操作所有的容器,取出元素。将容器内部的取出方式按照一个统一的规则向外提供,这个规则就是Iterator接口,使得对容器的遍历操作与其具体的底层实现相隔离,达到解耦的效果。
也就说,只要通过该接口就可以取出Collection集合中的元素,至于每一个具体的容器依据自己的数据结构,如何实现的具体取出细节,这个不用关心,这样就降低了取出元素和具体集合的耦合性。
使用迭代器遍历集合元素
public static void main(String[] args){
List<String> list1 = new ArrayList<>();
list1.add("a");
list1.add("b");
list1.add("c");
//while循环方式遍历
Iterator listIterator1 = list1.iterator();//先定义这个集合的迭代器
while(listIterator1.hasNext()){//然后使用while与迭代器里的函数配合操作
System.out.println(listIterator1.next());
}
//for循环方式遍历
Iterator listIterator2 = list1.iterator();
for(listIterator2; listIterator2.hasNext(); ){
System.out.println(listIterator2.next());
}
}
HashMap、HashTable、TreeMap的区别
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。
集合工具类Collections(注意不是Collection接口)
Collections:集合工具类,方便对集合的操作。这个类不需要创建对象,内部提供的都是静态方法。
Collections.sort(list);//list集合进行元素的自然顺序排序。
Collections.sort(list,new ComparatorByLen());//按指定的比较器方法排序。
class ComparatorByLen implements Comparator<String>{
public int compare(String s1,String s2){
int temp = s1.length()-s2.length();
return temp==0?s1.compareTo(s2):temp;
}
}
Collections.max(list);//返回list中字典顺序最大的元素。
int index = Collections.binarySearch(list,"zz");//二分查找,返回角标。
Collections.reverseOrder();//逆向反转排序。
Collections.shuffle(list);//随机对list中的元素进行位置的置换。
//将非同步集合转成同步集合的方法:Collections中的 XXX synchronizedXXX(XXX);
//原理:定义一个类,将集合所有的方法加同一把锁后返回。
List synchronizedList(list);
Map synchronizedMap(map);
数组工具类 Arrays
用于操作数组对象的工具类,里面都是静态方法。
- 数组 -> 集合:用数组的asList方法,将数组转换成list集合。
注意:在使用asList()时尽量不要将基本数据类型数组转List。
String[] arr ={"abc","kk","qq"};
List<String> list =Arrays.asList(arr);//将arr数组转成list集合。
asList转换得到的ArrayList不是java.util.ArrayList,此处ArrayList是Arrays的内部类,因此并没有add方法。因为asList的参数为一个泛型参数,想作为泛型参数就必须使用其所对应的包装类型。
正确的转化后的add操作,需要使用new ArrayList()包裹一层:
public static void main(String[] args) {
String[] arr = {"abc", "kk", "qq"};
// 使用new ArrayList包裹一层
List<String> list = new ArrayList<>(Arrays.asList(arr));
list.add("bb");
}
- 集合 -> 数组:用的是Collection接口中的toArray()方法;
如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。
如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。
所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
如何选用集合?
- 我们需要根据键值获取到元素值时就选用Map接口下的集合
- 需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap
- 我们只需要存放元素值时,就选择实现Collection接口的集合
- 需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList
7、理解java泛型概念
泛型,即“参数化类型”。
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。
也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
比如:
//声明list的时候就加上,将这个集合的内容类型进行限定。若不加上,则ArrayList可以存放任意类型
List<String> arrayList = new ArrayList<String>();
...
//arrayList.add(100); 在编译阶段,编译器就会报错
泛型只在编译阶段有效。
8、学会在函数和类定义时使用泛型
关于泛型的参考文献
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法
泛型类
将泛型类型用于类的定义中,被称为泛型类。
泛型类定义方法:
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
}
例子:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
//key这个成员变量的类型为T,T的类型由外部指定
private T key;
public Generic(T key) { //泛型构造方法形参key的类型也为T,T的类型由外部指定
this.key = key;
}
public T getKey(){ //泛型方法getKey的返回值类型为T,T的类型由外部指定
return key;
}
}
测试
//泛型的类型参数只能是类类型(包括自定义类),不能是简单类型
//传入的实参类型需与泛型的类型参数类型相同,即为Integer.
Generic<Integer> genericInteger = new Generic<Integer>(123456);
//传入的实参类型需与泛型的类型参数类型相同,即为String.
Generic<String> genericString = new Generic<String>("key_vlaue");
System.out.println("泛型类测试"+"key is " + genericInteger.getKey());
System.out.printl("泛型类测试"+"key is " + genericString.getKey());
输出:
泛型类测试: key is 123456
泛型类测试: key is key_vlaue
注意:
- 泛型的类型参数只能是类类型,不能是简单类型。
- 不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。
if(ex_num instanceof Generic){
}
泛型接口
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参 。 再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
泛型方法
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
说明:
1)public 与 返回值中间
2)只有声明了
3)
4)与泛型类的定义一样,此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型。
/**
* 泛型方法的基本介绍
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
*/
public <T> T genericMethod(Class<T> tClass)throws InstantiationException, IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}
泛型方法的基本用法
public class GenericTest {
//这个类是个泛型类,在上面已经介绍过
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
//我想说的其实是这个,虽然在方法中使用了泛型,但是这并不是一个泛型方法。
//这只是类中一个普通的成员方法,只不过他的返回值是在声明泛型类已经声明过的泛型。
//所以在这个方法中才可以继续使用 T 这个泛型。
public T getKey(){
return key;
}
/**
* 这个方法显然是有问题的,在编译器会给我们提示这样的错误信息"cannot reslove symbol E"
* 因为在类的声明中并未声明泛型E,所以在使用E做形参和返回值类型时,编译器会无法识别。
public E setKey(E key){
this.key = keu
}
*/
}
/**
* 这才是一个真正的泛型方法。
* 首先在public与返回值之间的必不可少,这表明这是一个泛型方法,并且声明了一个泛型T
* 这个T可以出现在这个泛型方法的任意位置.
* 泛型的数量也可以为任意多个
* 如:public K showKeyName(Generic container){
* ...
* }
*/
public <T> T showKeyName(Generic<T> container){
System.out.println("container key :" + container.getKey());
//当然这个例子举的不太合适,只是为了说明泛型方法的特性。
T test = container.getKey();
return test;
}
//这也不是一个泛型方法,这就是一个普通的方法,只是使用了Generic这个泛型类做形参而已。
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
//这也不是一个泛型方法,这也是一个普通的方法,只不过使用了泛型通配符?
//同时这也印证了泛型通配符章节所描述的,?是一种类型实参,可以看做为Number等所有类的父类
public void showKeyValue2(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
/**
* 这个方法是有问题的,编译器会为我们提示错误信息:"UnKnown class 'E' "
* 虽然我们声明了,也表明了这是一个可以处理泛型的类型的泛型方法。
* 但是只声明了泛型类型T,并未声明泛型类型E,因此编译器并不知道该如何处理E这个类型。
public T showKeyName(Generic container){
...
}
*/
/**
* 这个方法也是有问题的,编译器会为我们提示错误信息:"UnKnown class 'T' "
* 对于编译器来说T这个类型并未项目中声明过,因此编译也不知道该如何编译这个类。
* 所以这也不是一个正确的泛型方法声明。
public void showkey(T genericObj){
}
*/
public static void main(String[] args) {
}
}
泛型方法与可变参数
再看一个泛型方法和可变参数的例子:
public <T> void printMsg( T... args){
for(T t : args){
System.out.println("泛型测试"+"t is " + t);
}
}
输出:
printMsg(“111”,222,“aaaa”,“2323.4”,55.55);
9、java序列化
序列化定义
序列化: 将对象写入IO流中。
反序列化: 从IO流中恢复对象。
意义: 序列化机制允许将实现序列化的Java对象转换为字节序列,并将字节序列保存在磁盘中,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使地对象可以脱离程序的运行而独立存在。
使用场景:所有在网络上传输的对象都必须是可序列化的。所有必须保存到磁盘的java对象都必须是可序列化的。程序创建的JavaBean最好都实现Serializable接口。
实现序列化的方式
实现序列化有两种方式:实现Serializable接口或Externalizable接口,通常情况下,实现Serializable接口即可。两种接口的对比如下:
实现Serializable接口:
- 系统自动存储必要的信息;
- Java内建支持,易于实现,只需要实现接口,不需要任何代码支持;
- 性能略差;
实现Externalizable接口:
- 自己决定要序列化哪些属性;
- 必须实现该接口内的两个方法: void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;- 性能略好;
使用Serializable接口实现序列化
Serializable接口是一个标记接口,不用实现任何方法,一旦某个类实现了该方法,则该类的对象是可序列化的。
1、通过以下步骤实现序列化:
1)创建一个ObjectOutputStream输出流;
2)调用ObjectOutputSteam对象的writeObject ()输出可序列化对象。
//Person类实现这个Serializable接口
public class Person implements Serializable {
private String name;
private String age;
public Person() {
System.out.println("调用Person的无参构造函数");
}
public Person(String name, String age) {
this.name = name;
this.age = age;
System.out.println("调用Person的有参构造函数");
}
@Override
public String toString() {
// TODO 自动生成的方法存根
return "Person{'name' :" + name + ",'age' :" + age + "}";
}
}
//调用ObjectOutputStream 的writeObject()方法输出序列化文件
public class WriteObject {
public static void main(String[] args) {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("Person.txt"));
Person p = new Person("baby", "12");
oos.writeObject(p);
} catch (Exception e) {
// TODO: handle exception
}
}
}
输出:
aced 0005 7372 0017 7365 7269 616c 697a
6162 6c65 5465 7374 2e50 6572 736f 6e4e
aff9 165f 38dd f602 0002 4c00 0361 6765
7400 124c 6a61 7661 2f6c 616e 672f 5374
7269 6e67 3b4c 0004 6e61 6d65 7100 7e00
0178 7074 0002 3132 7400 0462 6162 79
2、通过以下步骤实现反序列化:
1)创建一个ObjectInputStream输入流;
2)调用ObjectInputStream对象的readObject()得到序列化对象。
public class WriteObject {
public static void main(String[] args) {
try {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("Person.txt"));
Person p = (Person) ois.readObject();
System.out.println(p.toString());
} catch (Exception e) {
// TODO: handle exception
}
}
}
输出:
Person{‘name’ :baby,‘age’ :12}
通过输出结果,我们知道反序列化没有调用类的构造方法,而是由JVM自己生成对象。
3、当类的成员是引用数据类型时
若一个类的成员不是基本数据类型,也不是String类型的时候,则该成员必须是可序列化的,否则会导致该类无法完成序列化。
4、java序列化算法
针对同一对象进行多次序列化,Java并不会序列化多次,而是沿用第一次序列化获得的序列化编码。
1)所有保存到磁盘的对象都有一个序列化编号;
2)当试图序列化一个对象时,会先检查该对象是否已经序列化过,只有该对象未被JVM序列化过,才会将该对象序列化为字节序列输出;
3)如果此对象已经被序列化过,则直接输出序列化编码号即可。
序列化版本号serialVersionUID
Java序列化提供了一个serializableVersionUID的序列化版本号,只要版本号相同,即使更改了序列化属性,对象也可以被正确地反序列化回来。
public class Person implements Serializable {
// 序列化版本号
private static final long serialVersionUID = 1227593270102525184L;
private String name;
private String age;
private int height;
序列化版本号可自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,这样随着class的升级,就无法正确反序列化;
不指定版本号另一个明显隐患是,不利于jvm间的移植,可能class文件没有更改,但不同jvm可能计算的规则不一样,这样也会导致无法反序列化。
序列化的总结
- 对象的类名、实例变量(包括基本类型,数组,对其他对象的引用)都会被序列化;方法、类变量(静态变量)、transient(瞬态变量)实例变量都不会被序列化。
- 所有需要网络传输的对象都需要实现序列化接口,通过建议所有的javaBean都实现Serializable接口。
- 如果想让某个变量不被序列化,使用transient修饰。
- 序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
- 反序列化时必须有序列化对象的class文件。
- 当通过文件、网络来读取序列化后的对象时,必须按照实际写入的顺序读取。
- 单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
- 同一对象序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化编号,不会重复序列化。
- 建议所有可序列化的类加上serialVersionUID 版本号,方便项目升级。
- 数组不能显式地声明serialVersionUID,因为它们始终都有默认的计算值,但是对于数组类,无需匹配serialVersionUID。
- 可以通过序列化和反序列化的方式实现对象的深复制。
字符串
1、字符串的不可变
- 字符串为什么是不可变的?
(1) 字符串本质是数组,数组在创建时就开辟了一个连续地址,固定的空间的内存
(2) 字符串常量池实现的前提条件是Java中String对象是不可变的,字符串的值存放在字符串常量池中。
字符串的不可变性是指引用的不可变。 虽然 String 中的 value 字符数组声明为 final,但是这个 final 仅仅是让 value的引用不可变,而不是为了让字符数组的字符不可替换。
2、字符串操作
字符串初始化赋值和输出
- 初始化: String str = “hello world!”
- 输出System.out.println(str);
合并
String str1 = "abc";
String str2 = "def";
String str = str1 + str2;
比较
//输出false
boolean e = str1.equals(str2);
获取
1. 获取长度:int length()
2. 获取该位置上的某个字符:char charAt(int index)
3. 获取字符在该字符串的位置:
int indexOf(String str):返回的是str在字符串中第一次出现的位置。
int indexOf(int ch,int fromIndex):从fromIndex指定位置开始,获取ch在字符串中出现的位置。
int lastIndexOf(int ch):反向索引一个字符出现的位置
判断某一子字符串是否包含在该字符之中
String str="Twinkle Twinkle little star, ";//创建字符串1
String str1="Twinkle";//创建字符串2
boolean b=str.contains(str1);//子字符串是否被包含在此字符串之中,包含输出true,否则输出false
替换
String str="Hello xx ,how are you? ";//创建字符串
String s=str.replace("xx","无名之辈W");//将xx替换为Jay
3、StringBuffer和StringBuilder
- String对象是不可变的,用字符数组保存字符串但有final修饰符
private final char value[];
- StringBuffer与StringBuilder继承自AbstractStringBuilder类,这两种对象是可变的
- String对象不可变,所以是线程安全的
- StringBuffer对方法加了同步锁或者调用的方法加了同步锁synchronized,因此线程安全
- StringBuilder运行速度最快
重要的JDK类库
1、Object类
- Object类是java.lang包下的核心类,Object类也是所有类的父类,任何一个类如果没有明确的继承一个父类的话,它就是Object的子类。
Object类提供了11个方法

-
clone()
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。 -
getClass()
final方法,返回Class类型的对象,反射来获取对象。 -
toString()
该方法用得比较多,一般子类都有覆盖,来获取对象的信息。 -
finalize()
该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。 -
equals()
比较对象的内容是否相等 -
hashCode()
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。 -
wait()
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
其他线程调用了该对象的notify方法。
其他线程调用了该对象的notifyAll方法。
其他线程调用了interrupt中断该线程。
时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
-
notify()
该方法唤醒在该对象上等待的某个线程。 -
notifyAll()
唤醒所有等待的线程
2、Java日期时间
Date类
java.util.Date类 表示特定的瞬间,精确到毫秒。
Date():该方法新建了一个Date对象,并对其进行了初始化(精确到毫秒)getTime():该方法把日期对象转换成对应的时间毫秒值
public class Demo01Date {
public static void main(String[] args) {
//创建日期对象,当前时间
Date date = new Date();
System.out.println(date);//Fri Jan 14 14:32:35 CST 2022
//把日期对象转换成对应的时间毫秒值
long millisecond = date.getTime();
System.out.println(millisecond);//1642141955599
}
}
DateFormat类
java.text.DateFormat是日期/时间格式化子类的抽象类,我们通过这个类可以帮助我们完成日期和文本之间的转换,也就是可以再Date对象与String对象之间来回转换
public SimpleDateFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造SimpleDateFormat。参数pattern是一个字符串,用来代表日期时间的自定义格式。
格式规则

public String format(Date date):将Date对象格式化为字符串public Date parse(String source):将字符串解析为Date对象
/*
*把Date对象转换成String
*/
public static void main(String[] args) {
Date date = new Date();
// 创建日期格式化对象,在获取格式化对象时可以指定风格
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = df.format(date);
System.out.println(str);
// 2022年01月14日
}
/**
*把String转换成Date对象
*/
public static void main(String[] args) throws ParseException {
DateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
String str = "2022年01月14日";
Date date = df.parse(str);
System.out.println(date);
// Fri Jan 14 00:00:00 CST 2022
}
3、BigDecimal类
Java中提供了大数字(超过16位有效位)的操作类,即 java.math.BinInteger 类和 java.math.BigDecimal 类,用于高精度计算.其中 BigInteger 类是针对大整数的处理类,而 BigDecimal 类则是针对大小数的处理类。
在商业计算中,对数字精度要求较高,必须使用 BigInteger 类和 BigDecimal 类,它支持任何精度的定点数,可以用它来精确计算货币值。
由于在运算的时候,float类型和double很容易丢失精度,所以一般不用来做计算货币。
BigDecimal构造方法
//方法一
BigDecimal BigDecimal(String s);//常用,推荐使用
static BigDecimal valueOf(double d); //常用,推荐使用
1.建议优先使用基于String的构造器,使用
BigDecimal(String val)构造器时可以预知的,写入new BigDecimal(“0.1”)将创建一个恰好等于0.1的BigDecimal。
2.如果必须使用double浮点数作为BigDecimal构造器的参数时,不要使用double作为参数,而应该通过BigDecimal.valueOf(double value)静态方法来创建对象。
BigDecimal类成员方法
public BigDecimal add(BigDecimal augend)//加
public BigDecimal subtract(BigDecimal subtrahend)//减
public BigDecimal multiply(BigDecimal multiplicand)//乘
public BigDecimal divide(BigDecimal divisor)//除
public BigDecimal divide(BigDecimal divisor,int scale, int roundingMode)//商,几位小数,舍取模式
BigDecimal应用例子
import java.math.BigDecimal;
/**
* @version: V1.0
* @author: fendo
* @className: BigDecimalTest
* @packageName: com.xxx
* @description: BigDecimal测试类
* @data: 2018-04-17 14:23
**/
public class ArithTest {
// 除法运算默认精度
private static final int DEF_DIV_SCALE = 10;
private ArithTest() {
}
/**
* 精确加法
*/
public static double add(double value1, double value2) {
BigDecimal b1 = BigDecimal.valueOf(value1);
BigDecimal b2 = BigDecimal.valueOf(value2);
return b1.add(b2).doubleValue();
}
/**
* 精确减法
*/
public static double sub(double value1, double value2) {
BigDecimal b1 = BigDecimal.valueOf(value1);
BigDecimal b2 = BigDecimal.valueOf(value2);
return b1.subtract(b2).doubleValue();
}
/**
* 精确乘法
*/
public static double mul(double value1, double value2) {
BigDecimal b1 = BigDecimal.valueOf(value1);
BigDecimal b2 = BigDecimal.valueOf(value2);
return b1.multiply(b2).doubleValue();
}
/**
* 精确除法 使用默认精度
*/
public static double div(double value1, double value2) throws IllegalAccessException {
return div(value1, value2, DEF_DIV_SCALE);
}
/**
* 精确除法
* @param scale 精度
*/
public static double div(double value1, double value2, int scale) throws IllegalAccessException {
if(scale < 0) {
throw new IllegalAccessException("精确度不能小于0");
}
BigDecimal b1 = BigDecimal.valueOf(value1);
BigDecimal b2 = BigDecimal.valueOf(value2);
// return b1.divide(b2, scale).doubleValue();
return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).doubleValue();
}
/**
* 四舍五入
* @param scale 小数点后保留几位
*/
public static double round(double v, int scale) throws IllegalAccessException {
return div(v, 1, scale);
}
/**
* 比较大小
*/
public static boolean equalTo(BigDecimal b1, BigDecimal b2) {
if(b1 == null || b2 == null) {
return false;
}
return 0 == b1.compareTo(b2);
}
public static void main(String[] args) throws IllegalAccessException {
double value1=1.2345678912311;
double value2=9.1234567890123;
BigDecimal value3=new BigDecimal(Double.toString(value1));
BigDecimal value4=new BigDecimal(Double.toString(value2));
System.out.println("精确加法================="+ArithTest.add(value1, value2));
System.out.println("精确减法================="+ArithTest.sub(value1, value2));
System.out.println("精确乘法================="+ArithTest.mul(value1, value2));
System.out.println("精确除法 使用默认精度 ================="+ArithTest.div(value1, value2));
System.out.println("精确除法 设置精度================="+ArithTest.div(value1, value2,20));
System.out.println("四舍五入 小数点后保留几位 ================="+ArithTest.round(value1, 10));
System.out.println("比较大小 ================="+ArithTest.equalTo(value3, value4));
}
}
4、其他重要的JDK库
IO
- java的I/O操作主要是指使用java进行输入输出操作。java所有的I/O机制都是基于数据流进行输入输出,这些数据流表示了字符或字节数据的流动序列。
- Java的I/O流提供了读写数据的标准方法。任何Java中表示数据源的对象都会提供以数据流的方式读写它的数据的方法。
1、输入、输出流的定义与使用
基本流:一组有序,有起点和终点的字节的数据序列。包括输入流和输出流。
输入流: 程序从输入流读取数据源。数据源包括外界(键盘、文件、网络…),即是将数据源读入到程序的通信通道。
输出流: 程序向输出流写入数据。将程序中的数据输出到外界(显示器、打印机、文件、网络…)的通信通道。
2、文件的操作
3、Reader和Writer
- Reader和Writer是java的IO库提供的输入输出流接口,用于读取和输出 字符流,即以 char 为单位进行读取和输出。
4、IO流典型用途
- 根据数据流向不同分为:输入流和输出流。
输出:把程序(内存)中的内容输出到磁盘、光盘等存储设备中
输入:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中

- 根据处理数据类型的不同分为:字节流和字符流。
字符流(char):可以用于读写文本文件。
字节流(byte):可以用于读写二进制文件及任何类型文件。
两者的区别:(1字符 = 2字节 、 1字节(byte) = 8位(bit) 、 一个汉字占两个字节长度)
数据库编程
1、JDBC的使用
JDBC(Java Database Connectivity):Java数据库连接。 就是用Java语言来操作数据库。原来我们操作数据库是在控制台使用SQL语句来操作数据库,JDBC是用语言向数据库发送SQL语句。JDBC API允许用户访问任何形式的表格数据,尤其是存储在关系数据库中的数据。
主要的执行流程:
(1)连接数据库;
(2)为数据库传递查询和更新指令;
(3)处理数据库响应以及返回的结果。

JDBC可以通过载入不同的**数据库的“驱动程序”**而与不同的数据库进行连接。要使用JDBC来访问MySQL数据库,首先需要添加MySQL数据库驱动程序。
 SUN提供的一套访问数据库的规范命名为JDBC(就是一组接口),而各个厂商提供的,遵循了JDBC规范的,可以访问自己数据库的API被称之为驱动!
SUN提供的一套访问数据库的规范命名为JDBC(就是一组接口),而各个厂商提供的,遵循了JDBC规范的,可以访问自己数据库的API被称之为驱动!
JDBC是接口,而JDBC驱动才是接口的实现,没有驱动无法完成数据库连接!每个数据库厂商都有自己的驱动,用来连接自己公司的数据库。
程序员,JDBC,JDBC驱动的关系及说明
- JDBC API: 由Sun公司提供,供程序员调用的接口与类,集成在
java.sql和javax.sql包中,比如DriverManager类、Connection接口、Statement接口、ResultSet接口。 - JDBC 驱动: 由数据库厂商提供,作用是负责连接各种不同的数据库
- Java程序员:JDBC对Java程序员而言是API,对实现与数据库连接的服务器提供商而言是接口模型。
三者的关系:
- SUN公司是规范制定者,制定了规范JDBC(连接数据库规范);
- 数据库厂商微软、甲骨文等分别提供实现JDBC接口的驱动jar包
- 程序员学习JDBC规范来应用这些jar包里的类。
JDBC总结
JDBC可以做三件事:与数据库建立连接、发送操作数据库的语句、处理结果
JDBC连接数据库的步骤:
- 加载一个Driver驱动
Class.forName("com.mysql.jdbc.Driver");
- 创建数据库连接(Connection)
String url= "jdbc:mysql://数据库地址:3306/数据库名";//指定要连接哪个数据库
String user= "root" ; //使用的用户名
String password= "root" ; //使用的密码
Connection conn = DriverManager.getConnection(url, user, password);
- 创建SQL命令发送器Statement
Statement statement= conn.createStatement();
- 通过Statement发送SQL命令并得到结果
ResultSet resultSet = statement.executeQuery("select * from user");
- 处理SQL语句的 结果(select语句)
while (resultSet.next()) {
//注意:这里要与数据库里的字段对应
String username = resultSet.getString("user_name");
String password = resultSet.getString("user_password");
String age = resultSet.getString("user_age");
System.out.println(username + " " + password + " " + age);
}
- 关闭数据库资源,断开连接
conn.commit();
conn.close();
JDBC连接数据库相关的知识总结
-
数据库驱动:
Driver
加载mysql驱动:Class.forName("com.mysql.jdbc.Driver");
加载oracle驱动:Class.forName("oracle.jdbc.driver.OracleDriver");
加载相应的驱动需要导入相应的包,如MySQL则需要导入:mysql-connector-java-5.1.13-bin.jar
否则无法正常执行。 -
获取数据库链接:
Connection
Connetion类主要用来链接数据库,常通过DriverManager.getConnection()来获取一个连接对象。
这里有3个参数,分别是url,user,password。对应的是要链接的数据库,用户名,密码等。如:
url=jdbc:mysql://localhost:3306/jdbc?useUnicode=true&characterEncoding=utf-8
user=root
password=root -
执行sql语句:
Statement
Statement对象用于执行sql语句,有以下3种:
(1)Statement对象用于执行不带参数的简单的SQL语句;
(2)PerparedStatement对象用于执行带或不带参数的预编译SQL语句;
(3)CallableStatement对象用于执行对数据库已存储过程的调用;
Statement的常用方法:
(1)executeQuery()方法:运行查询语句,返回ReaultSet对象。
(2)executeUpdata()方法:运行增,删,改操作,返回更新的行数。
(3)addBatch(String sql):把多条sql语句放到一个批处理中。
(4)executeBatch():向数据库发送一批sql语句执行。 -
执行
executeQuery()方法后返回的结果集
常用方法:
(1)getString(String columnName):获得当前行的某一string类型的字段
(2)getFloat(String columnName):获得当前行的某一float类型的字段
(3)getDate(String columnName):获得当前行的某一date类型的字段
(4)getBoolean(String columnName):获得在当前行的某一Boolean类型的字段
(5)getObject(String columnName):获取当前行的某一任意类型的字段
(6)next():移动到下一行
2、数据库连接池
参考文献
传统JDBC开发存在的问题:
(1)每次向数据库建立连接的时候都要将 Connection加载到内存中,会消耗大量的资源和时间
(2)对于每一次数据库连接,使用完之后都需要断开,否则可能出现数据库系统内存泄漏导致需要重启数据库
(3)不能控制被创建的连接对象数量,可能会导致服务器崩溃
数据库连接池技术解决的问题: 传统开发中数据库连接会消耗大量的资源和时间,当连接的用户过多时,还有可能导致内存泄漏,服务器崩溃。
数据库连接池的基本思想: 就是为数据库的连接建立一个 “缓冲池” 。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从 缓冲池 中取出一个,使用完毕后再放回去。
数据库连接池负责 分配、管理和释放 数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是每次都需要重新建立一个。如图

数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些
数据库连接的数量由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池技术的优点
- 资源重用:减少了系统消耗,增加了系统运行环境的平稳性
- 更快的系统反应速度:避免了数据库连接初始化和释放过程的开销,减少了系统的响应时间
- 新的资源分配手段:可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免了某一应用独占所有的数据库资源
- 统一的连接管理,避免数据库连接泄漏:在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露
数据库连接池
- JDBC数据库连接池使用java.sql.DataSource来表示,DataSource只是一个接口,该接口通常由服务器(Weblogic、WebSphere、Tomcat)提供实现,也有一些开源组织提供实现。
- DataSource通常被称为数据源或连接池,它包含连接池和连接池管理两个部分
- DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度
注意:
- 数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。
- 当数据库访问结束后,程序还是像以前一样关闭数据库连接:
conn.close();
但conn.close()并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
(1)C3P0数据库连接池
- 获取连接的方式一:
//使用C3P0数据库连接池的方式,获取数据库的连接:不推荐
public static Connection getConnection1() throws Exception{
ComboPooledDataSource cpds = new ComboPooledDataSource();
cpds.setDriverClass("com.mysql.jdbc.Driver");
cpds.setJdbcUrl("jdbc:mysql://localhost:3306/test");
cpds.setUser("root");
cpds.setPassword("abc123");
// cpds.setMaxPoolSize(100);
Connection conn = cpds.getConnection();
return conn;
}
- 获取连接的方式二(推荐):
//使用C3P0数据库连接池的配置文件方式,获取数据库的连接:推荐
private static DataSource cpds = new ComboPooledDataSource("demo");
public static Connection getConnection2() throws SQLException{
Connection conn = cpds.getConnection();
return conn;
}
其中配置文件位置在resource文件夹(resource文件夹就是默认的配置文件的位置,会自动扫描)下,名为c3p0-config.xml:
<c3p0-config>
<named-config name="demo">
<property name="user">rootproperty>
<property name="password">abc123property>
<property name="jdbcUrl">jdbc:mysql:///testproperty>
<property name="driverClass">com.mysql.jdbc.Driverproperty>
<property name="acquireIncrement">5property>
<property name="initialPoolSize">5property>
<property name="minPoolSize">5property>
<property name="maxPoolSize">10property>
<property name="maxStatements">20property>
<property name="maxStatementsPerConnection">5property>
named-config>
c3p0-config>
(2)DBCP数据库连接池
- DBCP 是 Apache 软件基金组织下的开源连接池实现,该连接池依赖该组织下的另一个开源系统:
Common-pool。如需使用该连接池实现,应在系统中增加如下两个 jar 文件:
Commons-dbcp.jar:连接池的实现
Commons-pool.jar:连接池实现的依赖库- Tomcat 的连接池正是采用该连接池来实现的。该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
- 数据源和数据库连接不同,
数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close();但上面的代码并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
- 获取连接方式一:
public static Connection getConnection3() throws Exception {
BasicDataSource source = new BasicDataSource();
source.setDriverClassName("com.mysql.jdbc.Driver");
source.setUrl("jdbc:mysql:///test");
source.setUsername("root");
source.setPassword("abc123");
//
source.setInitialSize(10);
Connection conn = source.getConnection();
return conn;
}
- 获取连接方式二:
//使用dbcp数据库连接池的配置文件方式,获取数据库的连接:推荐
private static DataSource source = null;
static{
try {
Properties pros = new Properties();
InputStream is = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
pros.load(is);
//根据提供的BasicDataSourceFactory创建对应的DataSource对象
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection4() throws Exception {
Connection conn = source.getConnection();
return conn;
}
其中,src下的配置文件为:(dbcp.properties)
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useServerPrepStmts=false
username=root
password=abc123
initialSize=10
#...
(3)Druid数据库连接池
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池,可以说是目前最好的连接池之一。
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class TestDruid {
public static void main(String[] args) throws Exception {
Properties pro = new Properties();
//pro.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
pro.load(new FileInputStream("src/main/java/com/test/jdbc/druid.properties"));//这个路径是druid.properties配置文件所在路径
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
Connection conn = ds.getConnection();
System.out.println(conn);
}
}
其中,配置文件为:(druid.properties),放在resources文件夹下
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?useSSL=false
username=root
password=123456
initialSize=10
maxActive=20
maxWait=1000
filters=wall
3、JDBC事务
MySQL事务
事务一般特指数据库事务(事务是数据库的功能)。 事务是一系列的动作,它们综合在一起才是一个完整的工作单元,这些动作必须全部完成,如果有一个失败的话,那么事务就会回滚到最开始的状态,仿佛什么都没有发生过一样。
事务的三大特性:原子性、一致性、隔离性、持久性。
- 原子性:事务是原子工作单元,由一系列动作组成,一个食物中的所有操作要么全部完成,要么全部不完成,若执行过程中有误,会被回滚到事务开始前的状态;
- 一致性:事务发生前后,数据库的完整性没有被破坏;
- 隔离性:数据库允许多个并发事务同时处理相同的数据;
- 永久性:事务完成之后,对数据库所做的操作是永久性的。
JDBC事务处理
JDBC是java数据库连接相关的API,所以java的事务管理也是通过该API进行的。JDBC的核心是Connection接口,JDBC事务管理是基于Connection接口来实现的,通过Connection对象进行事务管理。
JDBC对事物的处理规则,必须是基于同一个Connection对象的
JDBC提供了3个方法来进行事务管理
setAutoCommit()设置自动提交,方法中需要传入一个boolean类型的参数,true为自动提交,false为手动提交commit()提交事务rollback()回滚事务
JDBC默认的事务处理行为是自动提交。所以JDBC在进行事务管理时,首先要通过Connection对象调用setAutoCommit(false) 方法, 将SQL语句的提交(commit)由驱动程序转交给应用程序负责。并且调用setAutoCommit(false) 方法后,程序必须调用commit或者rollback方法,否则SQL语句不会被提交或回滚。
比如:
con.setAutoCommit();
// SQL语句
// SQL语句
// SQL语句
con.commit();或 con.rollback();
JDBC事务隔离级别:5种,在Connection接口中以常量的形式进行定义。除了TRANSACTION_NONE外,其它4种隔离级别 与 MySQL的事务隔离级别一样。
- TRANSACTION_NONE(不支持事务)
- TRANSACTION_READ_UNCOMMITTED
- TRANSACTION_READ_COMMITTED
- TRANSACTION_REPEATABLE_READ
- TRANSACTION_SERIALIZABLE
JDBC事务隔离级别可通过下面方法设置:
getTransactionIsolation() 获取当前隔离级别
setTransactionIsolation() 设置隔离级别
Connection接口中部分关于事务方面的源码:
package java.sql;
import java.sql.*;
public interface Connection extends Wrapper, AutoCloseable {
void setAutoCommit(boolean autoCommit) throws SQLException;
boolean getAutoCommit() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
int TRANSACTION_NONE = 0;
int TRANSACTION_READ_UNCOMMITTED = 1;
int TRANSACTION_READ_COMMITTED = 2;
int TRANSACTION_REPEATABLE_READ = 4;
int TRANSACTION_SERIALIZABLE = 8;
void setTransactionIsolation(int level) throws SQLException;
int getTransactionIsolation() throws SQLException;
}
Java异常
1、异常的定义与使用
异常: 在java语言中,将程序执行中发生的不正常情况称为“异常”。 注意:开发过程中的语法错误和逻辑错误不是异常。
异常的分类:
-
Error: 虚拟机无法解决的严重问题。比如:JVM系统内部错误、资源耗尽、StackOverFlowError、OOM、OutOfMemoryError。
一般不编写针对性的代码进行处理。 -
Exception: 其它因编程错误或偶然的外在因素导致的问题,可以使用针对性的代码进行处理。
异常的使用格式:
(1) try…catch…finally…
(2) try…catch
(3) try…catch…catch…
(4) try…catch…catch…finally
(5) try…finally
try…finally这种做法的目的是为了释放资源,但是异常没有处理。
直接catch和直接finally是不可以的,单独使用catch和finally是不可以的,它们必须有try的存在。
异常的好处
- 将问题进行封装。
- 将正常流程代码和问题出来代码相分离,方便阅读
异常的处理方式:
- 处理方式有两种:try-catch或者throw/throws。
(1)通过try…catch语句块来处理。Catch 语句包含要捕获异常类型的声明。当保护代码块中发生一个异常时,try 后面的 catch 块就会被检查。如果发生的异常包含在 catch 块中,异常会被传递到该 catch 块,这和传递一个参数到方法是一样。
(2)也可以在具体位置不处理,直接抛出,通过throws/throw到上层再进行处理。即不适用try-catch,直接throw/throws抛出去。 - 执行throw一定是抛出了异常;throws是声明异常出现的一种可能方式,不一定会发生异常
2、常用异常(Exception)类型
- 运行时异常-RuntimeException:可被忽略,不做处理(因为无法预先捕获并处理),因为这种异常会被自动抛出。
NullPointerException、ArrayIndexOutOfException、ClassCastException类型转换异常、ArithmeticException算数异常(如除以0)、IllegalArgumentException (非法参数异常)、IndexOutOfBoundsException (下标越界异常)、用户自定义异常等 - 编译时异常(受检查异常):不能被忽略,必须处理,否则无法通过编译,需要程序员自己抛出。
IOException——FileNotFoundException、ClassNotFoundException、SQLException、EOFException文件结束
ParseException
-
Throwable是所有异常的父类;
错误的基类是Error;
异常的基类是Exception。 -
自定义异常:
自定义异常需要继承自Exception或者RuntimeException类或其子类;
自定义异常通过throw抛出;
自定义异常通常需要编写几个重载的构造器,需要提供serualVersionUID;
自定义异常名字要见名之知意;
3、finally关键字
- finally语句为异常处理提供一个统一的出口,用于退出前的清理工作。适合放一些释放资源(在IO流操作和数据库操作中会见到)以及后续的处理代码。
- 一般来说,无论try中是否发生异常、try中是否有return、catch语句是否执行、catch中是否有return,finally语句都会执行。
如果try中有return时,在返回之前,会去先执行finally里的程序。 - 不执行finally的特例:
(1)finally里发生了异常,程序不会执行(比如第一句发生了异常,则之后的代码不会执行);
(2)程序所在线程死亡或关闭了CPU,如电脑突然关机、停电等。
(3)如果在执行到finally之前jvm退出了(比如:System.exit(0)),那么finally中的代码就不再执行了。
finally的重要性:
如果数据库访问异常,没有finally执行关闭动作的话,这个访问数据库的资源一直没有关闭,
将一直占用这个资源,有可能妨碍其他用户得访问。数据库压力会非常大。
Socket网络编程
网络编程: 就是程序部署在多台计算机上,通过网络互相访问。让程序在网络中可以传递数据。网络编程的本质是两个设备之间的数据交换
Socket本质: 是编程接口API,对于TCP/IP的封装,TCP/IP也提供了可供程序员做网络开发所用的接口
网络编程基于请求-响应,这两个模式也把网络程序分为服务器端程序和客户端程序。
- 服务器端:永无休止的在运行,等待客户端的请求,然后向客户端做出响应。
- 客户端:向服务器端发出请求,获得服务器端响应。
- 特点:
客户端有多个,服务器端只有一个,多个客户端访问同一个服务器;
服务器端被动等待请求,只要接收到请求,就会马上向客户端发出响应;
客户端主动发送请求,服务器马上就会响应客户端。
网络编程结构:B/S或C/S
- B/S:客户端是浏览器,比武taobao,baidu,京东等。程序升级只需要升级服务器端,客户端无需升级。
- C/S:客户端需要单独安装,如微信、qq等app。程序升级需要同时升级服务器端和客户端。
IP地址及端口号
当需要与某台计算机的某个应用程序建立连接时,必须要知道IP和端口号。
- IP地址:计算机在网络中的唯一标识,相当于计算机的身份证。
格式:255.255.255.255,其中每个段位的值是 0-255,其中 127.0.0.1 表示本机。 - 端口号:用于确定某个进程的地址(相当于某台计算机中某个进程的身份证号)
范围:0-65535,其中 0-1024 系统会占用。同一台计算机中,端口号不能重复。
1、理解TCP、UDP协议
网络协议:是为了进行有效的网络传输,提前制定的数据传输标准和格式。
TCP和UDP都是传输层的协议。
(Socket是基于TCP的通讯协议,即先建立连接,才能通讯。)
| 区别 | TCP | UDP |
|---|---|---|
| 是否连接 | 建立连接,形成传输数据的通道 | 面向无连接,将数据及源封装在数据包中,不需要建立连接 |
| 发送数据大小 | 在连接中进行大数据量传输,以字节流的形式 | 只能发送少量数据,每个数据包最大64K |
| 传输是否可靠 | 通过三次握手(四次挥手)完成连接,是可靠协议 | 因无连接,是不可靠协议 |
| 速度 | 必须建立连接,效率会稍低 | 不需要连接连接,速度快 |
| 应用场景 | 浏览器:HTTP、HTTPS协议; 传输文件:FTP协议; 基于邮件传输:STMP协议等; QQ文件传输等 | QQ语音 ;QQ视频 |
TCP协议:传输控制协议(Transmission Control Protocol)
- 需要先建立连接;
- 可靠安全,不丢失数据,但是速度慢
UDP协议:用户数据报协议(User Datagram Protocol)
- 无需建立连接;
- 不可靠,可能丢失数据,但速度快
应用:
如果要传输的数据是可以偶尔丢失的,那么可以使用UDP协议,如qq消息;
网上银行就不可以使用UDP
2、Java Socket编程
Socket:网络套接字 是两台计算机通信的端点。可以理解为两部通话的手机。服务器端和客户端各有一个Socket对象,就好像各有一个手机一样,可以互相传输数据。
Socket之间通讯是使用IO流完成的。每个Socket对象都有输入流和输出流对象,他们好比电话的听筒的话筒。其中输入流对应听筒,输出流对应话筒。
客户端使用OutputStream(话筒)向服务器端发送数据,服务器端使用InputStream(听筒)接收数据。反之服务器端使用OutputStream(话筒)发送数据,客户端使用InputStream(听筒)接收数据。
注意: 一个发送数据一个接收数据,必须是对应的。一方发送了数据,另一个方没有接收,或者一方接收等待中,另一个一直不发。这两种情况都无法完成数据的传输。
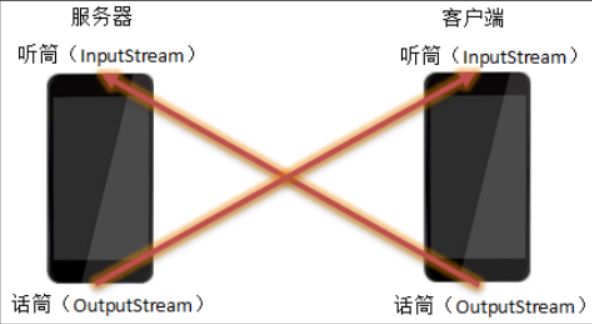
套接字使用TCP提供了两台计算机之间的通信机制。
1、客户端程序创建一个套接字,并尝试连接服务器的套接字。
2、当连接建立时,服务器会创建一个 Socket 对象。
3、客户端和服务器现在可以通过对 Socket 对象的写入和读取来进行通信。
服务器接收客户端发送数据的例子
注意:两端获取的输入流和输出流不要关闭,否则会提前导致通信连接关闭
- 服务器端
import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class ServerDemo1 {
public static void main(String[] args) throws IOException {
//1.创建服务器端 12121表示服务端的端口号
ServerSocket serverSocket = new ServerSocket(12121);
//2.与客户端连接,连接成功将获取socket对象
Socket socket = serverSocket.accept();
System.out.println("与客户端连接成功");
//3.读取客户端本次发送的数据
InputStream is = socket.getInputStream();
byte[] arr = new byte[1024];
int len = is.read(arr);
System.out.println(new String(arr,0,len));
//4.使用完毕,关闭本次通信连接.。 .
socket.close();
}
}
- 客户端
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
public class ClientDemo1 {
public static void main(String[] args) throws IOException {
//1. 创建客户端,和服务器创建连接
Socket socket = new Socket("127.0.0.1",12121);
//2. 向服务器发送消息
OutputStream os = socket.getOutputStream();
os.write("客户端回应".getBytes("utf-8"));
//3. 关闭本次通信
socket.close();
}
}
多线程
1、理解多线程的概念
普通方法调用:只有主线程一条执行路径
多线程执行:有多条执行路径,主线程和子线程并行交替执行
程序:指令和数据的有序集合
进程Process:是执行程序的一次执行过程,是一个动态的概念,是系统资源分配的单位
线程Thread: 一个进程中可以包含若干个线程。main就是我们的主线程。线程是CPU调度和执行的单位。
注意:很多多线程都是模拟出来的,即在一个cpu的情况下,在同一个时间点,cpu只能执行一个代码,因为切换的很快,所以就有同时执行的错觉。真正的多线程是指有多个cpu,即多核,如服务器。
总结:
- 线程就是独立的执行路径;
- 程序执行时,即使没有自己创建线程,后台也会有多个线程,如主线程main,垃圾回收gc线程;
- main()就是主线程,是系统的入口,用于执行整个程序;
- 一个进程中若有多线程,则现成的运行由调度器安排调度;
- 对同一份资源进行操作时,会存在资源抢夺的问题,需要加入并发控制;
- 线程会带来额外的开销,如cpu调度时间等;
- 每个线程在自己的工作内存交互,内存控制不当会造成数据不一致
2、能够使用多线程并发编程
线程创建
- 继承自Thread 类。重写run() 方法,调用start() 方法开启线程
//创建类来继承Thread类
public class TestThread extends Thread{
//run()方法线程体
@Override
public void run(){
for(int i=0;i<1000;i++){
System.out.println("多线程中的run()方法---"+i);
}
}
public static void main(String[] args){
//main主线程
//创建一个线程对象
TestThread1 testThread1 = new TestThread();
//调用start()方法开启线程
testThread1.start();//线程的run()方法与主线程main中的方法同时运行
for(int i=0;i<1000;i++){
System.out.println("main中的for循环---"+i);
}
}
}
//练习Thread,实现多线程同步下载图片
public class TestThread2 extends Thread{
//用构造器将TestThread2类中的构造方法进行重载
private String url;
private String name;
public TestThread2(String url, String name){
this.url = url;
this.name = namel
}
//重写run()方法
@Override
public void run(){
WebDownloader webDownloader = new WebDownloader();//新建下载器对象
webDownloader.downloader(url, name);//调用下载方法
System.out.println("下载的文件名为" + name);//输出我们要打印的提示信息
}
//主方法main()
public static void main(String[] args){
//创建多线程这个类的实例对象
TestThread2 t1 = new TestThread2("chrome://favicon2/? size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.csdn.net%2F", "1.jpg");
TestThread2 t2 = new TestThread2("chrome://favicon2/?size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.baidu.com%2F", "2.jpg");
TestThread2 t3 = new TestThread2("chrome://favicon2/?size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.runoob.com%2F", "3.jpg");
//启动这三个线程
t1.start();
t2.start();
t3.start();
}
}
//下载器
class WebDownloader{
//下载方法
public void downloader(String url, String name){
try{
FileUtils.copyURLToFile(new URL(url), new File(name));//作用:把一个URL变成一个文件
}catch(IOException e){
e.printStackTrace();
System.out.println("IO异常,download方法出现问题");
}
}
}
总结:
线程不一定立即执行,由CPU来调度安排执行
继承自Thread类实现多线程的过程:(1)继承自Thread类。(2)重写run()方法,(3)调用start()方法开启线程
- 实现Runnable 接口。 实现run() 方法,编写线程执行体;创建线程对象,调用start() 方法启动线程
//创建类来实现接口
public class TestThread3 implements Runnable{
//run()方法线程体
@Override
public void run(){
for(int i=0;i<1000;i++){
System.out.println("多线程中的run()方法---"+i);
}
}
public static void main(String[] args){
//创建一个Runnable接口实现类对象
TestThread3 testThread3 = new TestThread3();
//创建线程对象,通过线程对象来开启我们的线程,代理
//调用start()方法开启线程
new Thread(testThread3).start();
for(int i=0;i<1000;i++){
System.out.println("main中的for循环---"+i);
}
}
}
//用实现Runnable()接口的方法进行改写
public class TestThread2 implements Runnable{
//用构造器将TestThread2类中的构造方法进行重载
private String url;
private String name;
public TestThread2(String url, String name){
this.url = url;
this.name = namel
}
//重写run()方法
@Override
public void run(){
WebDownloader webDownloader = new WebDownloader();//新建下载器对象
webDownloader.downloader(url, name);//调用下载方法
System.out.println("下载的文件名为" + name);//输出我们要打印的提示信息
}
//主方法main()
public static void main(String[] args){
//创建多线程这个类的实例对象
TestThread2 t1 = new TestThread2("chrome://favicon2/? size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.csdn.net%2F", "1.jpg");
TestThread2 t2 = new TestThread2("chrome://favicon2/?size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.baidu.com%2F", "2.jpg");
TestThread2 t3 = new TestThread2("chrome://favicon2/?size=24&scale_factor=1x&show_fallback_monogram=&page_url=https%3A%2F%2Fwww.runoob.com%2F", "3.jpg");
//启动这三个线程------------启动方法修改了
Thread(t1).start();
Thread(t2).start();
Thread(t3).start();
}
}
//下载器
class WebDownloader{
//下载方法
public void downloader(String url, String name){
try{
FileUtils.copyURLToFile(new URL(url), new File(name));//作用:把一个URL变成一个文件
}catch(IOException e){
e.printStackTrace();
System.out.println("IO异常,download方法出现问题");
}
}
}
总结;
实现Runnable 接口实现多线程的过程:(1)创建一个类实现Runnable接口;(2)重写run()方法;(3)执行线程需要丢入Runnable接口的实现类,然后调用start()方法
Thread类本身也是实现了Runnable这个接口
- 实现Callable接口(了解即可)
总结 ❤
| 继承Thread类 | 实现Runnable接口 | |
|---|---|---|
| 子类继承Thread类具备多线程能力 | 实现Runnable接口具有多线程能力 | |
| 启动线程:子类对象.start() | 启动线程:传入目标对象+Thread(目标对象).start() | – |
| 不建议使用:避免OOP单继承局限性 | **推荐使用:**避免单继承的局限性,灵活方便,方便同一个对象被多个线程使用。 | – |
静态代理
真实对象和代理对象都要实现同一个接口
代理对象要代理真实角色
- 好处:
代理对象 可以做很多真实对象做不了的事情(比如婚庆公司的例子)
真实对象 专注做自己的事情
线程状态(5个)
- 创建状态:new一个线程,线程一旦创建就进入到了新生状态
- 就绪状态:调用start()方法之后,线程立即进入就绪状态,但不意味着立即调度执行
- 阻塞状态:当调用sleep、wait或同步锁定时,线程进入阻塞状态,就是代码不往下执行,阻塞事件解除之后,重新进入就绪状态,等待cpu调度执行
- 运行状态:进入运行状态,线程才真正执行线程体的代码块
- 死亡状态:线程中断或者结束,一旦进入死亡状态,就不能再次启动
停止线程
- 不推荐使用JDK提供的stop()、destroy()方法
- 推荐让线程自己停下来
- 建议使用一个标志位进行终止变量。即当flag=false,则终止线程运行
public class TestStop implements Runnable{
//1. 设置一个标志位flag
private boolean flag = true;
@Override
public void run(){
int i=0;
//2. 让线程的主体使用该表标识
while(flag){//设置一个外部的标志位,当标志位为false时停止操作
System.out.println("run...Thread" + i++);
}
}
//3. 设置一个公开的方法停止线程,转换标志位
public void stop(){
this.flag = false;
}
//主方法
public static void main(String[] args){
//启动线程
TestStop testStop = new TestStop();
new Thread(testStop).start();
for(int i=0;i<1000;i++){
System.out.println("main"+i);
if(i == 900){
//调用stop方法切换标志位,让线程停止进行
testStop.stop();
System.out.println("线程该停止了");
}
}
}
}
线程休眠
sleep让线程休眠,可以放大问题的发生性。
sleep(时间)制定当前线程阻塞的毫秒数;
sleep存在异常InterruptException;
sleep时间达到后线程进入就绪状态;
sleep可以模拟网络延时,倒计时等;
每一个对象都有一个锁,sleep不会释放锁;
//模拟网络延时:可方法问题的发生性
public class TestSleep implements Runnable{
//票数
private int ticketNums = 10;
@Override
public void run(){
while(true){
if(ticketNums <= 0){//没有票了就跳出
break;
}
//模拟延时
try{
Thread.sleep(100);
}catch( InterruptException e){
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "----拿到了第" + ticketNums-- + "张票");
}
}
public static void main(String[] args){
//实现Runnable接口的调用方法
TestSleep ticket = new TestSleep();
new Thread(ticket, "张三").start();
new Thread(ticket, "李四").start();
new Thread(ticket, "王二狗").start();
}
}
//模拟倒计时 / 模拟打印当前系统时间
public class TestSleep2{
public static void main(String[] args){
//打印当前系统时间
Date startTime = new Date(System.currentTimeMillis());//获取当前系统时间
SimpleDateFormat parrern = new SimpleDateFormat("HH:MM:SS");//格式化
while(true){
try{
System.out.println(pattern.format(startTime));//打印时间
Thread.sleep(1000);//休眠1000ms
startTime = new Date(System.currentTimeMillis());//刷新时间
}catch( InterruptException e){
e.printStackTrace();
}
}
}
//模拟倒计时
/**
public static void tenDown() throws TnterruptedException{
int num = 10;
while(true){
Thread.sleep(1000);
System.out.println(num==);
if(nun<=0){
break;
}
}
}
**/
}
线程礼让
//在run()方法中加入代码
Thread.yield();
线程礼让,就是让当前正在执行的线程暂停,但不阻塞
让线程从运行状态转为就绪状态
礼让不一定成功,看cpu的心情,礼让只是让CPU去重新调度这几个线程的方法
3、了解JAVA锁机制
并发: 同一个对象被多个线程同时操作
线程同步: 就是一种等待机制,多个需要同时访问此对象的线程进入到这个 对象的等待池 形成队列 【形成条件:队列+锁】
锁机制(synchronized): 由于同一个进程的多个线程共享同一块存储空间,在带来方便的同时也带来了访问冲突问题,为了保证数据在方法中被访问时的正确性,在访问时加入锁机制(synchronized),当一个线程获得对象的排它锁,独占资源,其他线程必须等待,使用后释放锁哦即可。
锁带来的问题:
性能下降;
性能倒置;
线程不安全的问题,每个线程的内存都是各自的,最开始的值都是从主内存读取到的,互不影响,因此各自操作同一个数据的时候会引发不安全的问题。
线程不安全的例子:
- 不安全的取钱:
/**
* 不安全的取钱
* 两个人去银行取钱
* 注意:一个class里只能有一个public类!
**/
public class UnsafeBank{
public static void main(String[] args){
Account account = new.Account(100, "Save money");
Drawing me = new Drawing(account, 50, "me");
Drawing you = new Drawing(account, 100, "you");
me.start();
you.start();
}
}
//账户
class Account{
int money;//余额
String name;//卡名
//构造函数
public Account(int money, String name){
this.money = money;
this.name = name;
}
}
//银行: 模拟取钱取钱
class Drawing extends Thread{
Account account;//账户
int drawingMoney;//取了多少钱
int nowMoney;//现在手里有多少钱
//构造函数
public Drawing(Account account, int drawingMoney, String name){
super(name);
this.account = account;
this.drawingMoney = drawingMoney;
}
//取钱操作
@Override
public voif run(){
//判断是否当前可以取钱
if(account.money - drawingMoney <0){
System.out.println(Thread.currentThread().getName() + "钱不够,无法取钱");
return;
}
//卡内余额 = 余额 - 取出的钱
account.money = account.money - drawingMoney ;
//手里剩的钱
nowMoney = nowMoney + drawingMoney ;
System.out.println(account.name + "余额为:" + account.money);
System.out.println(this.getName() + "手里的钱" + nowMoney);
}
}
- 线程不安全的集合:
public class UnsafeList{
public static void main(String[] args){
List<String> list = new ArrayList<String>();
for(int i=0;i<1000;i++){
new Thread(()->{
list.add(Thread.currentThread().getName());
}).start();
}
try{
Thread.sleep(3000);//休眠3000ms也就是3s,放大错误
}catch(InterruptException e){
e.printStackTrace();
}
System.out.println(list.size());
}
}
-
同步方法:
public synchronized void method(int args){}。就是给该方法加上synchronized关键字 -
synchronized方法控制对“对象”的访问,每个对象对应一把锁,每个synchronized方法都必须获得调用该方法的对象的锁才能执行,否则线程会阻塞,方法一旦执行,就独占该锁,直到该方法返回才释放锁,后面被阻塞的线程才能获得这个锁,继续执行。
缺点:影响方法执行效率。 -
同步块:
sybchronized (Obj){}。同步块锁的对象就是变化的量,需要增删改的对象,要进行锁住,吧变换的对象的具体操作放到同步块{}里。 与同步方法的不同是锁的对象不同。
其中Obj称之为同步监视器 ,Obj可以是任何对象。
同步方法中无需指定同步监视器,因为同步方法中监视器就是this,就是这个对象本身,或者是class(反射) -
线程安全的例子1:
/**
* 安全的方法——同步方法——为了保证线程安全
**/
public class UnsafeBank{
public static void main(String[] args){
Account account = new.Account(100, "Save money");
Drawing me = new Drawing(account, 50, "me");
Drawing you = new Drawing(account, 100, "you");
me.start();
you.start();
}
}
//账户
class Account{
int money;//余额
String name;//卡名
//构造函数
public Account(int money, String name){
this.money = money;
this.name = name;
}
}
//银行: 模拟取钱取钱
class Drawing extends Thread{
Account account;//账户
int drawingMoney;//取了多少钱
int nowMoney;//现在手里有多少钱
//构造函数
public Drawing(Account account, int drawingMoney, String name){
super(name);
this.account = account;
this.drawingMoney = drawingMoney;
}
//取钱操作
//同步方法synchronized默认的同步监视器【锁】就是this,这个对象本身
@Override
public void run(){
//--------------------------------------------------------------------
//同步块:锁的对象就是变化的量,需要增删改的对象,要进行锁住
synchronized(account){
//判断是否当前可以取钱
if(account.money - drawingMoney <0){
System.out.println(Thread.currentThread().getName() + "钱不够,无法取钱");
return;
}
//卡内余额 = 余额 - 取出的钱
account.money = account.money - drawingMoney ;
//手里剩的钱
nowMoney = nowMoney + drawingMoney ;
System.out.println(account.name + "余额为:" + account.money);
System.out.println(this.getName() + "手里的钱" + nowMoney);
}
//------------------------------------------------------------------------
}
}
- 线程安全的例子2:
//线程安全的集合
public class UnsafeList{
public static void main(String[] args){
List<String> list = new ArrayList<String>();
for(int i=0;i<1000;i++){
new Thread(()->{//这是一个线程的lambda表达式,用来实现线程的遍历
synchronized(list){
list.add(Thread.currentThread().getName());
}
}).start();
}
try{
Thread.sleep(3000);//休眠3000ms也就是3s,放大错误
}catch(InterruptException e){
e.printStackTrace();
}
System.out.println(list.size());
}
}
JOC:java.util.concurrent.CopyOnWriteArrayList;这个CopyOnWriteArrayList是一个线程安全的list
transient:序列的
volatile:唯一的
死锁
多个线程各自占有一些共享资源,并且互相等待其他线程占有的资源才能运行,而导致两个或者多个线程都在等待对方释放资源,都停止执行的情形。
.
某一个同步块同时拥有 “两个以上对象的锁” 时,就可能会发生 “死锁” 的问题。
产生死锁的例子:
/**
* 死锁:过多的同步可能造成相互不释放资源
* 从而相互等待,一般发生于同步中持有多个对象的锁
* 解决方法:不要在同一个代码块中,出现多个对象的锁(锁套锁)
* @author Administrator
*
*/
public class DeadLock {
public static void main(String[] args) {
Makeup g1=new Makeup(0, "girl a");
Makeup g2=new Makeup(1, "girl b");
g1.start();
g2.start();
}
}
//口红
class Lipstick{
}
//镜子
class Mirror{
}
//化妆
class Makeup extends Thread{
static Lipstick lipstick=new Lipstick();
static Mirror mirror=new Mirror();
int choice;//选择
String girl;//名字
public Makeup(int choice,String girl) {
this.choice = choice;
this.girl = girl;
}
@Override
public void run() {
makeup();
}
//相互持有对方的对象锁-->可能造成死锁
private void makeup() {
if(choice==0) {
synchronized(lipstick) {//获得口红的锁
System.out.println(this.girl+"获得口红");
//1秒后,1秒内girl b完全可以拿到mirror
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(mirror) {
System.out.println(this.girl+"获得镜子");
}
}
}
else {
synchronized(mirror) {//获得镜子的锁
System.out.println(this.girl+"获得镜子");
//2秒后,2秒内girl a完全可以拿到lipstick
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(lipstick) {
System.out.println(this.girl+"获得口红");
}
}
}
}
}
分析:
线程1先拿到了口红,在拿到口红的基础上,想拿镜子,而线程2先拿到了镜子,在拿到镜子基础上,想拿口红,那么结果就是,两个线程会无休止的等待下去。
解决方法:
不要在同一个代码块中,出现多个对象的锁(锁套锁);
解决死锁后的例子:
/**
* 死锁:过多的同步可能造成相互不释放资源
* 从而相互等待,一般发生于同步中持有多个对象的锁
* 解决方法:不要在同一个代码块中,出现多个对象的锁(锁套锁)
* @author Administrator
*
*/
public class DeadLock {
public static void main(String[] args) {
Makeup g1=new Makeup(0, "girl a");
Makeup g2=new Makeup(1, "girl b");
g1.start();
g2.start();
}
}
//口红
class Lipstick{
}
//镜子
class Mirror{
}
//化妆
class Makeup extends Thread{
static Lipstick lipstick=new Lipstick();
static Mirror mirror=new Mirror();
int choice;//选择
String girl;//名字
public Makeup(int choice,String girl) {
this.choice = choice;
this.girl = girl;
}
@Override
public void run() {
makeup();
}
//相互持有对方的对象锁-->可能造成死锁
private void makeup() {
if(choice==0) {
synchronized(lipstick) {//获得口红的锁
System.out.println(this.girl+"获得口红");
//1秒后,1秒内girl b完全可以拿到mirror
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized(mirror) {
System.out.println(this.girl+"获得镜子");
}
}
else {
synchronized(mirror) {//获得镜子的锁
System.out.println(this.girl+"获得镜子");
//2秒后,2秒内girl a完全可以拿到lipstick
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
synchronized(lipstick) {
System.out.println(this.girl+"获得口红");
}
}
}
}
产生死锁的四个必要条件:
- 互斥:一个资源每次只能被一个进程使用
- 请求保持:一个进程因请求资源而阻塞时,对已获得的资源保持不放
- 不剥夺:进程已获得的资源,在没有使用之前,不能强行剥夺
- 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系
如何避免死锁的发生:只要破坏以上四个必要条件之一即可
常见方法:
1、避免一个线程同时获取多个锁
2、避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资
线程通信
- java提供了几个方法解决线程之间的通信问题
| 方法名 | 作用 |
|---|---|
| wait() | 表示线程一直等待,直到其他线程通知,与sleep不同,会释放锁 |
| wait(long timeout) | 指定等待的毫秒数 |
| notify() | 唤醒一个处于等待的线程 |
| notifyAll() | 唤醒同一个对象上所有调用wait()方法的线程,优先级别高的线程优先调度 |
注意:这些均是Object类的方法,都只能在同步方法或者同步代码块中使用,否则会抛出异常IllegalMonitorStateException。
4、JDK线程池的使用
- 背景:经常创建和销毁、使用量特别大的资源,比如并发情况下的线程,对性能影响很大。
- 思路:提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
- 好处:提高响应速度;降低资源消耗;便于线程管理
ExecutorService:是真正的线程池接口。常见子类ThreadPoolExecutor
void execute(Runnable command):执行任务/命令,没有返回值,一般用来执行Runnable
submit(task):执行任务,有返回值,一般用来执行Callable
void shutdown:关闭连接池Executors:工具类、线程池的工厂类,用于创建并返回不同类型的线程池
//测试线程池
public class TestPool{
public static void main(String[] args){
//1. 创建服务,创建线程池
//newFixedThreadPool 参数为:线程池大小
ExecutorService service = Executor.newFixedThreadPool(10);
//2. 执行
service.execuate(new MyThread());
service.execuate(new MyThread());
service.execuate(new MyThread());
service.execuate(new MyThread());
//3.关闭链接
service.shutdown();
}
}
//实现Runnable接口去创建一个线程
class MyThread implements Runnable{
@Override
public void run(){
System.out.println(Thread.currentThread().getName());
}
}
注解
1、 注解的定义与使用
注解的定义方法
比如Juint中的@Test注解定义:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Test{ //修饰符 @interface 注解名
long timeout() default 0L; //注解元素的声明1
//注解元素的声明2
}
分析:
- 可以看到@Test注解上有@Target()和@Retention()两个注解。
这种注解了注解的注解,称之为元注解。就是我们要定义一个注解,在定义这个注解的时候,也要加上的一些注解就称为元注解
跟声明了数据的数据,称为元数据是一种意思。
常用的元注解:
@Target注解:用于限制注解能在哪些项上应用,有多个限制可传入多个值,如果没加这个注解就表示可以应用于任何项上。
@Retention注解:用于指定我们定义的这个注解应该保留多长时间,默认是RetentionPolicy.CLASS(表示包含在类文件中,不载入虚拟机)。RUNTIME表示包含在类文件中,由虚拟机载入,可以用反射API获取
@Document注解:主要用于归档工具识别。被注解的元素能被Javadoc或类似的工具文档化。
@Inherited注解:添加了@Inherited注解的注解,所注解的类的子类也将拥有这个注解。(比如父类拥有这个注解,则子类也会把这个注解继承下来)
@Repeatable注解:表示注解是可重复使用的
- 元注解之后的注解的格式是
修饰符 @interface 注解名 {
注解元素的声明1
注解元素的声明2
}
- 注解的元素声明两种形式
type elementName();//无默认值的元素必须传值
type elementName(0 default value;//带默认值
支持的元素类型:
- 8种基本数据类型(byte,short,char,int,long,float,double,boolean)
- String
- Class
- enum
- 注解类型
- 数组(所有上边类型的数组)
Java内置的注解
@Override注解: 告诉编译器这是一个覆盖父类的方法
@Deprecated注解: 表示被注解的元素已被弃用,过期了
@SuppressWarnings: 告诉编译器忽略警告
@FunctionalInterface: 该注解会强制编译器javac检查一个接口是否符合函数接口的标准。
利用反射获取注解
-
getAnnotations() 获取对象上的所有注解(包括继承)
-
getAnnotation(Class annotationClass) 获取对象上的指定注解(包括继承)
-
getDeclaredAnnotations() 用于获取对象上的所有注解(不包括继承)
-
getDeclaredAnnotation(Class annotationClass) 用于获取对象上的指定注解(包括继承)
WebService
参考文献1
参考文献2
1、什么是WebService?什么是Soap?
- WebService 是一种跨编程语言和跨操作系统平台的远程调用技术。 WebService可以实现不同系统、不同平台、不同语言之间的对接。
比如我们自己开发的系统需要一个发送邮件的功能,我们的做法是发送一个请求到一个系统,他会给我们提供邮件发送的功能。这个就是一个WebService,邮件发送系统就相当于WebService的服务端,我们的系统相当于客户端。
使用WebService来调用它的服务,只需要第三方公司提供一个接口调用文档和WebService地址,就能根据文档地址编程去调用它开放的短信服务,发送短信。
-
WebService有两种类型:
(1)以SOAP协议风格的WebService;
(2)以Restful风格的WebService -
WebService核心组件:
XML和HTTP
SOAP: 简单对象访问协议
WSDL: WebService描述语言
UDDI:统一描述、发现和集成协议 -
简单对象访问协议(SOAP): 提供了标准的RPC方法来调用WebService。SOAP规范定义了SOAP消息的格式,以及怎样通过HTTP协议来使用SOAP。
-
WebService表述语言(WSDL): 是一个基于XML的语言,用于描述WebService及其函数、参数和返回值。即提供了一个文档来让机器能读懂我们要使用的这个WebService。WSDL跟java一样,也是一种语言,是通过xml的形式说明该webservice如何调用。
2、如何编写WebService的服务器端与客户端
3、 调用ESB的soap报文的N种方式
ESB: 企业服务总线(Enterprise Service Bus),是组件与组件之间进行消息传递的载体。
组件之间可能会使用SOAP协议来通信。SOAP是一种可以接入和适配到ESB的通信协议。
WebService调用ESB的方式
- cxf框架
只需要知道WSDL地址就行了,不需要手动生成任何代码 - httpclient
- socket
通过socket发送post请求,soap请求内容写入流 - ajax调用soap
通过xmlHttp构造请求头和请求体,发送请求,回调函数的xmlHttp。responseXML种可以获取返回结果