我的实践:通过一个一维线性回归入门pytorch
文章目录
- 生成输入输出对
- 模型的设计
- 数据的加载
- 模型的训练与测试
机器学习简单来讲就是要在数据中训练出一个模型,能够将输入映射成合理的输出。所以,在训练模型之前,我们首先准备好输入、输出对;然后再利用这些输入、输出对来优化模型,使模型的LOSS(预测输出和实际输出的误差)尽可能小。模型优化的基本原理是梯度下降法。pytorch为实现上述任务提供了一个很好的框架,或者说一个很好的模板,使得做深度学习变得非常简单,简单到一两个小时就能入门。本文借助一个简单线性回归的例子,简要介绍了Pytorch框架中的数据加载及模型训练等。
生成输入输出对
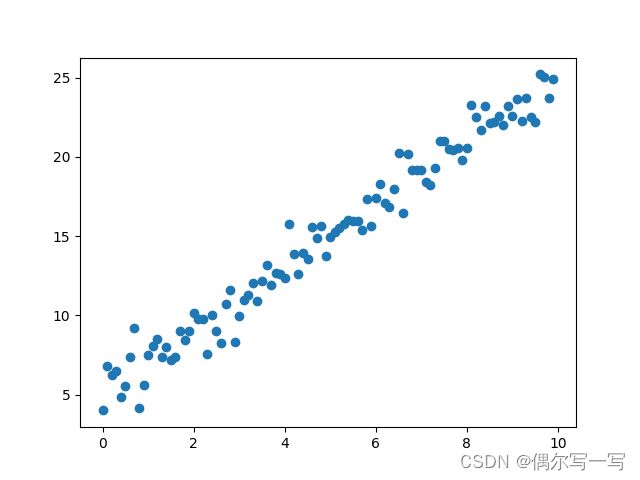
在训练模型之前,我们首先生成一些输入、输出对,作为模型训练数据和测试数据。本例通过一个线性函数叠加一些噪声来生成。比如下面这段代码,取权重值为2,偏置为5的线性函数,然后叠加一个标准正态分布的噪声,生成100个数据点。生成两次,一次用于模型训练,一次用于模型测试。通过该数据训练的线性模型,我们希望权重越接近2越好,偏置越接近5越好。
import random
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 生成数据
x = random.sample(range(0, 100), 100)
x = 0.1*np.array(x)
y = x*2+5+np.random.randn(100)
plt.plot(x, y, 'o')
plt.show()
data = [list(x), list(y)]
# 矩阵转置
data = list(zip(*data))
column = ['x', 'y']
# list转换成dataFrame
dataset = pd.DataFrame(data=data, columns=column)
# 将数据保存到'.csv'文件中
dataset.to_csv('data/trainData.csv')
# dataset.to_csv('data/testData.csv')
上述代码生成的数据分布如下图所示,
模型的设计
有了输入、输出对数据,接下来我们再来设计模型。pytorch为我们提供了一个框架,使得网络模型的搭建非常简单,简单得像是在搭积木。pytorch不仅提供了搭积木的框架,还提供了大量的积木块,例如Linear层、卷积层、激活函数等等,我们只需要根据任务需求将这些积木堆在一起就行了。我们通过线性回归这个最简单的例子来学习一下pytorch的模型搭建框架。
pytorch的积木搭建框架以及积木块都在pytorch的nn模块中,因此首先要导入nn模块。pytorch的积木搭建框架是一个叫做Module的类,在搭建自己的网络模型是需要继承这个类。在这个类里面,有两个函数为我们搭建积木提供了支撑,需要改写,一个是__init__函数,一个是forward函数。__init__函数列出我们需要用的积木块,并根据需要设置好这些积木块的相关参数;在设置参数的时候一定要注意上一层积木的输出维度和下一层积木的输入维度匹配。forward函数将这些积木块垒在一起,使输入能顺利地通过一层层的积木块,最后输出。我们这里是一个简单的线性回归问题,所以只需要一块积木,那就是nn.Linear,该积木块提供了线性变换功能。nn.Linear有三个参数,分别是in_features, out_features和bias,分别代表了输入的维度、输出的维度和是否需要偏置(默认的情况下偏置保留)。在我们这个例子中,输入和输出的维度都是1,需要偏置。模型搭建的代码如下,代码保存在model.py中。
from torch import nn
# 定义模型时继承nn.Module
class LinearRegress(nn.Module):
# __init__函数列出积木块并设置积木的参数,这里的参数由模型实例化时给出
def __init__(self, inputsize, outputsize):
super(LinearRegress, self).__init__()
self.Linear1 = nn.Linear(in_features=inputsize, out_features=outputsize)
# forward函数搭积木,将积木垒在一块,让输入依次通过积木块最后输出
def forward(self, x):
return self.Linear1(x)
数据的加载
为了简化训练数据和测试数据的加载过程,pytorch为我们提供了数据集模板Dataset以及数据加载器DataLoader。我们在训练模型时需要从数据集中抠出输入、输出对,Dataset恰好为我们给我们提供了一个抠输入、输出对的模板。我们定义自己的数据集时,需要继承Dataset,并改写三个函数,分别是__init__, getitem, len。__init__一般告诉代码要加载的数据集存在哪个位置。__getitem__从文件夹中读入数据集并进行一些处理,返回输入输出对。这里要注意返回输入、输出对的格式是Tensor,并且输入Tensor的维度一定要和模型的输入维度一致,输出Tensor的维度一定要和模型的输出维度一致,否则会出错。例如mn.Linear输入、输出都是二维Tensor,分别是[batchsize,in_features]、[bathchsize,outfeature]。所以,在加载了数据之后,首先要将输入、输出数据都转换成Tensor,然后将1维Tensor转换成二维Tensor。__len__函数返回数据集的长度。
DataLoader提供一些列参数设置,方便我们可以根据需要灵活的加载数据。例如一次加载的数据大小batchsize,是否打乱数据顺序shuffer等,还有各种参数可以看和help中对DataLoader的解释。下面是代码,保存在dataProcess.py中。
import os
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import pandas as pd
# 将数据导入到DataSet
class MyDataSet(Dataset):
# 初始化时从文件中把数据读进来
def __init__(self, dataDir, dataName):
DataPath = os.path.join(dataDir, dataName)
self.data = pd.read_csv(DataPath)
def __getitem__(self, idx):
# 将数据转换成二维Tensor
x_tensor = torch.Tensor(self.data['x'].to_list()).reshape(-1, 1)
y_tensor = torch.Tensor(self.data['y'].to_list()).reshape(-1, 1)
return x_tensor[idx], y_tensor[idx]
def __len__(self):
return len(self.data)
#加载训练数据
myTrainData = MyDataSet("data", "trainData.csv")
#将batch_size设置成50,表示每一次迭代取出50个数据。
myTrainDataLoader = DataLoader(dataset=myTrainData, batch_size=50, shuffle=True)
#加载测试数据
myTestData = MyDataSet("data", "testData.csv")
myTestDataLoader = DataLoader(dataset=myTestData, batch_size=50, shuffle=True)
模型的训练与测试
模型的训练过程大致如下:
- 从数据集中取出一个btachsize的输入、输出对。
- 把输入扔给模型,得到预测输出
- 计算预测输出和真实输出之间的LOSS
- 反向传播计算梯度,并优化一次模型参数
- 回到第1步,直到从数据集中取出所有数据,完成一次完整的训练
- 重复1-5步epoch次
为了测试模型的泛化能力,我们往往在优化模型的过程中还会使用一些测试数据来测试模型的预测效果。这里一定要注意测试数据和训练数据不是同一个数据集,提前要把数据进行分割,分成训练数据和测试数据。一般每进行一次完整的训练后,对模型进行一次测试,也就是每一个epoch,测试一次模型。测试的时候也需要计算模型预测输出和真实输出之间的LOSS,只是测试不用再计算梯度和优化模型了。如果在训练过程中发现训练的LOSS在不断减小,但是测试的LOSS却在增加,这时候模型发生了过拟合问题,要提前终止训练。
当然,我们为了看到训练的效果,往往要画LOSS随着迭代次数的变化曲线,这个我们可以借助Tensorboard,也可以用一个list把训练过程的LOSS保存下来,最后用matplotlib.pyplot画出来。
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
from dataProcess import *
import matplotlib.pyplot as plt
#加载训练数据
myTrainData = MyDataSet("data", "trainData.csv")
#将batch_size设置成50,表示每一次迭代取出50个数据。
myTrainDataLoader = DataLoader(dataset=myTrainData, batch_size=50, shuffle=True)
#加载测试数据
myTestData = MyDataSet("data", "testData.csv")
myTestDataLoader = DataLoader(dataset=myTestData, batch_size=50, shuffle=True)
# 创建网络模型
myModel = LinearRegress(inputsize=1, outputsize=1)
# 损失函数
loss_fn = nn.MSELoss()
# 学习率
learning_rate = 5e-3
# 优化器
optimizer = torch.optim.SGD(myModel.parameters(), lr=learning_rate)
# 总共的训练步数
total_train_step = 0
#总共的测试步数
total_test_step = 0
step = 0
epoch =500
# Tensorboard的writer实例,用于记录训练过程中的LOSS变化
writer = SummaryWriter("logs")
train_loss_his = []
test_totalloss_his = []
for i in range(epoch):
print(f"-------第{i}轮训练开始-------")
# 这一部分是模型训练
for data in myTrainDataLoader:
# 注意这里是取了一个batchsize的数据,该例batchsize=50,因此取了50个数据
x, y = data
# 把输入扔给模型,得到预测输出output
output = myModel(x)
# 计算预测输出output和真是输出y之间的LOSS
loss = loss_fn(output, y)
# 将梯度清零,好像这一步必须要
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 优化一次参数
optimizer.step()
# 总的迭代次数加1
total_train_step = total_train_step+1
# 将当前的LOSS放到LOSS记录的list中
train_loss_his.append(loss)
# 将当前的LOSS记录到tensorboard的中
writer.add_scalar("train_loss", loss.item(), total_train_step)
print(f"训练次数:{total_train_step},loss:{loss}")
# 下面这段代码是模型测试
total_test_loss = 0
# 这里告诉代码不用求梯度了
with torch.no_grad():
for data in myTestDataLoader:
x, y = data
output = myModel(x)
loss = loss_fn(output, y)
# 这里求一个epoch的总loss
total_test_loss = total_test_loss + loss
print(f"测试集上的loss:{total_test_loss}")
test_totalloss_his.append(total_test_loss)
writer.add_scalar("test_loss", total_test_loss.item(), i)
# 输出线性模型的两个参数,分别是权重和偏置
for parameters in myModel.parameters():
print(parameters)
writer.close()
# 画出训练损失变化曲线
plt.plot(train_loss_his)
plt.show()
# 画出测试损失变化曲线
plt.plot(test_totalloss_his)
plt.show()
运行上述代码,训练LOSS的变化如下图,

测试LOSS的变化如下图,

线性模型的两个参数:权重为2.1539,偏置为4.1611。可以看到训练后的参数和预期参数接近,但也存在一定的偏差。可以尝试设置不同学习率、采用不同的优化器、使用不同的LOSS函数等,会对结果产生很大的影响,这就是无聊的调参了。
到此为止,基于pytorch的深度学习框架就入门了,确实很简单!