ARIMA模型进行销售数据预测
ARIMA模型的预测分为以下几部分
1、导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.graphics.tsaplots import plot_pacf, plot_acf
plt.rcParams['font.sans-serif'] = ['Simhei']
plt.rcParams['axes.unicode_minus'] = False
import statsmodels.tsa.stattools as st2、导入数据
由于ARIMA方法对数据的平稳性有很高的要求,所以如果你的数据波动较大的话,还需要先进行降噪等操作来处理,我之前的数据波动性很大,然后我导师给我讲了一种方法——小波分解,处理尖峰波动数据很有效。下面是我数据的处理前后对比图,

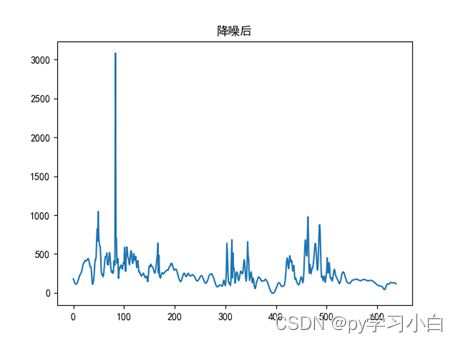
效果还是挺明显的。下面是小波分解的代码,直接把你的数据传进去,然后定义一个新的csv文件,把新的csv文件地址放上去,降噪后的数据直接就输出到这个新建的csv文件里了
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import pywt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 封装成函数
def sgn(num):
if (num > 0.0):
return 1.0
elif (num == 0.0):
return 0.0
else:
return -1.0
def wavelet_noising(new_df):
data = new_df
data = data.values.T.tolist() # 将np.ndarray()转为列表
w = pywt.Wavelet('sym8') # 选择sym8小波基
[ca5, cd5, cd4, cd3, cd2, cd1] = pywt.wavedec(data, w, level=5) # 5层小波分解
length1 = len(cd1)
length0 = len(data)
Cd1 = np.array(cd1)
abs_cd1 = np.abs(Cd1)
median_cd1 = np.median(abs_cd1)
sigma = (1.0 / 0.6745) * median_cd1
lamda = sigma * math.sqrt(2.0 * math.log(float(length0), math.e)) # 固定阈值计算
usecoeffs = []
usecoeffs.append(ca5) # 向列表末尾添加对象
# 软硬阈值折中的方法
a = 0.5
for k in range(length1):
if (abs(cd1[k]) >= lamda):
cd1[k] = sgn(cd1[k]) * (abs(cd1[k]) - a * lamda)
else:
cd1[k] = 0.0
length2 = len(cd2)
for k in range(length2):
if (abs(cd2[k]) >= lamda):
cd2[k] = sgn(cd2[k]) * (abs(cd2[k]) - a * lamda)
else:
cd2[k] = 0.0
length3 = len(cd3)
for k in range(length3):
if (abs(cd3[k]) >= lamda):
cd3[k] = sgn(cd3[k]) * (abs(cd3[k]) - a * lamda)
else:
cd3[k] = 0.0
length4 = len(cd4)
for k in range(length4):
if (abs(cd4[k]) >= lamda):
cd4[k] = sgn(cd4[k]) * (abs(cd4[k]) - a * lamda)
else:
cd4[k] = 0.0
length5 = len(cd5)
for k in range(length5):
if (abs(cd5[k]) >= lamda):
cd5[k] = sgn(cd5[k]) * (abs(cd5[k]) - a * lamda)
else:
cd5[k] = 0.0
usecoeffs.append(cd5)
usecoeffs.append(cd4)
usecoeffs.append(cd3)
usecoeffs.append(cd2)
usecoeffs.append(cd1)
recoeffs = pywt.waverec(usecoeffs, w) # 信号重构
return recoeffs
# 主函数
path = r"D:\桌面文件夹哦\数据统计\小虫\去噪前数据.CSV" # 原始数据路径
# 提取数据
data = pd.read_csv(path)
data = data.iloc[:, 0] # 取第一列数据
plt.plot(data)
plt.title("降噪前")
plt.show()
data_denoising = wavelet_noising(data) # 调用函数进行小波阈值去噪
print(data_denoising)
plt.plot(data_denoising) # 显示去噪结果
plt.title("降噪后")
plt.show()
df = pd.DataFrame(data_denoising)
df.to_csv(r"D:\桌面文件夹哦\数据统计\小虫\去噪数据.csv",float_format='%.1f')#降噪后数据保存文件3、将处理好的数据导入到本次的ARIMA模型文件中,并划分测试集、训练集以及设置索引
df = pd.read_csv(r"D:\桌面文件夹哦\Kaggle Forecasting\Store-Item-Demand-Forecasting-Challenge-master\2特征-原数据.CSV",
parse_dates=['Date'])
df.info()
# 默认索引改成时间索引
data = df.copy()
data = data.set_index('Date')
# 绘制时序图
plt.plot(data.index, data['Sales'].values)
plt.show()
# 划分测试集,训练集
train = data.loc[:'2022/8/31', :]
test = data.loc['2022/9/1':, :]
print(test)我的数据格式很简单,只有两列,一列是日期,一列是销量,无其它特征。

4、进行平稳性检验
# 单位根检验-ADF检验
print(sm.tsa.stattools.adfuller(train['Sales'])) # [ADF,P]
# 白噪声检验
# 白噪声检验
acorr_ljungbox(train['Sales'], lags = [6, 12],boxpierce=True)
# 计算ACF,PACF
acf=plot_acf(train['Sales'])
plt.title("总有功功率的自相关图")
plt.show()
# PACF
pacf=plot_pacf(train['Sales'])
plt.title("总有功功率的偏自相关图")
plt.show()ADF检验结果如下,其中第一个指标为adf指标,-8.1033明显小于5%置信水平下的值,所以该数据是平稳的。
![]()
5、AIC、BIC定阶,即确定(p,d,q)中的pq值,由于我们的数据没有进行差分,所以d直接设置为0。pq值可以通过ACF、PACF自行看出来,但是这个主观性比较大,所以,我们采用AIC、BIC方法来自动定阶。
# 通过AIC、BIC确定对应的阶数
order_analyze = st.arma_order_select_ic(train, max_ar=5, max_ma=5, ic=['aic', 'bic'])
print('train AIC', order_analyze.aic_min_order)
print('train BIC', order_analyze.bic_min_order)6、拟合模型
我的文档通过BIC、AIC模型定阶得到的pq值为3,1,直接带入进去
# 拟合模型
model = sm.tsa.arima.ARIMA(train,order=(3,0,1))
arima_res=model.fit()
arima_res.summary()7、预测+评价
#模型预测
predict=arima_res.predict("2022/9/1","2022/9/30")
original = test['Sales']
plt.plot(test.index,test['Sales'])
plt.plot(test.index,predict)
plt.legend(['y_true','y_pred'])
plt.show()
print(predict)
#评价指标评价
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
r_2 = r2_score(original,predict)
print('Test r_2: %.3f' % r_2)
# 计算MAE
mae = mean_absolute_error(original,predict)
print('Test MAE: %.3f' % mae)
# 计算RMSE
from math import sqrt
rmse = sqrt(mean_squared_error(original,predict))
print('Test RMSE: %.3f' % rmse)8、残差分析
'''残差分析'''
res=test['Sales']-predict
residual=list(res)
plt.plot(residual)
np.mean(residual)#查看残差的均值是否在0附近
plt.show()
print(np.mean(residual))