NeRF 从入门到精通
NeRF(神经辐射场)是当前最为火热的研究领域之一,效果非常惊艳,它要解决的问题就是给定一些拍摄的图,如何生成新的视角下的图. 不同于传统的三维重建方法把场景表示为点云、网格、体素等显式的表达,它独辟蹊径,将场景建模成一个连续的5D辐射场隐式存储在神经网络中,只需输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片。通俗来讲就是构造一个隐式的渲染流程,其输入是某个视角下发射的光线的位置o,方向d以及对应的坐标(x,y,z),送入神经辐射场Fθ得到体密度和颜色,最后再通过体渲染得到最终的图像。NeRF最先是应用在新视点合成方向,由于其超强的隐式表达三维信息的能力后续在三维重建方向迅速发展起来. 论文翻译 NeRF 论文主要点细致介绍
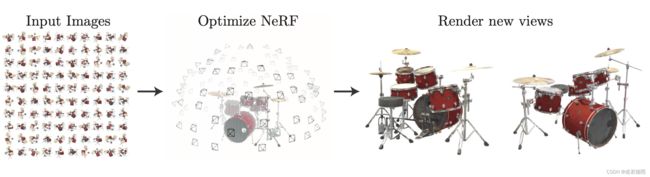 NeRF概述图
NeRF概述图
NeRF提出了一种从一组输入图像中优化连续5D神经辐射场的表示(任何连续位置的体积密度和视角相关颜色)的方法。使用体渲染技术沿光线累积此场景表示的采样点信息,以遍从任何视角渲染场景。在这里可视化了在半球区域上随机捕获的合成鼓(Synthetic Drums)场景的100个输入视图集,并展示了从优化后的NeRF表示中渲染的两个新视角下的图
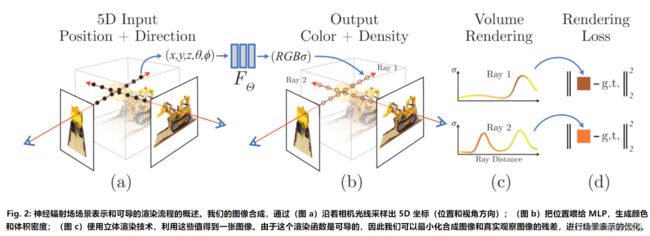 NeRF: 用于视图合成的神经辐射场的场景表示
NeRF: 用于视图合成的神经辐射场的场景表示  NeRF入门教程(原理)
NeRF入门教程(原理)  NeRF网络结构图
NeRF网络结构图
NeRF三问
1. NeRF效果为什么那么好,它解决了现有三维表达的哪些问题?
2. NeRF为什么那么慢?如何加速?
3. 为什么没看到其大规模商业应用?什么限制了它的普及?
1的解答: NeRF学习笔记 基于神经表示的三维重建建模
视角合成方法通常使用一个中间3D场景表征作为中介来生成高质量的虚拟视角,如何对这个中间3D场景进行表征,分为了“显示表示“和”隐式表示“,然后再对这个中间3D场景进行渲染,生成照片级的视角。“显示表示”3D场景包括网格,点云,体素等,它能够对场景进行显式建模,但是因为其是离散表示的,导致了不够精细化会造成重叠等伪影,更重要的是它存储的三维场景表达信息数据量极大,对内存的消耗限制了高分辨率场景的应用。”隐式表示“3D场景通常用一个函数来描述场景几何,可以理解为将复杂的三维场景表达信息存储在函数的参数中。因为往往是学习一种3D场景的描述函数,因此在表达大分辨率场景的时候它的参数量相对于“显示表示”是较少的,并且”隐式表示“函数是种连续化的表达,对于场景的表达会更为精细。NeRF做到了利用”隐式表示“实现了照片级的视角合成效果,它选择了Volume作为中间3D场景表征,然后再通过Volume rendering实现了特定视角照片合成效果。可以说NeRF实现了从离散的照片集中学习出了一种隐式的Volume表达,然后在某个特定视角,利用该隐式Volume表达和体渲染得到该视角下的照片。
 基于NeRF的三维内容生成
基于NeRF的三维内容生成
显式是离散的表达,不能精细化,导致重叠等伪影,耗费内存,限制了在高分辨率场景的应用。
隐式是连续的表达,能够适用于大分辨率的场景,而且不需要3D信号进行监督。 在NeRF之前,它的缺点是无法生成照片集的虚拟视角。eg:occupancy field、signed distance function(SDF)
2的解答 基于神经渲染的商品三维建模技术
NeRF速度慢的原因有几个方面,第一,有效像素少,生成得到的2D图像有效像素不到1/3,能够快速得到有效像素可以提升推理速度。第二,有效体素少,采样192个点,其中只有表面附近的点密度σ比较大,其他的点没必要进行推理。第三,网络推理速度慢,需要12层全连接网络推理,才能得到1个体素的颜色和密度,能优化这个性能也可以大大加快推理速度。通过空间换时间的方式,可以进行优化,包括FastNeRF、PlenOctree等方法,但是仅仅是单纯的记住NeRF输出结果,会使得存储空间过大,达到200M~1G的大小,这样的大的模型也是没法实用的。
3的解答 NeRF 背景、改进、应用与发展
NeRF目前还没有比较成功的商业化的应用,论文中的出色效果许多无法在现实中落地。技术如果不能落地,就会变成空中楼阁。NeRF还存在训练速度慢、渲染速度慢、只能用于静态场景、泛化性能差、需要大量视角、难以与传统渲染管线融合等问题,这里我们没有办法说明,隐式神经表示是未来的视觉领域的新钥匙,它的意义还需要时间和实验来证明。但是它所呈现了那一个个惊艳的demo,确实是我们对视觉和图形学最理想的追求。
 消融实验,各组件对效果的影响
消融实验,各组件对效果的影响
第9行是NeRF完整的模型做为参考基线,第一行是去除了位置编码、视角相关性和分层采样后的最小版本,2-4行是从完整模型分别去除位置编码、视角相关性和分层采样的结果,不难看出位置编码和视角相关性最为重要,分层采样也有一定的收益。5-6行展示了输入图片减少下的性能,请注意只有25张的结果依然超过了其他最好的方法。7-8行展示了位置编码L选择的影响,如果只使用5会降低性能,但是从10到15并不能提升性能,一旦2的L次方超过图中最大的频率(在我们的数据中大约是1024)再增大L的收益是有限的
针对NeRF 根本性缺陷 的改进
Mip-NeRF
NeRF只在相机位置固定、改变观察方向的视角生成上表现较好。当拉近、拉远时图像会产生锯齿以及模糊。NeRF对每一个像素只发射一条光线,如果多发射几条光线、提高采样率,在一定程度上能够解决锯齿化的问题,但这样的方法大大增加了计算量,效率低下。于是Mip-NeRF提出了用圆锥体取代光线的方案。
BARF
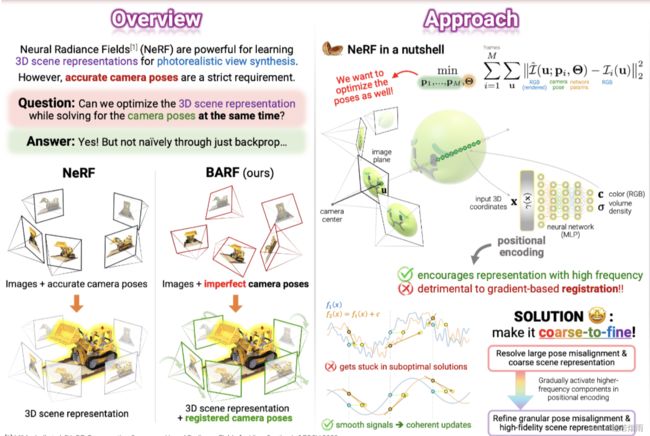 bundle-adjusting-NeRF/
bundle-adjusting-NeRF/
NeRF的依赖于准确的先验姿态,而BARF在没有非常准确的位姿情况下,仍然可以取得非常不错的结果
课程 教程
CVPR 2020 tutorial on Neural Rendering
用深度学习完成3D渲染任务的蹿红 一文详细描述了NeRF的训练流程并且给出了详细的代码解析
对于光线步进不太熟悉的可参考体积云渲染实战:ray marching,体积云与体积云光照
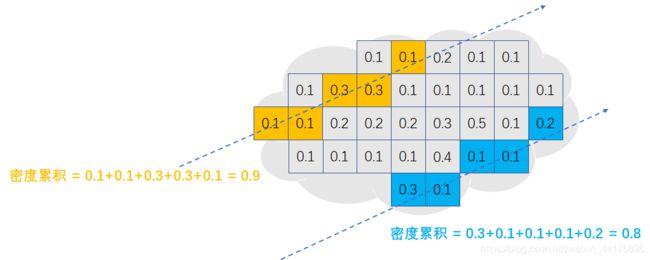
NeRF 背景、改进、应用与发展
- 提出了一种5D的神经辐射场来作为复杂场景的隐式表示
- 基于经典的volume rendering技术提出了一种可微渲染的过程
- 提出了位置编码(positional encoding)将5D输入映射到高维空间
原理说的倒是很简单,怎么看代码理解呢?
选用的代码是nerf-pytorch
数据加载、模型构建、光线生成、Pytorch版NeRF实现以及代码注释
体积渲染、位置编码
 NeRF 源码分析解读
NeRF 源码分析解读  NeRF入门教程(代码)
NeRF入门教程(代码)
Nerf源码解析——Pytroch3D版 深度解读nerf-pytorch项目 nerf-pytorch代码逐行分析
NeRF的在训练中输的数据是:从不同位置拍摄同一场景的图片,拍摄这些图片的相机位姿、相机内参,以及场景的范围。若图像数据集缺少相机参数真值,作者便使用经典SFM重建解决方案COLMAP估计了需要的参数,当作真值使用。
在训练使用NeRF渲染新图片的过程中,先将这些位置输入MLP以产生volume density和RGB颜色值;取不同的位置,使用体积渲染技术将这些值合成为一张完整的图像;因为体积渲染函数是可微的,所以可以通过最小化上一步渲染合成的、真实图像之间的差来训练优化NeRF场景表示。这样的一个NeRF训练完成后,就得到一个 以多层感知机的权重表示的 模型。一个模型只含有该场景的信息,不具有生成别的场景的图片的能力。
代码实践
看到效果这么好?是不是忍不住想自己训练几个了呢?别急,NeRF对训练数据非常挑剔,先把这几个小建议看完再拍数据也不迟 训练NeRF模型的几个建议
这里推荐全流程的笔记:5秒钟训练NeRF,NVIDIA Instant NeRF 测试
上面那个速度很快,但是加了很多trick不是很好理解。理解代码还得从原版入手,使用作者提供的数据集可以非常容易的训练,训练8-12小时左右就可得到不错的模型
git clone https://github.com/yenchenlin/nerf-pytorch.git
cd nerf-pytorch
pip install -r requirements.txt
bash download_example_data.sh
python run_nerf.py --config configs/lego.txt训练时的日志如下,单卡V100训练papers里设置的200k iters需要约9个小时,而训练2M iters则需要约3天
2022-08-07 11:11:26,936 Loaded blender (138, 400, 400, 4) torch.Size([40, 4, 4]) [400, 400, 555.5555155968841]
2022-08-07 11:11:27,832 Found ckpts []
2022-08-07 11:11:27,832 Not ndc!
2022-08-07 11:11:27,832 Begin
2022-08-07 11:11:27,833 TRAIN views are [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
96 97 98 99]
2022-08-07 11:11:27,833 TEST views are [113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130
131 132 133 134 135 136 137]
2022-08-07 11:11:27,833 VAL views are [100 101 102 103 104 105 106 107 108 109 110 111 112]
2022-08-07 11:11:27,895 [Config] Center cropping of size 200 x 200 is enabled until iter 500
2022-08-07 11:11:39,655 [TRAIN] Iter: 100 Loss: 0.21448999643325806 PSNR: 9.682350158691406
2022-08-07 11:11:51,337 [TRAIN] Iter: 200 Loss: 0.18467113375663757 PSNR: 10.187240600585938
2022-08-07 11:12:02,997 [TRAIN] Iter: 300 Loss: 0.1307702213525772 PSNR: 11.529464721679688
2022-08-07 11:12:14,597 [TRAIN] Iter: 400 Loss: 0.09181326627731323 PSNR: 13.534463882446289
2022-08-07 11:12:26,232 [TRAIN] Iter: 500 Loss: 0.04724493995308876 PSNR: 16.618690490722656
2022-08-07 11:12:38,102 [TRAIN] Iter: 600 Loss: 0.024210933595895767 PSNR: 19.26488494873047
2022-08-07 11:12:50,058 [TRAIN] Iter: 700 Loss: 0.02467876300215721 PSNR: 19.190380096435547
2022-08-07 11:13:02,035 [TRAIN] Iter: 800 Loss: 0.022504327818751335 PSNR: 19.746057510375977
2022-08-07 11:13:13,930 [TRAIN] Iter: 900 Loss: 0.01715896651148796 PSNR: 20.800106048583984
2022-08-07 11:13:25,805 [TRAIN] Iter: 1000 Loss: 0.011604433879256248 PSNR: 22.746078491210938
...
2022-08-07 12:55:13,045 Done, saving (40, 400, 400, 3) (40, 400, 400)
2022-08-07 12:55:14,048 test poses shape torch.Size([25, 4, 4])
2022-08-07 12:58:08,322 Saved test set
2022-08-07 12:58:08,323 [TRAIN] Iter: 50000 Loss: 0.006679918151348829 PSNR: 26.695810317993164
...
2022-08-07 14:44:54,779 [TRAIN] Iter: 100000 Loss: 0.0030043553560972214 PSNR: 31.759702682495117
...
2022-08-07 16:31:54,245 [TRAIN] Iter: 150000 Loss: 0.004577052779495716 PSNR: 30.233829498291016
...
2022-08-07 18:18:24,129 [TRAIN] Iter: 200000 Loss: 0.0029374894220381975 PSNR: 33.149261474609375
...
2022-08-07 20:04:40,973 [TRAIN] Iter: 250000 Loss: 0.0024353070184588432 PSNR: 32.8510627746582
...
2022-08-07 21:50:57,790 [TRAIN] Iter: 300000 Loss: 0.003205683780834079 PSNR: 31.8543758392334
...
2022-08-07 23:37:15,449 [TRAIN] Iter: 350000 Loss: 0.0018961415626108646 PSNR: 35.06672668457031
...
2022-08-08 01:23:30,750 [TRAIN] Iter: 400000 Loss: 0.003284045495092869 PSNR: 32.84665298461914
...
2022-08-08 03:09:51,729 [TRAIN] Iter: 450000 Loss: 0.0028410619124770164 PSNR: 30.531545639038086
...
2022-08-08 04:56:10,768 [TRAIN] Iter: 500000 Loss: 0.0015981048345565796 PSNR: 35.85493850708008
...
2022-08-08 22:46:49,150 [TRAIN] Iter: 1000000 Loss: 0.0011331683490425348 PSNR: 38.53938674926758
....
2022-08-09 16:34:49,687 [TRAIN] Iter: 1500000 Loss: 0.0014951317571103573 PSNR: 36.259368896484375
...
2022-08-10 10:27:08,556 [TRAIN] Iter: 2000000 Loss: 0.0021002222783863544 PSNR: 34.695308685302734可视化结果如下,图标含义:标迭代次数, PNSR,粗看都差不多,但是放大看漏斗处糊的程度不一样
 50000, 26.69
50000, 26.69  100000, 31.75
100000, 31.75  150000, 30.23
150000, 30.23  200000, 33.15
200000, 33.15  300000, 31.85
300000, 31.85  400000, 32.84
400000, 32.84  500000, 35.85
500000, 35.85  1000000, 38.54
1000000, 38.54  1500000, 36.23
1500000, 36.23  2000000, 34.67
2000000, 34.67
NeRF是典型的不地道,用它自带的数据训一个比一个漂亮,有种瞬间成大佬的感觉,可是一旦要训自己采集的数据,训一个糊一个,让人有种深深的挫败感,问题出在哪呢?
其实数据不是随便拍的,预处理也有很多讲究,而且当使用它给出的llff代码生成训练所需的poses_bounds.npy时一定还会报这个让人摸不着头脑的问题
IndexError: list assignment index out of range原因是colmap会丢掉信息比较小的帧,因此该帧是没有pose可以生成的,在官方LLFF中会出现indexError。而使用starhiking/LLFF 会忽略这个问题,并且在相应图片文件夹下生成一个view_imgs.txt文件标注了colmap实际使用的图片名字,此时剔除images中不存在于view_imgs.txt的图片即可
由于手头没有数据集,我们选择nerf自带的fern进行测试,将其下的image数据拷贝到新建的project文件夹内,新建run.sh并赋予运行权限,执行如下代码获取其所需的位姿真值,具体命令含义可参见三维重建:colmap安装与使用,colmap简介及入门级使用
代码看起来很复杂,简单说来就是通过特征提取、特征点匹配、稀疏重建用colmap最终计算出:相机内参、相机位姿、稀疏3D点
用LLFF 项目中的imgs2poses.py将相机的参数转换为poses_bounds.npy(python imgs2poses.py fern/ )至此NeRF训练需要的数据制作完成
此外原版NeRF训练非常慢,一般要8-12个小时才能得到一个还不错的结果,为此各路大神提出了很多改进方案,最有名的是NVIDIA的 instant-ngp , 其自带GUI可视化训练,速度超快,具体方法可参看instant-ngp的环境搭建和demo
美中不足的是它的代码是tiny-cuda-nn写的,读起来不如pytorch舒畅,没事,还有torch-ngp
nerf_pl: NeRF (Neural Radiance Fields) and NeRF in the Wild using pytorch-lightning
NeRF训练视频教程中文字幕版 NeRF导出带纹理mesh模型
商业应用
这方面做的最好的还属阿里,推出了Object Drawer,它的价值在于消除了显示的建模流程,提高了商品重建和展示的效率,在其官方的博客上给出了几篇论述,但比较分散,这里整理如下
1.淘系技术发布业界首个基于神经渲染的3D建模产品Object Drawer,推理速度均提升10000倍
2.基于神经渲染的商品三维建模技术
3.大淘宝技术发布首个基于神经渲染的3D建模产品Object Drawer
4.CVPR 2022 | 鲁棒的神经辐射场重建
NeRF的主要限制之一是:其需要很多图片来恢复纹理与几何细节。因此很多研究“极少量图片或者无监督的神经辐射场重建”,其往往假设:仅有一个场景下的几张图片数据,甚至场景中的部分区域从未被观察到。 其难以生成高质量的新视角图片,主要原因在于训练与测试视角差异较大,而NeRF较易过拟合至训练视角,导致最终新视角的效果较差
5.CVPR 2022 | 神经辐射场几何编辑方法NeRF-Editing
基于图像的3D场景建模与渲染是计算机视觉和计算机图形学中一个被广泛研究的课题。传统的方法依赖基于网格的场景表征,通过可微分光栅化程序或路径追踪的方法根据真实图像以优化网格表征。然而,基于二维图像监督的网格优化往往易于陷入局部最优,并且在优化过程中无法改变网格的拓扑结构。
6. 商品3D建模的视觉定位和前景分割方法
目前业界比较成熟的视觉方案是COLMAP. 在实际使用中我们发现,COLMAP的成功率只有80%,尤其在弱纹理、重复纹理、相机运动快时,精度严重下降;或者部分帧pose丢失甚至软件直接崩溃。

NeRF相关技术在实际应用中存在许多问题,主要问题包括:
1.训练及推理速度较慢,1张1080P图推理时间超过50s,一个物体的建模时间通常需要2天以上
2.渲染图片清晰度不足,且无法恢复细节纹理
3.需要大量多视角图片才能实现较好的view interpolation
4.隐式表达无法直接导入图形学工具,不支持显式使用,例如CAD场景搭配设计
5.只能还原拍摄场景的光照,无法支持环境光照变化的场景应用
辐射神经场算法改进 NeRF算法详解
传统三维重建如Photo grammetry工具大致流程为:稀疏点云重建->稠密点云重建->网格重建->纹理贴图->材质贴图。经验表明,以Photogrammetry为基础的建模工具强依赖于拍摄环境;对弱纹理和平滑区域的表面还原较差;通常依赖人工修复模型网格与纹理并赋予材质。
NeRF虽然是隐式表示了三维模型,但也可以采用一些方法将NeRF的模型显式提取,并进行可视化分析。我们的分析结果为:
第一,NeRF得到的三维模型表面粗糙,但不影响渲染效果。因为NeRF不是将射线与物体表面相交于1个点,而是用一系列点的概率来表示,这样的方法降低了对模型形状精细度的要求,依赖于整体的渲染过程完成颜色的修正。
第二,NeRF的三维模型许多时候是有缺陷的。弱纹理区域传统方法很难处理,NeRF生成的模型在弱纹理区域也经常出现凹陷等问题,但是这些凹陷对渲染结果的影响有限。
第三,NeRF的形状收敛速度很快。一般训练2~4个epoch,模型形状已经完成收敛与最终结果差异不大,而颜色则需要几十个epoch迭代。
推理速度
输出1920*1080分辨率的图像,NeRF的推理速度为50s/帧,而实用的要求要达到30帧/s以上,差距为1500倍。参考三问2,我们分别从3个角度进行分析:
有效像素
我们需要快速得到有效像素从而支持神经渲染。首先我们通过NeRF模型的密度σ可以预先提取mesh模型,mesh模型和神经网络共同表示三维模型。mesh模型支持光栅化渲染,可以快速得到2D有效像素,只针对有效像素渲染可以大大提升渲染速度。
有效体素
空间中大量的点不在物体表面附近,随机采样的效率很低,利用mesh模型,可以快速得到物体表面信息,从而只在表面附近进行采样,这样的话,采样的效率可以大大提升,可以不需要粗采样,直接精采样,精采样也只需要32个点即可达到同样的效果。
网络优化
12层神经网络来进行模型表示,其中蕴含着大量冗余节点。网络加速的方法主要是两种,一种是网络剪枝,另一种是模型蒸馏。我们通过实验验证,网络剪枝的方法在NeRF网络优化方面优于模型蒸馏。通过L1正则,我们可以优化80%的节点,网络规模下降到原来的1/5,效果保持不变。
动手训练新的三维场景
poses_boudns.npy记录了相机的内参,包括图片分辨率(图片高与宽度)、焦距,共3个维度、外参(包括相机坐标到世界坐标转换的平移矩阵 与旋转矩阵 ,其中旋转矩阵为 的矩阵,共9个维度,平移矩阵为 的矩阵,3个维度,因此该文件中的数据维度为 (另有两个维度为光线的始发深度与终止深度,通过COLMAP输出的3D点位置计算得到),其中N为图片样本数
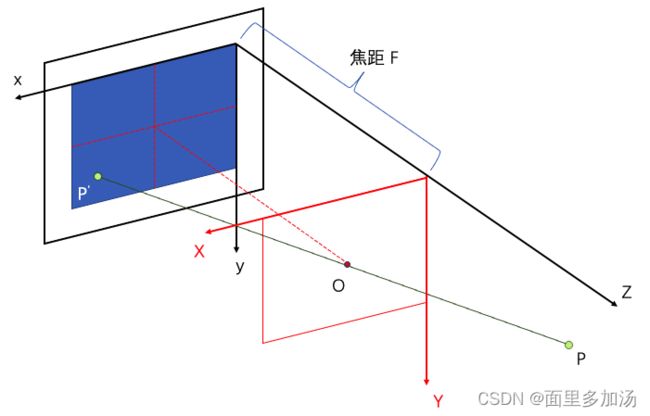
像素坐标到相机坐标的变换
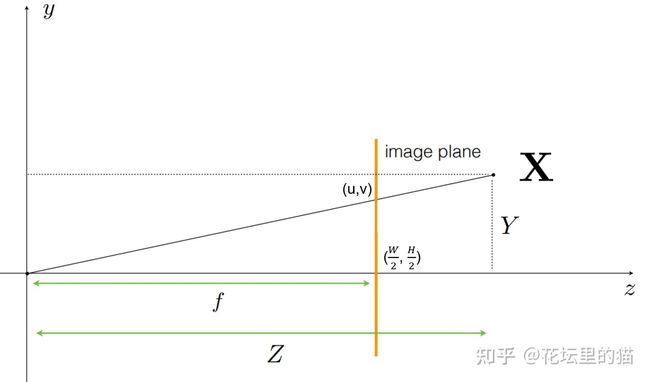
dirs=np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)为什么相机坐标前面有负号?那是因为COLMAP采用的是opencv定义的相机坐标系统,其中x轴向右,y轴向下,z轴向内;而Nerf pytorch采用的是OpenGL定义的相机坐标系统,其中x轴向右,y轴向上,z轴向外。因此需要在y与z轴进行相反数转换。
这块需要结合光线追踪相关的原理来看Ray Tracing in One Weekend(中文翻译)
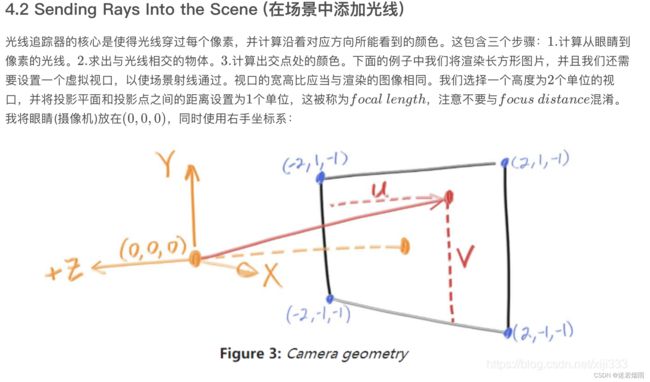
MLP的输入并不是真正的点的三维坐标 ,而是由像素坐标经过相机外参变换得到的光线始发点与方向向量以及不同的深度值构成的,而方位的输入也并不是 ,而是经过标准化的光线方向
最新的进展可关注awesome-neural-rendering