sklearn中GradientBoostingClassifier bug:ValueError: Input contains NaN, infinity or a value too large
文章目录
- 宣称支持缺失值处理
- 实际却不支持缺失值处理
宣称支持缺失值处理
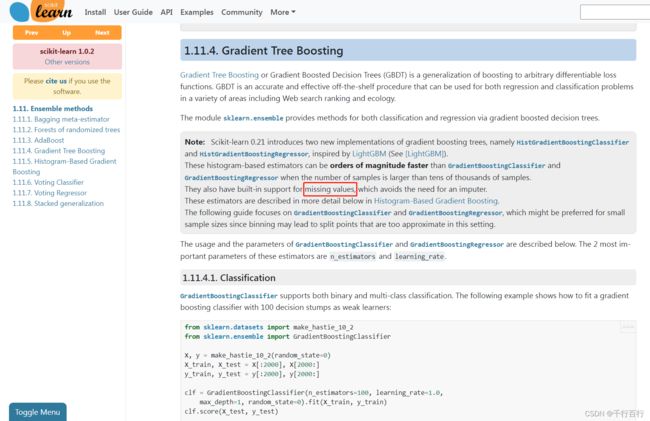
sklearn的文档宣称支持处理缺失值,文档原文如下(为了防止文档发生变化,特意截图如下):
Note Scikit-learn 0.21 introduces two new implementations of gradient boosting trees, namely HistGradientBoostingClassifier and HistGradientBoostingRegressor, inspired by LightGBM (See [LightGBM]).
These histogram-based estimators can be orders of magnitude faster than GradientBoostingClassifier and GradientBoostingRegressor when the number of samples is larger than tens of thousands of samples.
They also have built-in support for missing values, which avoids the need for an imputer.
These estimators are described in more detail below in Histogram-Based Gradient Boosting.
The following guide focuses on GradientBoostingClassifier and GradientBoostingRegressor, which might be preferred for small sample sizes since binning may lead to split points that are too approximate in this setting.
实际却不支持缺失值处理
import numpy as np
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
X_train[0,0]=np.nan
clf = GradientBoostingClassifier()
clf.fit(X_train, y_train)
报错:
ValueError: Input contains NaN,
infinity or a value too large for dtype('float32').
我使用的sklearn版本是1.0.2,版本是符合文档要求的。
可见sklearn还是有bug的,大家用的时候小心点!