Pytorch中模型常用片段汇总
文章目录
- 前言
- 1、统计模型的可学习参数的数量
- 2、模型不同位置使用不同学习率
- 3、目标检测中box的变换
- 4、张量提取操作
- 5、绘制边框和坐标
- 6、新奇的expand操作
- 7、编译相关
- 8、可视化PIL --> to_tensor转换
- N、分布式相关
前言
本文主要整理一些pytorch关于搭建模型过程中常用的代码片段。
1、统计模型的可学习参数的数量
这个指标是我在conditional detr论文中看见的,即比较的是detr和conditional detr两个方法参数的数量。注意,此处统计的是数量,并不是参数所占有的内存大小。贴上公开源码:
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print('number of params:', n_parameters) # 43,196,001
比如conditional detr的参数数目为43,196,601即可学习参数的数量为43M。
2、模型不同位置使用不同学习率
比如给backbone和model其余部分采用不同的学习率进行更新:
param_dicts = [
# 除backbone其余模块的可学习参数,n是名字,属于字符串对象
{"params": [p for n, p in model_without_ddp.named_parameters() if "backbone" not in n and p.requires_grad]},
# backbone单独指定的学习率
{
"params": [p for n, p in model_without_ddp.named_parameters() if "backbone" in n and p.requires_grad],
"lr": 1e-5,
},
]
'''
n:
backbone.0.body.layer3.5.conv3.weight
backbone.0.body.layer4.0.conv1.weight
'''
optimizer = torch.optim.AdamW(param_dicts, lr=1e-4, weight_decay=1e-4)
# 40轮epochs后更新一次学习率。
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 40)
# 在每一个iter后,更新一次优化器
for cur_epoch in epochs:
for data in cur_epoch:
optimizer.zero_grad()
losses.backward()
# max_norm = 0.1是个超参。
# 执行梯度裁剪
if max_norm > 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
# 更新一轮epoch后,在调用lr_scheduler。
lr_scheduler.step()
上述部分中单独指定了backbone的学习率为1e-5,其余模块学习率为1e-4,且权重衰减为1e-4;且训练经过40轮epochs后更新一次学习率。另外,还设定了一个梯度裁剪参数,若模型的的参数梯度超过max_norm则执行裁剪。
3、目标检测中box的变换
在目标检测算法中,经常涉及boxes由[cx,cy,w,h] <–> [x1,y1,x2,w2]以及rescale的操作变换。在此提供两个函数:
参考地址:Facebook_detr
code:
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1) # [N]
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1) # [N] --> [N,1] --> [N,4]
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
# boxes: [cx,cy,w,h]
boxes =torch.tensor([[1,2,3,4],[5,6,7,8]],dtype=torch.float32)
# rescale
res = rescale_bboxes(boxes,(1,1))
print(res)
4、张量提取操作
常用来提取置信度>某个阈值的操作,语言描述不出来,看代码吧:
# 若batch == 1
boxes = torch.randn(1,5,4) # [b=1,num_boxes,4]
keep = torch.tensor([0,0,0,1,1]).to(torch.bool) # [num_boxes]的bool型张量
res = boxes[0,keep] # [2,4],将keep中TRUE的boxes提取出来,注意0不能舍去
print(res)
print(res.shape)
# 若batch>1,常用来计算loss,因为可以消除掉batch这个维度
boxes = torch.randn(2,5,4) # [batch, num_boxes, 4]
keep = torch.tensor([[0,0,0,1,1],[1,1,1,0,0]]).to(torch.bool) # [batch,num_boxes]
res = boxes[keep] # [num_truth,4]
print(res)
print(res.shape)
简单理解,若想提取布尔型张量keep中的TRUE所对应的元素,则keep的shape必须和待提取张量的前两维度相同:4维张量则3维的keep;3维张量则2维的keep。
5、绘制边框和坐标
同样,在facebook_detr搬运过来的。
def plot_results(pil_img, prob, boxes):
'''
pil_img: Image.open()对象
prob:[num_TP,num_classes]的Tensor
boxes:[num_TP,4]
'''
plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), COLORS * 100):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=3))
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=15,
bbox=dict(facecolor='yellow', alpha=0.5))
plt.axis('off')
plt.show()
6、新奇的expand操作
这种比普通的torch.expand操作更加实用,可以作为一个技巧使用。
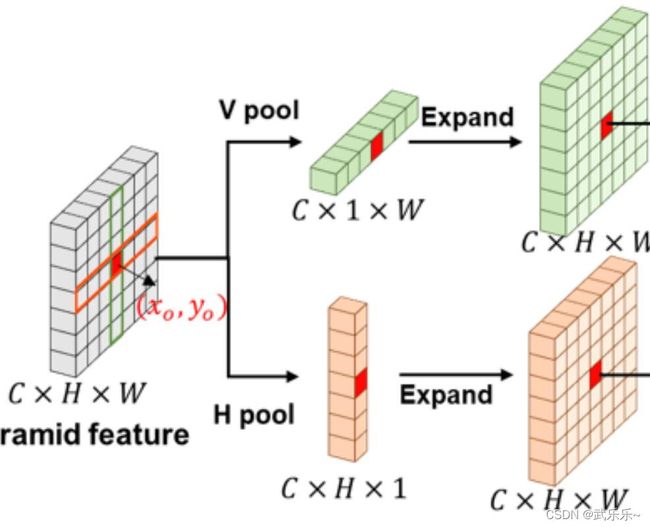
import torch
import torch.nn as nn
import torch.nn.functional as F
#----#
# 输入
#----#
fm = torch.randn(1,3,128,100)
#----------------------#
# 创建四个W和H方向上的操作
#----------------------#
h_pool = nn.AdaptiveAvgPool2d((1, None))
w_pool = nn.AdaptiveAvgPool2d((None, 1))
#--------------#
# 创建一个1*3卷积
#--------------#
h_conv = nn.Conv2d(3, 3, (1, 3), 1, (0, 1), bias=True)
w_conv = nn.Conv2d(3, 3, (3, 1), 1, (1, 0), bias=True)
#---------------------#
# forward计算
#---------------------#
h = h_pool(fm) # [1,3,1,100]
h = h_conv(h) # [1,3,1,100]
# 双线性插值采样:[1,3,1,100] --> [1,3,128,100]
# 注意 align_corners 设置为 True,默认是FALSE
reg_feat_h = F.interpolate(h, (128,100), mode='bilinear', align_corners=True)
7、编译相关
python setup.py build_ext --inplace # 仅编译算子在当前文件夹
python setup.py install # 编译成包放进虚拟环境
python setup.py develop # 上述两条命令的合并
8、可视化PIL --> to_tensor转换
千万记得是 np.uint8!!!
img = sample['img'].permute(1,2,0).contiguous().numpy() * 255
img = img.astype(np.uint8) # 服了u