决策树原理及CART算法python实现
本博客分成两部分
- 第一部分记录决策树的原理以及 I D 3 ID3 ID3、 C 4.5 C4.5 C4.5算法
- 第二部分记录CART算法、及其简单实现
具体内容看目录
决策树
概念
决策树是一种基本的分类与回归的算法,其模型呈树形结构,在分类问题种,表示基于特征对实例进行分类的过程,可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布
分类与回归一个比较浅层的区别是回归针对连续变量,分类针对离散变量
本博客大部分内容是记录分类问题的学习,当然后面也会有回归问题的分析
在学习的时候,利用训练数据,根据损失函数最小化原则建立决策树模型。
在预测的时候,对新的数据,利用决策树模型进行分类
决策树的学习通常包括3个步骤:特征选择、决策树的生成、决策树的剪枝
决策树学习思想主要来自ID3算法、C4.5算法以及CART算法
分类问题训练数据集为:
D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . ( x N , y N ) D = {(x_1,y_1),(x_2,y_2),...(x_N,y_N)} D=(x1,y1),(x2,y2),...(xN,yN)
其中
- x i = ( x i ( 1 ) , x i ( 2 ) , . . . x i ( n ) ) x_i=(x_i^{(1)},x_i^{(2)},...x_i^{(n)}) xi=(xi(1),xi(2),...xi(n))为输入实例(特征向量),n为特征个数
- y i ∈ { 1 , 2 , . . . K } y_i\in\{1,2,...K\} yi∈{1,2,...K},为标记的类
- N N N为样容量
本篇博客围绕的训练数据集如下:
一家银行的贷款样本,希望通过该训练集学习一个贷款申请的决策树(通过特征对样本中的人(实例)进划分),从而对新的贷款申请顾客进行分类,根据其特征判断是否应该给他贷款
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 是否同意贷款(类别) |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
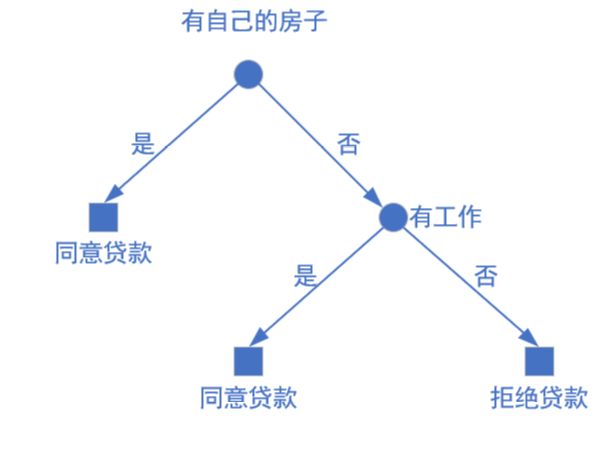
经过对这个数据集的划分,有可能得到下面左图这个决策树
此时有个人要贷款,其特征是(青年,没有工作,有自己的房子,信贷情况良好)。
则该人(实例)最后被分到的类别是同意贷款(如右图)

模型与学习
决策树的模型
决策树是一种描述对实例进行分类的树形结构。其内部结点表示一个特征或者属性,叶结点表示一个分类
在用决策树分类时(决策树已经生成),从根节点开始,根据某一特征将实例分配到其子结点中,每个子结点对应该特征的一个取值。递归对实例进行分配,直到分配到叶节点,将该实例分类到叶节点的类中。
正如上面那个例子那样
决策树与 i f − t h e n if-then if−then
概念中说到的决策树可以看作一种if-then规则的集合,其转换如下:
- 由决策树的根节点到叶节点对应的每一条路径构建一条规则
- 路径上的内部结点的特征对应着规则的条件,叶节点对应着规则的结论
如下上面贷款例子的决策树可以转化为一个if-then规则如下。对于不同的决策树,有着不同的规则,但是都是if-then结构

决策树的路径(规则)对应的if-then规则有一个重要的性质叫做互斥且完备:
-
完备:每个实例都被一条路径(规则)覆盖
如上图中每个人能从这个决策树找到一条路径
-
互斥:每个实例只被一条规则所覆盖
因为是if-else结构,那么肯定是互斥的
决策树与条件概率分布
除了看作if-then的规则集合,决策树还能看作给定特征条件下的条件概率分布,这一条件概率分布定义在特征空间的一个划分。
所有特征向量存在的空间称为特征空间,可以将其映射到坐标轴上
通过特征将特征空间划分为互不相交的单元或者区域,在每个单元定义一个类的概率分布就构成了一个条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X), X X X取决于单元的集合(X=c代表当前单元为 c c c), Y Y Y取决于类的集合
决策树的一条路径对应的就是特征空间划分中的一个单元,一个单元就是决策树中的一个叶节点,决策树将一个叶节点的实例的类别强行分到条件概率最大的一类中
样本中的被分配到某个叶节点的实例类别不一定全是一样的,所以我们要找个方式确定叶节点代表的类别,这个方法就是条件概率分布
即叶节点中哪个类别的实例多就将叶节点划分为哪个类
如图我们有如下一个特征空间(矩形区域)
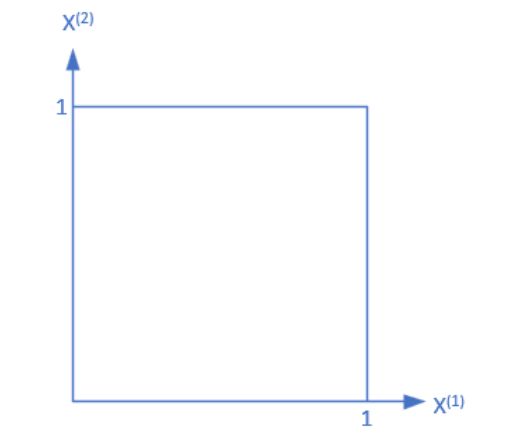
现在对其进行划分成若干个小矩形,每个小矩形表达的就是一个单元

设X取值为单元的集合, Y Y Y为类的集合,类的取值为+1和-1,则当每个单元中对应的条件概率分布为 P ( Y ∣ X ) P(Y|X) P(Y∣X)
由于假设Y的的取值只有两个,即+1和-1,则某个单元c的条件概率满足 P ( Y = + 1 ∣ X = c ) > 0.5 P(Y=+1|X=c)>0.5 P(Y=+1∣X=c)>0.5时,认为这个单元(叶节点)属于正类。落在这个单元的实例都被分到正类
假设条件概率分布如左图所示,则最终对单元(叶节点)的分类如右图所示,则最终每个单元(叶节点)的分类如右图所示
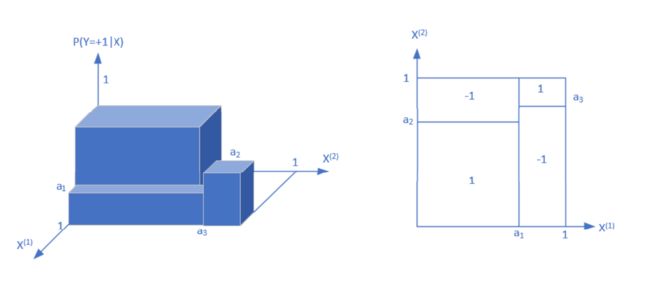
上述的条件概率分布最终可以对应到下面这棵决策树

决策树学习
学习目标
假设给定训练数据集
D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . ( x N , y N ) D = {(x_1,y_1),(x_2,y_2),...(x_N,y_N)} D=(x1,y1),(x2,y2),...(xN,yN)
其中
- x i = ( x i ( 1 ) , x i ( 2 ) , . . . x i ( n ) ) x_i=(x_i^{(1)},x_i^{(2)},...x_i^{(n)}) xi=(xi(1),xi(2),...xi(n))为输入实例(特征向量),n为特征个数
- y i ∈ { 1 , 2 , . . . K } y_i\in\{1,2,...K\} yi∈{1,2,...K},为标记的类
- N N N为样容量
决策树学习的目标就是利用给定的训练数据集建立决策树模型,使它能对实例进行正确的分类
能对训练数据进行正确分类的决策树可能有多个,也可能一个都没有
因为基于特征空间划分的类的条件概率有无穷多个
我们需要一个能比较好地对训练数据集进行正确分类的决策树,同时有比较好的泛化能力
前者表示能对训练数据集有比较准确的分类能力,后者指对未知的数据也要有比较准确的预测(也就是不能过拟合)
过拟合会使模型缺乏泛化能力
学习策略
决策树学习的策略是以损失函数为目标函数的最小化
当损失函数确定后,我们便能根据损失函数选择最优的决策树(因为一个数据集的决策树可以有多个)
其中损失函数与决策树的拟合能力和泛化能力有关,在拟合和泛化中寻找平衡
学习算法
概念中说过,决策树是基于特征对训练集进行分类的,而一个特征向量有许多个特征,先选取哪个特征对数据集划分就是一个问题
有的特征对数据集划分后并没有什么作用,比如一个数据集有两个类,本来类1和类2的比例是1比1,经过一个特征划分后每个子数据集中类别的比例还是1比1,分了等于没分,并没有减少类地不确定性
决策树学习的算法通常就是一个递归地选择最优特征,并根据该特征对数据集进行分割,使得对各个数据子集有一个最好的分类的过程
这一过程对应着特征空间的划分,也对应着决策树的构建
-
开始时,构建根节点,将所有训练集都放在根节点
-
选择一个最优特征,按照这一特征将训练数据集分割成子集
-
如果这些子集已经能够被基本正确分类,则构建叶结点,将这些子集分到对应的叶节点(选择条件概率大的作为叶节点类别)
-
如果还有子集不能被基本正确分类,那么对这些子集选择新的最优特征,接续分割
-
递归进行下去,直至所有的训练子集被基本正确分类或者没有合适的特征为止
例子
现在来看看下面这颗决策树是怎么生成的
这里暂时忽略判断最优特征的过程
首先构建一个根节点,将整个数据集 D D D放在根节点

根据是否有房子,将数据集分为两个子集 D 1 D_1 D1、 D 2 D_2 D2
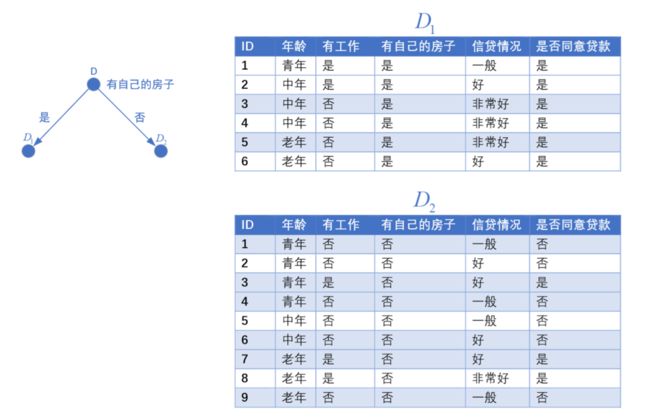
由于子数据集 D 1 D_1 D1,全部是同意贷款,则同意贷款的条件概率为1,将 D 1 D_1 D1数据集所在结点变为叶子结点并将其类别标记为同意贷款
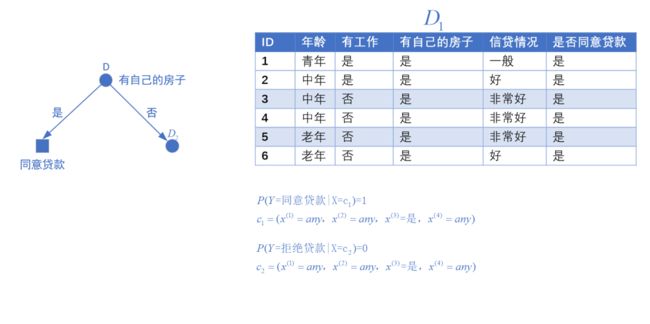
对于子数据集 D 2 D_2 D2,其同意贷款的条件概率为 3 9 \frac{3}{9} 93,拒绝贷款的调价概率为 6 9 \frac{6}{9} 96
可选取一个其他特征对其继续进行切分
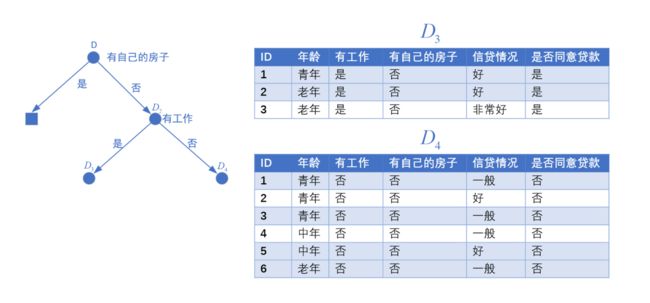
最终两边的两个子数据集 D 3 D_3 D3和 D 4 D_4 D4不用再划分,生成叶节点,得到最后的决策树
但是通过分类过程我们可以发现,我们使劲划分,使每次叶节点计算条件概率的时候分到的类的条件概率都是1,所以实际上这个模型是过拟合的(跟数据也有关系)
问题
上述算法也引出了几个问题
- 每次划分时怎么选取最优特征
- 我们递归生成决策树的时候,直到不能进行下去才停止,这存在一个过拟合问题,从而导致决策树的泛化能力(对未知数据的分类能力)很差,我们该怎样对决策树进行剪枝
这两个问题是接下来要探讨的主要内容
特征选择
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树的学习效率
选择不同特征生成的决策树并不同
有些特征分类后对决策树学习的精度并没有什么影响
比如对上述数据集选取年龄进行分类,观察每个子数据集的类别可以发现这样划分一次后青年和中年的中每个类别的条件概率相近,仍不能很好地分类,都还得继续找特征划分,最后得到的决策树会比较复杂,所以可猜测年龄并不是一个最优特征

若通过划分后子每个子数据集中类别不确定性比较小(条件概率差别大),那就可以认为这个特征是具有比较好的分类能力的
而不确定性让我们想到了一个东西:熵
熵
在信息论与概率论中,熵用来表示随机变量的不确定性
我们可以用熵判断一个数据集\子数据集中类别的不确定性
设 X X X是一个取有限个值的离散随机变量,其概率分布为(注意这个 X X X只是一个随机变量,不特指数据集中的向量)
P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X=x_i)=p_i,\ \ \ i=1,2,...,n P(X=xi)=pi, i=1,2,...,n
则随机变量 X X X的熵定义如下。由于 log 0 \log{0} log0是无定义的,所以在熵中规定 log 0 = 0 \log0=0 log0=0
H ( X ) = − ∑ i = 1 n p i log p i H(X)=-\sum_{i=1}^{n}p_i\log{p_i} H(X)=−i=1∑npilogpi
通常log都以2或者 e e e为底数。可以发现熵与 X X X的取值无关,只跟其分布(也就是 X X X每个取值的概率 p p p)有关,于是也可以将 X X X的熵记作 H ( p ) H(p) H(p)
H ( p ) = − ∑ i = 1 n p i log p i H(p)=-\sum_{i=1}^{n}p_i\log{p_i} H(p)=−i=1∑npilogpi
当某个 p i = 1 p_i=1 pi=1时, H ( p ) H(p) H(p)的值最小为0
可以求导证明在每个 p i = 1 n p_i=\frac{1}{n} pi=n1时, H ( p ) H(p) H(p)是取得最大值的,也就是 X X X的分布最均匀,最不确定的时候熵最大为 l o g n logn logn,所以熵的取值范围为
0 < = H ( p ) < = log n 0<=H(p)<=\log{n} 0<=H(p)<=logn
例子
当随机变量只取两个值,如1,0时, X X X的分布为
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p , 0 < = p < = 1 P(X=1)=p,\ P(X=0)=1-p,\ 0<=p<=1 P(X=1)=p, P(X=0)=1−p, 0<=p<=1
则熵为
H ( p ) = − p l o g 2 p − ( 1 − p ) l o g 2 ( 1 − p ) H(p)= -plog_2p-(1-p)log_2(1-p) H(p)=−plog2p−(1−p)log2(1−p)
这时,熵 H ( p ) H(p) H(p)随概率 p p p变化的曲线如图。当每个概率取 1 n = 0.5 \frac{1}{n}=0.5 n1=0.5时, H ( p ) H(p) H(p)最大,随机变量不确定性最大;当 p = 0 p=0 p=0或者 p = 1 p=1 p=1时, H ( p ) = 0 H(p)=0 H(p)=0,随机变量完全没有不确定性

条件熵
条件熵使用到的是条件概率分布
设有随机变量 ( X , Y ) (X,Y) (X,Y),其联合概率分布为
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , . . . n ; j = 1 , 2 , . . . , m P(X=x_i,Y=y_j)=p_{ij},\ i=1,2,...n;\ j=1,2,...,m P(X=xi,Y=yj)=pij, i=1,2,...n; j=1,2,...,m
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性
我们对给定 X = x i X=x_i X=xi条件下 Y Y Y的熵加权求和(也就是对 X X X求期望),就得到了条件熵
H ( Y ∣ X ) = ∑ i = 1 n P ( X = x i ) H ( Y ∣ X = x i ) , i = 1 , 2 , . . . n H(Y|X)=\sum_{i=1}^{n}P(X=x_i)H(Y|X=x_i),\ i=1,2,...n H(Y∣X)=i=1∑nP(X=xi)H(Y∣X=xi), i=1,2,...n
经验熵和经验条件熵
当熵和条件熵中的概率由数据估计出来,那么所对应的熵好条件熵分别成为经验熵和经验条件熵
信息增益
信息增益表示的是得知特征 X X X的信息而使得类 Y Y Y的信息的不确定性减少的程度
设特征A对训练数据集 D D D的信息增益为 g ( D , A ) g(D,A) g(D,A),则其定义为**数据集 D D D的经验熵 H ( D ) H(D) H(D)与特征 A A A给定的条件下D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)**之差
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
给定一个训练数据集 D D D和某个特征 A A A
- 经验熵 H ( D ) H(D) H(D)表示对数据集 D D D进行分类的不确定性
- 条件经验熵H(D|A)表示在特征A给定的条件下对数据 D D D进行分类的不确定性
- 他们的差,即信息增益,就表示由于得知特征 A A A而使得对数据集 D D D的分类不确定性减少的程度
- 信息增益大的特征具有更强的分类能力,我们每次选取信息增益大的特征当作最优特征对数据集进行划分即可
数据集信息增益算法
首先对数据集规定一些变量名称
-
设训练数据集为 D D D, ∣ D ∣ |D| ∣D∣表示样本容量,即样本个数
-
设有 K K K个类 C k C_k Ck, k = 1 , 2 , . . . K k=1,2,...K k=1,2,...K, ∣ C k ∣ |C_k| ∣Ck∣为属于类 C k C_k Ck的样本个数, ∑ k = 1 K ∣ C k ∣ = ∣ D ∣ \sum_{k=1}^K|C_k|=|D| ∑k=1K∣Ck∣=∣D∣
-
设某个特征 A A A有 n n n个不同的取值 { a 1 , a 2 , . . . a n } \{a_1,a_2,...a_n\} {a1,a2,...an},根据特征 A A A的取值将 D D D划分为 n n n个子集 D 1 , D 2 , . . . D n D_1,D_2,...D_n D1,D2,...Dn, ∣ D i ∣ |D_i| ∣Di∣表示 D i D_i Di的样本个数, ∑ i = 1 n ∣ D i ∣ = ∣ D ∣ \sum_{i=1}^n|D_i|=|D| ∑i=1n∣Di∣=∣D∣
-
记子集 D i D_i Di中属于类 C k C_k Ck的样本的集合为 D i k D_{ik} Dik, ∣ D i k ∣ |D_{ik}| ∣Dik∣为 D i k D_{ik} Dik的样本个数
则信息增益算法如下
-
输入:训练数据集 D D D和特征 A A A
-
输出:特征 A A A对训练数据集 D D D的信息增益 g ( D , A ) g(D,A) g(D,A)
-
过程:
-
计算数据集D的经验熵 D ( D ) D(D) D(D)
H ( D ) = − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ log 2 ∣ C k ∣ ∣ D ∣ H(D) = -\sum_{k=1}^K\frac{|C_k|}{|D|}\log_2{\frac{|C_k|}{|D|}} H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣ -
计算特征 A A A对数据集 D D D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)
H ( D ∣ A ) = ∑ i = 1 n ∣ D i ∣ ∣ D ∣ H ( D i ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ ∑ k = 1 K ∣ D i k ∣ ∣ D i ∣ log 2 ∣ D i k ∣ ∣ D i ∣ H(D|A)=\sum_{i=1}^{n}\frac{|D_i|}{|D|}H(D_i)=-\sum_{i=1}^{n}\frac{|D_i|}{|D|}\sum_{k=1}^K\frac{|D_{ik}|}{|D_i|}\log_2{\frac{|D_{ik}|}{|D_i|}} H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)=−i=1∑n∣D∣∣Di∣k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣ -
计算信息增益
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
-
特征选择例子
结合之前贷款的数据,看一下如何用信息增益求出最优特征,分别以 A 1 , A 2 , A 3 , A 4 A_1,A_2,A_3,A_4 A1,A2,A3,A4表示年龄、有工作、有自己的房子和信贷情况
首先计算经验熵 H ( D ) H(D) H(D)

对特征 A 1 A_1 A1:年龄,计算信息增益
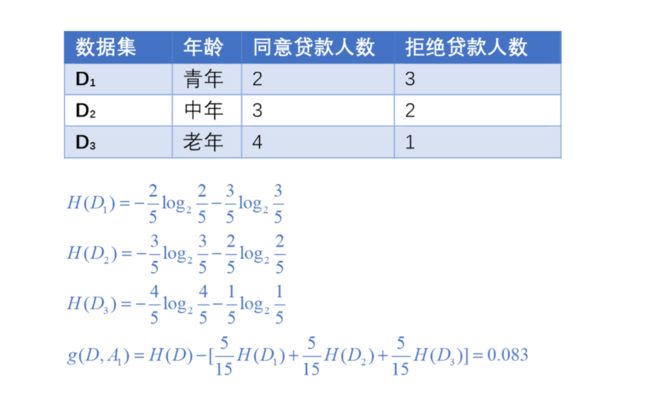
对其他特征同样计算信息增益,最终
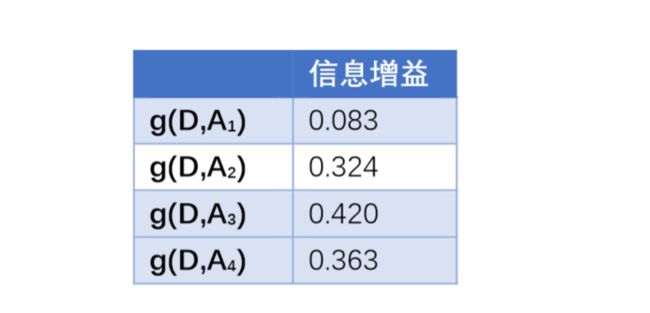
所以最终选择是否有自己的房子作为第一个划分特征
在对子数据集再划分的时候,信息增益需要重新计算,因为数据变了
信息增益比
信息增益的表示的是得知特征 X X X的信息而使得类 Y Y Y的信息的不确定性减少的程度
但信息增益的大小会受特征取值的影响,某个特征的可能的取值越多,每个子数据集划分到的数据越少,其每个子集中类 Y Y Y不确定性可能会越小,此时数据集被划分后总体类 Y Y Y的不确定性会减少,所以此时该特征信息增益越大。
也就是 g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)中的 H ( D ∣ A ) H(D|A) H(D∣A)会偏小
使用信息增益选择特征会偏向于选择特征取值比较多的特征
上面数据集没体现出来这一点
虽然特征取值比较多确实能使类 Y Y Y的不确定性更少,但是有时这并不是一个好的划分特征,只是因为该特征取值太多以至于每个子数据集样本太少从而使类 Y Y Y的不确定性减少
比如把身份证号当作一个人的特征,这时候每个子数据集只有一个数据(一人只有一个身份证号),训练集中其类别(是否同意贷款)被完全确定,信息增益最大
但身份证号并不是一个判断能否贷款的特征
所以我们要消除特征取值范围对我们的影响,给信息增益加一个惩罚项,使用信息增益除以这个惩罚项,当某特征取值比较多的时候,这个惩罚项会变大,从而抵消特征取值范围大小的影响。
这个惩罚项可以是数据集 D D D对某特征 A A A的经验熵 H A ( D ) H_A(D) HA(D),特征取值越不确定(越多),这个经验熵越大。
之前经验熵 H ( D ) H(D) H(D)其实是数据集对类 Y Y Y经验熵 H Y ( D ) H_Y(D) HY(D)的简写
于是我们得到了信息增益比
g R ( D , A ) = g ( D , A ) H A ( D ) g_{R}(D,A)=\frac{g(D,A)}{H_A(D)} gR(D,A)=HA(D)g(D,A)
H A ( D ) H_A(D) HA(D)计算
设当前数据集为 D D D,特征 A A A有 n n n个不同的取值 { a 1 , a 2 , . . . a , n } \{a_1,a_2,...a,_n\} {a1,a2,...a,n},其中 ∣ a i ∣ |a_i| ∣ai∣表示在当前数据集 D D D中,特征 A A A为 a i a_i ai的样本个数,则数据集 D D D对特征 A A A的经验熵 H A ( D ) H_A(D) HA(D)如下
H A ( D ) = − ∑ i = 1 n ∣ a i ∣ ∣ D ∣ l o g 2 ∣ a i ∣ ∣ D ∣ H_A(D)=-\sum_{i=1}^n\frac{|a_i|}{|D|}log_2\frac{|a_i|}{|D|} HA(D)=−i=1∑n∣D∣∣ai∣log2∣D∣∣ai∣

并不是说有了信息增益比就不能用信息增益
这两个都可以作为特征选择条件
具体怎么选得看具体算法采用的是什么
决策树生成算法
这里介绍两个决策树生成的经典算法, I D 3 ID3 ID3和 C 4.5 C4.5 C4.5
在理解了前面的内容之后这两个算法其实就变得非常简单了
ID3算法
算法描述
ID3算法核心是各个结点上应用信息增益准则选择特征,递归构建决策树
从根节点开始,对结点计算所有可选特征的信息增益,选择信息增益最大的特征作为结点的划分特征,由该特征的不同取值建立子节点
递归调用以上方法,直到所有特征的信息增益均很小或者没有特征可以选
具体实现
-
输入:训练数据集D,特征集A,阈值 ε \varepsilon ε
-
输出:决策树 \ 子树 T T T
-
过程
-
若D中所有实例属于同一类 C k C_k Ck,则T为单节点树,将 C k C_k Ck作为该结点的标记,返回 T T T
-
若 A = ∅ A=\varnothing A=∅,则 T T T为单节点树,将 D D D中实例数最大的类 C k C_k Ck作为该结点的标记类,返回 T T T
-
否则,计算A中各特征值对 D D D的信息增益,选择信息增益最大的特征 A g A_g Ag
-
如果 A g A_g Ag的信息增益小于阈值 ε \varepsilon ε,则 T T T为单节点树,将 D D D中实例数最大的类 C k C_k Ck作为该结点的标记类,返回 T T T
划分的收益太小,不如不分
-
否则对 A g A_g Ag的每一可能值 a i a_i ai,依据 A g = a i A_g=a_i Ag=ai,将 D D D分割正若干非空子集 D i D_i Di,构建子结点并由子节点生成决策子树 T i T_i Ti。由该结点与其子结点构建出来的决策子树 T i T_i Ti组成 T T T返回
对于第 i i i个子结点,以 D i D_i Di为训练集,以 A − { A g } A-\{A_g\} A−{Ag}为特征集,递归调用 1 − 5 1-5 1−5,从而构建决策子树 T i T_i Ti
-
C 4.5 C4.5 C4.5算法
C 4.5 算 法 C4.5算法 C4.5算法与 I D 3 ID3 ID3唯一不同的就是在选择最优特征的时候使用信息增益比作为准则
决策树的剪枝
为何要剪枝
决策树生成算法递归生成决策树,直到不能继续下去,这样的决策树拟合能力可以,但是泛化能力不行,出现过拟合的情况
过拟合容易被噪音影响
过拟合的原因在于学习时过多考虑如何提高对训练数据的正确分类,从而构建出过于复杂(结点太多)的决策树
在决策树学习中将决策树进行简化的过程叫做剪枝,其中分为前剪枝和后剪枝
前剪枝
在决策树生成之前对决策树进行简化叫做前剪枝,具体做法就是在适当的时候停止对数据集进行划分
I D 3 ID3 ID3算法和 C 4.5 C4.5 C4.5算法中的阈值 ε \varepsilon ε就是前剪枝的过程
还有许多在决策树生成之前剪枝的方式,在此不提
后剪枝
在决策树学习中将已生成的树进行简化的过程叫做后剪枝,后剪枝种类也很多
这里介绍一种基于代价复杂度损失函数的剪枝算法
后剪枝的具体方法是从已经已生成的树上剪掉一些子树或叶结点,并将其根节点或者父节点结合作为一个新的叶结点,从而简化分类树模型
如下面这个就是一个后剪枝
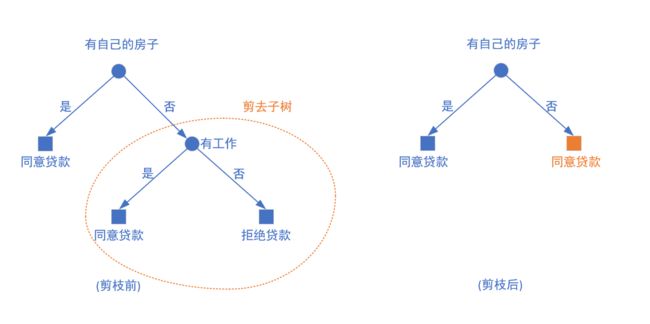
具体算法
决策树的剪枝往往通过极小化决策树整体的损失函数或代价函数来实现
损失函数
设
-
树 T T T的叶节点个数为 ∣ T ∣ |T| ∣T∣
-
t t t是树 T T T的叶节点,该叶结点上有 N t N_t Nt个样本点,其中 k k k类的样本点有 N t k N_{tk} Ntk个, k = 1 , 2 , . . . K k=1,2,...K k=1,2,...K
-
H t ( T ) H_t(T) Ht(T)为结点 t t t上的经验熵
-
α > = 0 \alpha{>=0} α>=0是一个参数
损失肯定跟训练集的预测误差(拟合程度有关)有关。其中训练集的预测误差可以用每个叶节点的经验熵表示如下,当各个结点的熵越小时,说明拟预测误差越小,拟合得越好
C ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) = − ∑ t = 1 ∣ T ∣ ∑ k = 1 K N t k log N t k N t C(T)=\sum_{t=1}^{|T|}N_tH_t(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk}\log\frac{N_{tk}}{N_t} C(T)=t=1∑∣T∣NtHt(T)=−t=1∑∣T∣k=1∑KNtklogNtNtk
如果直接用 C ( T ) C(T) C(T)作为损失函数,那么拟合程度越好则损失函数越小,这样在追求损失函数最小时肯定会出现过拟合的现象,所以需要有另一项随着拟合程度越好而越大的项对损失函数进行惩罚从而平衡拟合与泛化
拟合程度越好,决策树越复杂,树 T T T的叶节点个数 ∣ T ∣ |T| ∣T∣越大,所以可以用 ∣ T ∣ |T| ∣T∣做惩罚项,再由参数 α \alpha α控制拟合程度与复杂度对损失函数的影响,则得到损失函数如下
C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha}(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣
由于我们的目的是损失函数 C α ( T ) C_{\alpha}(T) Cα(T)极小化,所以较大的 α \alpha α促使选择较简单的模型(树),较小的 α \alpha α促使选择比较复杂的模型(树), α = 0 \alpha=0 α=0意味着只考虑模型与训练数据集的拟合程度,不考虑模型的复杂度
当 α \alpha α确定时,需要选择损失函数最小的决策子树,子树越大,拟合越好,模型的复杂度越高;相反子树越小,模型的复杂度越小,但是拟合程度就会变差,所以上述损失函数表达了两者的平衡
算法过程
-
输入:整颗决策树树 T T T,参数 α \alpha α
-
输出:修剪后的树 T α T_{\alpha} Tα
-
过程
-
计算每个结点的经验熵
-
递归从树的叶节点向上回缩,对于某一组叶节点(同一父亲),设其回退(剪掉)之前整体树为 T A T_A TA,其回退(剪掉)之后整体树为 T B T_B TB
若
C α ( T A ) < = C α ( T B ) C_{\alpha}(T_A)<=C_{\alpha}(T_B) Cα(TA)<=Cα(TB)
则剪去这组叶节点,将其父节点变为新的叶节点 -
回到2,继续对其他叶节点剪,直到没有可剪的为止
-
CART算法
CART全称为(classification and regression tree),即分类回归树模型,其决策树模型可应用与分类也可应用于回归
分类: 离散
回归: 连续
该算法同样由特征选择、树的生成以及剪枝组成,但是与前面两个算法有一定的区别:
C A R T CART CART假设决策树是二叉树,其内部结点特征的取值为‘是’和‘否’,左边分支是取值为’是’的分支,右边分支是取值为‘否’的分支
这样的决策树等价于递归二分每个特征,将输入空间(特征空间)划分为有限个单元,在这些单元上确定预测的概率分布
之前是根据特征的取值对特征空间进行划分,与这里不同
如在贷款数据集中年龄有三个特征青年、中年、老年;前面的算法若选中了年龄的特征,则会将一个结点分成三个子结点;而在 C R A T CRAT CRAT中,可能会根据数据集中年龄是否为青年分成两个子结点,一个对应着青年数据集,另一个对应中年和老年的数据集
C A R T CART CART算法主要有两步
-
生成决策树:树要尽量大
-
剪枝:用验证数据集对已经生成的数进行剪枝
C A R T CART CART生成
C A R T CART CART可以生成回归树和分类树,为了便于衔接,这里先介绍分类树
分类树
首先还是最优特征选择的问题, C A R T CART CART不仅要面临特征选择的问题,还有着选择特征的最优切分点的问题,因为每次选择该特征中一个取值对该特征进行二分
与 I D 3 ID3 ID3使用信息增益不同, C A R T CART CART分类树生成算法使用基尼指数选择最优特征和决定该特征的最优切分点
基尼指数
分类问题中,假设有 K K K个类,样本点属于第 k k k类的概率为 p k p_k pk,则概率分布的基尼指数定义如下,其
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^{K}p_k(1-p_k)=1-\sum_{k=1}^{K}p_k^2 Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
则对于给定的样本集合D,其基尼指数如下。其中 C k C_k Ck是D中属于第 k k k类的样本子集, K K K是类的种数;
基尼指数 G i n i ( D ) Gini(D) Gini(D)表示集合 D D D的不确定性,由式子可以看出,数据集中的类越均匀,基尼指数越大,集合 D D D的类不确定性越大,和熵类似
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D)=1-\sum_{k=1}^{K}(\frac{|C_k|}{|D|})^2 Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
如果样本 D D D根据特征 A A A是否取某一个可能值 a a a而被分割成 D 1 D_1 D1和 D 2 D_2 D2两部分,则在特征A条件下,集合 D D D的基尼指数定义如下(加权求和),其表示经过 A = a A=a A=a分割后数据集 D D D的不确定性
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
算法描述
-
输入:训练数据集 D D D,停止计算的条件
-
输出: C A R T CART CART决策树
-
过程
-
对于训练数据集 D D D的每个特征 A A A,对其可能取得每个值 a a a,根据样本点对 A = a A=a A=a的测试为‘是’或‘否’将 D D D分割成 D 1 D_1 D1和 D 2 D_2 D2两部分,利用上述计算 A = a A=a A=a时的基尼指数 G i n i ( D , A ) Gini(D,A) Gini(D,A)
-
对于某个特征 A A A的每个分割 A = a A=a A=a,选出基尼指数最小的作为当前特征的最优切分点;
所有特征最优切分点分割下的基尼指数相比较,选出基尼指数最小的特征为最优特征;
以此得到最优特征以及最优切分点
-
生成子结点,通过最优特征的最优切分点将数据集 D D D分到两个子结点中
-
对两个子节点递归调用 1 , 2 , 3 1,2,3 1,2,3,直到满足停止条件
-
生成 C A R T CART CART决策树
-
这里的停止条件是结点中样本个数小于预定阈值或者样本集的基尼指数小于预定阈值或没有更多特征
一个特征仍是只能用来分割一次
例子
仍是上面贷款的数据集
首先经计算各特征的基尼指数,选择最优特征和最优切分点。分别以 A 1 , A 2 , A 3 , A 4 A_1,A_2,A_3,A_4 A1,A2,A3,A4表示年龄、有工作、有子集的房子和信贷情况四个特征
求特征 A 1 A_1 A1的基尼指数,发现按照青年或者老年二分基尼指数一样且最小,则其均可以作为特征 A 1 A_1 A1的切分点

计算其他特征的每个取值的基尼指数
一个特征 A A A只有两个取值 a a a的情况下每个取值的基尼指数是一样的

因为 G i n i ( D , A 3 = 是 有 子 集 的 房 子 ) = 0.27 Gini(D,A_3=是有子集的房子)=0.27 Gini(D,A3=是有子集的房子)=0.27最小,所以以是否有自己的房子为最优特征,任意一个取值作为切分点(因为只有两个取值)
数据集被划分为 D 1 D_1 D1, D 2 D_2 D2;这两个数据集继续在 A 1 , A 2 , A 4 A_1,A_2,A_4 A1,A2,A4中寻找最优特征和最优切分点进行划分
回归树
在回归树中,假设 X X X与 Y Y Y分别为输入和输出变量,并且 Y Y Y是连续变量,给定如下训练集,需要生成一个回归树,对于新的输入 X X X,需要预测输出 Y Y Y的值
D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) D={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)} D=(x1,y1),(x2,y2),...,(xN,yN)
与分类树不同,分类树中输出是离散的,这里的输出 Y Y Y是连续的,也就是其值落在某个区间
一个回归树对应着输入空间(特征空间)的一个划分以及在划分的单元上的输出值
跟分类树的条件概率分布类似
假设现在已经将输入空间划分为 M M M各单元 R 1 , R 2 , . . . , R M R_1,R_2,...,R_M R1,R2,...,RM,并且在每个单元上有一个固定的输出 c m c_m cm( c m c_m cm是根据分到这个单元上的 n n n个实例对应的输出 y 1 , . . . y n y_1,...y_n y1,...yn计算出来的,下面会讲到),于是回归树模型可以表示为
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f(x)=\sum_{m=1}^Mc_mI(x\in{R_m}) f(x)=m=1∑McmI(x∈Rm)
就是取 x x x被划分到的单元对应的输出值 c m c_m cm
c m c_m cm选取
当输入空间划分确定时,可以用平方误差表示回归树对训练数据的预测误差,用平方误差最小的准则求解每个单元上 R m R_m Rm的最优输出值
∑ x i ∈ R m ( y i − f ( x i ) ) 2 \sum_{x_i\in{R_m}}(y_i-f(x_i))^2 xi∈Rm∑(yi−f(xi))2
要使平方误差最小,则 f ( x i ) f(x_i) f(xi)应该取 y i y_i yi的均值
则单元 R m R_m Rm上的 c m c_m cm的最优值 c ^ m \hat{c}_m c^m是 R m R_m Rm上的所有输入实例 x i x_i xi对应的输出 y i y_i yi的均值
c ^ m = a v e ( y i ∣ x i ∈ R m ) \hat{c}_m=ave(y_i|x_i\in{R_m}) c^m=ave(yi∣xi∈Rm)
空间划分
与分类树空间划分类似,选择第 j j j个变量 x ( j ) x^{(j)} x(j)和它取的值 s s s作为切分变量和切分点,划分出两个区域
R 1 ( j , s ) = { x ∣ x j < = s } 和 R 2 ( j , s ) = { x ∣ x j > s } R_1(j,s)=\{x|x^{j}<=s\}\ 和 \ R_2(j,s)=\{x|x^{j}>s\} R1(j,s)={x∣xj<=s} 和 R2(j,s)={x∣xj>s}
对于划分的两个区域,分别以 c 1 c_1 c1、 c 2 c_2 c2代表其输出值,则每个切分点的最小误差为
m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 \underset{c_1}{min}\sum_{x_i\in{R_1(j,s)}}(y_i-c_1)^2+\underset{c_2}{min}\sum_{x_i\in{R_2(j,s)}}(y_i-c_2)^2 c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2
当其中 c 1 c_1 c1和 c 2 c_2 c2取以下值时能使上式最小
与每个单元误差最小时的输出类似
c ^ 1 = a v e ( y i ∣ x i ∈ R 1 ( j , s ) ) 和 c ^ 2 = a v e ( y i ∣ x i ∈ R 2 ( j , s ) ) \hat{c}_1=ave(y_i|x_i\in{R_1(j,s)}) \ 和\ \hat{c}_2=ave(y_i|x_i\in{R_2(j,s)}) c^1=ave(yi∣xi∈R1(j,s)) 和 c^2=ave(yi∣xi∈R2(j,s))
则对每个变量 j j j,每个切分点 s s s求切分后的误差最小值,即可得到最优切分变量 j j j和最优切分点 s s s
m i n j , s [ ∑ x i ∈ R 1 ( j , s ) ( y i − c ^ 1 ) 2 + ∑ x i ∈ R 2 ( j , s ) ( y i − c ^ 2 ) 2 ] \underset{j,s}{min}[\sum_{x_i\in{R_1(j,s)}}(y_i-\hat{c}_1)^2+\sum_{x_i\in{R_2(j,s)}}(y_i-\hat{c}_2)^2] j,smin[xi∈R1(j,s)∑(yi−c^1)2+xi∈R2(j,s)∑(yi−c^2)2]
得到切分点后对输入空间进行二分,对每个子结点重复上述过程,找到其他的最优切分变量和最优切分点继续对输入空间进行划分,直到满足停止条件
最后划分出每个单元,再对每个单元计算输出 c m c_m cm,得到一颗回归树
算法过程
-
输入:训练数据集 D D D
-
输出:回归树 f ( x ) f(x) f(x)
-
过程
-
首先选择最优切分变量 j j j与切分点 s s s,具体方法如下,就是扫描每个变量 j j j和每个变量 j j j的每个取值 s s s
m i n j , s [ ∑ x i ∈ R 1 ( j , s ) ( y i − c ^ 1 ) 2 + ∑ x i ∈ R 2 ( j , s ) ( y i − c ^ 2 ) 2 ] \underset{j,s}{min}[\sum_{x_i\in{R_1(j,s)}}(y_i-\hat{c}_1)^2+\sum_{x_i\in{R_2(j,s)}}(y_i-\hat{c}_2)^2] j,smin[xi∈R1(j,s)∑(yi−c^1)2+xi∈R2(j,s)∑(yi−c^2)2]c ^ 1 \hat{c}_1 c^1和 c ^ 2 \hat{c}_2 c^2如下
-
用选定的 ( j , s ) (j,s) (j,s)划分区域,并用 c ^ 1 \hat{c}_1 c^1和 c ^ 2 \hat{c}_2 c^2作为每个区域的输出值
$$
R_1(j,s)={x|x^{j}<=s}\ 和 \ R_2(j,s)={x|x^{j}>s}\\hat{c}m=\frac{1}{N_m}\sum{x_i\in{R_m(j,s)}}y_i,\ m=1,2
$$ -
继续对上面两个区域调用步骤 1 , 2 1,2 1,2划分
-
最后将输入空间划分为了 M M M个区域 R 1 , R 2 , . . . R M R_1,R_2,...R_M R1,R2,...RM,生成决策树
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f(x)=\sum_{m=1}^Mc_mI(x\in{R_m}) f(x)=m=1∑McmI(x∈Rm)
-
C A R T CART CART剪枝
C A R T CART CART用的后剪枝,也就是从“完全生长”的决策树从底端剪去一些子树,使决策树变得简单,使其对未知数据又更准确的预测
C A R T CART CART剪枝由两步构成
-
从生成的决策树 T 0 T_0 T0底端开始不断剪枝,直到 T 0 T_0 T0的根节点,形成一个子树序列 { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} {T0,T1,...,Tn}
这里的子树意义为:若树 T 1 T_1 T1由 T 0 T_0 T0剪枝叶得来,则 T 1 T_1 T1为 T 0 T_0 T0的子树, T 0 T_0 T0也为 T 0 T_0 T0的子树
-
然后通过交叉验证在独立的验证数据子集上对子树进行测试,从中选择最优子树
形成子树序列
在前面介绍过一个损失函数
C α ( T ) = C ( T ) + α ∣ T ∣ C_\alpha(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣
在 C A R T CART CART剪枝过程中,用这个损失函数进行剪枝判断。
但是与前面的减枝算法略有不同,因为此处的减枝包含着 α \alpha α的选取
其中 C ( T ) C(T) C(T)是对训练数据的预测误差, ∣ T ∣ |T| ∣T∣为树的叶节点个数, α > = 0 \alpha>=0 α>=0用来权衡训练数据的拟合程度与模型的复杂度:
- 当 α = 0 \alpha=0 α=0时,此时损失函数仅与拟合度有关,拟合得越好,损失函数越小,此时最好是不剪枝,对应着决策树 T 0 T_0 T0
- 当 α → ∞ \alpha\rightarrow\infty α→∞时,损失函数与决策树的复杂度 ∣ T ∣ |T| ∣T∣有很大关系,此时迫使 ∣ T ∣ |T| ∣T∣最小,即将决策树剪到单节点树,对应 T n T_n Tn
对于分类问题, C ( T ) C(T) C(T)使用基尼指数,对于回归问题 C ( T ) C(T) C(T)可采用平方误差的形式
在之介绍的后减枝算法中可知,对于固定的 α \alpha α,可以通过损失函数最小化原则,对决策树进行剪枝,找到一个且仅一个使 C α ( T ) C_\alpha(T) Cα(T)最小的子树(损失函数确定的情况下只能剪出一颗最优子树(应剪尽剪)),将其表示为 T α T_{\alpha} Tα,其在损失函数 C α ( T ) C_\alpha(T) Cα(T)下是最优的。
α \alpha α如此多种可能取值,如何生成不同 α \alpha α下产生的最优子树序列 { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} {T0,T1,...,Tn}供我们在最优子树序列中选择最优的呢?
B r e i m a n Breiman Breiman等人证明:可以用递归的方式进行剪枝。
将 α \alpha α从小增大 0 = α 0 < α 1 < . . . < α n < + ∞ 0=\alpha_0<\alpha_1<...<\alpha_n< +\infty 0=α0<α1<...<αn<+∞,产生一系列区间 [ α i , α i + 1 ) , i = 0 , 1 , . . . , n [\alpha_i,\alpha_{i+1}),i=0,1,...,n [αi,αi+1),i=0,1,...,n,每个区间对应着一颗子树(每个区间 [ α i , α i + 1 ) [\alpha_i,\alpha_{i+1}) [αi,αi+1)内 α \alpha α取任意值剪枝后得到的最优子树都是一样的,下面会说到有的结点 t t t需要 α \alpha α大到临界点 α i + 1 \alpha_{i+1} αi+1才能剪去)
则** α ∈ [ α i , α i + 1 ) , i = 0 , 1 , . . . n \alpha\in[\alpha_i,\alpha_{i+1}),i=0,1,...n α∈[αi,αi+1),i=0,1,...n**对应着 n + 1 n+1 n+1棵最优子树,即最优子树序列 { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} {T0,T1,...,Tn},序列中的子树是嵌套的( T 1 T_1 T1是对 T 0 T_0 T0剪枝得来, T 2 T_2 T2是 T 1 T_1 T1剪枝得来)
我们剪枝得到的子树序列也对应着 { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} {T0,T1,...,Tn}
比较小的 α \alpha α偏向于选择叶结点比较多的树,则从小的 α \alpha α开始剪,慢慢增大 α \alpha α,直到将树剪没,这样就把所有最优子树都考虑到了
T n T_n Tn即是最后因为 α \alpha α过大把所有结点剪去形成的单节点树

具体地:
从整体树 T 0 T_0 T0开始剪枝,对 T 0 T_0 T0的任意内部结点 t t t:
以 t t t为单节点树**(剪枝后)的损失函数(局部的)为
C α ( t ) = C ( t ) + α C_\alpha(t)=C(t)+\alpha Cα(t)=C(t)+α
以 t t t为根节点树的子树 T t T_t Tt(剪枝前)**的损失函数为
C α ( T t ) = C ( T t ) + α ∣ T t ∣ C_\alpha(T_t)=C(T_t)+\alpha|T_t| Cα(Tt)=C(Tt)+α∣Tt∣
当 α = 0 \alpha=0 α=0或 α \alpha α充分小的时候,可忽略复杂度 ∣ T t ∣ |T_t| ∣Tt∣的影响,此时不剪枝的损失小于剪枝后的损失(不剪枝时误差 C ( T t ) C(T_t) C(Tt)更小)
C α ( T t ) < C α ( t ) C_\alpha(T_t)
当 α \alpha α增大到某一 α \alpha α时,由于复杂度的权衡,剪枝前后的损失相等
C α ( T t ) = C α ( t ) C_\alpha(T_t)=C_\alpha(t) Cα(Tt)=Cα(t)
当 α \alpha α再增大,那么复杂度对损失函数的作用就会被放得很大,于是剪枝前损失比剪枝后大
C α ( T t ) > C α ( t ) C_\alpha(T_t)>C_\alpha(t) Cα(Tt)>Cα(t)
当 C α ( T t ) > C α ( t ) C_\alpha(T_t)>C_\alpha(t) Cα(Tt)>Cα(t),即 α > C ( t ) − C ( T t ) ∣ T t ∣ − 1 \alpha>\frac{C(t)-C(T_t)}{|T_t|-1} α>∣Tt∣−1C(t)−C(Tt)时,应该对该对结点剪枝,因为剪去后该结点对整体树贡献的损失会比剪去前少
当 C α ( T t ) = C α ( t ) C_\alpha(T_t)=C_\alpha(t) Cα(Tt)=Cα(t),即 α = C ( t ) − C ( T t ) ∣ T t ∣ − 1 \alpha=\frac{C(t)-C(T_t)}{|T_t|-1} α=∣Tt∣−1C(t)−C(Tt),也应该对该结点剪枝,因为此时是否剪去该节点对整体树贡献的损失一致,但是剪去能使复杂度变小,能使决策树更简单
根据上面的结论,有以下方法:
-
对于 T 0 T_0 T0中每一内部结点(非叶结点) t t t,计算
g ( t ) = C ( t ) − C ( T t ) ∣ T t ∣ − 1 g(t)=\frac{C(t)-C(T_t)}{|T_t|-1} g(t)=∣Tt∣−1C(t)−C(Tt) -
在 T 0 T_0 T0中剪去 g ( t ) g(t) g(t)最小的 T t T_t Tt,将得到的子树作为 T 1 T_1 T1,同时将最小的的 g ( t ) g(t) g(t)设为 α 1 \alpha_1 α1,此时 T 1 T_1 T1为区间 [ α 1 , α 2 ) [\alpha_1,\alpha_2) [α1,α2)的最优子树
α \alpha α从小开始慢慢增大,不漏掉子树
假如此时选择一个较大的 g ( t ) b i g g(t)_{big} g(t)big设为 α 1 \alpha_1 α1,那么不仅要将 g ( t ) = α 1 g(t)=\alpha_1 g(t)=α1的结点 t b i g t_{big} tbig剪去,还需要将 g ( t ) m i n g(t)_{min} g(t)min对应的结点 t m i n t_{min} tmin剪去,因为对于结点 t m i n t_{min} tmin有 α 1 > C ( t m i n ) − C ( T t m i n ) ∣ T t m i n ∣ − 1 \alpha_1>\frac{C(t_{min})-C(T_{t_{min}})}{|T_{t_{min}}|-1} α1>∣Ttmin∣−1C(tmin)−C(Ttmin),此时剪去该 t m i n t_{min} tmin比不剪更优
这时我们就漏掉了一棵在上一棵子树的基础上只剪去 t m i n t_{min} tmin而不减去 t b i g t_{big} tbig的子树,所以 α \alpha α应每次选最小的
-
在剪枝后的子树的基础上一直剪下去,直到根节点,在此过程中, α \alpha α不断增大,产生新区间,最终得到子树序列
{ T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} {T0,T1,...,Tn}
这里剪枝之后重新计算的 g ( t ) g(t) g(t)最小值应该可以证明比上一次 g ( t ) g(t) g(t)最小值大,这样 α \alpha α才会不断增大
交叉验证
在上面选取 α \alpha α的过程中,我们生成了子树序列 { T 0 , T 1 , . . . T n } \{T_0,T_1,...T_n\} {T0,T1,...Tn}
则可以利用验证数据集,测试上述各子树的平方误差或基尼指数,较小的被认为是最优的决策树
这里有点迷
选出最优子树 T k T_k Tk时,由于每颗子树 T 0 , T 1 , . . . T n T_0,T_1,...T_n T0,T1,...Tn都对应一个参数 α 0 , α 1 , . . . , α n \alpha_0,\alpha_1,...,\alpha_n α0,α1,...,αn,所以对应的 α k \alpha_k αk也确定了,便得到了最优决策树 T α T_\alpha Tα
虽然最优决策树 T k T_k Tk前面的子树剪枝时使用的 α \alpha α不是 α k \alpha_k αk,但是由于 α k \alpha_k αk比前面子树的 α \alpha α大,所以 α k \alpha_k αk也能把前面子树剪的枝剪掉,所以可以认为整体 T k T_k Tk是 α k \alpha_k αk对应的子树
具体算法
-
输入: C A R T CART CART算法生成的决策树 T 0 T_0 T0
-
最优决策树 T α T_\alpha Tα
-
过程
-
设 k = 0 k=0 k=0, T = T 0 T=T_0 T=T0
-
设 α = + ∞ \alpha=+\infty α=+∞
-
自下而上地对各内部结点 t t t计算 C ( T t ) C(T_t) C(Tt), ∣ T t ∣ |T_t| ∣Tt∣以及
g ( t ) = C ( t ) − C ( T t ) ∣ T t ∣ − 1 α = m i n ( α , g ( t ) ) g(t)=\frac{C(t)-C(T_t)}{|T_t|-1}\\ \alpha=min(\alpha,g(t)) g(t)=∣Tt∣−1C(t)−C(Tt)α=min(α,g(t))T t T_t Tt表示 t t t为根节点的子树
C ( T t ) C(T_t) C(Tt)是对训练数据的预测误差(针对 T t T_t Tt而言),分类树用基尼指数,回归树可用平方误差
∣ T t ∣ |T_t| ∣Tt∣是 T t T_t Tt的叶节点个数
-
自上而下访问内部结点 t t t,如果有 g ( t ) = α g(t)=\alpha g(t)=α,进行剪枝,并对叶结点 t t t以多数表决法得到其类,得到剪枝后的树 T T T
-
设 k = k + 1 k=k+1 k=k+1, α k = α \alpha_k=\alpha αk=α, T k = T T_k=T Tk=T
因为 T 0 T_0 T0被原本的整树用了,所以这里先 + 1 +1 +1
-
如果 T T T不是单节点构成的树,回到步骤 3 3 3
-
采用交叉验证法在子树序列 T 0 , T 1 , . . . T n T_0,T_1,...T_n T0,T1,...Tn选取最优子树 T α T_\alpha Tα
-
python实现
-
没有实现后剪枝,简单用基尼指数阈值剪枝
-
每个结点的用字典表示,其结构如下
{ 'split_feat':,# 切分特征 (非叶节点存在) 'split_value':,# 切分特征值 (非叶节点存在) 'left':{}, # 左子树 (非叶节点存在) 'right':{}, # 右子树 (非叶节点存在) 'label':, # 类别 (所有结点均存在) 'is_leaf':True, # 叶节点标识,仅叶结点存在 } -
无调参过程
-
数据在Github(https://github.com/coding-cadenza/MachineLearning))
-
下面主要用西瓜数据集做,课本里面的数据集太弱了
-
代码简单,仅供参考
import math
import random
import numpy as np
import pandas as pd
from graphviz import Digraph
'''
结点结构
{
'split_feat':,# 切分特征 (非叶节点存在)
'split_value':,# 切分特征值 (非叶节点存在)
'left':{}, # 左子树 (非叶节点存在)
'right':{}, # 右子树 (非叶节点存在)
'label':, # 类别 (所有结点均存在)
'is_leaf':True, # 叶节点标识,仅叶结点存在
}
'''
class CART:
def __init__(self, values, labels, features):
self.values = values
self.labels = list(labels)
self.unique_labels = list(set(labels))
self.features = list(features)
self.gini_threshold = 0.7 # 基尼指数阈值
self.root = self.create_tree(self.values, self.labels, self.features.copy())
'''
创建决策树
:param value: 训练实例
:param labels: 实例对应的类别
:param features: 实例特征对应名称
'''
def create_tree(self, values, labels, features):
# 数据类别相同,直接返回该类别
if len(set(labels)) == 1:
return {'label': labels[0],'is_leaf':True}
# 特征已用完时,不能再分,返回最多的类别
if len(features) == 0:
return {'label': max(labels, key=labels.count),'is_leaf':True}
# 选择最优特征以及最优特征的最优特征值
best_feat, best_feat_val = self.choose_best_feat(values, labels)
# 选不出最优特征时返回(在选最优特征的时候可以剪枝,或者每个特征都只有一种取值了也是选不出来的)
if best_feat == -1:
return {'label': max(labels, key=labels.count),'is_leaf':True}
best_feat_name = features[best_feat]
# 创建根节点,以最优特征为键名,其孩子为键值(嵌套)
root = {'split_feat': best_feat_name, 'split_value': best_feat_val,'label': max(labels, key=labels.count)}
# 二分数据集,递归创建决策树
del features[best_feat] # 删去已选特征
values_equal, labels_equal, values_unequal, labels_unequal = self.split_data(values, labels, best_feat,
best_feat_val) # 二分数据集
features_copy = [feature for feature in features] # 引用冲突解除
# 创建左右子树
root['left'] = self.create_tree(values_equal, labels_equal, features)
root['right'] = self.create_tree(values_unequal, labels_unequal, features_copy)
return root
'''
选出最优特征以及最优切分点的值
:param values: 实例
:param labels: 类别
'''
def choose_best_feat(self, values, labels):
best_feat = -1
best_feat_val = ''
exam_num = float(len(values))
if len(values) == 0:
return best_feat, best_feat_val
feat_num = len(values[0]) # 特征数量
min_gini = self.gini_threshold # 最小的基尼指数,初始化为最大值
# 遍历每个特征
for i in range(feat_num):
unique_feat_vals = set([value[i] for value in values]) # 该特征所有特征取值
if len(unique_feat_vals) == 1:
continue
# 统计该特征每个特征值划分后的基尼指数
for val in unique_feat_vals:
# 按val二分数据集
values_equal, labels_equal, values_unequal, labels_unequal = self.split_data(values, labels, i,
val)
# 每个数据集计算基尼指数
gini_R1 = self.cal_gini(values_equal, labels_equal)
gini_R2 = self.cal_gini(values_unequal, labels_unequal)
# 加权求和
gini = len(values_equal) / exam_num * gini_R1 + len(values_unequal) / exam_num * gini_R2
if gini < min_gini:
min_gini = gini
best_feat = i
best_feat_val = val
return best_feat, best_feat_val
'''
将数据集按某特征值切分成两个子集,并返回去掉该特征的两个子集
:param values: 实例
:param labels: 类别
:param axis: 切分的特征(维度)
:param axis_val: 切分的特征值
:returns values_equal,labels_equal,values_unequal,labels_unequal: 切分并去掉切分特征后的实例、类别
'''
def split_data(self, values, labels, axis, axis_val):
values_equal = []
labels_equal = []
values_unequal = []
labels_unequal = []
exam_num = len(values)
for i in range(exam_num):
val_vec = list(values[i]) # 特征向量
# 去掉切分特征的向量
sub_val = val_vec[:axis]
sub_val.extend(val_vec[axis + 1:]) # 去掉切分特征
if val_vec[axis] == axis_val:
values_equal.append(sub_val)
labels_equal.append(labels[i])
else:
values_unequal.append(sub_val)
labels_unequal.append(labels[i])
return values_equal, labels_equal, values_unequal, labels_unequal
'''
计算基尼指数
:param values
:param labels
:return gini: 基尼指数
'''
def cal_gini(self, values, labels):
exam_num = float(len(values))
gini = 1.0
# 统计每个类别的个数
label_count = {}
for label in labels:
if label not in label_count.keys():
label_count[label] = 0
label_count[label] += 1
for key in label_count.keys():
gini -= math.pow((label_count[key] / exam_num), 2)
return gini
'''
决策树预测
:param values: 需要预测的实例集合
:return labels: 预测结果集合
'''
def predict(self,values):
values = list(values)
labels = []
for value in values:
labels.append(self.tree_search(value,self.root))
return labels
'''
决策树搜索
:param value: 搜索实例
:param node: 当前搜索到的结点
'''
def tree_search(self,value,node):
if 'is_leaf' in node.keys():
return node['label']
else:
feat_index = self.features.index(node['split_feat'])
if value[feat_index] == node['split_value']:
return self.tree_search(value,node['left'])
else:
return self.tree_search(value, node['right'])
'''
决策树可视化入口
:param filename: 输出文件的位置以及名字
'''
def tree_visualization(self,filename='file'):
dot = Digraph(format='png')
self.tree_visualization_core(self.root,dot)
dot.render(filename=filename)
'''
决策树可视化核心代码
使用每个字典的地址作为结点名字保证结点的唯一性
:param node: 当前结点
:param dot : 传递Digraph对象,创建结点用
'''
def tree_visualization_core(self, node,dot):
if 'is_leaf' in node.keys(): # 单节点树
dot.node(name=str(id(node)), label='类别: ' + node['label'], fontname="Microsoft YaHei", shape='square',color = '#00BFFF')
else:
dot.node(name=str(id(node)), label='切分特征: ' + node['split_feat'] + '\n切分值: ' + node['split_value'],
fontname="Microsoft YaHei", shape='square',color = '#00BFFF')
# 左边
self.tree_visualization_core(node['left'],dot)
dot.edge(str(id(node)), str(id(node['left'])), 'yes')
# 右边
self.tree_visualization_core(node['right'], dot)
dot.edge(str(id(node)), str(id(node['right'])), 'no')
if __name__ == '__main__':
# 测试西瓜数据
input_filename = './data/watermelon.csv'
output_filename = './TreePng/watermelon'
df = pd.DataFrame(pd.read_csv(input_filename, encoding='utf-8'))
features = df.columns[:-1].values
data = df.values
values = data[:, :-1]
labels = data[:, -1]
'''交叉验证,70%训练集,30%测试集'''
# 随机特征向量分成两组
# 先将下标切分,后面方便将特征向量和标签切分
train_index = list(range(len(values)))
test_index = []
test_len = int(len(values) * .3) # 需要测试集的大小
for i in range(test_len):
rand = int(random.uniform(0, len(train_index)))
test_index.append(train_index[rand])
del train_index[rand] # 将训练移入测试集的下标从训练下标删除
train_values = values[train_index]
train_labels = labels[train_index]
test_values = values[test_index]
test_labels = labels[test_index]
# 训练决策树并画图
cart = CART(train_values, train_labels, features)
cart.tree_visualization(output_filename)
# 计算结果
correct_rate = 0.0
correct_num = 0
res_labels = cart.predict(test_values)
for i in range(test_len):
if test_labels[i] == res_labels[i]:
correct_num += 1
correct_rate = correct_num * 1.0 / test_len
print('西瓜分类准确率为:{}', correct_rate)
结果
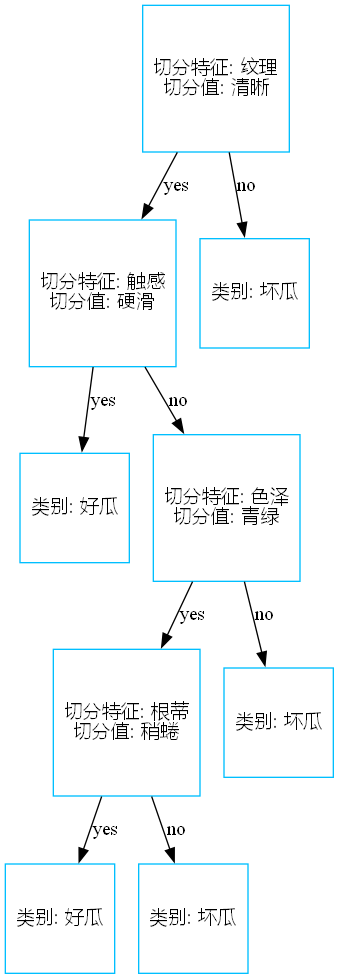
西瓜分类分类准确率为:{} 0.8
Process finished with exit code 0