超越传统微调!Meta新作VPT:视觉Prompt来了!冻结主干,仅调节1%参数,性能提升显著!...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
丰色 发自 凹非寺
转载自:量子位(QbitAI)
Prompt tuning,作为NLP领域中的一个“新宠”,甚至曾被学者誉为NLP预训练新范式。
那么,它能否借鉴到CV领域并产生同样的成绩呢?
现在,来自康奈尔大学和Meta AI等机构,通过Prompt来调整基于Transformer的视觉模型,结果发现:
完全可以!

Visual Prompt Tuning
论文:https://arxiv.org/abs/2203.12119
比起全面微调,Prompt性能提升显著。无论模型的规模和训练数据怎么变,24种情况中有20种都完全胜出。

与此同时,它还能大幅降低每项任务所需的存储成本。

只使用不到1%的模型参数
大家一贯使用的全面微调(full fine-tuning),需要为每个下游任务存储和部署单独的主干参数副本,成本太高,尤其是现在基于Transformer的模型越来越大,已经超过CNN架构。
所谓Prompt,最初指的是在输入文本中预编语言指令,以便预培训的语言模型后续可以直接理解各种下游任务。
它曾让GPT-3即使在少样本或零样本的情况下表现出很强的泛化能力。
最近一些成果则表明,Prompt与完全微调的性能相当,参数存储量还减少了1000倍。
NLP中的高超性能让不少人开始在CV领域中探索Prompt的魔力,不过都只局限于跨模态任务中文本编码器的输入。
在本文中,作者将他们所提出的Visual Prompt Tuning方法,简称为VPT。这是首次有人将Prompt应用到视觉模型主干(backbone),并做出成果。
具体来说,比起全面微调,VPT受最新大型NLP模型调整方法的启发,只在输入空间中引入少量可特定某任务训练的参数(不到模型参数的1%),同时在训练下游任务期间冻结(freeze)预训练模型的主干。
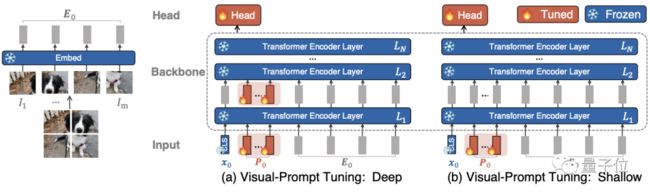
在实操中,这些附加参数只用预先加入到每个Transformer层的输入序列中,并在微调期间与线性head一起学习。
他们一共探索出两种变体:
VPT-Deep变体为Transformer编码器每层的输入预先设置一组可学习的参数;
VPT-Shallow变体则仅将提示参数插入第一层的输入。
两者在下游任务的训练过程中,只有特定于任务的提示和线性头的参数会更新,而整个Transformer编码器被冻结。
接下来,是骡子是马?拉出来溜溜~
20/24的优胜率
实验涉及两种在ImageNet-21k上预训练好的主干,一个来自Vision Transformer,一个来自Swin Transformer。
进行对比的微调方法有三大种,7小种,包括:
(1)完全微调:更新所有主干和分类头(classification head)参数
(2)以分类头为重点的微调,包括Linear、Partial-k和Mlp-k三种;
(3)以及在微调过程中更新一个主干子集参数或向主干添加新的可训练参数的方法,分为Sidetune、Bias和Adapter三种。

实验的数据集有两组,一共涉及24个跨不同领域的下游识别任务,包括:
(1)由5个基准细粒度视觉分类任务组成的FGVC;
(2)由19个不同视觉分类集合组成的VTAB-1k,细分为使用标准相机拍摄的自然图像任务(Natural)、用专用设备(如卫星图像)捕获的图像任务(Specialized)以及需要几何理解的任务(Structured),比如物体计数。
测得每项任务上的平均准确度后,得出的主要结果如下:
VPT-Deep在24个任务中有20个的表现都优于全面微调,同时使用的总模型参数显著减少(1.18× vs. 24.02×);
要知道,在NLP领域中Prompt再厉害,性能也不会超过全面微调。这说明Prompt很适用于视觉Transformer模型。
和其他微调方法相比(b、c组),VPT-Deep的性能则全部胜出。

此外,选择不同主干参数规模和模型规模的ViT(ViT-B、ViT-L和ViT-H)进行测试还发现,VPT方法不会受影响,依然基本保持性能领先。
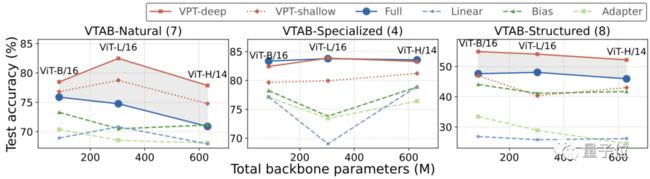
而在Swin Transformer中,全面微调法的平均准确度虽然更高,但也付出了巨大的参数代价。
其他微调方法则全部不敌VPT。

作者介绍
一作贾梦霖,康奈尔大学信息科学(Information Science)博士生,主要研究方向为视觉和文本信息的细粒度识别,截至目前共发表过4篇顶会。

共同一作为唐路明,也是康奈尔大学的一位计算机博士在读学生,本科毕业于清华大学数学与物理专业。
他的主要研究方向为机器学习和计算机视觉的交叉领域。

VPT 论文下载
后台回复:VPT,即可下载上面论文ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!

▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看