Visual Prompt Tuning
参考文献:Jia, M., Tang, L., Chen, B. C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S. N. (2022). Visual prompt tuning. arXiv preprint arXiv:2203.12119.
pdf连接: https://arxiv.org/pdf/2203.12119.pdf
1.文章背景
对于大量的识别任务来说,最准确的结果是通过对在大量原始数据上预训练的大型基础模型进行调整获得的,然而在实际中,使这些大型的模型去适应下游任务有其自身的挑战。最有效的调整策略是使用端到端的方式对预训练的模型进行微调。但是这种策略需要很大的存储开销,对于每一个下游任务,需要存储一个单独的模型参数的副本。这种方法是不可行的,特别是对于哪些基于transformer的结构,比如ViT-H有6亿多的参数,ResNet-50有25M的参数。
一种流行的策略是微调参数的一个子集,例如classifier head或者是bias term。也有方法在模型的框架上添加额外的残差块。但是这些方法的性能都低于full fine-tuning。
受最近的在NLP领域的prompt技术的影响,本文提出新的有效的方法使得transformer模型适应下游任务,将其命名为VPT(Visual Prompt Tuning)。在下游任务训练期间,该方法会冻结预训练的transformer backbone,通过引入少量的特定于任务的可学习的参数到输入空间来实现和full fine-tune相当甚至是超过全微调的性能。
2.方法
2.1 预备知识
一个图像分为m个patch块,每一个块的维度为3*h*w,如下图所示
![]()
定义image patch embedding集合Ei,作为输入到第i+1层transformer层的输入。
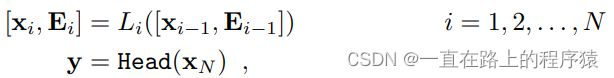
其中的xi为[cls] token的嵌入表示。
2.2 本文所提方法
本文提出了两种VPT,分别是VPT-Shallow和VPT-Deep。
模型如下图所示:
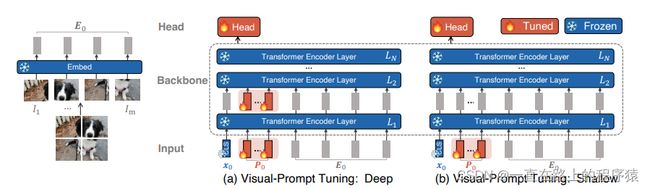
VPT-Shallow,prompts向量仅被插入到第一个Transformer Layer中。
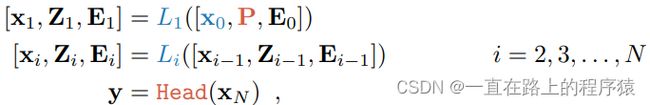
P的形状如下所示,是一个p*d的矩阵。
![]()
VPT-Deep,prompt向量被插入到每一个Transformer层的输入空间中 。
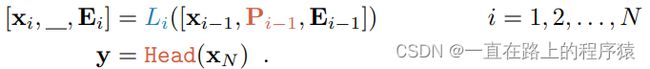
P的形状如下所示,是一个N*p*d的矩阵,其中N是Transformer的层数。
![]()
2.3 参数比较
ViT-Base有86M的参数,带768。prompt长度为50的VPT-Shallow和VPT-Deep的参数量分别为50*768 = 0.038M和12*50*768 = 0.46M,分别占ViT-Base参数的0.04%和0.53%。
3.实验
3.1 实验设置
实验模型
实验用到的模型:ViT和Swin Transformer。两个模型都是在ImageNet-21K上进行预训练。
基线模型
(a)FULL:更新模型的所有参数和分类头的参数
(b)更新分类头的参数,分类头有一下三种定义方式。
——LINEAR:使用线性层作为分类头
——PARTIAL-k:微调模型主干的最后k层(包括分类头的参数),其他层参数保持不变。
——MLP-k:使用一个具有k层的多层感知机作为分类头
(c)更新模型主干参数的子集或者在微调期间为模型主干添加新的可以训练的参数。需要更新的子集有以下三种定义:
——SIDETUNE:
——BIAS:仅仅微调预训练主干的偏差项
——ADAPTER:在Transformer层内插入带有残差连接的MLP模块。
下游任务
FGVC,由5个细粒度的视觉分类任务组成,其中包括CUB-200-2011,NABird,Oxford Flowers, Stanford Dog和Stanford Cars。如果有数据集仅仅有训练集和测试集,那么本文作者以9:1的比例对训练集进行随机划分,划分为训练集和验证集。使用验证集来选择超参数。
VTAB-1k,由19个不同的视觉分类任务组成,这些任务被分为三组,Natural,该任务中的图像由普通的相机获得;Specialized,该任务中的图像由专业的设备获得,比如医疗和卫星图像;Structured,该任务需要对图像进行理解,比如物体计数。VTAB中的每一个任务都包含1000个训练例子,对训练集使用800-200的分割来确定超参数,最后在所有的训练数据上评估。在test集上运行3次,求取平均值。
3.2 实验结果
(1)在下游任务上使用不同的9种调整参数的方法的性能
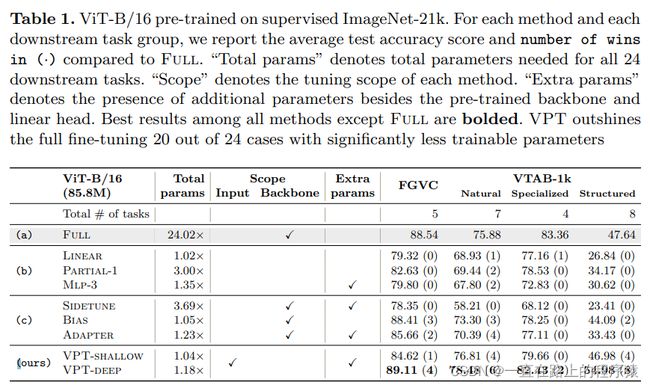
Table 1展示在四个不同的下游任务组中,微调ViT-B/16的所取得的平均结果。
(2)6种训练参数的方法分别使用不同大小的数据集微调模型,最终在测试集上的性能。
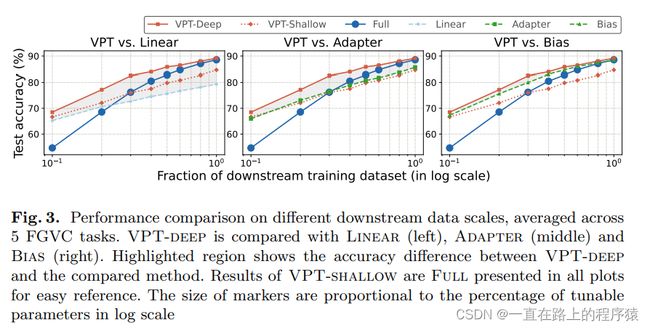
从上图中可以发现,在低资源的场景下,VPT方法取得了最好的效果。随着使用训练数据规模的增大,VPT-DEEP的性能一直超越着全微调的性能。虽然在第三张图中,Bias也比全微调的效果好,但是其性能低于VPT-DEEP的性能。
(3)在不同规模的骨干网络上使用VPT,最终在测试集上的性能
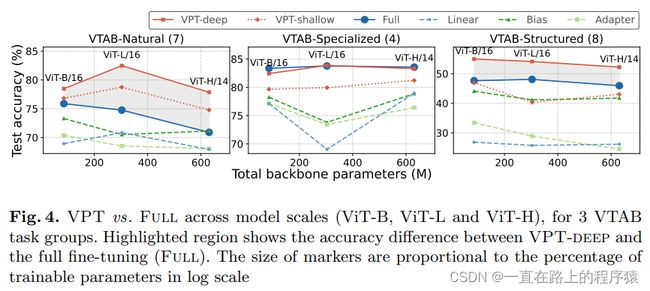
从三个图中可以发现,使用VPT-deep的方法,在Natural和Structured上的性能超越了FULL,在Specialized上取得了和FULL相当的效果(随着模型规模的增大,VPT-deep相比较于FULL,这种优势仍然存在,这点与NLP不同,在NLP领域中,在小模型上使用prompt的效果要低于FULL,但是随着模型大小增大,使用prompt的性能逐渐追上FULL的性能)。但VPT-shallow在后两个任务组中的性能低于微调。
3.3 消融实验
(1)Prompt Location
VPT和其他方法的不同在于将可学习的参数作为了Transformer Layer的输入。对于将prompts插入在输入的哪里,以及怎么插入,本文进行了实验,实验结果如下所示:

Add的方式是给经过编码后的每一个image patch embedding添加一个可以训练的prompts,这种方式可以保证输入到Transformer块的长度和从嵌入层输出来的长度一样。尽管这种方式取得了和FULL相当的性能,但是低于在VPT-deep和shallow的性能。
不同于将prompts插入到第一层Transformer layer的潜在空间,一种做法是在嵌入层之前引入pixel-level的prompt,比如Prepend-pixel和Concat-channel。通过实验结果发现,这两种方式都导致了性能下降。观察发现,在Transformers的潜在输入空间,prompts更容易学习特定于任务的信号。
(2)prompt Length
相比于全微调,提示长度是一个额外增加的需要调整的超参数。为了便于和其他方法比较,本文也在其他方法上的额外超参数上使用了消融实验,比如MLP的层数,ADAPTER的reduction rate(减少率)。实验结果如下所示:
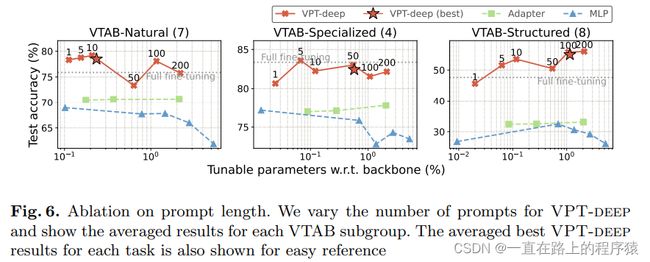
从上图发现,对于不同的任务最佳的提示长度是不同的。横坐标的意思是,可训练的参数与模型主干参数的比值。
(3)Prompt Depth
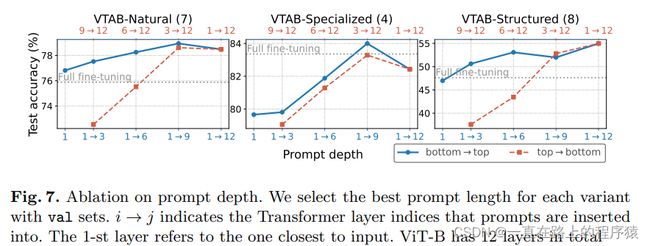
在哪一层加以及怎样加提示也是一个值得考虑的问题。使用两种添加prompt的方法,分别从上往下和从下往上添加提示(模型从下往上依次是嵌入层,transformer第一层,第二层,第三层,…….)。通常上来说,VPT的性能与prompt depth是正相关的关系。同时,从实验中也发现,使用从上往下的方式,效果往往要差,这意味着在Transformer更早层的提示比更后层提示更重要。
(4)Final Output
ViT原始的设置是使用最终的[CLS]的embedding作为分类头的输入,这也是本篇文章ViT实验的默认设置。本文探索了使用不同的embedding作为分类头的输入,所产生的效果。
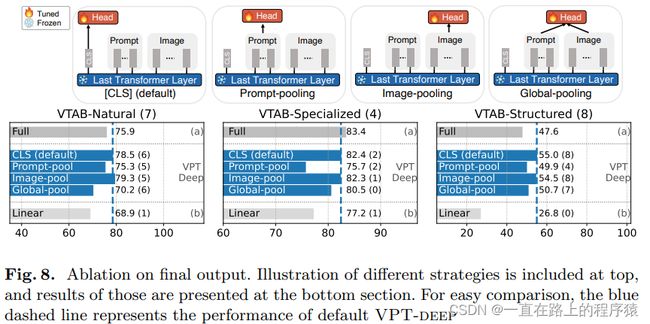
使用所有Image Patch Embedding的平均作为分类头的输入取得了和默认设置相同的效果。如果池化的向量包括提示向量,那么最终的性能将会下降。
- 分析
4.1 可视化
使用t-SNE对[CLS]的embedding进行可视化。使用的是VTAB的中三个任务,这三个任务分别属于三个组别(Natural,specialized,structured)。可视化过程:将每一个测试例子的[cls]的embedding通过t-SNE进行可视化。如果模型的效果很好,那么对于属于同一个类别的测试用例的[cls]的embedding,可视化后的结果应当在一个簇中,且簇与簇之间要可区分。
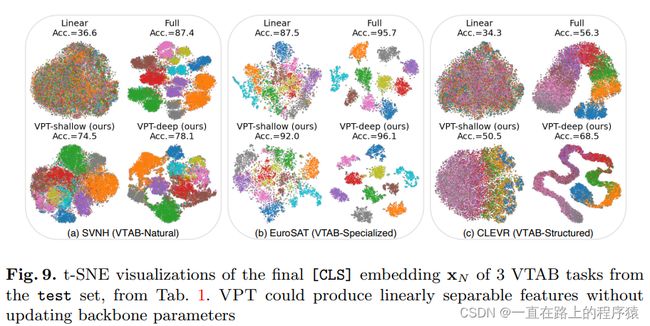
所有的图都显示,使用比全微调更少的参数,VPT-deep能够得到线性可分离的表示。同时也观察到,在transformer的每一层加入prompts,可以改善模型的性能。从第三个图中可以发现,VPT-deep和FULL可以恢复任务的流形结构。
4.2 将VPT应用到更多的视觉任务上
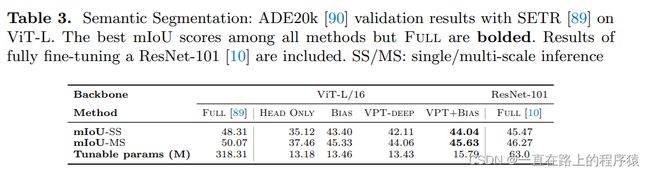
本文将VPT用在语义分割任务中。语义分割模型由一个Transformer和一个标准的ConvNet head组成,使用ConvNet head来进行分割。实验结果如下所示,Head ONLY是仅仅更新卷积头的参数,BIAS是更新头部参数和网络主干的bias向量。虽然参数有效的方法不能够和FULL进行比较,但是VPT取得了和Bias可比较的结果。
值得注意的是,VPT和一个全微调的使用卷积模型的最好的结果取得了可比较的效果。
4.3 在使用其他预训练目标的预训练模型上使用VPT
除了用标记数据预训练的骨干,我们还用两个自监督的目标进行实验,MAE和MoCo v3。
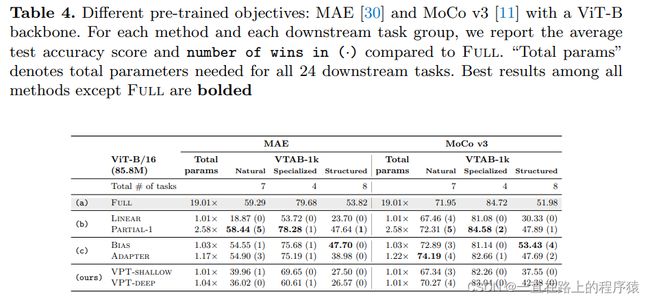
上表是使用ViT-B在VTAB-1k上的结果。可以观察到VPT的变体超越了LINEAR,但是和其他技术的比较却不具有说服力。对于MAE来说,PARTIAL-1超越了其他参数有效的方法。在MoCP V3中,VPT不在保持着最好的性能,尽管VPT和其他的技术的结果性能仍然可以比较。这表明两个自监督的ViT和使用监督的ViT有着根本的不同。为什么以及如何产生这些差异仍然是一个开放的问题。