论文笔记:Document-Level Event Role Filler Extraction using Multi-Granularity Contextualized Encoding
作者:陈宇飞
单位:燕山大学
paper ACL2020
code
目录
- 一、Abstract
- 二、Introduction
- 三、Methodology
-
- 3.1 Constructing Paired Token-tag Sequences from Documents and Gold Role Fillers
- 3.2 k-sentence Reader
- 3.3 Multi-Granularity Reader
- 四、Result
- 五、Conclusion
一、Abstract
首先本文研究了端到端的预训练模型在文档级角色抽取中的表现,以及对于捕获到的上下文的长度对模型性能的影响。为了动态的聚合不同粒度级别(例如,句子和段落级别)的文本信息,本文提出了一种多粒度阅读器。
二、Introduction
完整的文档级事件抽取任务通常需要角色抽取、共指消解和事件跟踪,在本文中只研究角色抽取任务,角色抽取任务的例子如下图。
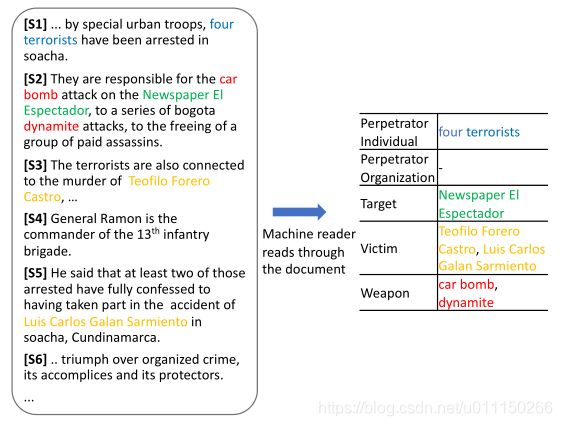
本文的目标是识别出文本中描述的每个事件对应的角色的文本范围,这通常需要句子层面的理解,以及上下文的精确解释。例如,将“Teofilo Forero Castro”(在S3提到)确定为汽车炸弹袭击事件的受害者(在S2提到),确定在S4没有角色(两者都主要依赖于句子层面的理解),以及将S1的“four terrorists”确定为肇事者个人(这需要跨句子边界的共指消解)。
近期的文档级的角色抽取任务中采用了一种带有独立分类器的管道体系结构,但是这类体系结构都受到不同流水线工作中误差传播的影响,而且需要大量的特征工程,而这些特征在特定领域需要语感和专家知识。
捕捉长序列中的长期依赖性仍然是神经网络的一个基本挑战,以Bert为例,Bert的最大序列限制到了512,但是一个文档的长度往往超过512。为此,本文研究了上下文长度对模型性能的影响并找到最合适的长度,提出了一种多粒度阅读器。
三、Methodology
模型结构大体分成三部分:(1)将文档转换成成对的标记序列,并将任务形式转化为序列标记问题;(2)基础知识阅读器;(3)多粒度阅读器。
3.1 Constructing Paired Token-tag Sequences from Documents and Gold Role Fillers
本文引入了BIO(Beginning, Inside, Outside)标记方案将文档转换成成成对的令牌/BIO标记序列,总体思路如下图所示。

首先使用分裂器把文档分成句子 s 1 s_1 s1、 s 2 s_2 s2… s n s_n sn。为了构建数据集,从每个句子 i i i开始,连接连续的k个句子( s i s_i si to s i + k − 1 s_{i+k-1} si+k−1)以形成长度为k的重叠候选序列。同时为了使训练数据平衡,采用相同数量的正负序列。其中正序列至少包含一个事件角色,负序列不包含事件角色。构造验证集时,将连续k个句子组合在一起,产生 n / k n/k n/k个序列,即序列1为{ s 1 s_1 s1,… s k s_k sk},序列2为{ s k + 1 s_{k+1} sk+1,… s 2 k s_{2k} s2k}。对于段落阅读器,设置k为训练集的平均段落长度,为测试集的真实段落长度。
3.2 k-sentence Reader
k-sentence阅读器的输入为X = { x 1 ( 1 ) x_1^{(1)} x1(1), x 2 ( 1 ) x_2^{(1)} x2(1),…, x l 1 ( 1 ) x_{l_1}^{(1)} xl1(1),…, x 1 ( k ) x_1^{(k)} x1(k), x 2 ( k ) x_2^{(k)} x2(k),…, x l 1 ( k ) x_{l_1}^{(k)} xl1(k)},这里的 x i ( k ) x_i^{(k)} xi(k)代表第k个句子中的第i个词。
Embedding Layer
在嵌入层,本文将输入序列中的每个token x i x_i xi表示为其单词嵌入和上下文标记表示的连接。使用100维的GloVe预训练词向量做word embedding,, x e i xe_i xei= E ( x i ) E(x_i) E(xi)。使用Bert-base生成上下文表示, x b 1 xb_1 xb1, x b 2 xb_2 xb2,…, x b m xb_m xbm = BERT( x 1 x_1 x1, x 2 x_2 x2,…, x m x_m xm)。然后把两者连接起来, x i x_i xi=concat( x e i xe_i xei, x b m xb_m xbm)。
BiLSTM Layer
为了帮助模型更好地捕获序列标记之间的特定于任务的特征。使用多层(3层)双向LSTM编码器,将其表示为BiLSTM:
{ p 1 p_1 p1, p 2 p_2 p2, …, p m p_m pm} = BiLSTM({ x 1 x_1 x1, x 2 x_2 x2, …, x m x_m xm})
CRF Layer
{ p 1 p_1 p1, p 2 p_2 p2,…, p m p_m pm}通过一个线性层以后得到一个大小为m × 标注种类的矩阵P,其中 P i , j P_{i,j} Pi,j代表第 i i i个标记的标签 j j j的得分。对于一个标注序列 y y y = { y 1 y_1 y1,…, y m y_m ym}的分数表示为:
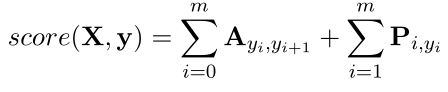
3.3 Multi-Granularity Reader
为了探索聚合不同粒度的上下文token表示(句子级和段落级)的效果,提出了多粒度阅读器。将其应用于两个粒度。词向量在不同粒度时是相同的,上下文表示却不同。相应的,本文在句子级上下文表示和段落级上下文表示上,建立了两个 B i L S T M s BiLSTMs BiLSTMs( B i L S T M s e n t BiLSTM_{sent} BiLSTMsent and B i L S T M p a r a BiLSTM_{para} BiLSTMpara) 。下图为多粒度阅读器的整体架构图。
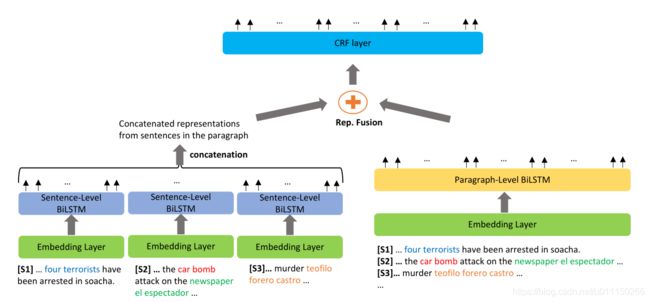
Sentence-Level BiLSTM
按顺序应用于段落中的每一个句子:
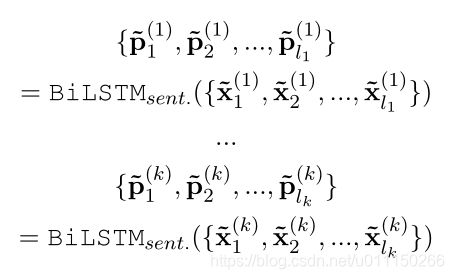
Paragraph-Level BiLSTM
针对完整的段落,捕获tokens之间的依赖性:
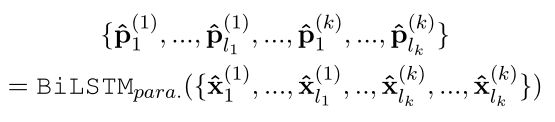
Fusion and Inference Layer
对于每一个token x i ( j ) x_i^{(j)} xi(j),本文提出了两种将句子级表示和段落级表示融合的方法:
1. 简单融合:

2. 门控制融合:控制从两个表示中获得多少信息:

四、Result
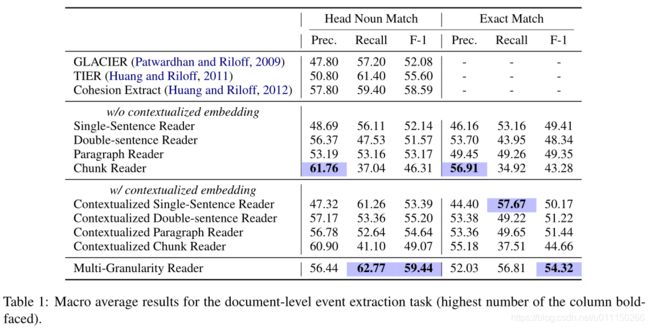
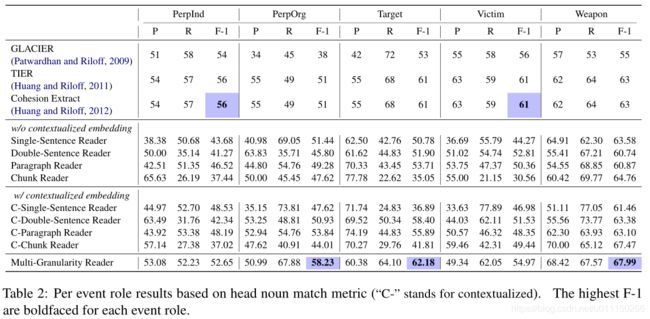
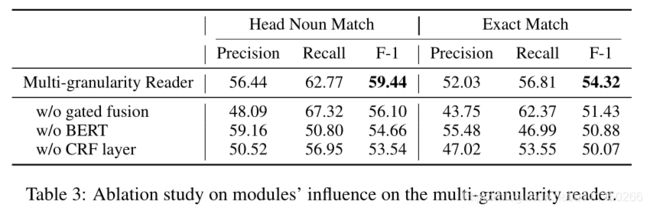
下图为消融实验结果,分析加入门控融合后结果会好于简单融合,证明了动态融合上下文的重要性;去除BERT后召回率和F1都显著下降;替换掉CRF层对每个token独立标注决策时精确率和召回率都显著下降。
五、Conclusion
对于神经模型来说,具有非常长长度的上下文的信息可能难以捕获导致性能下降。本文提出了一种新型多粒度阅读器,动态地纳入段落和句子级的上下文化表示。基准数据集和定性分析的评估结果证明了本文的模型实现了对现有工作的改进。