【深度学习MVS系列论文】MVSNet: Depth Inference for Unstructured Multi-view Stereo
目录
-
- 核心思路
- 相关工作
- Pipeline
-
- 图像特征
- Cost Volumn
- Depth Map
- Loss
- 实现
-
- 数据
- 视角选择
- 训练
- 后处理
- 实验
-
- 评估
- 消融
- 缺陷
MVSNet: Depth Inference for Unstructured Multi-view Stereo
ECCV 2018
核心思路
- extract deep visual image features
- build 3D cost column upon the reference camera frustum via the differential equations homography warping
- apply 3D convolution to regularize and regress the initial deep map
- refine with the reference image
input: one reference image + several source images
output: depth for the reference image
key sight: differential equations homography warping operation, encode camera geometries in the network to build the 3D cost volumes from 2D image features and enables the end-to-end training
contribution:
- encode the camera parameters as the differential equations homography to build the 3D cost volume upon the camera frustum
- bridge the 2D feature extraction and 3D cost regularization networks
- decouple the MVS reconstruction to smaller problems of per-view depth map estimation
- variance-based metric that maps multiple features into one cost feature to adopt arbitrary number of views
- 3D cost volumn is built upon the camera frustum instead of the regular Euclidean space
- decouple MVS reconstruction to per-view depth map estimation
相关工作
-
point cloud reconstruction: propagation strategy, gradually density the reconstruction
- 无法并行化,耗费时间长
-
volumetric reconstruction: 将3D空间划分为网格,判断点是否附着在surface
- 离散化误差,高内存消耗
-
depth map reconstruction
传统方法:
- hand-crafted similarity metrics and engineered regularizations
- 在低纹理、镜面反射区域错误匹配
- 准确度高但完整性很差
双目CNN:
- 无法利用全部视点的信息全局优化
- MVS输入图像的相机形态是任意的
原始多目CNN法:
- volumetric representation of regular grids
- 巨大的内存消耗难以加速
- divide-and-conquer策略时间长
基于学习的MVS
- SurfaceNet、LSM
- 都是基于体表示的,只能处理小体积低分辨率的物体
相关改进:
- learned features → handcrafted features
- semi-global matching for post-processing
- soft argmin回归视差
Pipeline
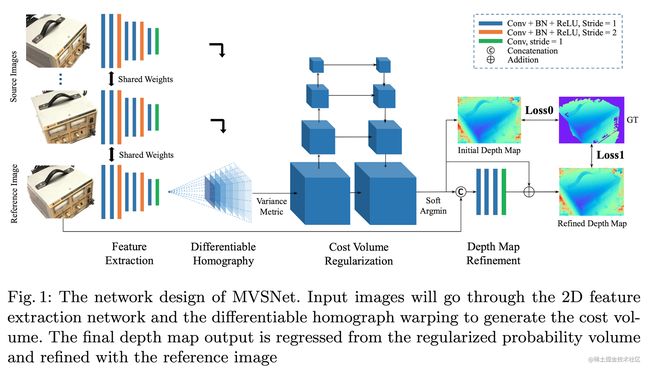
图像特征
8层2D CNN,共享权重,CNN+BN+ReLU,通过stride=2缩小尺寸
输入128维,输出32维度,原始邻接关系已经被编码在其中
Cost Volumn
提取出的特征和相机参数 → 3D代价体,不同在于此构建在camera frustum之上
通过homography在不同深度假设d下将2D和3D进行关联,最终得到feature volumns
Cost Metric
通过方差(分别减平均后的平方除总数)将所有feature volumns编码得到一个cost volumn
❌所有视点对于匹配代价贡献相同
Cost Volumn Regularization
由于图片特征提取中有噪声,对其进行smooth
cost volumn C → probability volumn P
multi-scale 3D CNN(这里有一些涉及网络细节的部分没做整理)
最终通过softmax得到概率不仅可以用作深度估计,而且可用于评估置信度(后续深度估计质量不高的可以通过概率分布观察,也可以做outlier filter)
Depth Map
Initial Estimation
最简单就是概率体P做像素级的winner-take-all(argmax),但不可微,没法反向传播
改为在深度方向计算期望
D = ∑ d m i n d m a x d × P ( d ) D = \sum_{dmin}^{dmax} d \times P(d) D=dmin∑dmaxd×P(d)
Probability Map
对于错误匹配的点,概率分布很可能不是单峰的,很难决断深度到底是多少
take the probability sum over the four nearest depth hypotheses to meatier the estimation quality(这里的解决方法不是十分懂)
Depth Map Refinement
由于感受野,边缘往往过于平滑,用原始图的边缘信息补齐
depth residual learning network(这里涉及残差网络细节的部分没做整理)
Loss

实现
数据
数据集都只有点云ground truth,需要先通过SPSR转换为mesh surface,再在每个视角渲染得到depth map
最终每个场景49张图片*7种亮度共有27097个训练样本
视角选择
通过计算两张图的score挑选一张reference图的两个source
训练
又经过了一定的下采样和裁切得到640*512
深度范围共256层
训练了10w次
后处理
Filter
- photometric consistency: 用当时的概率评估matching quality <0.8的被剔除
- geometric consistency: depth consistency among multiple views
Similar to the left-right disparity check for stereo, we project a reference pixel p1 through its depth d1 to pixel pi in another view, and then reproject pi back to the reference image by pi’s depth estimation di. If the reprojected co- ordinate preproj and and the reprojected depth dreproj satisfy |preproj − p1| < 1 and |dreproj − d1|/d1 < 0.01, we say the depth estimation d1 of p1 is two-view consistent
Fusion
depth map → point cloud
实验
评估
- distance: acc. | comp. | overall
- percentage: acc. | comp. | f-score
消融
View Number
即使train在N=3,但是不影响valid在N=5,N在可控范围内越大loss越小
Image Features
深度特征比传统特征好还快
Cost Metric
element-wise variance operation > mean operation
Depth Refinement
最后的深度剩余网络refine深度图效果不明显,提升只有一点点,甚至差一点点
缺陷
这些缺陷都是数据集本身的问题。。。
- 自己生成的深度图无法做到100%准(前景边缘的背景像素可能被错误标注)
- 被遮挡的像素不该被用于训练