模型的数据归一化处理
使用fashion_mnist数据建立一个模型,对数据进行归一化处理之后再放入模型中进行训练。
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
2.6.2
sys.version_info(major=3, minor=6, micro=8, releaselevel='final', serial=0)
matplotlib 3.3.4
numpy 1.19.5
pandas 1.1.5
sklearn 0.24.2
tensorflow 2.6.2
keras.api._v2.keras 2.6.0
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
# 归一化之前的最大值和最小值
print(np.max(x_train), np.min(x_train))
255 0
对数据进行归一化
# 数据归一化x = (x - u) / std
# 实现数据归一化使用StanderdScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# x_train: [None, 28, 28] -> [None, 784] -> [None, 28, 28]
# 验证集和测试集也需要用训练集的方差来做
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28)
# 归一化之后的最大值和最小值
print(np.max(x_train_scaled), np.min(x_train_scaled))
2.0231433 -0.8105136
# tf.keras.model.Sequential()
'''
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
'''
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
# relu: y = max(0, x)
# softmax: 将向量编程概率分布 x = [x1, x2, x3]
# y = [e^x1/sum, e^x2/sum, e^x3/sum], sum = e^x1 + e^x2 + e^x3
# reason for sparse:y->index. y ->one_hot->[]
model.compile(loss="sparse_categorical_crossentropy",
optimizer = keras.optimizers.SGD(0.001),
metrics = ["accuracy"])
history = model.fit(x_train_scaled, y_train, epochs=10,
validation_data=(x_valid_scaled, y_valid))
Epoch 1/10
1719/1719 [==============================] - 5s 2ms/step - loss: 0.9403 - accuracy: 0.7012 - val_loss: 0.6350 - val_accuracy: 0.7856
Epoch 2/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.5903 - accuracy: 0.7961 - val_loss: 0.5339 - val_accuracy: 0.8176
Epoch 3/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.5174 - accuracy: 0.8185 - val_loss: 0.4844 - val_accuracy: 0.8340
Epoch 4/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.4790 - accuracy: 0.8315 - val_loss: 0.4585 - val_accuracy: 0.8434
Epoch 5/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.4540 - accuracy: 0.8394 - val_loss: 0.4371 - val_accuracy: 0.8516
Epoch 6/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.4356 - accuracy: 0.8458 - val_loss: 0.4222 - val_accuracy: 0.8556
Epoch 7/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.4208 - accuracy: 0.8514 - val_loss: 0.4131 - val_accuracy: 0.8584
Epoch 8/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.4093 - accuracy: 0.8547 - val_loss: 0.4051 - val_accuracy: 0.8626
Epoch 9/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.3989 - accuracy: 0.8589 - val_loss: 0.4006 - val_accuracy: 0.8644
Epoch 10/10
1719/1719 [==============================] - 4s 2ms/step - loss: 0.3902 - accuracy: 0.8611 - val_loss: 0.3900 - val_accuracy: 0.8678
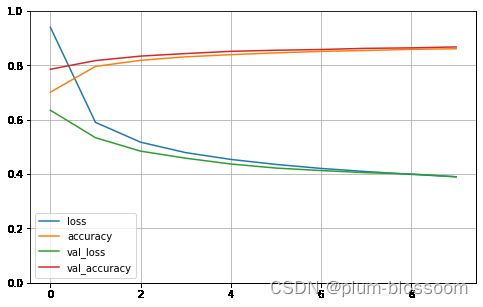
进行归一化之后的accuracy为:0.87
不进行归一化的accuracy为:0.83 代码链接
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
model.evaluate(x_test_scaled, y_test)
313/313 [==============================] - 0s 1ms/step - loss: 0.4235 - accuracy: 0.8474
[0.4235072731971741, 0.8474000096321106]