CUDA By Example(五)——常量内存与事件
本章将介绍如何使用GPU上特殊的内存区域来加速应用程序的执行,以及如何通过事件来测量CUDA应用程序的性能。通过这些测量方法,你可以定量的分析对应用程序的某个修改是否会带来性能提升
文章目录
- 常量内存
-
- 光纤跟踪简介
- 在GPU上实现光线跟踪
- 通过常量内存来实现光线跟踪
- 常量内存带来的性能提升
- 使用事件来测量性能
- 遇到的问题与解决方案
- 补充知识
常量内存
由于在GPU上包含有数百个数学计算单元,因此性能瓶颈通常并不在于芯片的数学计算吞吐量,而是在于芯片的内存带宽。由于在图形处理器上包含了非常多的数学逻辑单元(ALU),因此有时输入数据的速率甚至无法维持如此高的计算速率。因此,有必要研究一些手段来减少计算问题时的内存通信量。
到目前为止,我们已经看到了CUDA C程序中可以使用全局内存和共享内存。但是,CUDA C 还支持另一种类型的内存,即常量内存。从常量内存的名字就可以看出,常量内存用于保存在核函数执行期间不会发生变化的数据。NVIDIA 硬件提供了 64KB 的常量内存,并且对常量内存采取了不同于标准全局内存的处理方式。在某些情况中,用常量内存来替换全局内存能有效地减少内存带宽。
光纤跟踪简介
下面给出一个简单的光纤跟踪(Ray Tracing)应用程序示例,并在这个示例中介绍如何使用常量内存。
简单地说,光线跟踪是从三维对象场景中生成二维图形的一种方式。原理很简单:在场景中选择一个位置放上一台假想的相机。这台数字相机包含一个光传感器来生成图像,因此我们需要判断哪些光将接触到这个传感器。图像中的每个像素与命中传感器的光线有着相同的颜色和强度。
由于在传感器中命中的光线可能来自场景中的任意位置,因此事实上也证明了采用逆向计算或许是更容易实现的。也就是说,不是找出哪些光线将命中某个像素,而是想象从该像素发出一道射线进入场景中。按照这种思路,每个像素的行为都像一只 “观察” 场景的眼睛。如下图所示
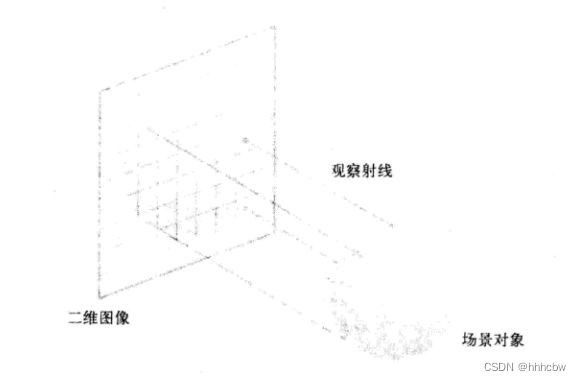
我们将跟踪从像素中投射出的光线穿过场景,直到光线命中某个物体,然后计算这个像素的颜色。我们说像素都将“看到”这个物体,并根据它所看到物体的颜色来设置它的颜色。光线跟踪中的大部分计算都是光线与场景中物体的相交运算。
在更复杂的光线跟踪模型中,场景中的反光物体能够反射光线,而半透明的物体能够折射光线。这将生成二次射线(Secondary Ray)和三次射线(Tertiary Ray)等等。事实上,这正是光线跟踪最具吸引力的功能之一:实现基本的光线跟踪器是很容易的,如果需要的话,也可以在光线跟踪器中构建更为复杂的成像模型以生成更真实的图像。
在GPU上实现光线跟踪
这里的光线跟踪器只支持一组包含球状物体的场景,并且相机被固定在Z轴,面向原点。此外,我们将不支持场景中的任何照明,从而避免二次光线带来的复杂性。我们也不计算照明效果,而只是为每个球面分配一个颜色值,然后如果它们是可见的,则通过某个预先计算的值对其着色。
光线跟踪器从每个像素发射一道光线,并且跟踪这些光线会命中哪些球面。此外,它还将跟踪每道命中光线的深度。当一道光线穿过多个球面时,只有最接近相机的球面才会被看到。我们的 ”光线跟踪器“ 会把相机看不到的球面隐藏起来。
通过一个数据结构对球面建模,在数据结构中包含了球面的中心坐标 (x,y,z),半径 radius,以及颜色值 (r,g,b)。
#define INF 2e10f
struct Sphere {
float r, b, g;
float radius;
float x, y, z;
__device__ float hit(float ox, float oy, float* n) {
float dx = ox - x;
float dy = oy - y;
if (dx * dx + dy * dy < radius * radius) {
float dz = sqrtf(radius * radius - dx * dx - dy * dy);
*n = dz + z;
return dz + z;
}
return -INF;
}
};
这个结构中定义了一个方法 hit(float ox, float oy, float *n),对于来自 (ox, oy) 处像素的光线,这个方法将计算光线是否与这个球面相交。如果光线与球面相交,那么这个方法将计算从相机到光线命中球面处的距离。我们需要这个信息,原因在前面已经提到了:当光线命中多个球面时,只有最接近相机的球面才会被看见。
main() 函数遵循了与前面示例大致相同的代码结构。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#include 我们为输入的数据分配了内存,这些数据是一个构成场景的 Sphere 数组。由于 Sphere 数组将在 CPU 上生成并在 GPU 上使用,因此我们必须分别调用 cudaMalloc() 和 malloc() 在 GPU 和 CPU 上分配内存。我们还需要分配一张位图图像,当在 GPU 上计算光线跟踪球面时,将用计算得到的像素值来填充这张图像。
在分配输入数据和输出数据的内存后,我们将随机地生成球面的中心坐标,颜色以及半径。
// 分配临时内存,对其初始化,并复制到
// GPU上的内存,然后释放临时内存
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
for (int i = 0; i < SPHERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
当前,程序将生成一个包含 20 个球面的随机数组,但这个数量值是通过一个 #define 宏指定的,因此可以相应地做出调整。
通过 cudaMemcpy() 将这个球面数组复制到 GPU,然后释放临时缓冲区。
HANDLE_ERROR(cudaMemcpy(s, temp_s, sizeof(Sphere) * SPHERES, cudaMemcpyHostToDevice));
free(temp_s);
现在,输入数据位于 GPU 上,并且我们已经为输出数据分配好了空间,因此可以启动核函数。
// 从球面数据中生成一张位图
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<grids,threads>>> (dev_bitmap);
这个函数将执行光线跟踪计算并且从输入的一组球面中为每个像素计算颜色数据。最后,将输出图像从 GPU 中复制回来,并显示它。当然,我们还要释放所有已经分配但还未释放的内存。
// 将位图从GPU复制回到CPU以显示
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
// 释放内存
cudaFree(dev_bitmap);
cudaFree(s);
return 0;
}
每个线程都会为输出影像中的一个像素计算颜色值,因此我们遵循一种惯用的方式,计算每个线程对于的 x 坐标和 y 坐标,并且根据这两个坐标来计算输出缓冲区中的偏移。此外,我们还将图像坐标 (x, y) 偏移 DIM/2,这样 z 轴将穿过图像的中心。
__global__ void kernel(unsigned char* ptr, Sphere* s) {
// 将threadIdx/BlockIdx映射到像素位置
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
由于每条光线都需要判断与球面相交的情况,因此我们现在对球面进行迭代,并判断每个球面的命中情况。
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
}
}
显然,判断相交计算的大部分代码都包含在 for() 循环中。对每个输入的球面进行迭代,并调用 hit() 方法来判断来自像素的光线能否 “看到” 球面。如果光线命中了当前的球面,那么接着判断命中的位置与相机之间的距离是否比上一次命中的距离更加接近。如果更加接近,那么我们将这个距离保存为新的最接近球面。此外,我们还将保存这个球面的颜色值,这样当循环结束时,线程就会知道与相机最接近的球面的颜色值。由于这就是从像素发出的光线 ”看到” 的颜色值,也就是该像素的颜色值,因此这个值应该保存在输出图像的缓冲区中。
在判断了每个球面的相交情况后,可以将当前的颜色值保存到输出图像中,如下所示:
ptr[offset * 4 + 0] = (int)(r * 255);
ptr[offset * 4 + 1] = (int)(g * 255);
ptr[offset * 4 + 2] = (int)(b * 255);
ptr[offset * 4 + 3] = 255;
}
注意,如果没有命中任何球面,那么保存的颜色值将是变量 r, b 和 g 的初始值。在本示例中,r、b 和 g 的初始值都设置为 0,因此背景色是黑色。你可以修改这些值以便生成不同颜色的背景。
完整代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
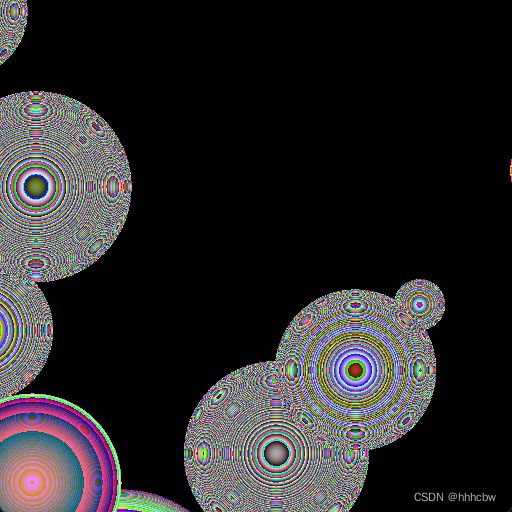
#include 运行结果如下
通过常量内存来实现光线跟踪
下面使用常量内存来改进这个示例。由于常量内存是不能修改的,因此显然无法用常量内存来保存输出图像的数据。在这个示例中只有一个输入书,即球面数组,因此应该将这个数据保存到常量内存中。
常量内存的声明方法与共享内存是类似的。要使用常量内存,那么在代码中将不再像下面这样声明数组:
Sphere *s;
而是在变量前面加上 __constant__ 修饰符:
__constant__ Sphere s[SPHERES};
注意,在最初的示例中,我们声明了一个指针,然后通过 cudaMalloc() 来为指针分配 GPU 内存。当我们将其修改为常量内存时,同样要将这个声明修改为在常量内存中静态地分配空间。我们不再需要对球面数组调用 cudaMalloc() 或者 cudaFree(),而是在编译时为这个数组提交一个固定的大小。这对许多应用程序来说是可以接受的,因为常量内存能够带来性能的提升。我们稍后会看到常量内存的优势,但首先来看看如何将 main() 函数修改为使用常量内存:
int main()
{
// 记录起始时间
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
// 在GPU上分配内存以计算输出位图
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
// 为Sphere数据集分配内存
// HANDLE_ERROR(cudaMalloc((void**)&s, sizeof(Sphere) * SPHERES));
// 分配临时内存,对其初始化,并复制到
// GPU上的内存,然后释放临时内存
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
for (int i = 0; i < SPHERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
HANDLE_ERROR(cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES));
// HANDLE_ERROR(cudaMemcpy(s, temp_s, sizeof(Sphere) * SPHERES, cudaMemcpyHostToDevice));
free(temp_s);
// 从球面数据中生成一张位图
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<grids,threads>>> (dev_bitmap);
// 将位图从GPU复制回到CPU以显示
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
// 释放内存
cudaFree(dev_bitmap);
// cudaFree(s);
return 0;
}
这段代码在很大程度上类似于之前 main() 的实现。正如在前面提到的,对 main() 函数的修改之一就是不再需要调用 cudaMalloc() 为球面数组分配空间。在下面给出了另一处修改:
HANDLE_ERROR(cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES));
当从主机内存复制到 GPU 上的常量内存时,我们需要使用这个特殊版本的 cudaMemcpy()。cudaMemcpyToSymbol() 与参数为 cudaMemcpyHostToDevice() 的 cudaMemcpy() 之间的唯一差异在于 cudaMemcpyToSymbol() 会复制到常量内存,而 cudaMemcpy() 会复制到全局内存。
除了 __constant__ 修饰符和对 main() 的两处修改之外,其他的代码都是相同的。
常量内存带来的性能提升
__constant__ 将把变量的访问限制为只读。在接受了这种限制后,我们希望得到某种回报。在前面曾提到,与从全局内存中读取数据相比,从常量内存中读取相同的数据可以节约内存带宽,主要有两个原因:
- 对常量内存的单次读操作可以广播到其他的 “邻近(Nearby)” 线程,这将节约 15 次读取操作
- 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量
“邻近” 这个词的含义是什么?要回答这个问题,首先需要解释线程束 (Warp) 的概念。线程束可以看成是一组线程通过交织而形成的一个整体。在 CUDA 架构中,线程束是指一个包含 32 个线程的集合,这个线程集合被 “编织在一起” 并且以 “步调一致(Lockstep)” 的形式执行。在程序中的每一行,线程束中的每个线程都将在不同的数据上执行相同的指令。
当处理常量内存时,NVIDIA 硬件将把单次内存读取操作广播到每个半线程束 (Half-Warp)。在半线程束中包含了 16 个线程,即线程束中线程数量的一半。如果在半线程束中的每个线程都从常量内存的相同地址上读取数据,那么 GPU 只会产生一次读取请求并在随后将数据广播到每个线程。如果从常量内存中读取大量的数据,那么这种方式产生的内存流量只是使用全局内存时的 1/16(大约6%)。
但在读取常量内存时,所节约的并不仅限于减少了 94% 的带宽。由于这块内存的内容是不会发生变化的,因此硬件将主动把这个常量数据缓存到 GPU 上。在第一次从常量内存的某个地址上读取后,当其他半线程束请求同一个地址时,那么将命中缓存,这同样减少了额外的内存流量。
在我们的光线跟踪器中,每个线程都要读取球面的相应数据从而计算它与光线的相交情况。在把应用程序修改为将球面数据保存在常量内存后,硬件只需要请求这个数据一次。在缓存数据后,其他每个线程将不会产生内存流量,原因有两个:
- 线程将在半线程束的广播中收到这个数据
- 从常量内存缓存中收到数据
然而,当使用常量内存时,也可能对性能产生负面影响。半线程束广播功能实际上是一把双刃剑。虽然当 16 个线程都读取相同地址时,这个功能可以极大地提升性能,但当所有 16 个线程分别读取不同的地址时,它实际上会降低性能。
只有当 16 个线程每次都只需要相同的读取请求时,才值得将这个读取操作广播到 16 个线程。然而,如果半线程束中的所有 16 个线程需要访问常量内存中不同的数据,那么这个 16 次不同的读取操作会被串行化,从而需要 16 倍的时间来发出请求。但如果从全局内存中读取,那么这些请求会同时发出。在这种情况中,从常量内存读取就慢于从全局内存中读取。
使用事件来测量性能
·在充分理解了常量内存即可能带来正面影响,也可能带来负面影响后,你已经决定将光线跟踪器改为使用常量内存。下面我们使用 CUDA 的事件 API 来测量 GPU 在某个任务上花费的时间,以直观感受常量内存带来的性能提升。
CUDA 中的事件本质上是一个 GPU 时间戳,这个时间戳是在用户指定的时间点上记录的。由于 GPU 本身支持记录时间戳,因此就避免了当使用 CPU 定时器来统计 GPU 执行的时间时可能遇到的诸多问题。这个 API 使用起来很容易,因为获得一个时间戳只需要两个步骤:首先创建一个事件,然后记录一个事件。例如,在某段代码的开头,我们告诉 CUDA 运行时记录当前时间。首先创建一个事件,然后记录这个事件:
cudaEvent_t start;
cudaEventCreate(&start);
cudaEventRecord(start, 0);
要统计一段代码的执行时间,不仅要创建一个起始事件,还要创建一个结束事件。当在 GPU 上执行某个工作时,我们不仅要告诉 CUDA 运行时记录起始时间,还要记录结束时间:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 在 GPU 上执行一些工作
cudaEventRecord(stop, 0);
然而,当按照这种方式来统计 GPU 代码时间时,仍然存在一个问题。要修复这个问题,只需一行代码,但需要对这行代码进行一些解释。在使用事件时,最复杂的情况是当我们在 CUDA C 中执行的某些异步函数调用时。例如,当启动光线跟踪器的核函数时,GPU 开始执行代码,但在 GPU 执行完之前,CPU 会继续执行程序中的下一行代码。从性能的角度来看,这是非常好的,因为这意味着我们可以在 GPU 和 CPU 上同时进行计算,但从逻辑概念上来看,这将使计时工作变得更加复杂。
你应该将 cudaEventRecord() 视为一条记录当前时间的语句,并且把这条语句放入 GPU 的未完成工作队列中。因此,直到 GPU 执行完了在调用 cudaEventRecord() 之前的所有语句时,事件才会被记录下来。由 stop 事件来测量正确的时间正是我们所希望的,但仅当 GPU 完成了之前的工作并且记录了 stop 事件后,才能安全地读取 stop 时间值。幸运的是,我们有一种方式告诉 CPU 在某个事件上同步,这个事件 API 函数就是 cudaEventSynchronize():
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 在 GPU 上执行一些工作
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
现在,我们已经告诉运行时阻塞后面的语句,直到 GPU 执行到达 stop 事件。当 cudaEventSynchronize 返回时,我们知道在 stop 事件之前的所有 GPU 工作已经完成了,因此可以安全地读取在 stop 中保存的时间戳。值得注意的是,由于 CUDA 事件是直接在 GPU 上实现的,因此它们不适用于对同时包含设备代码和主机代码的混合代码计时。也就是说,如果你试图通过 CUDA 事件对核函数和设备内存复制之外的代码进行计时,将得到不可靠的结果。
测量光线跟踪器的性能
为了对光线跟踪器计时,我们需要分别创建一个起始事件和一个结束事件。下面是一个支持计时的光线跟踪器,其中没有使用常量内存:
int main()
{
// 记录起始时间
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
// 在GPU上分配内存以计算输出位图
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
// 为Sphere数据集分配内存
HANDLE_ERROR(cudaMalloc((void**)&s, sizeof(Sphere) * SPHERES));
// 分配临时内存,对其初始化,并复制到
// GPU上的内存,然后释放临时内存
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
for (int i = 0; i < SPHERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
//HANDLE_ERROR(cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES));
HANDLE_ERROR(cudaMemcpy(s, temp_s, sizeof(Sphere) * SPHERES, cudaMemcpyHostToDevice));
free(temp_s);
// 从球面数据中生成一张位图
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<grids,threads>>> (dev_bitmap, s);
// 将位图从GPU复制回到CPU以显示
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
// 获得结束时间,并显示计时结果
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("Time to generate: %3.lf ms\n", elapsedTime);
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
// 显示位图
bitmap.display_and_exit();
// 释放内存
cudaFree(dev_bitmap);
cudaFree(s);
return 0;
}
运行结果如下:
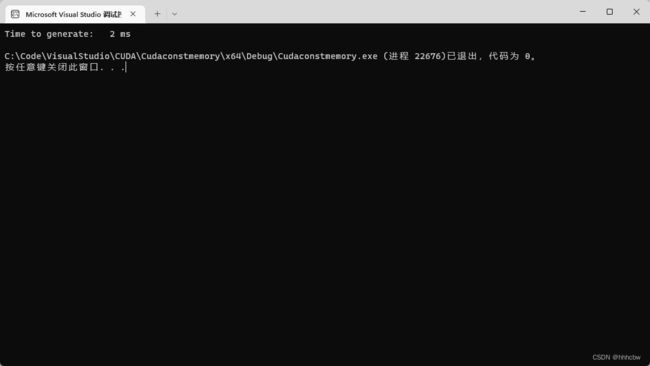
这里使用了两个额外的函数,分别为 cudaEventElapsedTime() 和 cudaEventDestroy()。cudaEventElapsedTime() 是一个工具函数,用来计算两个事件之间经历的时间。第一个参数为某个浮点变量的地址,在这个参数中将包含两次事件之间经历的时间,单位为毫秒。
当使用完事件后,需要调用 cudaEventDestroy() 来销毁它们。这相当于对 malloc() 分配的内存调用 free(),因此每个 cudaEventCreate() 都对应一个 cudaEventDestroy() 同样是非常重要的。
接下来对使用常量内存的光线跟踪器进行计时:
int main()
{
// 记录起始时间
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
HANDLE_ERROR(cudaEventRecord(start, 0));
CPUBitmap bitmap(DIM, DIM);
unsigned char* dev_bitmap;
// 在GPU上分配内存以计算输出位图
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
// 为Sphere数据集分配内存
// HANDLE_ERROR(cudaMalloc((void**)&s, sizeof(Sphere) * SPHERES));
// 分配临时内存,对其初始化,并复制到
// GPU上的内存,然后释放临时内存
Sphere* temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
for (int i = 0; i < SPHERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
HANDLE_ERROR(cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere) * SPHERES));
// HANDLE_ERROR(cudaMemcpy(s, temp_s, sizeof(Sphere) * SPHERES, cudaMemcpyHostToDevice));
free(temp_s);
// 从球面数据中生成一张位图
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
kernel<<<grids,threads>>> (dev_bitmap);
// 将位图从GPU复制回到CPU以显示
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
// 获得结束时间,并显示计时结果
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("Time to generate: %3.lf ms\n", elapsedTime);
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
// 显示位图
bitmap.display_and_exit();
// 释放内存
cudaFree(dev_bitmap);
// cudaFree(s);
return 0;
}
运行结果如下:
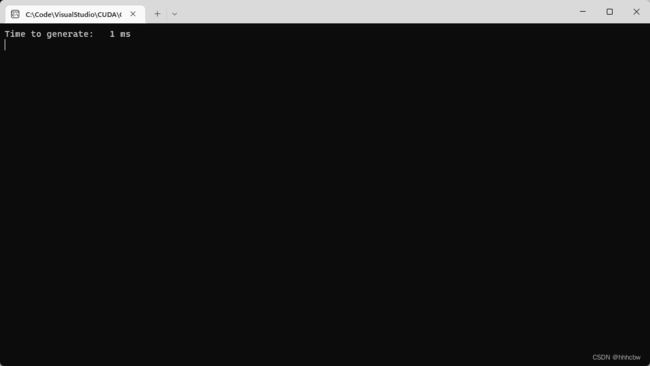
实验结果表明,使用常量内存的光线跟踪器的性能比使用全局内存的性能提升了 50%。在不同的 GPU 上,你得到的实验结果可能会有所不同,但使用常量内存的光线跟踪器应该比不使用常量内存的光线跟踪器要更快一些。
遇到的问题与解决方案
在运行第一个不使用常量内存的光线跟踪器时,出现错误 identifier "s" is undefined in device code,这是因为对于存放在全局内存的参数,需要通过参数列表传入核函数中,所以改为如下语句:
kernel<<<grids,threads>>> (dev_bitmap, s);
而对于常量内存,其不需要传入核函数中,所以使用原本的语句即可:
kernel<<<grids,threads>>> (dev_bitmap);
补充知识
常量内存其实只是全局内存的一种虚拟地址形式,并没有特殊保留的常量内存块。