图神经网络的池化操作
图神经网络有两个层面的任务:一个是图层面(graph-level),一个是节点(node-level)层面,图层面任务就是对整个图进行分类或者回归(比如分子分类),节点层面就是对图中的节点进行分类回归(交通网络道路流量预测)。对于图层面的任务,我们需要聚合图的全局信息(包括所有节点和所有边),并且聚合全局信息得到一个可以表示全图的向量,后续对该向量进行分类回归操作。
如何将全局信息表示为一个向量呢,在图片分类和回归任务中,我们有池化操作,在图数据中,我们一样引入池化操作。
目录
1、全局池化
1.1 readout
1.2 全局虚拟节点
2、层次池化
2.1 基于图坍缩的池化机制
2.2 基于TopK的池化机制
2.3 基于边收缩的池化机制
参考文献
1、全局池化
1.1 readout
读出操作(readout)[1]最简单的池化操作,其操作公式为:
![]()
其中 可以是
可以是![]() 操作,也就是说readout直接对图中所有节点求最大值,求和,求均值,将做得到的值作为图的输出。
操作,也就是说readout直接对图中所有节点求最大值,求和,求均值,将做得到的值作为图的输出。
1.2 全局虚拟节点
全局虚拟节点[2]就是引入一个虚拟节点,这个虚拟节点和图中所有节点相连,并且也参加整个图的卷积等操作,最后该虚拟节点的隐含特征就是整个图的特征,示意图如下:

引入全局节点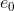 ,图中原来的节点为
,图中原来的节点为![]() 。
。
2、层次池化
层次池化经过K轮消息传递,节点更能够提取全局信息。
2.1 基于图坍缩的池化机制
图坍缩就是将图中的节点划分为几个节点簇,每个节点簇作为下一次图坍缩的节点。

目前DIFFOOL[3]和EigenPooL[4]是两种基于图坍缩的图神经网络算法
2.2 基于TopK的池化机制
TopK[5]对池化机制和上面的图坍缩不同,图坍缩是将图的节点不断聚合成簇的过程,而TopK是一个不断抛弃节点的过程,具体来说就是设置一个超参数 ,其中
,其中![]() ,接着学习出表示节点重要度的值
,接着学习出表示节点重要度的值 并按照重要度对节点进行降序排序,选择最重要的
并按照重要度对节点进行降序排序,选择最重要的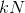 个节点,公式表示如下:
个节点,公式表示如下:
![]()
![]()
![]()
![]() 表示一个切片操作,就是留下个节点以及与其相连的边
表示一个切片操作,就是留下个节点以及与其相连的边
如何选择也是一个可以创新的地方,在论文中,作者引入了一个全局基向量 ,将节点向量在该向量上的投影作为重要度:
,将节点向量在该向量上的投影作为重要度:
![]()
其中 为节点特征向量。论文中给出的TopK的模型结构为:
为节点特征向量。论文中给出的TopK的模型结构为:
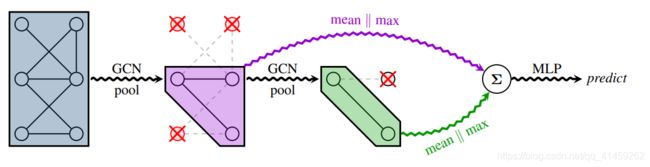
该作者还在每一层池化之后添加读出操作,并在最后最后一层做求和,这样有助于虽有节点的信息融合。
2.3 基于边收缩的池化机制
该方法迭代式的对每一条边的节点进行两两归并并形成新的节点,同时保留合并前的两节点的连接关系到新节点上,EdgePool[6]就是基于边收缩的池化图网络,接下来介绍其相关算法:
首先对于每条边计算一个原始分数:
![]()
如下图(左)根据A,B,C,D四个点计算出来的边的原始分数
再根据入度计算每个边的分数:
![]()
节点分数为边入度边分数之和
如下图(左中),D的值就是:![]() , C的值为
, C的值为![]() .
.
再计算边对其入度节点的值的归一化
如下图(右中),C->D的边的值为:1.6/1.5=1
最后选择分数最大且未被选中的两个节点进行收缩操作。

收缩之后的节点更新方式为:
![]()
 可以为求和,求均值,全连接等操作。
可以为求和,求均值,全连接等操作。
参考文献
[1] Gilmer J, Schoenholz S S, Riley P F, et al. Neural message passing for quantum chemistry[J]. arXiv preprint arXiv:1704.01212, 2017.
[2] Pham T, Tran T, Dam H, et al. Graph classification via deep learning with virtual nodes[J]. arXiv preprint arXiv:1708.04357, 2017.
[3] Ying Z, You J, Morris C, et al. Hierarchical graph representation learning with differentiable pooling[C]//Advances in neural information processing systems. 2018: 4800-4810.
[4] Ma Y, Wang S, Aggarwal C C, et al. Graph convolutional networks with eigenpooling[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 723-731.
[5] Cangea C, Veličković P, Jovanović N, et al. Towards sparse hierarchical graph classifiers[J]. arXiv preprint arXiv:1811.01287, 2018.
[6] Diehl F. Edge contraction pooling for graph neural networks[J]. arXiv preprint arXiv:1905.10990, 2019.
[7] 刘忠雨,李彦霖,周洋,《深入浅出图神经网络:GNN原理解析》