R语言笔记:机器学习【决策树(Decision Tree】
写在开头:
我是一个学R的小白,因为读研老师要求开始接触R。
记一记笔记留给自己以后回顾,顺便分享出来嘻嘻。
我把需要深入的的函数进行介绍~方便了解这些函数的用法,一些简单的函数我就不放出来啦
决策树这部分的笔记主要是利用分类回归法哈
rpart()函数
用于建立分类回归树,使用前library(rpart)。
格式
rpart(输出变量~输出变量,data=,method=,parms=list(split=异质性测度指标),control)
参数含义
method——用于指定方法。可取值:”class”表示建立分类树;”poisson”和”anova”分别表示输出变量为计数变量和其他数值型变量
parms——用于指定分类树异质性测度指标。可取值:”gini”表示采用Gini系数;”information”表示采用信息熵
control——用于设定预修剪参数、后修剪中的复杂度参数CP值
rpart.control()函数
用于自行设置预修剪等参数,使用前library(rpart)。
格式
rpart.control(minsplit=20,maxcompete=4,xval=10,maxdepth=30,cp=0.0.1)
参数含义
minsplit——用于指定节点的最小样本量,默认为20.当节点样本量小于指定值时将不再继续分组。
maxcompete——制定按变量重要性(使输出变量异质性下降)降序,输出当前最佳分组变量的前若干个候选变量,默认值为4
xval——用于指定进行交叉验证剪枝时的交叉折数,默认值为10
maxdepth——用于指定最大树深度,默认为30
cp——用于指定最小代价复杂度剪枝中的复杂度CP参数值,默认初始值为0.01
NOTE:rpart.control函数的执行结果应赋给一个R对象,该对象名将作为rpart函数中control的参数值。
rpart.plot()函数
用于直观地展示决策树,实现决策树的可视化,使用前library(rpart.plot)。
格式
rpart.plot(objective,type=编号,branch=外形编号,extra=1)
参数含义
objective——决策树结果对象名
type——用于指定决策树展示方式,可取值:0:对于叶节点显示所包含样本量和预测值,对于根节点和中间节点,显示分组条件;1:显示所有节点所包含的样本量和预测值,对于根节点和叶节点,在上方显示分组条件。2:与1类似,只是分组条件显示在根节点和中间节点的下方
branch——用于指定决策树的外形,可取值:0表示以斜线形式连接数的上下节点。1表示以垂线形式连接
extra——用于指定在节点中显示哪些数据,可取值:1:显示预测类别和节点样本量;2:显示预测类别和置信度;3:显示预测类别和节点判错率;4~9…
printcp(objective)和plotcp(objective)函数
用于浏览和可视化CP值。
一个栗子
初建分类树
library(rpart);library(rpart.plot)
rt<-read.table("D:/R/《R语言数据挖掘方法及应用》案例数据/消费决策数据.txt",header=T)
rt$Income<-as.factor(rt$Income)
rt$Gender<-as.factor(rt$Gender)
##自行设定预修剪等参数,复杂度参数CP为0
ctl<-rpart.control(minsplit = 2,maxcompete = 4,xval=10,cp=0)
set.seed(12345)
treefit1<-rpart(rt$Purchase~.,data=rt,method = "class",parms=list(split="gini"),control=ctl)
printcp(treefit1)
plotcp(treefit1)
##根据CP值与预测误差的可视化图可知包含12个叶节点(nslipt=11)处决策树有最低交叉验证预测误差
出现的结果如下:

重新建树:按系统默认参数建树,cp=0.01
set.seed(12345)
treefit2<-rpart(rt$Purchase~.,data=rt,method="class",parms = list(split="gini"))
treefit2
rpart.plot(treefit2,type=4,branch=0,extra=2)
出现的结果如下:
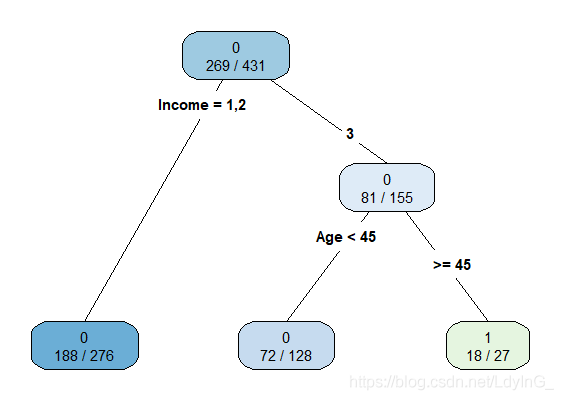
上面就是得出的决策树啦