高级实训任务一:基于CNN及其变体的图像分类
实验内容
卷积神经网络(CNN)因为其能够自动抽取图像的浅层到深层的特征,所以在近几年有许多应用。实验尝试使用深度学习框架Tensorflow,用AlexNet、ResNet两种CNN来对MNIST手写数据集进行图像分类。
实验原理
公式

ReLU Nonlinearity(Rectified Linear Unit)
卷积层使用ReLU代替sigmoid作为激活函数,加快收敛速度。Rectify指取不小于0的数。
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
Local Response Normalization(局部响应归一化)
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化,也就是Local Response Normalization。局部响应归一化的方法如下面的公式:
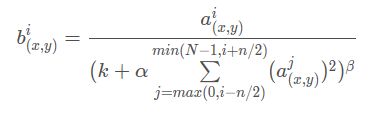 k = 2 , n = 5 , α = 1 0 − 4 , β = 0.75 k=2, n=5,\alpha=10^{-4},\beta=0.75 k=2,n=5,α=10−4,β=0.75
k = 2 , n = 5 , α = 1 0 − 4 , β = 0.75 k=2, n=5,\alpha=10^{-4},\beta=0.75 k=2,n=5,α=10−4,β=0.75
AlexNet
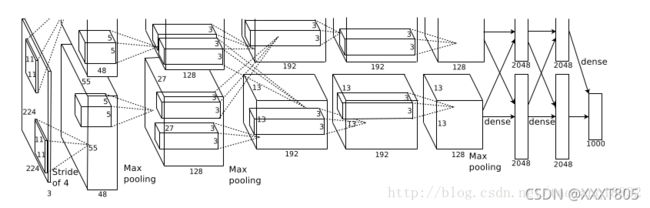
AlexNet总共包含8层,其中有5个卷积层和3个全连接层,有60M个参数,神经元个数为650k,分类数目为1000。
- Conv1:

输入图像规格为224 * 224 * 3,卷积核大小为11 * 11,卷积核个数为48 *2 = 96,步长为4,padding为[1,2],分为两组使用GPU并行运算。由于边缘像素无法进行卷积计算,卷积后的输出的图像大小 N = [224-11+(1+2)] / 4 + 1 = 55,深度为48 * 2 = 96,因此输出为55 * 55 * 96。 - MaxPooling1

输入为55 * 55 * 96,卷积核大小为3 * 3,步长为2,padding为0,输出为27 * 27 *96. - Conv2:
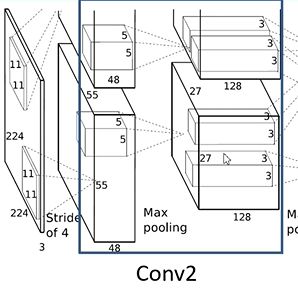
输入为27 * 27 * 96,卷积核个数为128 * 2 = 256,卷积核大小为5 * 5,步长为1,padding为[2,2],则卷积后的输出为27 * 27 * 256. - MaxPooling2
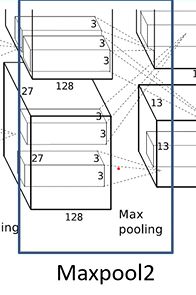
输入为27 * 27 * 256,卷积核大小为3 * 3,步长为2, padding为0,输出为13 * 13 * 256. - Conv3
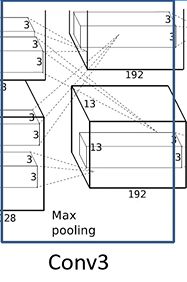
输入为13 * 13 * 256,卷积核个数为192 * 2 = 384,卷积核大小为3 * 3,步长为1,padding为[1,1],输出为13 * 13 * 384. - Conv4
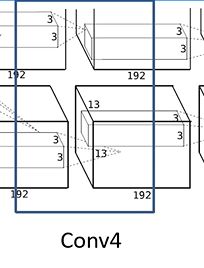
输入为13 * 13 * 384,卷积核个数为192 * 2 = 384,卷积核大小为3 * 3,步长为1,padding为[1,1],输出为13 * 13 * 384. - Conv5
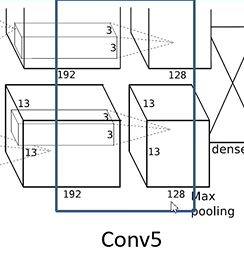
输入为13 * 13 * 384,卷积核个数为128 * 2 = 256,卷积核大小为3 * 3,步长为1,padding为[1,1],输出为13 * 13 * 256. - MaxPooling3
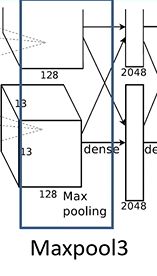
输入为13 * 13 * 256,卷积核大小为3 * 3, padding为0,步长为2,输出为6 * 6 * 256. - fc1:输入为6 * 6 * 256,采用66256尺寸的过滤器对输入数据进行卷积运算,每个过滤器对输入数据进行卷积运算生成一个结果,通过一个神经元输出,设置4096个过滤器,所以输出结果为4096。过程中设置了Dropout,随机去掉一些神经元节点。
Dropout:
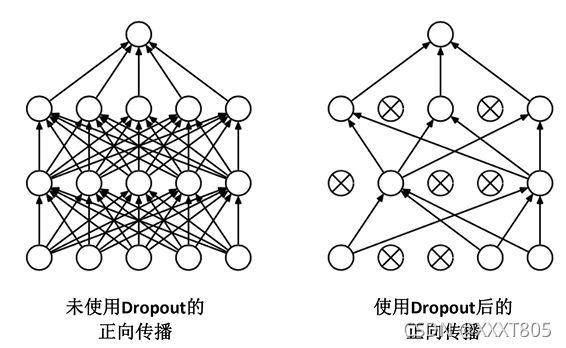
- fc2:将输入的4096个数据与4096个神经元进行全连接,过程中同样设置了dropout。
- fc3:输入为4096,输出为1000(类别数目)。
ResNet
残差结构
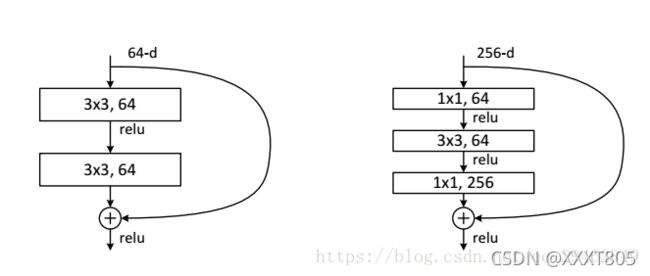
左边的结构适用于层数较少的ResNet(如ResNet-34),输入主分支为两个卷积核为3 * 3的卷积层,得出的特征矩阵与输入的特征矩阵相加,之后通过relu函数得到输出。注意,主分支与侧分支(shortcut)的输出特征矩阵shape必须相同。
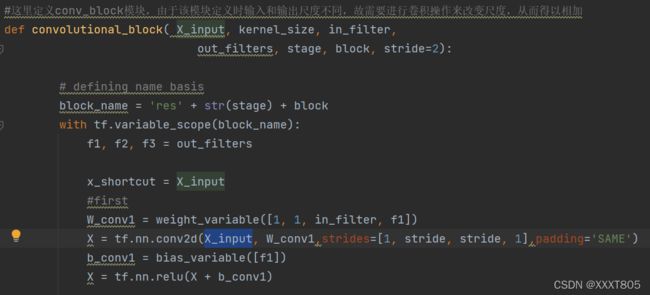
右边的适用于层数较多的(如ResNet-50/101/152),主分支有3个卷积层,1*1卷积层用于降维和升维,保持精度又减少计算量。
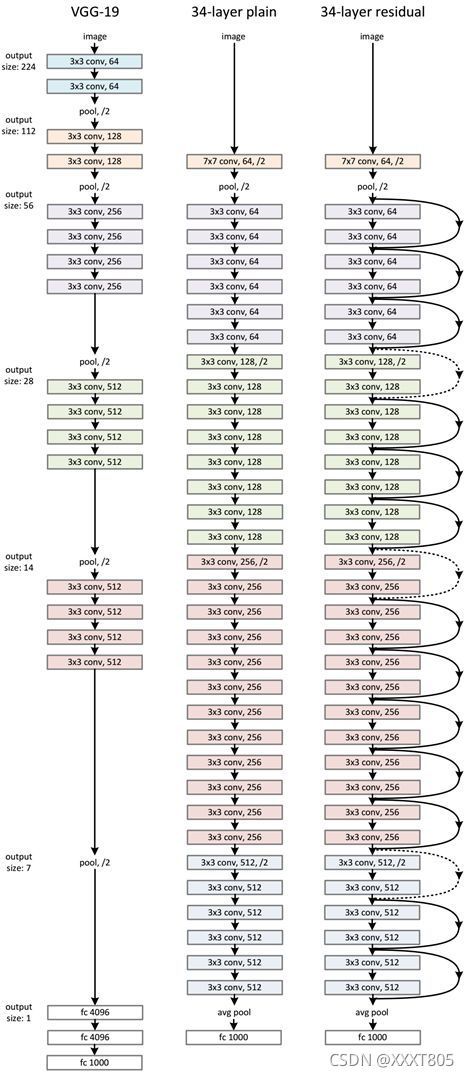
ResNet的网络结构
通过卷积层、池化层、一系列残差结构,最后经过一个平均池化层以及一个全连接层得到最终输出。
实验过程
配置环境
Tensorflow的安装配置
MINIST手写数据集的读取
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 输入数据
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)AlexNet
将代码实现分为三个过程,读取数据、定义网络模型、训练数据和评估模型。
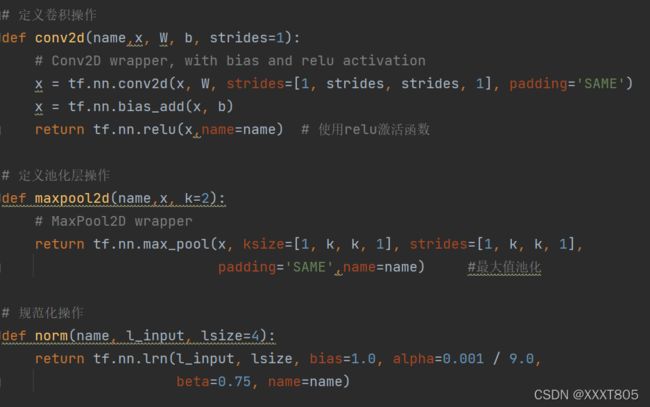
- 定义卷积操作、池化操作、规范化操作以及参数。
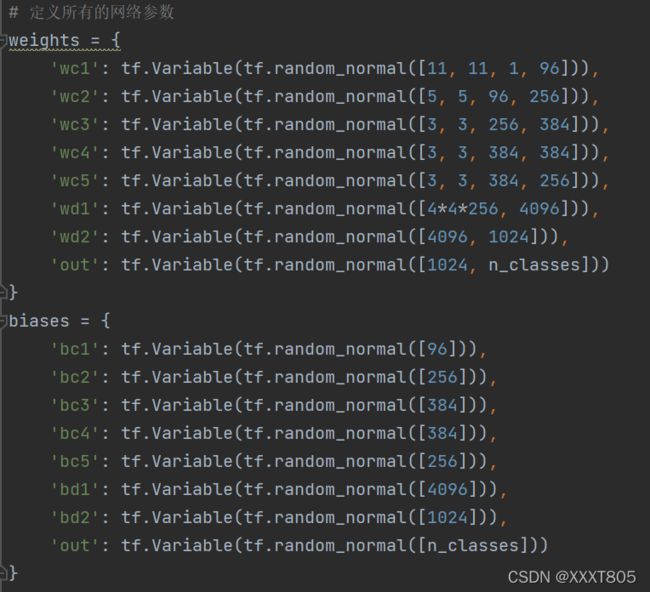
- 定义AlexNet模型
- 定义损失函数、优化器和评估函数
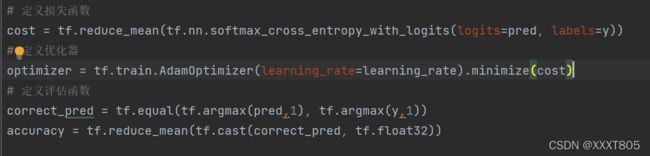
- 训练模型和测试模型
ResNet
- 初始化变量
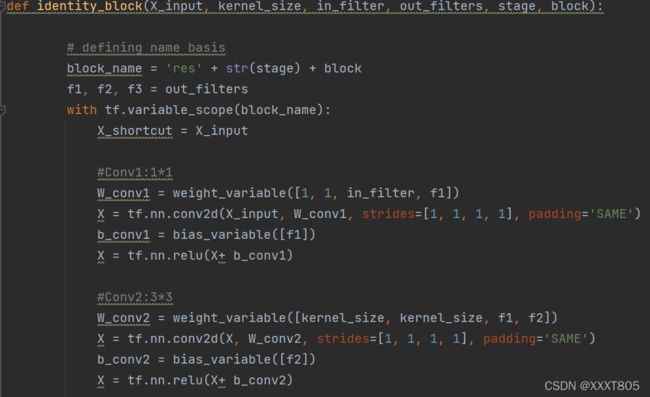
- 定义残差网络的id_block块,包含3个卷积层。
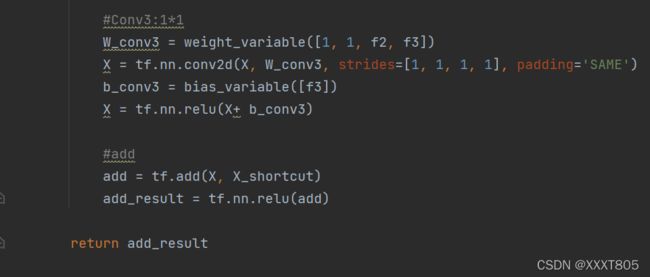
- 定义conv_block,也包含3个卷积层。
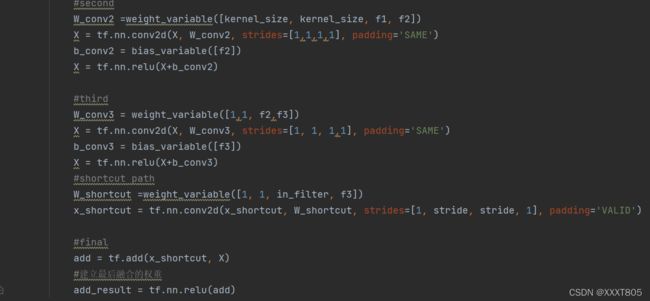
- 定义相关函数
- dropout函数

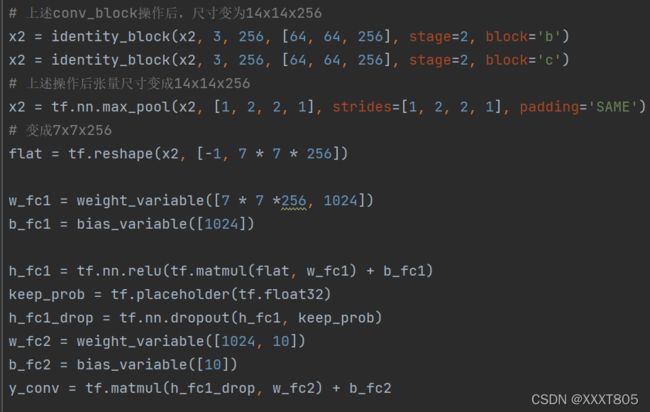
- 损失函数,使用交叉熵计算

- 训练模型和测试模型
实验结果以及分析
AlexNet
实验结果
观察到训练集准确率随迭代次数增加逐渐增加,最后趋于稳定,迭代19840次后测试集准确度达到0.91406;迭代20000次后测试集准确度为0.91796875。
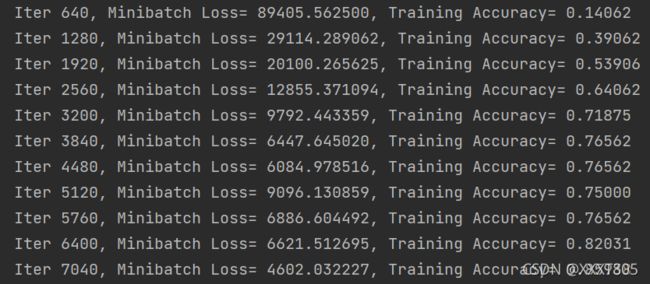
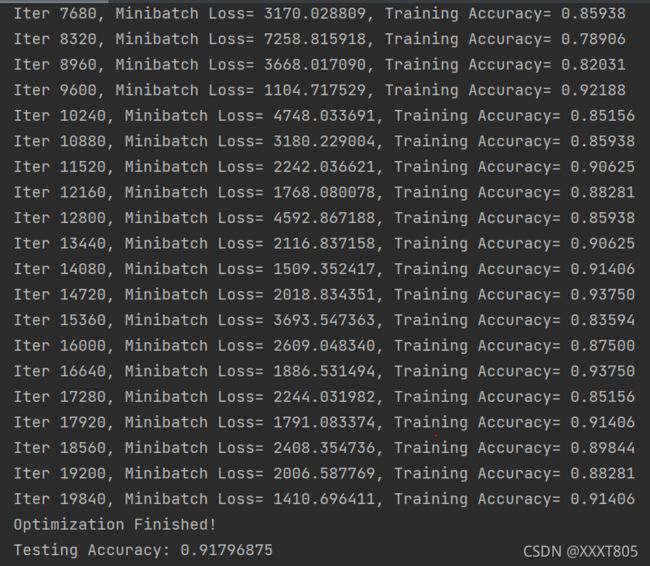
神经网络结构分析
AlexNet将CNN用到了更深更宽的网络中,效果分类的精度更高相比于以前的LeNet,优势主要在于:
- 使用了非线性激活函数ReLU:AlexNet使用ReLU代替了Sigmoid,能加快训练的同时解决sigmoid在训练较深的网络中出现的梯度弥散问题。
- Dropout随机失活:AlexNet在后面的三个全连接层中使用Dropout,随机忽略一部分神经元,以避免模型过拟合。
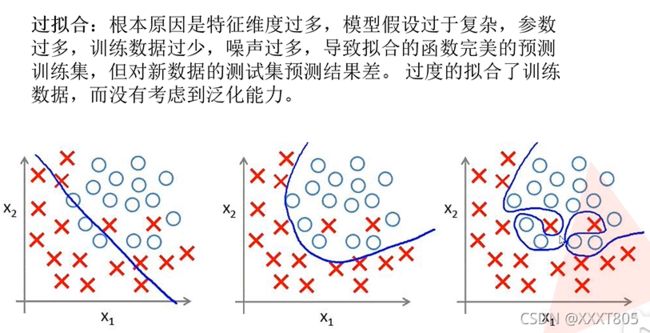
- 数据增广(data agumentation):随机地从256256的原始图像中截取224224大小的区域,相当于增加了2048倍的数据量,以避免模型过拟合。
- 重叠的最大池化层:在CNN中使用重叠的最大池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层:局部响应归一化,LRN一般用在激活和池化函数后,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 首次使用了GPU加速计算:使用CUDA加速深度神经卷积网络的训练。
ResNet
实验结果
训练集准确率随迭代次数增加逐渐增加,在迭代次数4300次后趋于稳定。
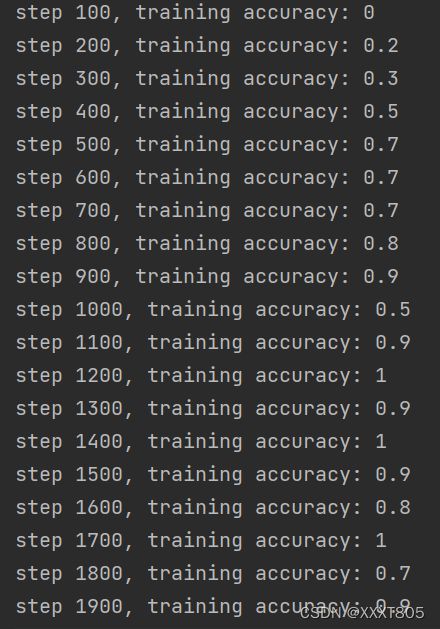
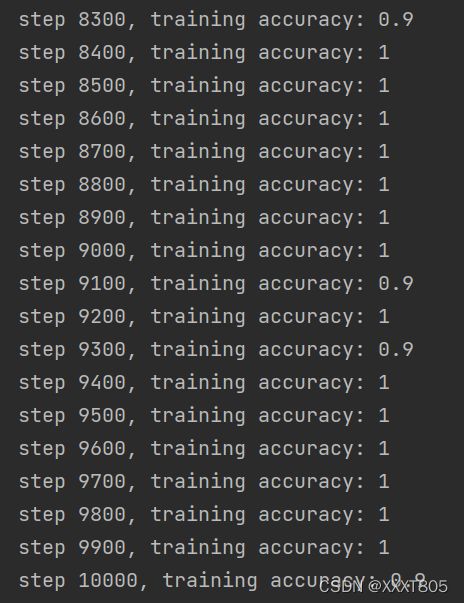
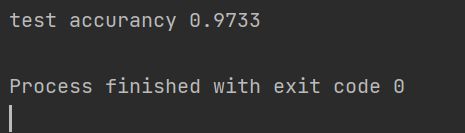
最终测试准确度为0.9733.
神经网络结构分析
- ResNet允许神经网络更深。
- 提出residual(残差)模块,解决了网络模型的退化问题。
- 丢弃了Dropout,使用Bath Normalization加速训练,标准化处理数据,避免梯度消失或梯度爆炸。