决策树的创建与分类
决策树的创建与分类
- 决策树的定义
决策树(Decision Tree)是一种基本的分类与回归方法 。 - 工作原理
由判断模板到终止模板的流程,类似与你问我答的小游戏,答案也是只能用对或错回答,下图表示原理
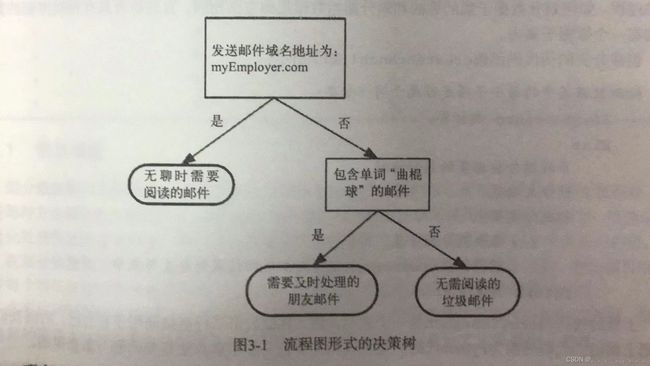
- 优点
计算复杂度不高,输出易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。 - 缺点
可能会产生过度匹配问题 - 适用数据类型
数值型和标称型 - 决策树的构造
(1)收集数据:可以使用任何方法。
(2)准备数据:树构造算法只适用于标称型数据,因此数据型数据必须离散化。
(3)分析数据:可以使用任何方法,构造数据完成之后,我们应该检查图形是否符合预期。
(4)训练算法:构造树的数据结构。
(5)测试算法:使用经验树计算错误率。
(6)使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。 - 信息增益
在划分数据集之前之后信息发生的变化
计算信息增益需要了解熵(信息的期望值)
 - 决策树的实现
- 决策树的实现 - 收集数据

- 构造数据集
我们把不浮出水面是否生存和是否有脚蹼用(0,1)表示,属于鱼类用(yes,no)表示。
def createDataSet():
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['no surfacing ','flippers']
return dataSet,labels
- 计算熵值
import operator
from numpy import *
from math import log
def createDataSet():
data=[[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
feature_label=['no surfacing','flippers']
return data,feature_label
def calshang(dataSet):
numEntry=len(dataSet) #统计所有实例数
label_list=[example[-1] for example in dataSet] #遍历每一行元素,取每一行最后一个元素构成标签列表。['yes', 'yes', 'no', 'no', 'no']
classCount={} #创建字典,对数据集中分类情况进行统计。
for label in label_list:
if label not in classCount.keys():
classCount[label]=0
classCount[label]+=1
# print(classCount) #{'yes': 2, 'no': 3}
shang=0.0
for key in classCount: #遍历类别字典,计算熵值
prob=classCount[key]/numEntry #float(classCount[key])/numEntry
shang+=-prob*log(prob,2)
return shang
dataSet,feature_label=createDataSet()
print('原始数据集为 %s'%(dataSet))
print('特征名称为:%s'%(feature_label))
print("熵为:")
print(calshang(dataSet))
结果显示:

- 划分数据集函数:
def split_dataSet(dataSet,featureX_axis,value):
reduced_dataSet=[] #划分后的数据集
for data in dataSet:
if data[featureX_axis]==value: #特征X值为value的,划分到一个子集中
reduced_data=data[0:featureX_axis]
reduced_data.extend(data[featureX_axis+1:]) #去除特征X对应的列
reduced_dataSet.append(reduced_data)
return reduced_dataSet
##测试函数功能
dataSet,feature_label=createDataSet()
split_dataSet(dataSet,1,1) #以索引为1的特征(是否有脚蹼)进行划分,返回特征对应为1的数据样本。注意:返回的数据中只剩下一个特征(索引为0的特征,即"不浮出水面是否可以生存"),因为以索引为1的特征进行划分,接下来的划分中不能再使用这个特征,所以数据会减少一个特征。
print(split_dataSet(dataSet,1,1))
结果显示:
![]()
- 特征提取
def chooseBestSplit(dataSet):
num_dataSet=len(dataSet) #计算划分前的数据集的实例个数
num_feature=len(dataSet[0])-1 #计算划分前的数据集的特征个数
base_shang=calshang(dataSet) #计算划分前的数据集的熵
bestInfoGain=0.0 #初始化信息增益为0
bestFeature=-1 #记录最佳划分的特征的索引
for i in range(num_feature): #遍历所有特征,寻求最佳特征划分
feature=[example[i] for example in dataSet] #得到第i个特征,对应的所有实例的数据
uniqueValue=set(feature) #第i个特征所有可能的取值
newEntropy=0.0
for value in uniqueValue: #遍历第i个特征所有可能的取值,计算按照第i个特征划分后数据集的信息熵
subDataSet=split_dataSet(dataSet,i,value)
prob=len(subDataSet)/float(num_dataSet)
newEntropy+=prob*calshang(subDataSet)
infoGain=base_shang-newEntropy #计算按照第i个特征划分后数据集的信息增益
print("以索引为"+str(i)+"的特征进行划分,信息增益为:"+str(infoGain))
if infoGain>bestInfoGain:
bestInfoGain=infoGain
bestFeature=i #记录最佳划分特征索引号
#print("bestFeature is %d" %(bestFeature))
return bestFeature
###函数功能测试
myDat,label=createDataSet()
bestFeature=chooseBestSplit(myDat)
print("bestFeature index is %d" %(bestFeature))
结果显示:
![]()
由结果得出:先选择特征”不浮出水面是否可以生存“时,对应的信息增益要大于选择特征”是否有脚蹼"“。