Python POST 爬虫爬取掘金用户信息
Python POST 爬虫爬取掘金用户信息
1. 概述
Python第三方库requests提供了两种访问http网页的函数,基于GET方式的get()函数和基于POST方式的post()函数。
get函数是最为常用的爬取方式,可以获取静态HTML页面和大部分动态加载json文件,但有一些网站对部分数据文件进行了加密处理,不能使用get来获取到文件内容,此时就需要使用post函数来进行获取。例如本文中所要爬取的掘金网站的用户信息。
POST方式与GET方式最主要的区别在于POST在发送请求时会附上一部分参数,服务器根据参数来选择返回给客户的内容。因此在使用post函数时,一大重要之处在于构造参数。有一部分网站会对参数进行加密,这种时候就需要通过观察和一些常用解密方法来进行解密,常用的加密方法包括base64、Hex以及压缩等方法,本文破解的掘金网站参数是使用了base64加密。
综上,本文通过post函数构造加密参数获取了掘金五个主要分类下面的5000页文章信息并从中提取出作者的个人用户信息,去掉重复信息,共获取16598条个人用户信息。
2. 网页观察
掘金,https://juejin.cn/,国内知名极客平台、程序员社区,掘金中有非常多的技术大牛,通过获取掘金的用户信息,我们可以提取出非常多关于国内程序员现状的有价值信息。
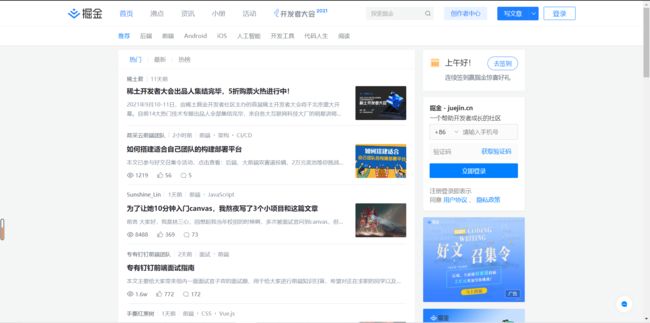
观察掘金首页,会发现没有直接的用户展示页面,因此,要获取大量用户数据,我们拟定通过获取文章作者信息的方式来获取用户数据。掘金首页有若干个标签分类,每一个标签分类会展示若干篇文章,我们计划主要针对“后端”,“前端”,“Android”,“iOS","人工智能”五个标签分类来获取。
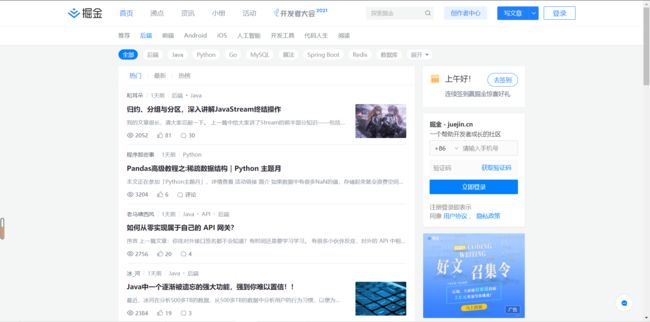
进入“后端”页面,下拉到尽头,发现该网页的文章加载并不是通过静态翻页的形式,而是动态加载json文件的形式。
F12检查,进入network,下拉加载新的文章:
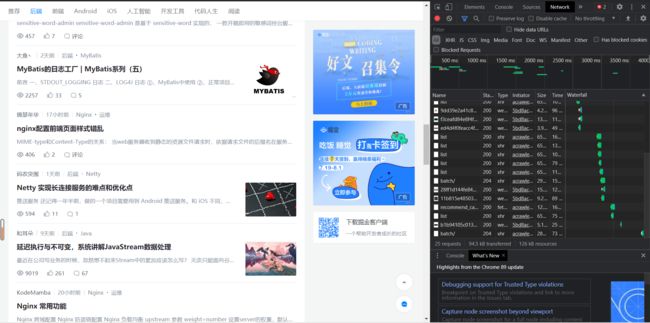
观察加载出来的新文件,发现一个新文件“recommend_cate_feed”:
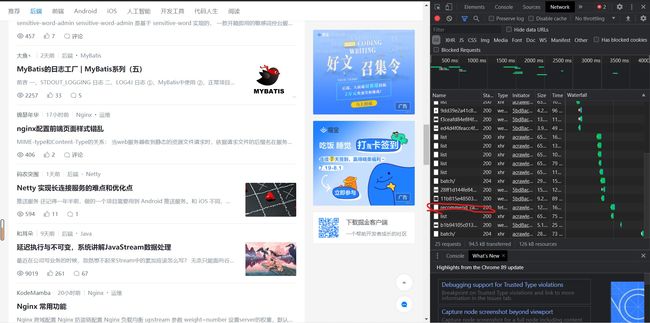
点击该文件,选择Preview板块,发现为一个字典,其中有若干个键,打开data键,发现其中包含有若干文章信息,可以确定此文件即为我们所需要的文件:
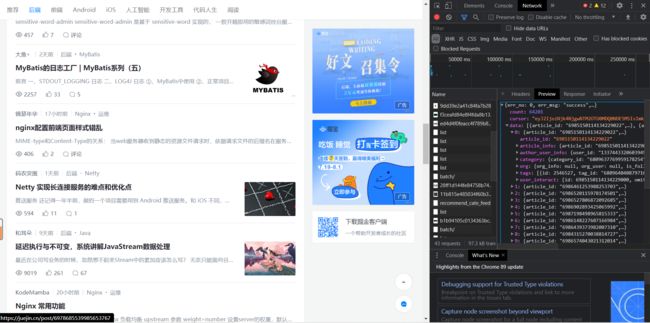
直接打开此链接网站,网页显示“404”,不能直接通过GET访问,需要使用POST方式来访问。
然后我们继续下拉窗口,加载新的文件,对比之前的文件发现,两者的链接网址都一样,不同之处在于POST发送的参数中的cursor值不同:

(原文件整体信息)
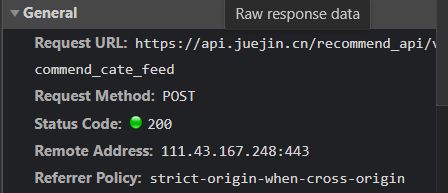
(新文件整体信息)
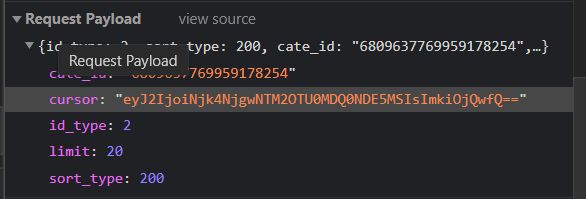
(原文件参数)
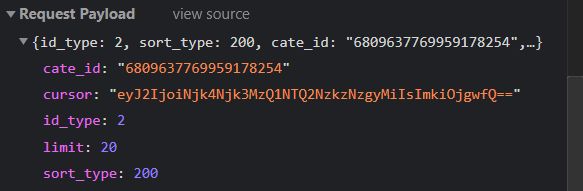
(新文件参数)
因此我们可以推测出控制翻页和类别标签的参数都是cursor,可以看出cursor是加密过后的值,如要使用其模拟翻页需要对其进行解密。
3. 数据提取
从上文中我们获取到了所需信息的网址位置,接下来我们准备使用Python来试爬取,并对其参数进行解密。
首先导入所需库:
import requests #用于数据获取
import pandas as pd #用于数据存储
将上文中找到的网址作为目标网址;
url = r"https://api.juejin.cn/recommend_api/v1/article/recommend_cate_feed"
先将上文查看到的文件中的所有参数都复制下来作为POST参数(Request Payload中的信息):
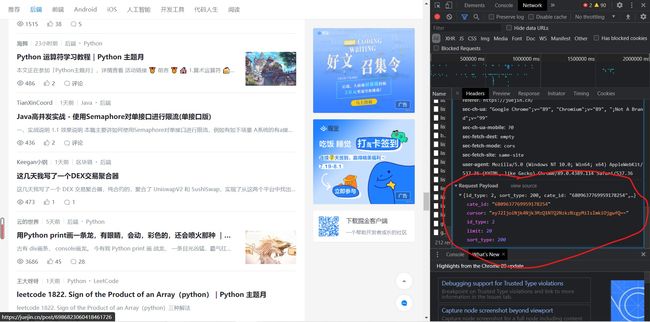
复制成字典类型:
p = {'id_type': 2, 'sort_type': 200, 'cate_id': '6809637769959178254', 'cursor': 'eyd2JzogJzY5ODY2NTI5MjU5NjM1MzQzNTAnLCAnaSc6IDYwfQ==', 'limit': 20}
再构造请求头,POST请求一般必备的请求头包括:user-agent, accept-encoding, accept-language, content-length和content-type。
将上述几项从Request Headers中复制成字典:

header = {"user-agent": "Mozilla/5.0",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
注意:有时读取到的可能是乱码,进行encoding转化的测试之后发现是因为请求头中支持br压缩编码,返回的编码是使用br压缩之后的,而requests默认解压缩只支持gzip。进行解压缩较为麻烦,直接将请求头中支持压缩编码的部分去掉,仅接受gzip压缩。
所以请求头构造如下:
header = {"user-agent": "Mozilla/5.0",
"accept-encoding": "gzip",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
然后使用post函数获取其内容,存储其json格式内容,打印出来观察:
r = requests.post(url, data = json.dumps(p), headers = header)
js_lst = r.json()
print(js_lst)
打印如下:
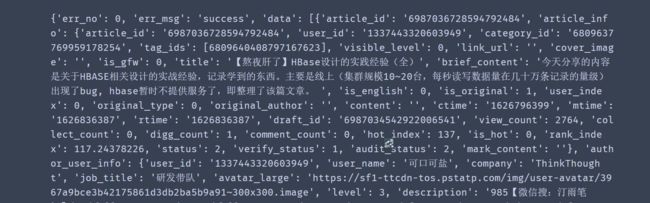
观察数据,发现我们需要的数据存储在data值之中,为一个列表,列表里每一篇文章为一个元素。再深入js_lst[“data”]观察,发现作者信息存储在author_user_info值之中,并作为字典存储了作者的诸多用户信息,将我们关心的数据提取出来:
for item in js_lst["data"]: #遍历每一篇文章
info_dic = item["author_user_info"] #作者信息存储的字典
if info_dic["user_id"] not in id_lst: #检查id来判断该作者信息是否已经被读取
id_lst.append(info_dic["user_id"]) #id
user_info = {} #存储提取后作者信息的字典
user_info["id"] = info_dic["user_id"] #id
user_info["name"] = info_dic["user_name"] #用户名
user_info["company"] = info_dic["company"] #所在公司
user_info["job"] = info_dic["job_title"] #职业
user_info["level"] = info_dic["level"] #用户等级
user_info["descrip"] = info_dic["description"] #个人简介
user_info["fans"] = info_dic["followee_count"] #粉丝数
user_info["stars"] = info_dic["follower_count"] #关注数
user_info["articles"] = info_dic["post_article_count"] #原创文章数
user_info["get_like"] = info_dic["got_digg_count"]#点赞数
user_info["views"] = info_dic["got_view_count"] #浏览量
info_lst.append(user_info) #将该用户的信息加入到用户列表
此处使用了将爬到的每一个用户的id都存入一个列表,在每一次爬取中先判断此时爬取的用户id是否在列表中,来避免重复爬取。
4.参数构造
接下来我们来构造参数实现多页面的爬取。
根据上文分析,POST请求时需要附带的参数共有五个:id_type, sort_type, cate_id, cursor以及limit。
根据上文对不同文件进行分析,再对不同类型的页面进行参数对比,我们得到id_type、sort_type和limit都是不需要改变的参数,直接使用上文中的即可。而cate_id控制了内容的分类(后端、前端等),cursor控制了翻页。
由于我们的目标类别只有主要的5种类别,因此我们直接获取五个类别的cate_id即可。较为麻烦的参数为cursor,可以看出其是经过加密之后的值,我们需要先将其解密。
根据cursor值的特点,我们推测其使用base64加密编码,尝试使用base64对上文的cursor进行解码:
import base64 #导入base64库
print(base64.b64decode(b'eyJ2IjogIjY5ODY2NTI5MjU5NjM1MzQzNTAiLCAiaSI6IDIwfQ==')) #打印解码之后的内容

可以看出确实是使用base64编码加密。
通过对几个不同的文件参数解码之后对比,我们可以得出结论:解码之后的v是类型值,而i是页数,i从20开始,以40为单位。
对于v,由于其与上文的类型数cate_id并不相同,我们人工获取五个目标类别的v参数,并存成字典:
cate_dict = {
"后端": ["6809637769959178254","6986652925963534350"],
"前端": ["6809637767543259144","6986785259966857247"],
"安卓": ["6809635626879549454","6986154038312042504"],
"人工智能": ["6809637773935378440","6986885294276476958"],
"IOS": ["6809635626661445640", "6986425314301870094"]}
然后我们选择对应的v和i进行编码,查看对比编码是否正确。
for key in list(cate_dict.keys()): #遍历每一个类别
cate_id = cate_dict[key][0] #cate_id
cate_password = cate_dict[key][1] #v
for page in range(20, 40060, 40): #控制翻页
encode_dic = {} #需要编码的cursor原始形式是一个字典
encode_dic["v"] = cate_password
encode_dic["i"] = page
#编码
cursor = base64.b64encode(str(encode_dic).replace("'", "\"").encode()) #j将该字典转化为字符串并将其中的单引号转化为双引号,再编码成字节类型,再使用base64编码
print(cate_id)
print(cursor.decode()) #打印编码出来的结果,使用字符串显示
编码结果如下:

注意此处涉及到的一个小技巧。因为Python同时支持单引号和双引号,且默认为单引号,所以将字典转化为字符串之后,字典中的项使用单引号。但正确参数解码之后的字典为双引号,因此需要将字符串之中的单引号使用replace函数转化为双引号,否则编码出来的结果不正确
从而我们就构造好了所需的参数。
5. 结果存储
构造好参数,提取好数据之后,我们就可以进行大批量爬取了。由于是爬取的动态API接口,因此一般不会因为爬取速度过快被检测到,不需要进行休眠。为保证质量,也可以适当进行休眠。
最后涉及到的一个问题是爬取到的数据的存储,因为爬取到的数据量较大,爬取耗时较长,最好是多次写入到csv文件中,从而保证即使在爬取过程中出现网络错误也不至于需要全部重来。
存储数据本文使用pandas库进行存储,将爬取到的列表转化为pandas的DataFrame类型,然后使用to_csv函数即可写入。
data = pd.DataFrame(info_lst) #数据类型转化
data.to_csv(r"juejin.csv")
为实现分批写入,我们在爬取过程中维护一个num变量,每获取一页num加1,当num等于25时将info_lst中的内容写入到文件中,并将info_lst清空以避免造成太大的内存消耗。如此需要使用追加写入,否则每一次写入会清空原有内容,追加写入只需设置mode为a。
if num == 25: #已爬取25页
data = pd.DataFrame(info_lst) #数据类型转化
data.to_csv(r"juejin.csv", mode = "a") #追加写入
info_lst = [] #清空暂存列表
num = 0
print("写入成功")
爬取结果:
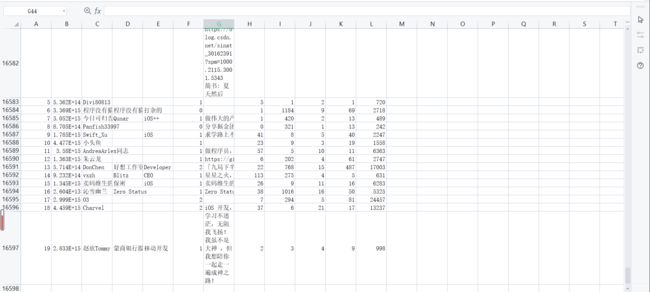
共16598条无重复的用户数据。
6. 源代码:
import requests
import base64
import pandas as pd
num = 0
url = r"https://api.juejin.cn/recommend_api/v1/article/recommend_cate_feed"
p ={"id_type":2,"sort_type":200,"cate_id":"6809637769959178254",
"cursor":"eyJ2IjoiNjk4NjY1MjkyNTk2MzUzNDM1MCIsImkiOjQwMDIwfQ==","limit":20}
header = {"user-agent": "Mozilla/5.0",
"cookie":"MONITOR_WEB_ID=6df3866a-2cab-4818-bb57-e75e971da3f8; _ga=GA1.2.1480397537.1626829211; _gid=GA1.2.1556542559.1626829211",
"accept-encoding": "gzip",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
id_lst = [] #去重所用的id列表
info_lst = [] #暂存结果列表
for key in list(cate_dict.keys()): #遍历每一个分类
cate_id = cate_dict[key][0] #类别号
cate_password = cate_dict[key][1] #v
for page in range(20, 40060, 40): #翻页
time.sleep(random.random()) #休眠0-1的随机时间
encode_dic = {} #cursor参数字典
encode_dic["v"] = cate_password
encode_dic["i"] = page
#编码
cursor = base64.b64encode(str(encode_dic).replace("'", "\"").encode())
#print(cursor)
p["cate_id"] = cate_id
p["cursor"] = cursor.decode()
#print(p)
r = requests.post(url, data = json.dumps(p), headers = header)
#print(r.apparent_encoding)
r.encoding = "utf-8"
#print(r.text)
js_lst = r.json()
for item in js_lst["data"]: #遍历每一篇文章
info_dic = item["author_user_info"] #作者信息存储的字典
if info_dic["user_id"] not in id_lst: #检查id来判断该作者信息是否已经被读取
id_lst.append(info_dic["user_id"]) #id
user_info = {} #存储提取后作者信息的字典
user_info["id"] = info_dic["user_id"] #id
user_info["name"] = info_dic["user_name"] #用户名
user_info["company"] = info_dic["company"] #所在公司
user_info["job"] = info_dic["job_title"] #职业
user_info["level"] = info_dic["level"] #用户等级
user_info["descrip"] = info_dic["description"] #个人简介
user_info["fans"] = info_dic["followee_count"] #粉丝数
user_info["stars"] = info_dic["follower_count"] #关注数
user_info["articles"] = info_dic["post_article_count"] #原创文章数
user_info["get_like"] = info_dic["got_digg_count"]#点赞数
user_info["views"] = info_dic["got_view_count"] #浏览量
info_lst.append(user_info) #将该用户的信息加入到用户列表
print("完成第{}/{}页".format(int((page-20)/40), 1000))
num+=1 #爬取页码加1
if num == 25: #每25页存储一次
data = pd.DataFrame(info_lst) #数据类型转化
data.to_csv(r"juejin.csv", mode = "a") #追加写入
info_lst = []
num = 0
print("写入成功")
print("key:{}完成".format(key))
print()
print()