首篇 | M2BEV:统一BEV表征的多摄像头多任务框架(英伟达、香港大学)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
论文链接:https://arxiv.org/pdf/2204.05088.pdf
摘要
本文提出统一框架M2BEV,可以在BEV空间中与多镜头图像联合实现3D目标检测和BEV分割。与之前工作的区别在于,M2BEV使用一个模型输出两个任务并提高了效率。M2BEV有效地将多视图2D图像特征转换为ego-car坐标系中的3D BEV特征。这种BEV表示的重要性在于它可以使不同的任务能够共享单个编码器。M2BEV框架进一步包含了四点重要的设计,其可以在提升性能的同时提升效率:1)一种有效的BEV编码器设计,可以减少体素特征图的空间维度;2)一种动态框分配策略,使用learning-to-match的方式来分配带anchor的3D GT Box;3)BEV centerness re-weighting,通过更大的权重优化远距离预测结果;4)大规模2D检测预训练和辅助任务。本文的实验表明,以上四点设计对缺少深度信息的基于不适定相机的3D感知任务有巨大的好处。M2BEV对内存更友好,允许以更高的分辨率图像输入,并且推理速度更快。nuScenes上的实验表明,M2BEV在3D目标检测和BEV分割任务上均取得了最先进的结果,最好的模型取得了42.5 mAP和 57.0 mIoU。
本文的主要贡献如下:
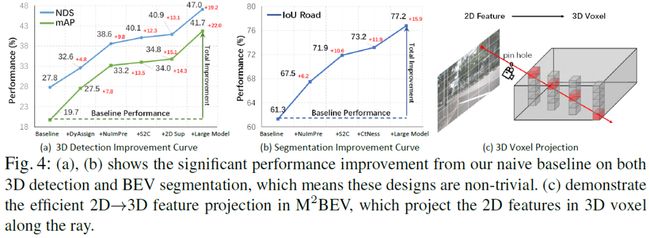
提出了一个统一的框架,将多摄像头图像转换为BEV表示,用于多任务autonomous vehicles(AV)感知,包括3D目标检测和BEV分割。据作者称,这是在单个框架中输出两个任务的首篇工作。
提出了几种新颖的设计,例如高效的BEV编码器、动态框分配和BEV centerness。这些设计有助于提高GPU内存的效率并显著提升算法性能。
本文的实验表明,使用2D标注和2D辅助监督进行大规模预训练可以显著提升3D任务的性能。因此,本文的方法在nuScenes的3D目标检测和BEV分割均实现了最先进的性能,表明BEV表示对于下一代AV感知很有前景。
介绍
现有基于摄像头的算法不适合360°多任务的AV感知,本文以三种主流的基于摄像头的方法展开说明:1)单目3D目标检测算法,如CenterNet [10]和FCOS3D [7]分别预测每个视图内的3D box。它们需要额外的后处理步骤来融合不同视图的预测结果并去重。这些步骤不稳定且不可导,因此不适合与下游任务进行端到端联合推理;2)基于伪激光雷达的方法,如pseudo-LiDAR [9]。这些方法可以重建具有深度信息的3D体素,但对深度估计中错误信息很敏感,并且通常需要额外的深度真值和训练监督;3)基于Transformer的方法。最近,DETR3D [11]使用了一个Transformer的框架,将3D目标query投影到多视图2D图像上,并使用自上而下的方式与图像特征交互。尽管DETR3D支持多视角的3D检测,但无法输出BEV分割和其他多任务,因为DETR3D只考虑了没有密集BEV表示的目标query。
如下图展示两种不同的方法:上图是传统的任务特定的范式,而下图是M2BEV方法:

方法
M2BEV的算法框架如下图所示:

M2BEV
Overview:M2BEV使用多视图的N个RGB图像和对应的内外参作为输入。输出是目标的3D Box和BEV分割结果。多视角图像首先使用2D主干获取2D特征。然后投影到3D空间构建3D体素。接着将3D体素输入到BEV编码器中获取BEV特征。最后,接上任务特定的head,输出多任务结果。
Part1—2D Image Encoder:使用常见的2D主干网络(ResNet等)和FPN输出不同分辨率的特征图(1/4、1/8、1/16、1/32)。然后将这些特征上采样至1/4原图大小,concatenate后接1x1卷积得到融合后的特征。不同视角的图像分别获取同样大小的特征图,用于下一步投影至3D ego-car坐标系中。
Part2—2D→3D Projection:2D→3D投影是本文多任务训练的核心模块。N个相同大小的多视角特征图组合并投影到3D空间获取体素特征,如下图(c)所示。
Part3:—3D BEV Encoder:给定输入的4D体素,需要使用BEV编码器来降维并输出BEV特征图。直观的想法是在Z轴上使用几个stride=2的3D卷积,但是这种方式效率很低。因此,本文使用一个新颖的Spatial to Channel(S2C)算子将4D张量降维到3D。
Part4:—3D Detection Head:得到统一的BEV特征后,就可以使用一些经典的head进行3D目标检测。本文使用PointPillars [1] 的检测头,与其不同的是,M2BEV提出了一种动态框分配的策略分配GT的anchor。
Part5:—BEV Segmentation Head:分割头也很简单,在BEV特征后接四个3x3卷积,最后使用一个1x1卷积输出2类的预测结果,即可行驶区域和车道线。
Efficient 2D→3D Projection
Preliminary:使用如下的公式将体素坐标投影到2D图像坐标中。P为图像,E为相机外参,I为相机内参,V表示体素张量。
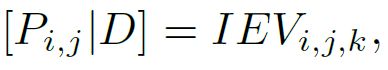
Our Approach:本文假设沿射线的深度分布是均匀的,即沿相机射线的所有体素都填充有与2D中间中单个像素对应的相同特征。这种统一的假设通过减少可学习的参数来提高计算和内存效率。
Improvement Designs
Dynamic Box Assignment:先前的许多工作如PointPillars [1]使用固定的IoU阈值分配GT的Anchor。但这对M2BEV来说是次优解,因为本文的BEV特征没有考虑LiDAR的深度,因此BEV表示可能编码了不太准确的几何信息。受2D目标检测算法FreeAnchor [30] 的启发,M2BEV将其扩展到3D目标检测中。
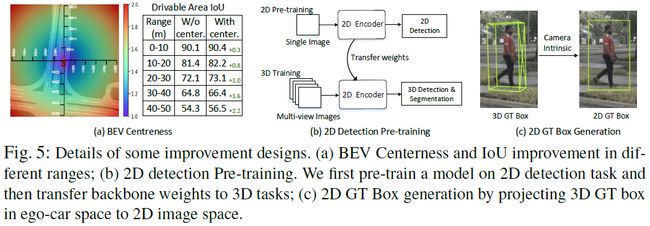
BEV Centerness:“中心”的概念通常用于2D检测器 [17, 31] 以重新加权正样本。本文则使用non-trivial distance-aware的方式将“中心”的概念从2D扩展到3D BEV坐标中。过程如上图a所示。动机是BEV空间中远离自车车身的区域对应图像中更少的像素。所以一个直观的想法是让网络关注更远的区域。具体而言,BEV Centerness定义如下:
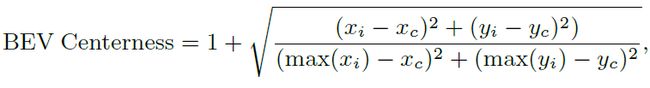
2D Detection Pre-training:本文发现在大规模2D检测数据集上预训练模型,可以明显提升3D性能,如上图b所示。即先使用nuImage数据集训练2D主干网络。在nuScenes上训练时,主干使用上述预训练的模型初始化。
2D Auxiliary Supervision:在获取到图像特征后,本文在不同尺度的特征上添加2D检测头,并使用从ego-car坐标中的3D Box生成2D GT Box计算损失。2D检测头与FCOS中的类似。辅助head只在训练阶段进行,推理时是不用的,因此不会引入额外的计算成本。上图c说明了如何从3D Box生成2D GT Box。
Training Losses
M2BEV的损失包含三项,检测损失、BEV分割损失和2D辅助损失:

实验结果
3D目标检测结果如下所示:

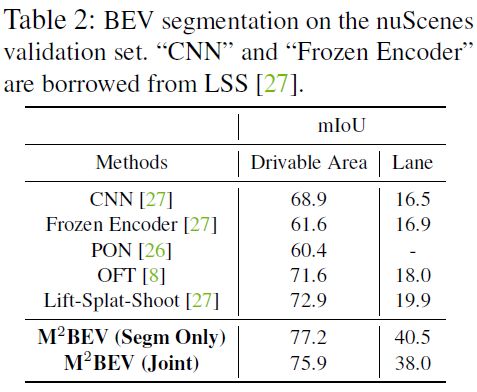
BEV分割结果如下所示:
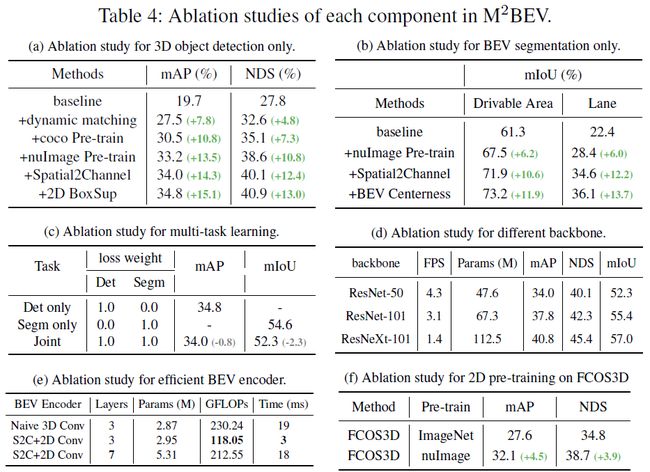
消融实验也很充分:
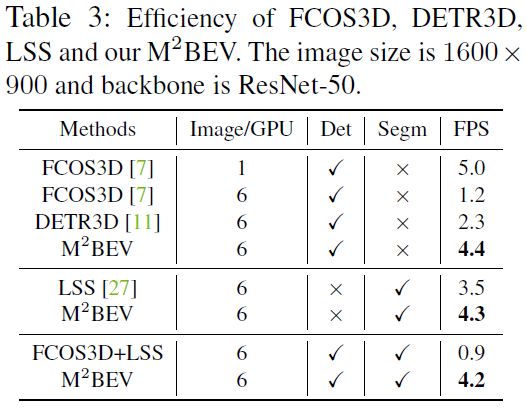
运行时间如下:
对标定错误的鲁棒性分析:

M2BEV的限制
本文提出的 M2BEV 框架并不完美,当路况复杂时,3D检测和BEV分割都存在失败案例,如下图所示。虽然本文的方法在基于相机的方法中优势比较明显,但与基于LiDAR的方法相比仍有很大的改进空间。相机噪声也是现实场景中不可避免的问题,当存在严重的校准误差时,M2BEV也会出现明显的预测质量下降的情况。

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
