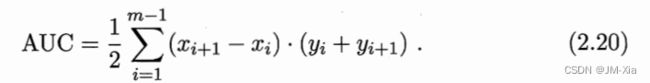【周志华机器学习】 西瓜书吃瓜教程 学习笔记总结Task01
第一章 绪论
1.2 第一章作为引子主要介绍了一些基本术语:
数据集dataset:记录的集合
示例instance/样本sample:关于一个事件或对象的描述
属性attribute/特征feature:反映事件或对象在某方面的表现或性质的事项
属性值attribute value:属性上的取值
属性空间attribute space/样本空间sample space/输入空间:属性张成的空间(以属性为坐标轴的多维空间)
特征向量feature vector:一个示例
并介绍了几个预测的模型运用:其本质是从输入空间到输出空间的映射
1.预测任务:监督学习
离散值的预测 —— 分类classification
连续值的预测 —— 回归regression,y=R
2.分类任务:监督学习
二分类问题binary classification —— 分为正类和反类,y=
或
多分类问题 multi-class classification ,
2
3.聚类clustering:无监督学习,自动形成簇cluster
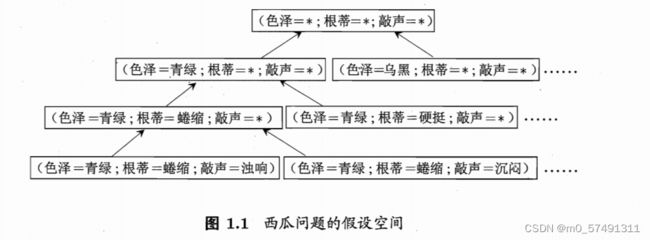
1.3 假设空间 :所有假设hypothesis组成的空间。以西瓜问题为例——
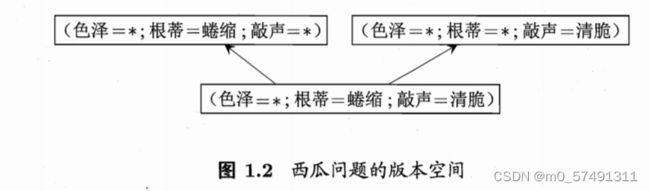
版本空间:一个与训练集一致的“假设空间”
归纳学习inductive learning:从样例中学习的归纳过程,狭义上=概念学习,其中最基本的布尔概念学习,通过0/1布尔值判断。
1.4 归纳偏好
最基本原则——奥卡姆剃刀Occam’s razor:若有多个假设与观察一致,则选最简单的那个。
所以一般选择更平滑的曲线,但其泛化能力更为重要。
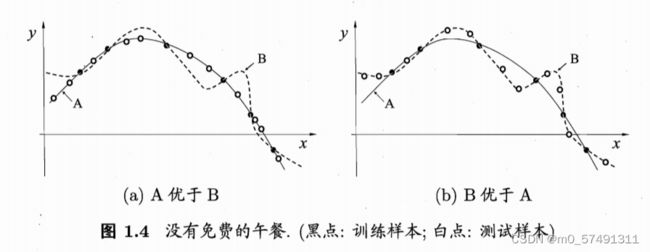
但我们通过对所有可能的f按均匀分布对误差求和 ,发现总误差与学习算法无关!但是NFL定理有一个重要前提是所有f问题出现的机会相同,而实际情况并非如此。
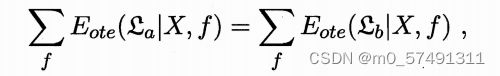
第二章 模型评估与选择
2.1 经验误差与过拟合
错误率(error rate) E=a(分类错误样本)/m(总样本)
精度(accuracy)=1-a/m
训练误差training error/经验误差empirical error:学习器在训练集上的误差
泛化误差generalization error:在新样本上的误差
过拟合overfitting
欠拟合underfitting

2.2 评估方法
用测试集的测试误差作为泛化误差的近似。
【留出法hold-out】:将数据集D划分为两个互斥的集合,一个作为训练集S,另一个作为测试集T。在S上训练出模型后,用T来评估其测试误差。采用分层采样stratified sampling,一般2/3-4/5的样本用于训练。
【交叉验证法k-fold cross validation】:将数据集粗略地分为k个大小相似的互斥子集,即
![]()
然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价。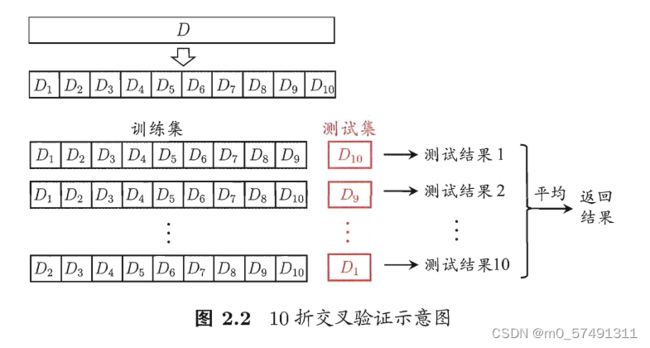
【自助法bootstrapping】:以自助采样bootstrap sampling为基础,计算得出初始数据集中仍约有36.8%的样本未出现在采样数据集中,这样的结果称为包外估计out-of-bag estimate。
【调参parameter tuning】
验证集validation set:用于评估测试的数据集
2.3 性能度量performance measure
2.3.1错误率与精度

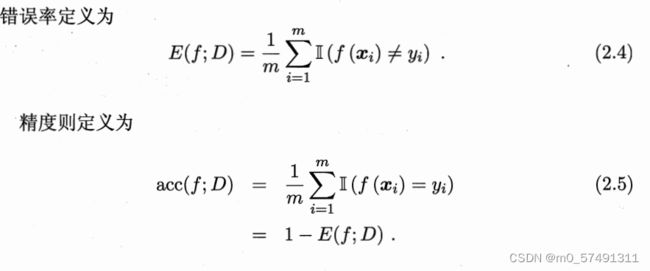

2.3.2查准率、查全率和F1
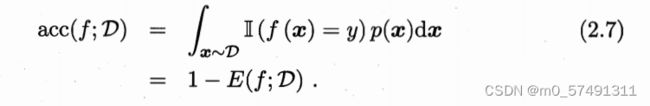


平衡点Break-Event Point(BEP)是P=R时的取值,更常用的还有F1度量
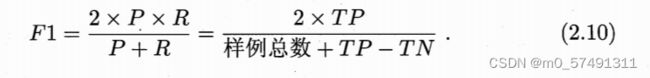
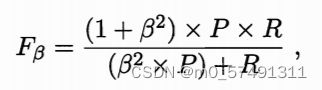
先在个混淆矩阵上分别计算(Pn、Rn)在计算平均值,得到宏查准率macro-P、宏查全率macro-R和宏F1macro-F1
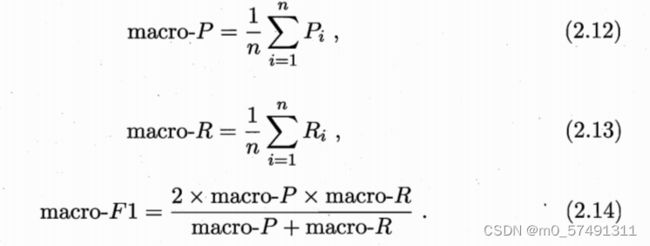


2.3.3ROC与AUC
ROC受试者工作特征(Receiver Operating Characteristic)
其纵轴真正利率TPR(Ture Positive Rate)
横轴假正利率FPR(False Positive Rate)
AUC可通过对ROC曲线下各部分的面积求和而得=1-loss
损失loss则对应的是ROC曲线之上的面积