PyTorch框架
文章目录
- 1. 张量
-
- 1.1 Variable
- 1.2 Tensor
- 1.3 张量的创建
- 1.4 张量的操作
- 1.5 计算图与动态图
-
- 1.5.1 计算图
- 1.6 autograd
-
- 1.6.1 torch.autograd.backward()
- 1.6.2 torch.autograd.gard()
- 1.6.3 autograd 三个要点
- 2. 数据处理
-
- 2.1 数据读取 Dataloader
- 2.2 数据预处理 transforms
-
- 2.2.1 数据增强 Data Augmentation
- 2.2.2 自定义 transforms
- 3. 模型构建
-
- 3.1 nn.Module
- 3.2 模型容器 Containers
-
- 3.2.1 nn.Sequetial
- 3.2.2 nn.ModuleList
- 3.2.3 nn.ModuleDict
- 3.3 卷积层
-
- 3.3.1 卷积维度
- 3.3.2 nn.Conv2d
- 3.4 池化层
-
- 3.4.1 线性层 nn.Linear
- 3.4.2 激活函数层
- 4. 损失函数与优化器
-
- 4.1 权值初始化
-
- 4.1.1 Xavier 方法
- 4.1.2 Kaiming 方法
- 4.1.3 十种初始化方法
- 4.2 损失函数
-
- 4.2.1 熵,交叉熵
- 4.2.2 nn.CrossEntropyLoss()
- 4.3 优化器
-
- 4.3.1 Optimizer
- 4.3.2 学习率
- 4.3.3 Momentum 动量,冲量
- 4.3.4 学习率调整策略
- 5. TensorBoard 与 Hook
-
- 5.1 TensorBorad 可视化
- 5.2 Hook函数
- 6. Regularization 与 Normalization
-
- 6.1 正则化之 weight_decay
- 6.2 正则化之 Dropout
- 6.3 Batch Normalization
-
- 6.3.1 _BatchNorm
- 6.4 Normalization
-
- 6.4.1 Layer Normalization
- 6.4.2 Instance Normalization
- 6.4.3 Group Normalization
- 7. 模型保存与加载
1. 张量
1.1 Variable
Variable 是torch.autograd中的数据类型,主要用于封装Tensor,进行 自动求导。

- data:被包装的 Tensor
- grad:data 的梯度
- grad_fn :创建 Tensor 的 Function,是自动求导的关键
- requires_grad:指示是否需要梯度
- is_leaf:指示是否是叶子节点
1.2 Tensor

Pytorch 0.4.0 开始,Variable 并入Tensor。
- dtype:张量的数据类型,如
torch.FloatTensor,torch.cuda.FloatTensor - shape:张量的形状,如 ( 64 , 3 , 224 , 224 ) (64,3,224,224) (64,3,224,224)
- device :张量所在的设备,GPU/CPU,是加速的关键
1.3 张量的创建
张量创建-参考链接-pytorch中文手册
① 直接创建
- torch.tensor(),从data 创建 tensor
- torch.from_numpy(ndarry),从numpy 创建 tensor,共享内存,当修改一个值时,另一个也将被改动。
② 依据数值创建
- torch.zeros(),依 size 创建全 0 张量
- torch.zeros_like(),依 input 形状创建全 0 张量
- torch.ones()、torch.ones_likes(),依 input 形状创建全 1 张量
- torch.full()、torch.full_likes(),依 input 形状创建 指定数据 的张量
- torch.arange(),创建等差的 1 维张量
- torch.linspace(),创建均分的 1 维张量
- torch.logspace(),创建对数均分的 1 维张量
- torch.eye(),创建单位对角矩阵(2维张量)
③ 依概率分布创建张量
- torch.normal(),生成正太分布
- torch.randn(),生成标准正太分布
- torch.rand(),在区间 [0,1) 上,生成均匀分布
- torch.randint(),生成均匀分布
- torch.randperm(),生成从0~1的随机排列
- torch.bernoulli(),以 input 为概率,生成伯努利分布( 0-1 分布,两点分布)
1.4 张量的操作
张量-索引,切片,连接,换位Indexing, Slicing, Joining, Mutating Ops-参考链接
pytorch实现线性回归小案例-code
1.5 计算图与动态图
1.5.1 计算图
计算图是用来 描述运算 的有向无环图,计算图有两个主要元素: 节点(Node)和 边(Edge)。节点 表示 数据,如向量,矩阵,张量;边 表示 运算,如加减乘除卷积等。
用计算图表示 y = ( x + w ) ⋅ ( w + 1 ) y = (x+w)\cdot(w+1) y=(x+w)⋅(w+1),则可表示为 a = x + w , b = w + 1 , y = a ⋅ b a=x+w, b=w+1, y=a\cdot b a=x+w,b=w+1,y=a⋅b

计算图与梯度求导
∂ y ∂ w = ∂ y ∂ a ∂ a ∂ w + ∂ y ∂ b ∂ b ∂ w = b ∗ 1 + a ∗ 1 = b + a = ( w + 1 ) + ( x + w ) = 2 ∗ w + x + 1 = 2 × 1 + 2 + 1 = 5 \begin{aligned} \frac{\partial y}{\partial w} &=\frac{\partial y}{\partial a} \frac{\partial a}{\partial w}+\frac{\partial y}{\partial b} \frac{\partial b}{\partial w} \\ &=b * 1+a * 1 \\ &=b+a \\ &=(w+1)+(x+w) \\ &=2 * w+x+1 \\ &=2\times1+2+1=5 \end{aligned} ∂w∂y=∂a∂y∂w∂a+∂b∂y∂w∂b=b∗1+a∗1=b+a=(w+1)+(x+w)=2∗w+x+1=2×1+2+1=5
叶子节点:用户创建的结点成为叶子节点,如 x x x 与 w w w
设置 叶子节点 主要是为了节省内存,在梯度反向传播结束之后,非叶子结点的梯度会被释放掉。
- grad_fn :记录创建该张量时所用的方法(函数)
w = torch.tensor([1.], requires_grad=True) # 梯度为1
x = torch.tensor([2.], requires_grad=True) # 梯度为2
a = torch.add(w, x) # retain_grad()保留梯度
# a.retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad) # tensor([5.])
# 查看叶子结点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
# True True False False False
# 查看梯度
print('gradient:\n', w.grad, x.grad, a.grad, b.grad, y.grad)
# tensor([5.]) tensor([2.]) None None None
# 查看grad_fn
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
# None None 1.6 autograd
1.6.1 torch.autograd.backward()
自动求取梯度
torch.autograd.backward(tensors, # 用于求导的张量,如 loss
grad_tensors=None, # 多梯度权重
retain_grad=None, # 保存计算图
create_graph=False) # 创建导数计算图,用于高阶求导
例子:
w = torch.tensor([1.], requires_grad=True) # 梯度为1
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
# a.retain_grad() # retain_grad()保留梯度
b = torch.add(w, 1)
y0 = torch.mul(a, b) # y0 = (x+w) * (w+1) = 6 dy0/dw = 5 y0对 w求梯度,也可看上面
y1 = torch.add(a, b) # y1 = (x+w) + (w+1) = 5 dy1/dw = 2
loss = torch.cat([y0, y1], dim=0) # tensor([6., 5.])
grad_tenors = torch.tensor([1., 2.]) # 多个梯度中权重的设置,y0对应 1,y1对应 2
# gradient 传入 torch.autograd.backward()中的grad_tensors
loss.backward(gradient=grad_tenors)
print(w.grad) # 9 = 1*5 + 2*2
1.6.2 torch.autograd.gard()
求取梯度
torch.autograd.grad(outputs, # 用于求导的张量,如loss
inputs, # 需要梯度的张量
grad_outputs=None, # 多梯度权重
retain_graph=None, # 保存计算图
create_graph=False) # 创建计算图
例子:
x = torch.tensor([3.], requires_grad=True)
y = torch.pow(x, 2) # y = x**2
grad_1 = torch.autograd.grad(y, x, create_graph=True)
# grad_1 = dy/dx = 2x = 2 * 3 = 6
print(grad_1) # (tensor([6.], grad_fn=),)
print(grad_1[0]) # tensor([6.], grad_fn=)
grad_2 = torch.autograd.grad(grad_1[0], x) # 求二阶导
# grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
print(grad_2) # (tensor([2.]),)
1.6.3 autograd 三个要点
- 梯度不自动清零
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
w.grad.zero_() # 手动对梯度进行清零,'_':原位操作。
# tensor([5.])
# tensor([5.])
# tensor([5.])
- 依赖于叶子结点的结点,
requires_grad默认为True
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
- 叶子结点不可执行in-place
in-place 原位操作:在原始内存当中去改变这一数据
为什么叶子节点不能进行in-place操作?
在反向传播过程中需要用到叶子结点。而在前向传播时,要记录叶子结点的地址。到反向传播时根据叶子结点的地址去寻找这个数据,进行使用计算。
a = torch.ones((1, ))
print(id(a), a)
# 1970317858920 tensor([1.])
a = a + torch.ones((1, ))
print(id(a), a)
# 1970369990728 tensor([2.])
# 开辟了新的地址,就不是原位操作,
a += torch.ones((1, )) # 原位操作.在原始地址上改变
print(id(a), a)
# 1970369990728 tensor([3.])
另一个例子
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
w.add_(1)
"""
autograd小贴士:
梯度不自动清零
依赖于叶子结点的结点,requires_grad默认为True
叶子结点不可执行in-place
"""
y.backward() # 报错,叶子结点不可执行in-place
这一节的代码,可查看链接
逻辑回归pytorch实现小案例
2. 数据处理
机器学习训练五大步骤,数据,模型,损失函数,优化器,迭代训练。

2.1 数据读取 Dataloader
torch.utils.data.DataLoader(),数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。参数解释链接
Epoch:所有训练样本都已输入到模型中,成为一个EpochIteration:一批样本输入到模型中,称之为一个IterationBatchSize:批大小,决定一个Epoch有多少个Iteration- 假如有80个样本,设置 BatchSize 为 8,则 1 Epoch = 10 Iteration。
torch.utils.data.Dataset(),Dataset 抽象类,所有自定义的 Dataset 需要继承它,并且复写 __getitem__()。getitem:接收一个索引,返回一个样本。对__getitem__()具体解释可参考链接。
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
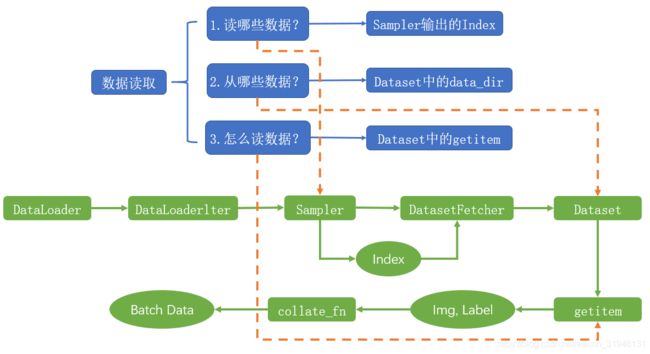
dataloader 划分人民币小案例
2.2 数据预处理 transforms
torchvision.transforms 常用的图像预处理方法,数据中心化,数据标准化,缩放,裁剪,旋转,翻转,填充,噪声添加,灰度变换,线性变换,仿射变换,亮度、饱和度及对比度变换。
transforms.Normalize(),逐channel 的对图像进行标准化, o u t p u t = ( i n p u t − m e a n ) / s t d output = (input-mean)/std output=(input−mean)/std
from torchvision import transforms
transforms.Normalize(mean, # 各通道的均值
std, # 各通道的标准差
inplace=False) # 是否原地操作
2.2.1 数据增强 Data Augmentation
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。
张贤同学 - 二十二种 transforms 图片数据预处理方法 - 参考链接
| 方法 | 功能 |
|---|---|
| transforms.CenterCrop() | 裁剪, 从图像中心裁剪图片 |
| transforms.RandomCrop() | 裁剪, 从图片中随机裁剪出尺寸为size的图片 |
| transforms.RandomResizedCrop() | 裁剪, 随机大小,长宽比裁剪图片 |
| transforms.FiveCrop() | 裁剪, 在图像上下左右以及中心裁剪出尺寸为size的5张图片 |
| transforms.TenCrop() | 裁剪, 对这5张图片进行水平或者垂直镜像获得10张图片 |
| transforms.RandomHorizontalFlip() | 翻转和旋转, 依概率水平或左右翻转图片 |
| transforms.RandomVerticalFlip() | 翻转和旋转, 依概率垂直或上下翻转图片 |
| transforms.RandomRotation() | 翻转和旋转, 随机旋转图片 |
| transforms.Pad() | 图像变换, 对图片边缘进行填充 |
| transforms.ColorJitter() | 图像变换, 调整亮度,对比度,饱和度和色相 |
| transforms.Grayscale() | 图像变换, 依概率将图片转为灰度图 |
| transforms.RandomGrayscale() | 图像变换, 依概率将图片转为灰度图 |
| transforms.RandomAffine() | 图像变换, 对图片进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转,平移,缩放,错切和翻转 |
| transforms.LinearTransformation() | 图像变换, |
| transforms.RandomErasing() | 图像变换, 对图像进行随机遮挡 |
| transforms.Lambda() | 图像变换, 用户自定义Lambda方法 |
| transforms.Resize() | 图像变换, 给定大小缩放 |
| transforms.Totensor() | 图像变换, 转为张量 |
| transforms.Normalize() | 图像变换, 标准化,归一化 |
| transforms.RandomChoice() | transforms的操作, 从一系列transforms方法中随机挑一个 |
| transforms.RandomApply() | transforms的操作, 依据概率执行一组transforms操作 |
| transforms.RandomOrder() | transforms的操作, 对一组transforms操作打乱顺序 |
2.2.2 自定义 transforms
自定义 transforms 要素:
- 仅接收一个参数,返回一个参数
- 注意上下游的输出与输入,上一个transform 的输出是下一个 tranform 的输入
可以通过类实现多参数的传入,这里代码相关解释可参考链接
class YourTransforms(object):
def __init__(self, ...):
...
def __call__(self, img):
...
return img
def Compose(object):
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
椒盐噪声:
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声。
信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中图像像素的占比。值越大(越接近 1),噪声越小。
定义一个AddPepperNoise类,作为添加椒盐噪声的 transform。在构造函数中传入 信噪比 和 概率,在__call__()函数中执行具体的逻辑,返回的是 image。
# 自定义添加椒盐噪声的 transform
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
# transform 会调用该方法
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 如果随机概率小于 seld.p,则执行 transform
if random.uniform(0, 1) < self.p:
# 把 image 转为 array
img_ = np.array(img).copy()
# 获得 shape
h, w, c = img_.shape
# 信噪比
signal_pct = self.snr
# 椒盐噪声的比例 = 1 -信噪比
noise_pct = (1 - self.snr)
# 选择的值为 (0, 1, 2),每个取值的概率分别为 [signal_pct, noise_pct/2., noise_pct/2.]
# 椒噪声和盐噪声分别占 noise_pct 的一半
# 1 为盐噪声,2 为 椒噪声
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
# 再转换为 image
return Image.fromarray(img_.astype('uint8')).convert('RGB')
# 如果随机概率大于 seld.p,则直接返回原图
else:
return img
3. 模型构建

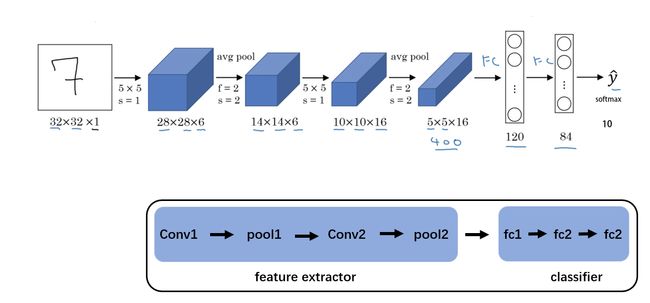
模型创建包括两个要素, 构建子模块 __init__() 和 拼接子模块 forward()。 在 LeNet 中继承nn.Module,必须实现__init__() 方法和forward()方法。其中在__init__() 方法里创建子模块,在 forward() 方法里拼接子模块。
在 LeNet 的__init__()中创建了 5 个子模块,nn.Conv2d()和nn.Linear()都是 继承于nn.module,也就是说一个 module 都是包含多个子 module 的。
class LeNet(nn.Module):
# 子模块创建
def __init__(self, classes): # 父类函数调用
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
# 子模块拼接
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.avg_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
3.1 nn.Module
pytorch神经网络模块 torch.nn 里包含很多子模块,主要以下面四个展开,其具体方法可参考链接。

nn.Module主要包含有8 个属性, 都是OrderDict(有序字典)。在 LeNet 的__init__()方法中会调用父类nn.Module 的__init__()方法,创建这 8 个属性。
nn.Module 代码debug 解释部分 - 参考链接
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict() # 存储管理nn.Parameter类型的参数
self._buffers = OrderedDict() # 存储管理缓存属性,如BN层中的running_mean
self._non_persistent_buffers_set = set()
self._backward_hooks = OrderedDict() # ***_hooks: 存储管理钩子函数
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
self._modules = OrderedDict() # 存储管理 nn.Module类型的参数
nn.Module 使用方法总结:
- 一个 Module 里可以包含多个子 module。比如 LeNet 是一个Module,里面包括多个卷积层、池化层、全连接层等子Module
- 一个 Module 相当于一个运算,必须实现 forward() 运算
- 每个 Module 都有 8 个字典管理自己的属性
3.2 模型容器 Containers
常见的模型容器Containers包含如下:
- nn.Sequetial: 按顺序包装多个网络层。 顺序性, 各网络层之间严格按顺序执行,常用于block构建。
- nn.ModuleList:像python的 list 一样包装多个网络层。 迭代性, 常用于大量重复网构建,通过 for 循环实现重复构建。
- nn.ModuleDict:像python的 dict 一样包装多个网络层。 索引性, 常用于可选择的网络层。
3.2.1 nn.Sequetial
在深度学习中,特征工程的概念被弱化了, 特征提取 和 分类器 这两步被融合到了一个神经网络中。在卷积神经网络中,前面的卷积层以及池化层可以认为是特征提取部分,而后面的全连接层可以认为是分类器部分。比如 LeNet 就可以分为特征提取和分类器两部分,这 2 部分都可以分别使用 nn.Sequetial 来包装。
nn.Sequential 是 nn.module 的容器,用于按顺序包装一组网络层,有以下两个特征:
- 顺序性:各网络层之间严格按照顺序构建
- 自带 forward():自带的 forward 里,通过 for 循环依次执行前向传播运算。
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
初始化时,nn.Sequetial会调用__init__()方法,将每一个子module 添加到 自身的_modules属性中。这里可以看到,传入的参数可以是一个list,或者一个 OrderDict。如果是一个 OrderDict,那么则使用 OrderDict 里的 key,否则使用数字作为 key 。(下图所示)
# container.py
def __init__(self, *args: Any):
super(Sequential, self).__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
网络初始化后,得到两个子Module:features 和 classifier。

在进行前向传播时,会进入 LeNet 的forward()函数,首先调用第一个Sequetial容器:self.features,由于self.features也是一个 module,因此会调用_call_impl(self, *input, **kwargs):函数,里面调用result = self.forward(*input, **kwargs),进入nn.Seuqetial的forward()函数,在这里依次调用所有的 module。具体过程可参考视频链接-模型容器章节。
在nn.Sequetial中,里面的每个子网络层 module 是使用序号来索引的,即使用数字来作为 key。一旦网络层增多,难以查找特定的网络层,这种情况可以使用 OrderDict (有序字典)。(结果如上图所示)
class LenetSequentialOrderDict(nn.Module):
def __init__(self, classes):
super(LenetSequentialOrderDict, self).__init__()
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16*5*5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes)
}))
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
3.2.2 nn.ModuleList
nn.ModuleList 是 nn.module 的容器,用于包装一组网络层,以 迭代 方式调用网络层,主要方法如下:
- append():在ModoleList 后面 添加网络层
- extend(): 拼接 两个ModuleList
- insert():指定在ModuleList 中位置 插入 网络层
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
# 列表生成式,生成20个全连接层,每个全连接层是 10个神经元的网络
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
3.2.3 nn.ModuleDict
nn.ModuleDict 是 nn.module 的容器,用于包装一组网络层,以 索引 方式调用网络层,主要方法如下:
- clear():清空 ModoleDict
- items():返回可迭代的键值对 (Key-value)
- keys():返回字典的键(key)
- values():返回字典的值 (values)
- pop():返回一对键值,并从字典中删除
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU() # prelu:有正有负, relu:仅有正
})
def forward(self, x, choice, act):
x = self.choices[choice](x)
x = self.activations[act](x)
return x
3.3 卷积层
对CNN卷积神经网络的描述可参考这篇博文CNN-卷积神经网络
3.3.1 卷积维度
一般情况下,卷积核在几个维度上滑动,就是几维卷积。下面图片引用链接
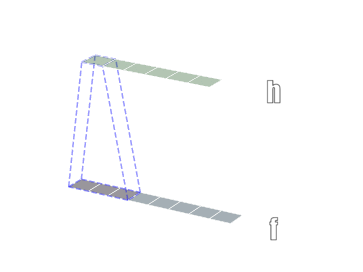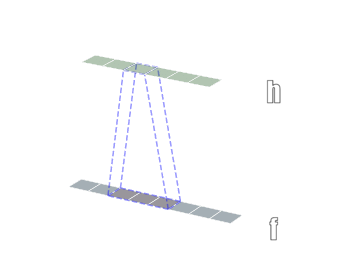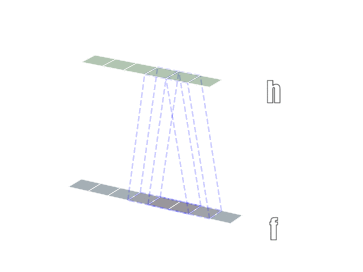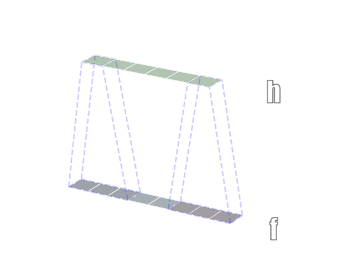
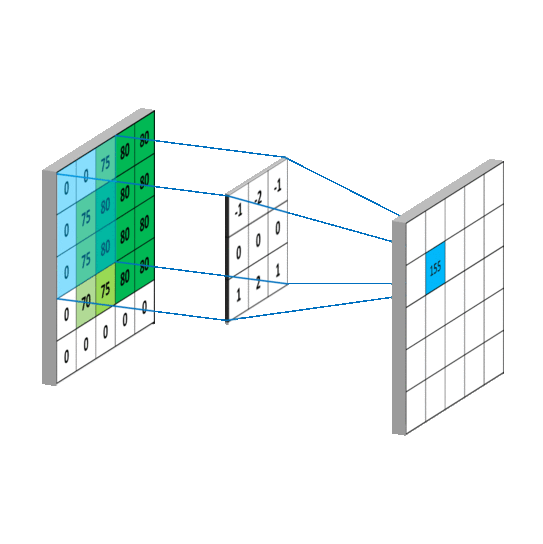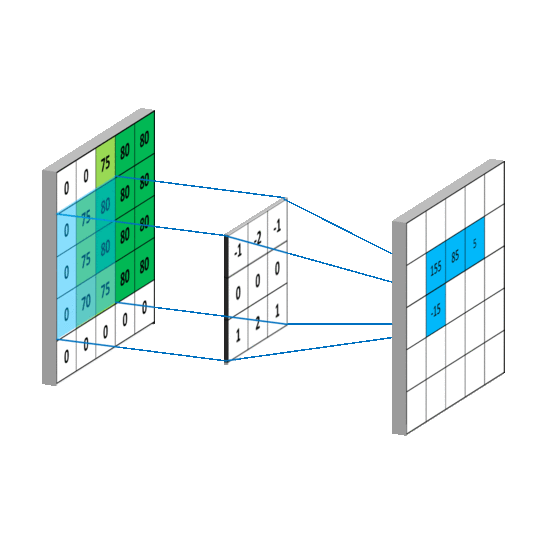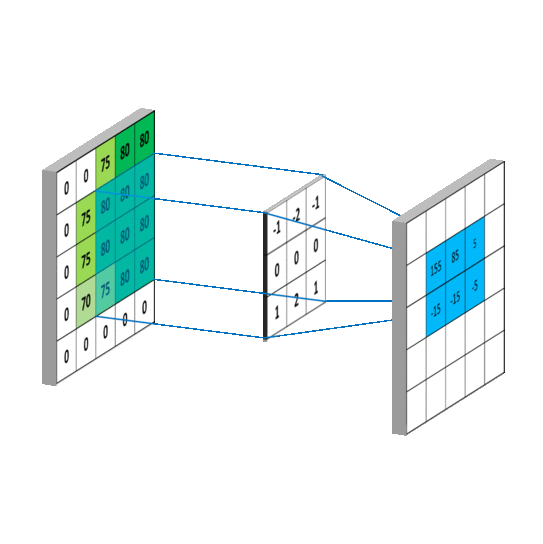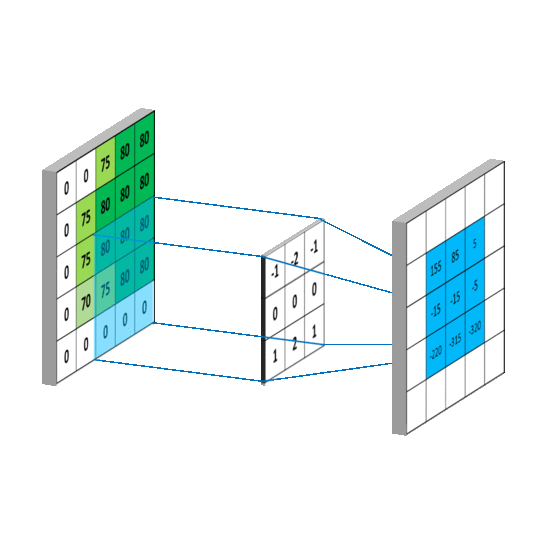

3.3.2 nn.Conv2d
对多个二维信号进行二维卷积
nn.Conv2d(in_channels= , # 输入通道数
out_channels= , # 输出通道数,等价于卷积核数
kernel_size= , # 卷积核尺寸
stride=1, # 步长
padding=0, # 填充个数
dilation=1, # 空洞卷积大小
groups=1, # 分组卷积设置
bias=True, # 偏置
padding_mode='zeros')
转置卷积 Transpose Convolution
转置卷积(nn.ConvTranspose2d)和部分跨越卷积 (Fractionally-strided Convolution),用于对图像进行上采样 。转置矩阵形状上是一个转置关系,权值完全不一样,则正常矩阵与转置卷积是不可逆的。
详细理解可参考这篇博文一文搞懂反卷积,转置卷积
公式推导细节可参考知乎文章 转置卷积(Transpose Convolution)


3.4 池化层
池化层函数参数具体参考链接
nn.MaxPool2d 是对二维信号(图像)进行最大化池化。
nn.MaxPool2d(kernel_size, # 池化核尺寸
stride=None, # 步长
padding=0, # 填充个数
dilation=1, # 池化核间隔大小
return_indices=False, # 记录池化像素索引。记录最大值像素所在位置的索引,在最大值反池化上采样时使用
ceil_mode=False) # 默认为 False,尺寸向下取整。为 True 时,尺寸向上取整
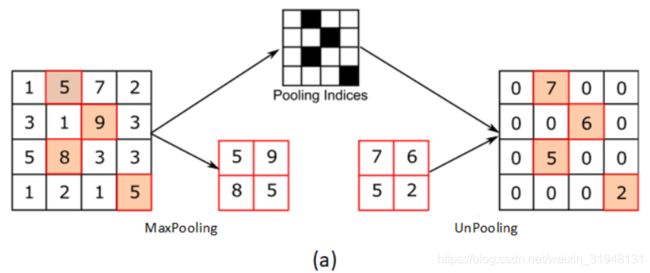
nn.AvgPool2d 是对二维信号(图像)进行平均值池化。
nn.MaxUnPool2d 是对二维信号(图像)进行最大值池化上采样。
3.4.1 线性层 nn.Linear
线性层又称全连接层,其每个神经元与上一层所有神经元相连。实现对前一层的 线性组合, 线性变换。
nn.Linear 对一维信号(向量)进行线性组合。
inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
linear_layer.bias.data.fill_(0.5) # 先测试 0
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)
3.4.2 激活函数层
激活函数对特征进行非线性变换,赋予多层神经网络具有深度 的意义。
激活层描述可以参考之前博文 - 神经网络基础知识。
4. 损失函数与优化器
4.1 权值初始化
梯度消失与梯度爆炸
考虑以下的三层全连接网络。
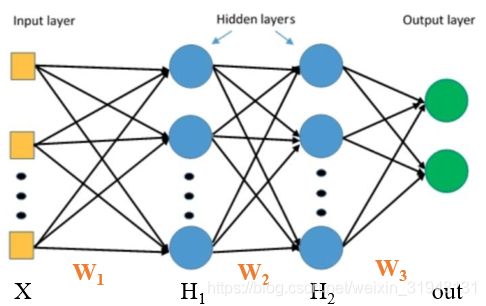
H 1 = X × W 1 H_1=X\times W_1 H1=X×W1, H 2 = H 1 × W 2 H_2=H_1\times W_2 H2=H1×W2, o u t = H 2 × W 3 out=H_2\times W_3 out=H2×W3,第二层的权重梯度
Δ W 2 = ∂ L o s s ∂ W 2 = ∂ L o s s ∂ o u t ∗ ∂ o u t ∂ H 2 ∗ ∂ H 2 ∂ w 2 = ∂ L o s s ∂ o u t ∗ ∂ o u t ∂ H 2 ∗ H 1 \begin{aligned} \Delta \mathrm{W}_{2} =\frac{\partial \mathrm{Loss}}{\partial \mathrm{W}_{2}}=\frac{\partial \mathrm{Loss}}{\partial \mathrm{out}} * \frac{\partial \mathrm{out}}{\partial \mathrm{H}_{2}} * \frac{\partial \mathrm{H}_{2}}{\partial \mathrm{w}_{2}} =\frac{\partial \mathrm{Loss}}{\partial \mathrm{out}} * \frac{\partial \mathrm{out}}{\partial \mathrm{H}_{2}} * \mathrm{H}_{1} \end{aligned} ΔW2=∂W2∂Loss=∂out∂Loss∗∂H2∂out∗∂w2∂H2=∂out∂Loss∗∂H2∂out∗H1
则有 Δ W 2 \Delta \mathrm{W}_{2} ΔW2 依赖于前一层的输出 H 1 H_{1} H1 。如果 H 1 H_{1} H1 趋近于零,那么 Δ W 2 \Delta \mathrm{W}_{2} ΔW2 也接近于 0,造成 梯度消失 。如果 H 1 H_{1} H1 趋近于无穷大,那么 Δ W 2 \Delta \mathrm{W}_{2} ΔW2 也接近于无穷大,造成 梯度爆炸 。要避免梯度爆炸或梯度消失,就要严格控制网络层输出的数值范围。
梯度爆炸实例代码解析过程,参考链接张贤同学-权值初始化。
4.1.1 Xavier 方法
Xavier 是 2010 年在文献《Understanding the difficult of training deep feedforward neural networks》提出的,详细探讨了具有激活函数时,应该如何进行初始化。结合 方差一致性 原则,保持数据尺度维持在恰当范围,通常方差为 1。主要针对饱和 / 激活函数如 sigmoid 和 tanh 等进行分析。同时考虑前向传播和反向传播数据尺度问题,需要满足两个等式: n i ∗ D ( W ) = 1 \boldsymbol{n}_{\boldsymbol{i}} * \boldsymbol{D}(\boldsymbol{W})=\mathbf{1} ni∗D(W)=1 和 n i + 1 ∗ D ( W ) = 1 \boldsymbol{n}_{\boldsymbol{i+1}} * \boldsymbol{D}(\boldsymbol{W})=\mathbf{1} ni+1∗D(W)=1, n i n_i ni:输入神经元的个数, n i + 1 n_{i+1} ni+1:输出神经元的个数。 ⇒ D ( W ) = 2 n i + n i + 1 \Rightarrow D(W)=\frac{2}{n_{i}+n_{i+1}} ⇒D(W)=ni+ni+12。
通常 Xavier 服从均匀分布,假设 W 服从均匀分布 W ∼ U [ − a , a ] \boldsymbol{W} \sim \boldsymbol{U}[-\boldsymbol{a}, \boldsymbol{a}] W∼U[−a,a],下限是 − α -\alpha −α,上限是 α \alpha α,通常采用 0 均值,所以上下线是对称的关系。那么方差 D ( W ) = ( − a − a ) 2 12 = ( 2 a ) 2 12 = a 2 3 D(W)=\frac{(-a-a)^{2}}{12}=\frac{(2 a)^{2}}{12}=\frac{a^{2}}{3} D(W)=12(−a−a)2=12(2a)2=3a2,令 2 n i + n i + 1 = a 2 3 ⇒ a = 6 n i + n i + 1 \frac{2}{n_{i}+n_{i+1}}=\frac{a^{2}}{3} \Rightarrow a=\frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}} ni+ni+12=3a2⇒a=ni+ni+16,则可推导出
⇒ W ∼ U [ − 6 n i + n i + 1 , 6 n i + n i + 1 ] \Rightarrow W \sim U\left[-\frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}}, \frac{\sqrt{6}}{\sqrt{n_{i}+n_{i+1}}}\right] ⇒W∼U[−ni+ni+16,ni+ni+16]
# 手动xavier初始化
a = np.sqrt(6 / (self.neural_num + self.neural_num))
tanh_gain = nn.init.calculate_gain('tanh') # 计算增益
a *= tanh_gain
nn.init.uniform_(m.weight.data, -a, a)
# pytorch 自带 Xavier初始化方法
tanh_gain = nn.init.calculate_gain('tanh')
nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
4.1.2 Kaiming 方法
虽然 Xavier 方法提出了针对饱和激活函数的权值初始化方法,但是 AlexNet 出现后,大量网络开始使用 非饱和的激活函数 如 ReLU 等,这时 Xavier 方法不再适用。2015 年针对 ReLU 及其变种等激活函数提出了 Kaiming 初始化方法。
针对 ReLU,方差应该满足: D ( W ) = 2 n i \mathrm{D}(W)=\frac{2}{n_{i}} D(W)=ni2 ;针对 ReLu 的变种,方差应该满足: D ( W ) = 2 ( 1 + α 2 ) ∗ n i \mathrm{D}(W)=\frac{2}{\left(1+\alpha^{2}\right) * n_{i}} D(W)=(1+α2)∗ni2 , α \alpha α 表示负半轴的斜率,如 PReLU 方法,标准差满足 std ( W ) = 2 ( 1 + a 2 ) ∗ n i \operatorname{std}(W)=\sqrt{\frac{2}{\left(1+a^{2}\right) * n_{i}}} std(W)=(1+a2)∗ni2。
# 激活函数改为 ReLU
# 手动kaiming初始化
# nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
# pytorch 提供 kaiming初始化方法
# nn.init.kaiming_normal_(m.weight.data)
calculate_gain():计算激活函数的 方差变化尺度 。
方差变化尺度指,输入数据的方差除以经过激活函数之后输出数据的方差,也就是方差的一个比例。
nn.init.calculate_gain(nonlinearity, param=None)
# nonlinearity: 激活函数名称
# param: 激活函数的参数,如Leaky ReLU 的 negative_slop
4.1.3 十种初始化方法
- Xavier均匀分布
- Xavier正态分布
- Kaiming均匀分布
- Kaiming正态分布
- 均匀分布
- 正态分布
- 常数分布
- 正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
4.2 损失函数
损失函数,衡量模型输出与真实标签的差异。
损失函数 Loss function:一个样本。 L o s s = f ( y ∧ , y ) Loss=f\left(y^{\wedge}, y\right) Loss=f(y∧,y)
代价函数 Cost function:整个样本集。 cos t = 1 N ∑ i N f ( y i ∧ , y i ) \cos t=\frac{1}{N} \sum_{i}^{N} f\left(y_{i}^{\wedge}, y_{i}\right) cost=N1∑iNf(yi∧,yi)
目标函数 Objective function: O b j = C o s t + R e g u l a r i z a t i o n Obj=Cost+Regularization Obj=Cost+Regularization
class _Loss(nn.Module):
def __init__(self, size_average=None, reduce=None, reduction='mean'):
super(_Loss, self).__init__()
if size_average is not None or reduce is not None:
self.reduction = _Reduction.legacy_get_string(size_average, reduce)
else:
self.reduction = reduction
4.2.1 熵,交叉熵
交叉熵 的与softmax推导公式可以参考神经网络基础知识-Softmax+CrossEntropy
4.2.2 nn.CrossEntropyLoss()
nn.CrossEntropyLoss(),nn.LogSoftmax() 与 nn.NLLLoss() 结合,进行交叉熵计算。此函数并不是公式意义上的交叉熵计算,而是采用softmax对数据进行了一个归一化的处理,把数据值归一化到概率输出值的形式。
分类任务通常是以概率值输出为主的,交叉熵其实是衡量两个概率分布之间的差异。交叉熵值越低,表示两个分布越近。
nn.CrossEntropyLoss(weight=None, # weight: 各类别的Loss设置权值
size_average=None,
ignore_index=-100, # ignore_index: 忽略某个类别
reduce=None,
reduction='mean') # reduction: 计算模式,可为 none/sum/mean
# none - 逐个元素计算,sum - 所有元素求和,返回标量,mean - 加权平均,返回标量
熵,交叉熵
- 交叉熵 = 信息熵 + 相对熵
- 交叉熵: H ( P , Q ) = − ∑ i = 1 N P ( x i ) log Q ( x i ) \mathrm{H}(\boldsymbol{P}, \boldsymbol{Q})=-\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right) H(P,Q)=−∑i=1NP(xi)logQ(xi)
- 自信息: I ( x ) = − log [ p ( x ) ] \mathrm{I}(x)=-\log [p(x)] I(x)=−log[p(x)]
- 熵: H ( P ) = E x ∼ p [ I ( x ) ] = − ∑ i N P ( x i ) log P ( x i ) \mathrm{H}(\mathrm{P})=E_{x \sim p}[I(x)]=-\sum_{i}^{N} P\left(x_{i}\right) \log P\left(x_{i}\right) H(P)=Ex∼p[I(x)]=−∑iNP(xi)logP(xi)
- 相对熵:
D K L ( P , Q ) = E x ∼ p [ log P ( x ) Q ( x ) ] = E x ∼ p [ log P ( x ) − log Q ( x ) ] = ∑ i = 1 N P ( x i ) [ log P ( x i ) − log Q ( x i ) ] = ∑ i = 1 N P ( x i ) log P ( x i ) − ∑ i = 1 N P ( x i ) log Q ( x i ) = H ( P , Q ) − H ( P ) \begin{aligned} \boldsymbol{D}_{K L}(\boldsymbol{P}, \boldsymbol{Q}) &=\boldsymbol{E}_{\boldsymbol{x} \sim p}\left[\log \frac{P(x)}{Q(\boldsymbol{x})}\right] \\ &=\boldsymbol{E}_{\boldsymbol{x} \sim p}[\log P(\boldsymbol{x})-\log Q(\boldsymbol{x})] \\ &=\sum_{i=1}^{N} P\left(x_{i}\right)\left[\log P\left(\boldsymbol{x}_{i}\right)-\log Q\left(\boldsymbol{x}_{i}\right)\right] \\ &=\sum_{i=1}^{N} P\left(\boldsymbol{x}_{i}\right) \log P\left(\boldsymbol{x}_{i}\right)-\sum_{i=1}^{N} P\left(\boldsymbol{x}_{i}\right) \log \boldsymbol{Q}\left(\boldsymbol{x}_{i}\right) \\ &=H(P, Q)-H(P) \end{aligned} DKL(P,Q)=Ex∼p[logQ(x)P(x)]=Ex∼p[logP(x)−logQ(x)]=i=1∑NP(xi)[logP(xi)−logQ(xi)]=i=1∑NP(xi)logP(xi)−i=1∑NP(xi)logQ(xi)=H(P,Q)−H(P)
熵也叫信息熵,用来描述一个事件的不确定性,不确定性越大熵就越大。熵是自信息的一个期望。
自信息是用于衡量单个输出、单个事件的不确定性,p(x)表示事件x的概率。
熵 是整个概率分布的一个不确定性,它是用来描述整个概率分布,所以需要对自信息I(x)求期望。
相对熵又称为KL散度,用来衡量两个分布之间的差异(即两个分布之间的距离,但不是距离函数,无对称性)
交叉熵 是衡量两个概率分布P,Q之间的一个关系,一个相似度。P是一个真实概率分布,训练集中样本的分布;Q是模型输出的分布。
交叉熵: H ( P , Q ) = D K L ( P , Q ) + H ( P ) \mathrm{H}(\boldsymbol{P}, \boldsymbol{Q})=\boldsymbol{D}_{K L}(\boldsymbol{P}, \boldsymbol{Q})+H(P) H(P,Q)=DKL(P,Q)+H(P)。机器学习中优化(最小化)交叉熵,等价于优化相对熵 D K L ( P , Q ) \boldsymbol{D}_{K L}(\boldsymbol{P}, \boldsymbol{Q}) DKL(P,Q) 的(优化KL距离)。等号右边的信息熵 H ( P ) H(P) H(P),由于训练集是固定的,所以 H ( P ) H(P) H(P)是一个常数,概率分布式是固定的。优化时常数可以忽略掉。
对于一个样本的 Loss 计算公式为: H ( P , Q ) = − ∑ i = 1 N P ( x i ) log Q ( x i ) = l o g Q ( x i ) \mathrm{H}(\boldsymbol{P}, \boldsymbol{Q})=-\sum_{i=1}^{N} \boldsymbol{P}\left(\boldsymbol{x}_{\boldsymbol{i}}\right) \log Q\left(\boldsymbol{x}_{\boldsymbol{i}}\right) = logQ(x_{i}) H(P,Q)=−∑i=1NP(xi)logQ(xi)=logQ(xi),因为 N=1, P ( x i ) = 1 P(x_{i})=1 P(xi)=1。所以 loss ( x , class ) = − log ( exp ( x [ class ] ) ∑ j exp ( x [ j ] ) ) = − x [ class ] + log ( ∑ j exp ( x [ j ] ) ) \operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right) loss(x, class )=−log(∑jexp(x[j])exp(x[ class ]))=−x[ class ]+log(∑jexp(x[j])) 。如果增添了类别的权重,则 loss ( x , class ) = weight [ class ] ( − x [ class ] + log ( ∑ j exp ( x [ j ] ) ) ) \operatorname{loss}(x, \text { class })=\operatorname{weight}[\text { class }]\left(-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)\right) loss(x, class )=weight[ class ](−x[ class ]+log(∑jexp(x[j])))。
代码调试部分可参考链接 张贤同学 - 4.2 损失函数
| 损失函数 | 功能 |
|---|---|
| nn.NLLLoss() | 实现负对数似然函数中的 负号功能 |
| nn.BCELoss() | 二分类交叉熵,输入值取值在[0,1] |
| nn.BCEWithLogitsLoss() | 结合Sigmoid与二分类交叉熵,网络最后不加Sigmoid函数 |
| nn.L1Loss() | 计算inputs与 target之差的 绝对值 |
| nn.MSELoss() | 计算inputs与 target之差的平方, l n = ( x n − y n ) 2 l_{n}={(x_{n}-y_{n})}^2 ln=(xn−yn)2 |
| nn.SmoothL1Loss() | 平滑的L1Loss |
| nn.PoissonNLLLoss() | 泊松分布的 负对数似然损失函数 |
| nn.KLDivLoss() | 计算KLD(divergence),KL散度,相对熵 |
| nn.MarginRankingLoss() | 计算两个向量之间的相似度,用于排序任务; loss ( x , y ) = max ( 0 , − y ∗ ( x 1 − x 2 ) + margin ) \operatorname{loss}(x, y)=\max (0,-y *(x1-x2)+\operatorname{margin}) loss(x,y)=max(0,−y∗(x1−x2)+margin),该方法计算两组数据之间的差异,返回一个 n ∗ n n*n n∗n的 Loss 矩阵 |
| nn.MultiLabelMarginLoss() | 多标签边界 损失函数 |
| nn.SoftMarginLoss() | 计算二分类的 Logistic 损失 |
| nn.MultiLabelSoftMarginLoss() | SoftMarginLoss 多标签版本 |
| nn.MultiMarginLoss() | 计算多分类的折页损失 |
| nn.TripletMarginLoss() | 计算 三元组损失,人脸验证中常用 |
| nn.HingeEmbeddingLoss() | 计算两个输入的相似性,常用于非线性embedding和半监督学习 |
| nn.CosineEmbeddingLoss() | 采用余弦相似度计算两个输入的相似性 |
| nn.CTCLoss() | 计算CTC (Connection Temporal Classification)损失,解决时序类数据的分类 |
4.3 优化器
pytorch的优化器,管理 并更新 模型中可学习的参数的值,使得模型输出更接近真实标签。
- 导数 : 函数在指定坐标轴上的变化率
- 方向导数 :指定方向上的变化率
- 梯度 :一个向量,方向为方向导数取得最大值的方向
4.3.1 Optimizer
基本属性
class Optimizer(Object):
def __init__(self, params, defaults):
self.defaults = defaults # 优化器的超参数,如 weight_decay, momentum
self.state = defaultdict(dict) # 参数的缓存,如 momentum 中需要用到前几次的梯度,就缓存在这个变量中
self.param_groups = [] # 管理的参数数组,是一个list,其中每一个元素是字典
# _step_count: 记录更新次数,学习率调整中使用
基本方法
zero_grad() :清空所管理参数的梯度,在pytorch 中,张量的梯度不自动清零。
step() :执行一步更新
add_param_group() :向优化器中添加参数组
state_dict() :获取优化器当前状态信息 字典
load_state_dict() :加载状态信息字典
代码调试部分可参考链接 张贤同学 - 4.3 优化器
4.3.2 学习率
梯度下降: w i + 1 = w i − l r ∗ g ( w i ) w_{i+1} = w_i -lr *g(w_i) wi+1=wi−lr∗g(wi),学习率lr控制更新的步伐
iter_rec, loss_rec, x_rec = list(), list(), list()
lr = 1 # /1. /.5 /.2 /.1 /.125
max_iteration = 4 # /1. 4 /.5 4 /.2 20 200 # 最大迭代次数
for i in range(max_iteration):
y = func(x)
y.backward() # 求 x 的梯度
print("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}".format(
i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))
x_rec.append(x.item())
x.data.sub_(lr * x.grad) # x -= x.grad # 0.5 0.2 0.1 0.125
x.grad.zero_() # 梯度清零
iter_rec.append(i)
loss_rec.append(y)
plt.subplot(121).plot(iter_rec, loss_rec, '-ro')
plt.xlabel('Iteration')
plt.ylabel('Loss value')
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.subplot(122).plot(x_t.numpy(), y.numpy(), label='y = 4*x^2')
plt.grid()
y_rec = [func(torch.tensor(i)).item() for i in x_rec]
plt.subplot(122).plot(x_rec, y_rec, '-ro')
plt.legend()
plt.show()
先以学习率 lr=1,最大迭代次数 max_iteration=4,画出图形
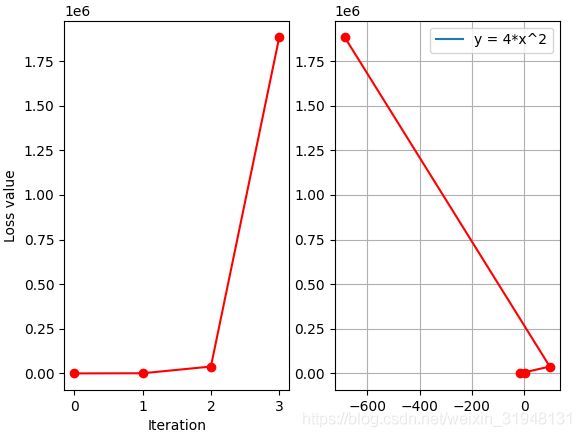
学习率 lr=0.2,最大迭代次数 max_iteration=4,画出图形

学习率 lr=0.2,最大迭代次数 max_iteration=20,画出图形
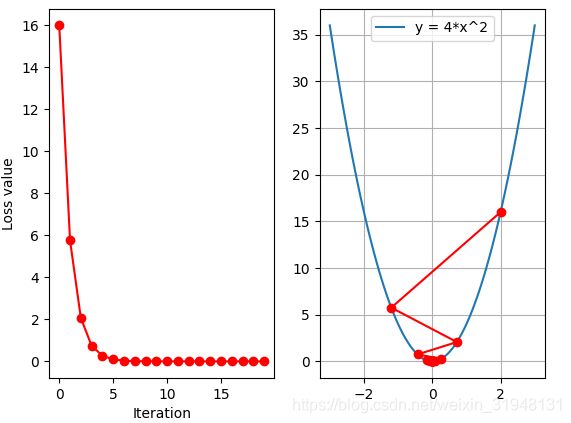
在学习率 lr=0.125时,达到最好的情况,但事先不知道如何才能选到 0.125 这个值,先观察多个学习率 ,不同Loss的变化情况。
iteration = 100
num_lr = 10
lr_min, lr_max = 0.01, 0.2
lr_list = np.linspace(lr_min, lr_max, num=num_lr).tolist()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
for iter in range(iteration):
y = func(x)
y.backward()
x.data.sub_(lr * x.grad) # x.data -= x.grad
x.grad.zero_()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {}".format(lr_list[i]))
plt.legend()
plt.xlabel('Iteration')
plt.ylabel('Loss value')
plt.show()
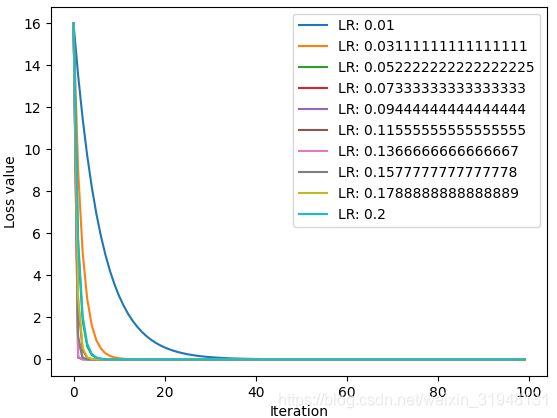
上图中学习率在0.136时收敛最快,(最下面紫色曲线,离0.125 最近)
4.3.3 Momentum 动量,冲量
momentum 动量的更新方法,结合当前梯度与上一次更新信息,用于当前更新。
指数加权平均(时间序列中常用)
求取当前时刻的平均值,距离当前时刻越近的参数值,参考性越大,所占权重越大,权重随着时间间隔增大呈指数下降的。
v t = β ∗ v t − 1 + ( 1 − β ) ∗ θ t v_t=\beta*v_{t-1}+(1-\beta)*\theta_t vt=β∗vt−1+(1−β)∗θt
v t v_t vt 是当前时刻的平均值, θ t \theta_t θt 是当前时刻的值,它所占的权重是 ( 1 − β ) (1-\beta) (1−β), v t − 1 v_{t-1} vt−1 是上一时刻的指数加权平均值。
实例 - 现求得是第100天时刻的平均值
v 100 = β ∗ v 99 + ( 1 − β ) ∗ θ 100 = ( 1 − β ) ∗ θ 100 + β ∗ ( β ∗ v 98 + ( 1 − β ) ∗ θ 99 ) = ( 1 − β ) ∗ θ 100 + ( 1 − β ) ∗ β ∗ θ 99 + ( β 2 ∗ v 98 ) = ( 1 − β ) ∗ θ 100 + ( 1 − β ) ∗ β ∗ θ 99 + ( 1 − β ) ∗ β 2 ∗ θ 98 + ( β 3 ∗ v 97 ) = ( 1 − β ) ∗ θ 100 + ( 1 − β ) ∗ β 1 ∗ θ 99 + ( 1 − β ) ∗ β 2 ∗ θ 98 + ( β 3 ∗ v 97 ) = ∑ i N ( 1 − β ) ∗ β i ∗ θ N − i \begin{array}{l} \mathrm{v}_{100}=\boldsymbol{\beta} * \boldsymbol{v}_{99}+(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\theta}_{100} \\ =(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\theta}_{100}+\boldsymbol{\beta} *\left(\boldsymbol{\beta} * \boldsymbol{v}_{98}+(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\theta}_{99}\right) \\ =(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\theta}_{100}+(\mathbf{1}-\boldsymbol{\beta}) * \boldsymbol{\beta} * \boldsymbol{\theta}_{99}+\left(\boldsymbol{\beta}^{2} * \boldsymbol{v}_{98}\right) \\ =(1-\beta) * \theta_{100}+(1-\beta) * \beta * \theta_{99}+(1-\beta) * \beta^{2} * \theta_{98}+\left(\beta^{3} * v_{97}\right) \\ =(1-\beta) * \theta_{100}+(1-\beta) * \beta^{1} * \theta_{99}+(1-\beta) * \beta^{2} * \theta_{98}+\left(\beta^{3} * v_{97}\right) \\ =\sum_{i}^{N}(1-\beta) * \beta^{i} * \theta_{N-i} \end{array} v100=β∗v99+(1−β)∗θ100=(1−β)∗θ100+β∗(β∗v98+(1−β)∗θ99)=(1−β)∗θ100+(1−β)∗β∗θ99+(β2∗v98)=(1−β)∗θ100+(1−β)∗β∗θ99+(1−β)∗β2∗θ98+(β3∗v97)=(1−β)∗θ100+(1−β)∗β1∗θ99+(1−β)∗β2∗θ98+(β3∗v97)=∑iN(1−β)∗βi∗θN−i
def exp_w_func(beta, time_list):
return [(1 - beta) * np.power(beta, exp) for exp in time_list]
beta = 0.9
num_point = 100
time_list = np.arange(num_point).tolist()
weights = exp_w_func(beta, time_list)
plt.plot(time_list, weights, '-ro', label='Beta:{} \ny= B^t *(1-B)'.format(beta))
plt.xlabel('time')
plt.ylabel('weight')
plt.legend()
plt.title('exponential weight average')
plt.show()
print(np.sum(weights))

距离当前时刻越远,对当前时刻平均值的影响越小;距离当前时刻越近,影响越大,权重越大。
下面对不同的 B e t a Beta Beta,权重的变化情况:

B e t a Beta Beta 可理解为记忆周期的概念。 B e t a Beta Beta 值越小,记忆周期越短(红色曲线20天之后就不关注远期的参数值),蓝色曲线( B e a t = 0.98 Beat=0.98 Beat=0.98)记忆周期较长,80天之后不再关注。
β 越小,记忆周期越短, β 越大,记忆周期越长。
通常 B e t a Beta Beta值会设置为 0.9。物理意义,会更关注当前时刻 10 天左右的数据( 1 1 − β = 10 \frac{1}{1-\beta}=10 1−β1=10)。
Pytorch中momentum更新公式:
v i = m ∗ v i − 1 + g ( w i ) w i + 1 = w i − l r ∗ v i \begin{array}{c} v_{i}=m * v_{i-1}+g\left(w_{i}\right) \\ w_{i+1}=w_{i}-l r * v_{i} \end{array} vi=m∗vi−1+g(wi)wi+1=wi−lr∗vi
对比梯度下降更新公式: w i + 1 = w i − l r ∗ g ( w i ) w_{i+1} = w_i -lr *g(w_i) wi+1=wi−lr∗g(wi),其中 w i + 1 w_{i+1} wi+1表示第 i + 1 i+1 i+1次更新的参数, l r lr lr 表示学习率, v i v_{i} vi表示更新量, m m m表示 m o m e n t u m momentum momentum 系数, g ( w i ) g(w_{i}) g(wi) 表示 w i w_{i} wi 的梯度。
v 100 = m ∗ v 99 + g ( w 100 ) = g ( w 100 ) + m ∗ ( m ∗ v 98 + g ( w 99 ) ) = g ( w 100 ) + m ∗ g ( w 99 ) + m 2 ∗ v 98 = g ( w 100 ) + m ∗ g ( w 99 ) + m 2 ∗ g ( w 98 ) + m 3 ∗ v 97 \begin{aligned} v_{100} &=m * v_{99}+g\left(w_{100}\right) \\ &=g\left(w_{100}\right)+m *\left(m * v_{98}+g\left(w_{99}\right)\right) \\ &=g\left(w_{100}\right)+m * g\left(w_{99}\right)+m^{2} * v_{98} \\ &=g\left(w_{100}\right)+m * g\left(w_{99}\right)+m^{2} * g\left(w_{98}\right)+m^{3} * v_{97} \end{aligned} v100=m∗v99+g(w100)=g(w100)+m∗(m∗v98+g(w99))=g(w100)+m∗g(w99)+m2∗v98=g(w100)+m∗g(w99)+m2∗g(w98)+m3∗v97
代入上面例子,可看到,当前的更新量 v 100 v_{100} v100 要考虑到当前的梯度 g ( w 100 ) g(w_{100}) g(w100),上一时刻的梯度 g ( w 99 ) g(w_{99}) g(w99),前一个时刻梯度 g ( w 98 ) g(w_{98}) g(w98) … 之前时刻更新梯度对当前更新量的影响,会受到权重 m m m 的影响,由于 m < 1 m<1 m<1,越往前,权重越小,梯度信息的作用越小。
 上图左图 学习率为 0.03 时收敛更快。中间图把学习率为 0.01 时,设置 momentum 为 0.9,收敛更快。虽然设置了 momentum,但是震荡收敛,这是由于 momentum 的值太大,每一次都考虑上一次的比例太多,可以把 momentum 设置为 0.63 ,可以看到设置适当的 momentum 后,学习率 0.01 的情况下收敛更快了。
上图左图 学习率为 0.03 时收敛更快。中间图把学习率为 0.01 时,设置 momentum 为 0.9,收敛更快。虽然设置了 momentum,但是震荡收敛,这是由于 momentum 的值太大,每一次都考虑上一次的比例太多,可以把 momentum 设置为 0.63 ,可以看到设置适当的 momentum 后,学习率 0.01 的情况下收敛更快了。
| 优化器 | 解释说明 | 参考文献 / 链接 |
|---|---|---|
| optim.SGD | 随机梯度下降法 | 《On the importance of initialization and momentum in deep learning》 |
| optim.Adagrad | 自适应学习率梯度下降法 | 《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》 |
| optim.RMSprop | Adagrad 的改进 | http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf |
| optim.Adadelta | Adagrad的改进 | 《 AN ADAPTIVE LEARNING RATE METHOD》》 |
| optim.Adam | RMSprop结合Momentum | 《Adam: A Method for Stochastic Optimization》 |
| optim.Adamax | Adam增加学习率上限 | 《Adam: A Method for Stochastic Optimization》 |
| optim.SparseAdam | 稀疏版的Adam | |
| optim.ASGD | 随机平均梯度下降 | 《Accelerating Stochastic Gradient Descent using Predictive Variance Reduction》 |
| optim.Rprop | 弹性反向传播 | 《Martin Riedmiller und Heinrich Braun》 |
| optim.LBFGS | BFGS的改进 |
4.3.4 学习率调整策略
学习率调整一般为先大后小
class _LRScheduler(Object):
def __init__(self, optimizer, last_epoch=-1):
def get_lr(self):
raise NotImplementedError
主要属性:
- optimizer:关联的优化器
- last_epoch:记录 epoch 数
- base_lrs:记录初始学习率
主要方法:
- step():
更新下一个 epoch 的学习率 - get_lrs():虚函数,
计算下一个epoch 的学习率
学习率初始化:
- 设置较小数:0.01,0.001,0.0001
- 搜索最大学习率: 《Cyclical Learning Rates for Training Neural Networks》
Pytorch 学习率调整的策略
- 有序调整: Step、MultiStep、Exponential 和 CosineAnnealing
- 有序调整: ReduceLROnPleateau
- 有序调整: Lambda
- StepLR:等间隔调整学习率。
主要参数:step_size:调整间隔数;gamma:调整系数。
调整方式: l r = l r ∗ g a m m a lr=lr*gamma lr=lr∗gamma
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights-target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
-
MultiStepLR:按给定间隔调整学习率。
主要参数:milestone:设定调整时刻数;gamma:调整系数。
调整方式: l r = l r ∗ g a m m a lr=lr*gamma lr=lr∗gamma
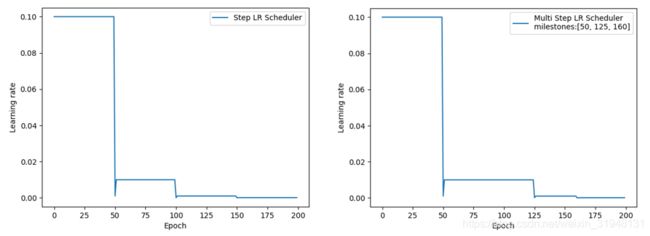
-
ExponentialLR:按指数衰减调整学习率。
主要参数:gamma:指数的底。
调整方式: l r = l r ∗ g a m m a ∗ ∗ e p o c h lr=lr*gamma** epoch lr=lr∗gamma∗∗epoch -
CosineAnnealingLR:余弦周期调整学习率。
主要参数:T_max:下降周期;eta_min:学习率下限。
调整方式: η t = η min + 1 2 ( η max − η min ) ( 1 + cos ( T c u r T max π ) ) \eta_{t}=\eta_{\min }+\frac{1}{2}\left(\eta_{\max }-\eta_{\min }\right)\left(1+\cos \left(\frac{T_{c u r}}{T_{\max }} \pi\right)\right) ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ))

scheduler_lr2 = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
scheduler_lr3 = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
scheduler_lr4 = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=t_max, eta_min=0.)
- ReduceLRonPlateau:监控指标,当指标不在变化 则调整学习率。
主要参数:mode:min / max 两种模式,min:观察所在的指标下降,若不下降,则调整,通常观察Loss;max:观察监控指标,若不上升,则调整,通常观察分类准确率accuracy。
factor:调整系数
patience:“耐心”,接受几次不变化
cooldown:“冷却时间”,停止监控一段时间
verbose:是否打印日志
min_lr:学习率下限
eps:学习率衰减最小值
loss_value = 0.5
accuracy = 0.9
factor = 0.1 # 系数是 0.1,也就是除以 10
mode = 'min' # 下降模式
patience = 10 # 连续10个epoch不变化
cooldown = 10
min_lr = 1e-4 # 当学习率到了10^-4,就不再下降
verbose = True
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience, cooldown=cooldown, min_lr=min_lr, verbose=verbose) # 设置学习率下降策略
for epoch in range(max_epoch):
for i in range(iteration):
optimizer.step()
optimizer.zero_grad()
# if epoch == 5:
# loss_value = 0.4
scheduler_lr.step(loss_value) # loss_value是标量,要放进函数step()中
Output:
Epoch 12: reducing learning rate of group 0 to 1.0000e-02.
Epoch 33: reducing learning rate of group 0 to 1.0000e-03.
Epoch 54: reducing learning rate of group 0 to 1.0000e-04.
前10个loss_value都是0.5,连续10个epoch都没有下降,就改变学习率。第二次间隔21个epoch,有10个是处于冷却时间,无需调整。
若将代码中if epoch == 5: loss_value = 0.4的#去掉,则输出变为17,38,59个Epoch输出上面的结果。说明是在第5个epoch之后,再连续10个epoch无变化,会接受调整。
- LambdaLR:自定义调整策略。
主要参数:lr_lambda:function or list
自定义一个lambda函数,函数的输入是epoch数,返回的是一个调整的系数,这个系数会乘以base_lr,得到下一个epoch的学习率,这就是Lambda可以自定义调整学习率的方法。
这个方法最实用的地方在于 设置不同的参数组 有不同学习率调整策略,在模型的fitting当中非常实用。
lr_init = 0.1
weight_1 = torch.randn((6,3,5,5)) # 可以对不同的参数组 设置不同学习率调整方法
weight_2 = torch.ones((5,5))
optimizer = optim.SGD([{'params': [weight_1]}, {'params': [weight_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1**(epoch//20) # 在lambda当中设置调整系数,去更新学习率
lambda2 = lambda epoch: 0.95**epoch
scheduler_lr = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2]) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
for i in range(iteration):
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
print('epoch:{:5d}, lr:{}'.format(epoch, scheduler_lr.get_lr()))
5. TensorBoard 与 Hook
5.1 TensorBorad 可视化
迭代训练可视化 - TensorBoard,TensorBoard 是TensorFlow 中强大的可视化工具。使用pip install tensorboard安装。

# 记录可视化数据到硬盘当中,以一个eventfile 形式去保存,保存在当前文件夹中run文件夹下
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalar('y=2x', x*2, x)
writer.add_scalar('y=pow(2,x)', 2**x, x)
writer.add_scalars('data/scalar_group', {'xsinx': x * np.sin(x),
'xcosx': x * np.cos(x),
'arctanx': np.arctan(x)}, x)
writer.close()
之后在终端 Terminal 中输入tensorboard --logdir=./deepeye/runs,eventfile文件保存在runs文件夹下。
SummaryWriter
SummaryWriter:提供创建 event file 的高级接口
主要属性:
- log_dir : event file 输出文件夹
- comment:不指定 log_dir 时,文件夹后缀
- filename_suffix:event file 文件名后缀
from torch.utils.tensorboard import SummaryWriter
log_dir = './train_log/test_log_dir'
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix='12345678')
# writer = SummaryWriter(comment='_scalars', filename_suffix='12345678')
for x in range(100):
writer.add_scalar('y=pow_2_x', 2**x, x)
writer.close()
一般会指定输出文件夹,使用log_dir,若不使用,会保存在当前文件夹下runs文件夹下,不推荐。

主要方法:
-
add_scalar():记录标量
tage:图像的标签名,图的唯一标识
scalar_value:要记录的标量
global_step:x轴 -
add_scalars():
main_tag:下降周期
tag_scalar_dict:key是变量的tag,value是变量的值
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix='test_suffix')
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x) # 'x*2': 是y轴,'x':是X轴
writer.add_scalar('y=pow_2_x', 2 ** x, x) # '2**x': 是y轴,'x':是X轴
writer.add_scalars('data/scalar_group', {'xsinx': x * np.sin(x),
'xcosx': x * np.cos(x)}, x) # 'main_tag': 'data/scalar_group'
writer.close()
- add_histogram():统计直方图与多分为数折线图
tag:图像的标签名,图的唯一标识
value:要统计的参数
global_step:y轴
bins:取直方图的bins
TensorBoard监控模型指标,可以参考链接 张贤同学-5.1 TensorBoard 介绍
- add_image():记录图像
tag:图像的标签名,图的唯一标识
img_tensor:图像数据,注意尺度
global_step:x轴
dataformats:数据形式,CHW,HWC,HW。如果像素值在 [0, 1] 之间,那么默认会乘以 255,放大到 [0, 255] 范围之间。如果有大于 1 的像素值,认为已经是 [0, 255] 范围,那么就不会放大。
writer = SummaryWriter(comment='test_your_comment', filename_suffix='_test_your_filename_suffix')
# img 1 random
fake_img = torch.randn(3, 512, 512)
writer.add_image('fake_img', fake_img, 1)
time.sleep(1)
# img 2 ones // 全为 1 ,会默认×255,所有像素值都是255,是白色的
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image('fake_img', fake_img, 2)
# img 3 1.1 // 所有像素值都是 1.1, 大于1, 默认为0~255之间,不会进行其他操作。都是1.1的像素值,是黑色的
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image('fake_img', fake_img, 3)
# img 4 HW 单通道的灰度图 // 没有彩色信息的rand,二维的灰度图
fake_img = torch.rand(512, 512)
writer.add_image('fake_img', fake_img, 4, dataformats='HW')
# img 5 HWC 通道放在最后一维 // 和方法1 两种模式,适应不同数据
fake_img = torch.rand(512, 512, 3)
writer.add_image('fake_img', fake_img, 5, dataformats='HWC')
writer.close()

将上面的显示结果显示在一个界面,不需要额外拖动鼠标显示,使用pytorch 中的torchvision.utils.make_grid。
torchvision.utils.make_grid():制作网格图像
主要参数:tensor:图像数据,B*C*H*W形式 ;
nrow:行数(列数自动计算);
padding:图像间距(像素单位);
normalize:是否将像素值标准化到 [0, 255]之间;
range:标准化范围,例如原图的像素值范围是 [-1000, 2000],设置 range 为 [-600, 500],那么会把小于 -600 的像素值变为 -600,那么会把大于 500 的像素值变为 500,然后标准化到 [0, 255] 之间;
scale_each:是否单张图维度标准化,;
pad_value:padding像素值。
- add_graph():可视化模型计算图
model:模型,必须是nn.Module
input_to_model:输出给模型的数据
verbose:是否打印计算图结构信息
torchsummary:查看模型信息,便于调试
主要参数:model:pytorch模型;
input_size:模型输入size;
batch_size:batch size;
device:cpu or cuda;
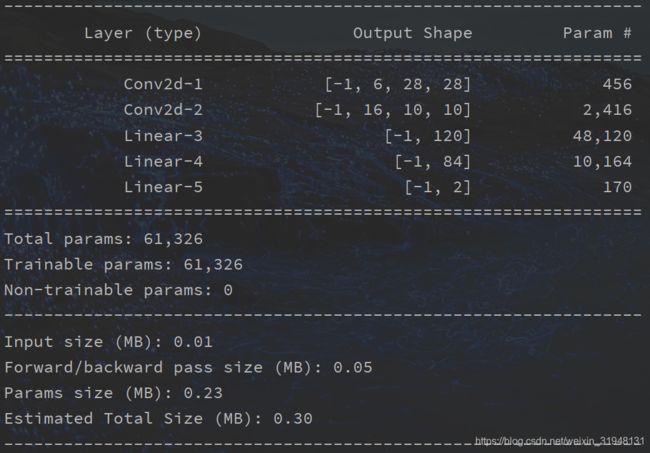
from torchsummary import summary # pip 安装
print(summary(lenet, (3, 32, 32), device='cpu'))
5.2 Hook函数
Hook函数机制:不改变函数主体,实现额外功能,像一个挂钩,hook。因为pytorch为动态图运行机制,在动态图运算过程中,运算结束之后,一些中间变量会被释放掉;例如特征图,非叶子节点的梯度等在运算结束后都会被释放掉。想要 提取和记录这些中间边量,采用Hook函数。
torch.Tensor.register_hook
Tensor.register_hook,针对tensor,功能是注册一个反向传播的hook函数,张量在反向传播时,若是非叶子节点,梯度会消失。针对这个反向传播过程中有可能存在的数据会消失,释放,就有了这个hook函数。
Hook函数仅一个输入参数,为张量的梯度。
torch.Module.register_forward_hook
Module.register_forward_hook,注册module的前向传播hook函数
主要参数:model:当前网络层; input:当前网络层输入数据;output:当前网络层输出数据。
torch.Module.register_forward_pre_hook
Module.register_forward_pre_hook,注册module前向传播前的hook函数
主要参数:model:当前网络层; input:当前网络层输入数据。
torch.Module.register_backward_hook
Module.register_backward_hook,注册module反向传播hook函数
主要参数:model:当前网络层; grad_input:当前网络层输入梯度数据;grad_output:当前网络层输出梯度数据。
具体解释过程,可参考这篇博文链接TensorSense-PyTorch的hook及其在Grad-CAM中的应用
6. Regularization 与 Normalization
6.1 正则化之 weight_decay
Regularization:减小方差的策略
误差可分解为:偏差,方差与噪声之和。即 误差 = 偏差 + 方差 + 噪声 之和。
偏差 度量了学习算法本身的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差 度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声 则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界。

目标函数:Obj = Cost Function + Regularization Term
代价函数: Cos t = 1 N ∑ i N f ( y i ∧ , y i ) \operatorname{Cos} t=\frac{1}{N} \sum_{i}^{N} f\left(y_{i}^{\wedge}, y_{i}\right) Cost=N1∑iNf(yi∧,yi),L1 正则项: ∑ i N ∣ w i ∣ \sum_{i}^{N}\left|w_{i}\right| ∑iN∣wi∣, L2 正则项: ∑ i N w i 2 \sum_{i}^{N}w_{i}^2 ∑iNwi2
在线性回归中应用正则化方式减小过拟合,LASSO回归运用L1范数正则化解决过拟合,岭回归运用L2范数正则化解决过拟合。可参考之前博文线性回归。
对L1正则化与L2正则化详细理解,可参考知乎文章 bingo酱-L1正则化与L2正则化
L2 Regularization = weight decay (权值衰减)
目标函数: Obj = Cost + Regularization Term = L o s s + λ 2 ∗ ∑ i N w i 2 Loss +\frac{\lambda}{2}*\sum_{i}^{N}w_{i}^2 Loss+2λ∗∑iNwi2
w i + 1 = w i − ∂ O b j ∂ w i = w i − ∂ L o s s ∂ w i = w i − ( ∂ L o s s ∂ w i + λ ∗ w i ) = w i ( 1 − λ ) − ∂ L o s s ∂ w i \begin{aligned} w_{i+1}=w_{i}-\frac{\partial O b j}{\partial w_{i}} &=w_{i}-\frac{\partial L o s s}{\partial w_{i}} \\ &=w_{i}-\left(\frac{\partial L o s s}{\partial w_{i}}+\lambda* w_{i}\right) \\ &=w_{i}(1-\lambda)-\frac{\partial L o s s}{\partial w_{i}} \end{aligned} wi+1=wi−∂wi∂Obj=wi−∂wi∂Loss=wi−(∂wi∂Loss+λ∗wi)=wi(1−λ)−∂wi∂Loss
其中 0 < λ < 1 0 < \lambda < 1 0<λ<1 ,所以具有权值衰减的作用,权值每次更新乘一个小于1 的数。

无权值衰减虽然对训练数据拟合很好,但很容易产生过拟合。
6.2 正则化之 Dropout
Dropout:随机失活。 随机 :dropout probability; 以一定的概率让神经元失去活性; 失活 :weight = 0,可理解为权值为0,相当于这个神经元不存在;
出自文章 《Dropout: A simple way to prevent neural networks from overfitting》
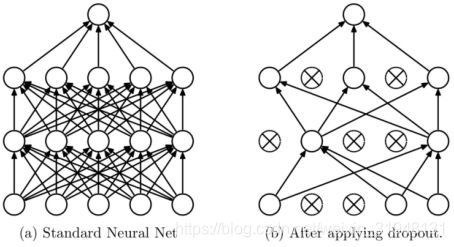
dropout 依据一定的概率让一部分的神经元失活,这就可以让神经元学习到更鲁棒的特征,减轻过度的依赖性,从而缓解过拟合,降低方差达到正则化效果。这样的操作也使得模型更加多样化,前向传播随机失活。
数据尺度变化: dropout 测试时,所有权重乘以 1- drop_prob,drop_prob=3,1- drop_prob=0.7
nn.Dropout():Dropout 层;主要参数 p:被舍弃概率,失活 概率。

红色曲线经过每个训练点,产生过拟合;蓝色曲线采用0.5概率的dropout,降低方差,减小过拟合。
pytoch 实现训练时对权重实现缩放,权重均乘以 1 1 − p \frac{1}{1-p} 1−p1,即除以 1 − p 1-p 1−p,测试时不需要额外操作。详细结果可参考代码部分。
6.3 Batch Normalization
Batch Normalization: 批标准化
批:一批数据,通常为mini-batch
标准化:0 均值,1 方差
优点:
- 可以用更大学习率,加速模型收敛。
- 可以不用精心设计权值初始化。数据的尺度变大变小,导致梯度的激增或消失,模型无法训练。用Batch Normalization 可以将数据尺度一定的规范化,进行一定约束
- 可以不用 dropout或较小的dropout。
- 可以不用 L2 或较小的 weight decay。
- 可以不用 LRN (local response normalization)。
出自文章《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》

输入层有一个Batch数据 x 1... m x_{1...m} x1...m,m 个数据,两个可学习的参数 γ , β \gamma, \beta γ,β。输出层将 x i x_i xi 变换成 y i y_i yi。首先在 mini-batch 上求一个均值,然后得到 方差,再标准化;参数 ϵ \epsilon ϵ 是一个修正项,用来防止分母是 0;最后在进行 affine transform 操作,这个操作的可以增强模型 capacity,使模型更灵活,选择性更多,比如可以让模型自行判断是否对数据分布进行变换。
Batch Normalization 的提出主要为了解决 Internal Covariate Shift (ICS),在训练过程中数据尺度发生变化,可能导致梯度爆炸或者梯度消失,从而模型无法有效训练。
6.3.1 _BatchNorm
_BatchNorm 基类包含 nn.BatchNorm1d(), nn.BatchNorm2d(), nn.BatchNorm3d() 三个基本方法。_BatchNorm 主要参数有,
num_feature : 一个样本特征数量(最重要)
e p s : ϵ \epsilon ϵ 分母修正项
momentum : 指数加权平均估计当前 mean / var,通常设置为0.1
affine : 是否需要 affine transform,默认True
track_running_stats : 是训练状态(True),mean / var 会根据每个 mini-batch而改变;还是测试状态。
nn.BatchNorm1d(), nn.BatchNorm2d(), nn.BatchNorm3d()
主要属性:
running_mean : 均值
running_var : 方差
weight : affine transform 中的 γ \gamma γ
bias : affine transform 中的 β \beta β , γ \gamma γ和 β \beta β可学习。
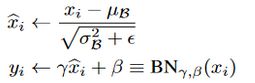
均值和方差, 训练状态(track_running_stats=True)时,采用指数加权平均计算,考虑之前和现在的mini_batch的均值和方差,进行综合估计;
r u n n i n g _ m e a n = ( 1 − m o m e n t u m ) ∗ p r e _ r u n n i n g _ m e a n + m o m e n t u m ∗ m e a n _ t running\_mean = (1 - momentum) * pre\_running\_mean + momentum * mean\_t running_mean=(1−momentum)∗pre_running_mean+momentum∗mean_t
r u n n i n g _ v a r = ( 1 − m o m e n t u m ) ∗ p r e _ r u n n i n g _ v a r + m o m e n t u m ∗ v a r _ t running\_var = (1 - momentum) * pre\_running\_var + momentum * var\_t running_var=(1−momentum)∗pre_running_var+momentum∗var_t
测试状态(track_running_stats=False)时,直接采用已经估计好的统计值。

输入数据的形状是 B ∗ 特 征 数 ∗ n d 特 征 B*特征数*nd 特征 B∗特征数∗nd特征。在下面的例子左图中,数据的维度是:(3, 5, 1),表示一个 mini-batch 有 3 个样本,每个样本有 5 个特征,每个特征的维度是 1。那么就会计算 5 个均值和方差,分别对应每个特征维度……

6.4 Normalization
Internal Covariate Shift(ICS):数据尺度 / 分布异常,导致训练异常
深度学习中常见的 Normalization:
- Batch Normalizaiton (BN)
- Layer Normalization (LN)
- Instance Normalization (IN)
- Group Normalization (GN)
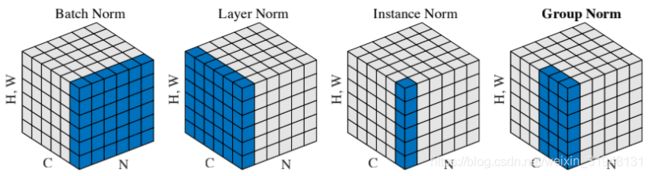
四种方法相同 地方:需要对数据 x i x_i xi进行normalization,最终变成 y i y_i yi
四种方法不同 地方:均值 μ β \mu_{\beta} μβ 和方差 σ β 2 \sigma_{\beta}^2 σβ2 求取方式不同。
BN 是在一个Batch上找特征的均值和方差,LN 是在一个网络层 里找均值和方差,IN 在图像生成当中使用的求 均值和方差的方法,GN 分组求取。
6.4.1 Layer Normalization
起因:BN 不适用于变长的网络,如RNN。网络层的神经元长度可能不一样,导致不能使用BN去计算它们的均值和方差。
出自文章《Layer Normalization》
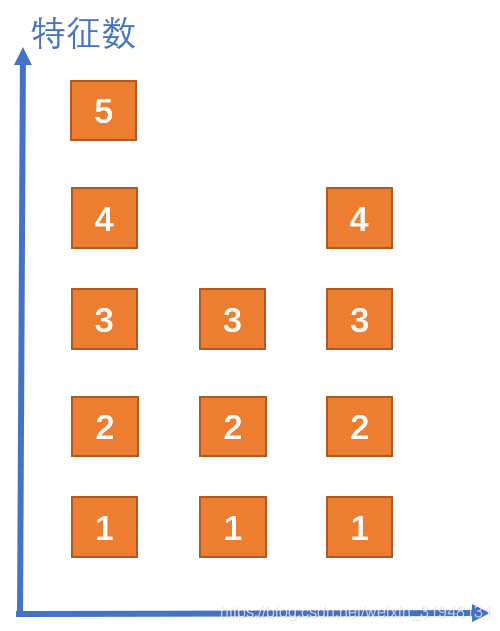 纵轴 理解为神经元的个数,(RNN的神经元每一次可能会变长度), 5 → 3 → 4 5\rightarrow 3\rightarrow 4 5→3→4
纵轴 理解为神经元的个数,(RNN的神经元每一次可能会变长度), 5 → 3 → 4 5\rightarrow 3\rightarrow 4 5→3→4
解决思路:逐层 计算均值和方差
注意事项:
- 不再有running_mean和running_var;LN不会在通过统计信息去获得均值和方差
- γ \gamma γ 和 β \beta β为逐元素的;(逐特征的),每一个神经元有它的 γ \gamma γ 和 β \beta β
nn.LayerNorm() 主要参数:
normalized_shape : 该层特征形状;然后根据该层的特征和形状,求取特征和方差
e p s : ϵ \epsilon ϵ 分母修正项
elementwise_affine : 是否需要affine transform
6.4.2 Instance Normalization
起因:BN 在图像生成(Image Generation)中不适用。
解决思路:逐Instance (channel) 计算均值和方差
出自文章《Instance Normalization: The Missing Ingredient for Fast Stylization》,《Image Style Transfer Using Convolutional Neural Networks》

不是将所有特征为1 一起计算,一行(3个2*2的正方形块)。而是一个通道一个通道计算(虚线,一个 2 ∗ 2 2*2 2∗2特征图)。
6.4.3 Group Normalization
起因:小 batch 样本中,BN 估计的值不准
解决思路:数据不够,通道来凑。每个样本的特征分为几组,每组特征分别计算均值和方差。可以看作是 Layer Normalization 的基础上添加了特征分组。
出自文章《Group Normalization》
注意事项:
- 不再有running_mean和running_var;
- γ \gamma γ 和 β \beta β为逐通道的
应用场景:大模型(小batch size)任务
7. 模型保存与加载
待续…
参考-深度之眼-PyTorch框架班
参考-github代码
参考-pytorch中文文档
参考-张贤同学-pytorch专栏