初学卷积——卷积的计算过程及应用场景
写在前面:
因为本人初学科学计算这一块,这两天遇到了卷积的问题,有点琢磨不透,就了解了一下卷积的计算过程及使用场景,因为时间太短,这里只能写下一点点个人的心得体会,希望大家多多包函与指教。
目录
- 一、卷积公式
- 二、卷积的翻转和平移
-
- 1.卷积的翻转
- 2.卷积的平移
- 三、卷积的计算方法
- 四、卷积的边缘效应
- 五、卷积的实际意义
- 六、convolve说明
- 七、参考
一、卷积公式
由于还没学习到二维卷积,所以我们这里只进行一维卷积的讨论。
- 离散卷积:
离散的数据,就好比是我们平时的考试成绩(0,1,2,…,100),离散卷积的公式如下:

这里i的定义域为负无穷到正无穷,当然具体的问题要具体分析,比如成绩(100分满分),那么i的定义域就是(0-100)。 - 连续卷积:
连续的数据,我们还是说成绩,但是这个老师比较牛*,他打分甚至可以个给你打根号,也就是说是0-100之间的所有实数。连续卷积的公式如下:

这里定积分的下限是负无穷,上限是正无穷,同理,还是具体情况具体分析,如果还是那个打分情况,那么就是下限为0,上限为100。
注:这里的*是卷积的符号,不是乘法。 - 公式说明:
我们可以从这两个公式中发现一个情况,就是无论是离散情况还是连续情况,都会有n = i + (n - i)和t = τ + (t - τ),那么这个问题我们后续在卷积翻转的时候再说明。
二、卷积的翻转和平移
1.卷积的翻转
卷积的翻转也即“卷”字的由来,由于本人技术有限绘制不了git图,所以这里用静态图片说明。
我们先讲解离散的情况(主要是连续的图太难画了呜呜呜)。我们以小学教学为例,只有语文和数学,各科满分100,且两者是相互独立的,互不干扰,那么假设小明总分195分,于是小明会有如下几个情况:
- 语文:95分;数学:100分。(出现的概率:g(195) = c(95) · m(100))
- 语文:96分;数学:99分。(出现的概率:g(195) = c(96) · m(99))
- 语文:97分;数学:98分。(出现的概率:g(195) = c(97) · m(98))
- 语文:98分;数学:97分。(出现的概率:g(195) = c(98) · m(97))
- 语文:99分;数学:96分。(出现的概率:g(195) = c(99) · m(96))
- 语文:100分;数学:95分。(出现的概率:g(195) = c(100) · m(95))
那么所有的概率即上述六个的求和,也即离散的那个公式。相应的图示如下:
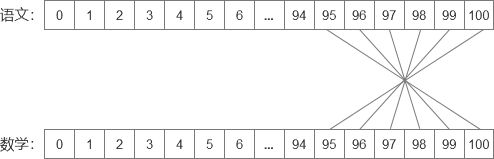
从上面的图看出这个线条错综复杂,是不是和你早上起来枕头上的头发一样凌乱,所以这里使用卷积的“卷”,对“语文”进行翻转,让他看的清晰一些。如下图所示:

这样的线条不凌乱了,但是数字还是倒着的,所以再对每个数字翻转一次。如下图所示:
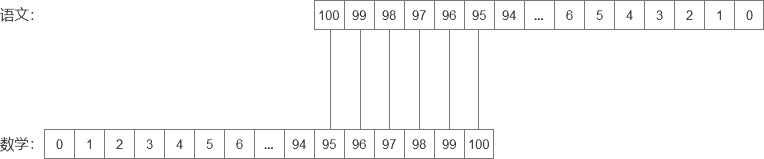
这样那么卷积的翻转就完成了,接下来就是卷积的平移问题。
2.卷积的平移
我们刚刚讨论的是195分的情况,那么如果是196分、197分甚至200分呢?那么就是上面(或者下面)的框框平移的过程了。如果学过计算机网络的同学,可以类比一下停止等待协议里面的滑动窗口,比较方便理解。
那么来到196分,196分的情况就比之前少了一种,各种情况分别是:
- 语文:96分;数学:100分。(出现的概率:g(196) = c(96) · m(100))
- 语文:97分;数学:99分。(出现的概率:g(196) = c(97) · m(99))
- 语文:98分;数学:98分。(出现的概率:g(196) = c(98) · m(98))
- 语文:99分;数学:97分。(出现的概率:g(196) = c(99) · m(97))
- 语文:100分;数学:96分。(出现的概率:g(196) = c(100) · m(96))
而对应的翻转后的图片如下:
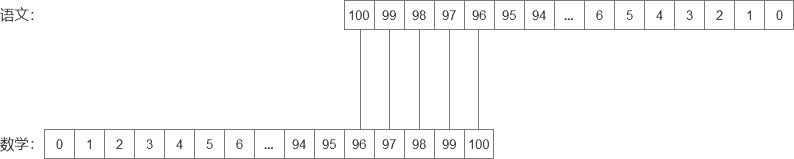
同理,当我们牛*轰轰的小明同学来到200分时,就只剩下唯一一种情况了:
- 语文:100分;数学:100分。(出现的概率:g(200) = c(100) · m(100))
而对应翻转后的图片如下:

我们就先假设小明考的总分从0-200都是等概率事件(即每个数字权重都相同),由于我们是从195分举例的,但是实际上总分为0也是可能出现的,所以整个窗口是从0-0一直移动至100-100为止,这就是平移,当然这里也会涉及到边缘效应的问题,下面再谈。
上面说的都是离散的情况,但是连续的情况也是同样的操作方式,而学习过高数的同学都懂,连续的情况无非就是求两个部分的面积总和。
三、卷积的计算方法
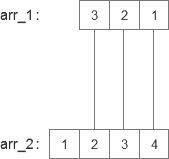
这里我们还是用离散的数据进行计算说明(主要还是积分看着都头大),当然100这个数据太大了,我们就另外取两个一维数组来计算,数组如下:

翻转后的数组如下:
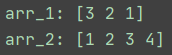
首先我们重温一下离散的卷积公式:
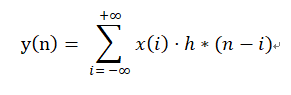
第一步我们要求n的值,我们看到arr_1有3个数据,arr_2有4个数据,所以n = 3 + 4 = 7。7就有以下6种情况构成:
- 1 + 6
- 2 + 5
- 3 + 4
- 4 + 3
- 5 + 2
- 6 + 1
那么也就可以说明我们要平移6次,我这里详细讲解每一次的过程。
第一次,也就是1对应1的时候,图片如下:
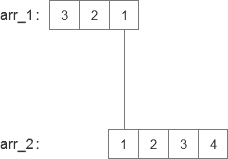
这时候我们执行x(i) · h(n - i)获得结果为1,因为就这么一个数据,所以求和后依旧为1,所以这时候卷积之后的数组中有了第一个数[1]。
第二次,也就是2对应1,1对应2的情况,图片如下:
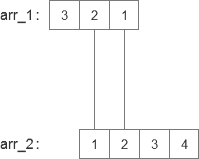
同理,执行x(i) · h(n - i)获得结果分别为2与2,求和之后为4,于是数组中有了第二个数,现在数组是[1 4]。
第三次,这时候我们发现arr_1和arr_2完全重叠了,关于重叠的问题下面和边缘效应一起讨论,图片如下:

执行公式后,数据分别为3、4、3,求和后数据为10,数组继续添加,为[1 4 10]。
依次执行相同步骤后,来到最后一步,就是3与4对应的时候,图片如下:
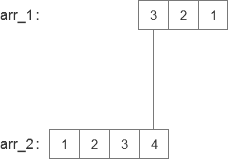
这时候只有一个数据了,得到12,添加至数组,数组也就完满了,数组为[1 4 10 16 17 12],卷积也就到此结束了。
四、卷积的边缘效应
由于本人查阅了相关资料,也没得到比较好的解答(也有可能是我不会查资料),所以我这里就粗略、浅显的谈一谈我对边缘效应的理解。
从图片来看,那么边缘效应指的就是两个数组没有完全重叠在一起的部分,如果用刚刚[1 2 3]和[1 2 3 4]的例子来说,那么重叠的部分就只有2种情况,即:

也就是说,其余的4种情况全存在边缘效应,也就是说会或多或少影响到数据。就好比我们烧了一盆书,还一直在往里面丢书,我们想知道某一时刻的温度与烧了的书的关系,但是之前还有一些书没有烧透彻,还可以提供点点火星,那是不是会对温度的测量造成点点误差?
五、卷积的实际意义
我们从一个系统来思考,只要系统不是及时响应的,那么我们在输入一个冲击的时候,会因为系统中的某些不可抗拒的因素影响到整个过程,而我们想求其中某个过程状态的时候就需要卷积。
就还是拿刚刚烧书的过程来说,我们将书丢进火里面就是一个冲击,但是之前还有些星星火会影响到现在的情况,也就是过去的东西会影响到现在;或者说我们吃饭的问题,比如我们早饭吃多了或者吃晚了,那么我们午饭就会吃得少或者也吃的晚,这就是卷积的实际使用场景,反映了一个变化情况的过程。
由于我也还在门口徘徊,所以要具体拿来相关的例子还是十分困难的呜呜呜。
六、convolve说明
convolve(a, v, mode='full')
Parameters
----------
a : (N,) array_like
First one-dimensional input array.
v : (M,) array_like
Second one-dimensional input array.
mode : {'full', 'valid', 'same'}, optional
'full':
By default, mode is 'full'. This returns the convolution
at each point of overlap, with an output shape of (N+M-1,). At
the end-points of the convolution, the signals do not overlap
completely, and boundary effects may be seen.
'same':
Mode 'same' returns output of length ``max(M, N)``. Boundary
effects are still visible.
'valid':
Mode 'valid' returns output of length
``max(M, N) - min(M, N) + 1``. The convolution product is only given
for points where the signals overlap completely. Values outside
the signal boundary have no effect.
这是numpy中convolve函数的源码中的注释,我用我蹩脚的英语翻译能力+翻译工具简单说明一下,传入的参数有3个,a、v、mode,其中a、v是必填的,mode是选填的,默认值为full。
a:第一个输入的一维数组。
v:第二个输入的一维数组。
mode:模式,共有3种,“full”,“same”,“valid”,默认full。
- full:默认模式,返回的是每个重叠点的卷积,卷积的输出形状为(N + M - 1),在卷积的端点信号不完全重叠,且存在边缘效应。
说明:这就是我们刚刚讨论的那种情况,N就是len(a),M就是len(v),存在的边缘效应看第三大点与第四大点也能够理解。 - same:返回的是M和N中最大值的,依旧存在边界效应。
说明:由于本人看源码技术还不够熟练,所以我只能在做测试的时候发现,最大值的取法就是从无边缘效应的部分开始向外扩展。 - valid:返回的就是信号重叠区域的卷积,不会返回存在边缘效应的部分,返回的长度为max(M, N) - min(M, N) + 1。
七、参考
[1] Ivan Idris.python数据分析基础教程NumPy学习指南(第2版)〔M〕.人民邮电出版社,2014:54-58.
[2] QLMX.numpy中的convolve的理解.CSDN,2017
[3] 小元老师.【小动画】彻底理解卷积【超形象】卷的由来,小元老师.哔哩哔哩.2020