Pyotorch自定义损失函数
1.损失函数知识总结参考:
深度学习笔记总结_GoAI的博客-CSDN博客
PyTorch 笔记.常见的PyTorch损失函数 - 知乎
Pytorch神经网络实战学习笔记_10 神经网络模块中的损失函数_LiBiGor的博客-CSDN博客
2.自定义损失函数学习参考:
pytorch教程之nn.Module类详解——使用Module类来自定义模型
pytorch教程之nn.Module类详解——使用Module类来自定义网络层
pytorch教程之损失函数详解——多种定义损失函数的方法
- Loss Function Library - Keras & PyTorch | Kaggle
- Pytorch如何自定义损失函数(Loss Function)? - 知乎
- pytorch系列12 --pytorch自定义损失函数custom loss function_墨流觞的博客-
- 自定义损失函数 - image processing
- pytorch教程之损失函数详解——多种定义损失函数的方法
- Pytorch自定义网络结构+读取自己数据+自定义Loss 全过程代码示例
3.定义原始模版:
使用torch.Tensor提供的接口实现:
- 继承nn.Module类
- 在__init__函数中定义所需要的超参数,在foward函数中定义loss的计算方法。
- 所有的数学操作使用tensor提供的math operation
- 返回的tensor是0-dim的scalar
- 有可能会用到nn.functional中的一些操作
- Pytorch如何自定义损失函数(Loss Function)? - 知乎
#例子:
class myLoss(nn.Module):
def __init__(self,parameters)
self.params = self.parameters
def forward(self)
loss = cal_loss(self.params)
return loss
#使用
criterion=myLoss()
loss=criterion(……)4.自定义函数方法
方法一:新建一个类
方案1:只定义loss函数的前向计算公式
在pytorch中定义了前向计算的公式,在训练时它会自动帮你计算反向传播。
class My_loss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.mean(torch.pow((x - y), 2))
#使用:
criterion = My_loss()
loss = criterion(outputs, targets)方案2:自定义loss函数的forward和backward
from numpy.fft import rfft2, irfft2
class BadFFTFunction(Function):
def forward(self, input):
numpy_input = input.numpy()
result = abs(rfft2(numpy_input))
return input.new(result)
def backward(self, grad_output):
numpy_go = grad_output.numpy()
result = irfft2(numpy_go)
return grad_output.new(result)方法二: 自定义函数
看一自定义类中,其实最终调用还是forward实现,同时nn.Module还要维护一些其他变量和状态。不如直接自定义loss函数实现:
# 直接定义函数 , 不需要维护参数,梯度等信息
# 注意所有的数学操作需要使用tensor完成。
def my_mse_loss(x, y):
return torch.mean(torch.pow((x - y), 2))
自定义损失的案例
1.通过自定义一个损失函数类来实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 第一步:自定义损失函数
继承nn.Mdule
class My_loss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.mean(torch.pow((x - y), 2))
2.准备数据
# 第二步:准备数据集,模拟一个线性拟合过程
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 将numpy数据转化为torch的张量
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
3.构建模型
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
# 第三步: 构建模型,构建一个一层的网络模型
model = nn.Linear(input_size, output_size)
# 与模型相关的配置、损失函数、优化方式
# 使用自定义函数,等价于criterion = nn.MSELoss()
criterion = My_loss()
# 定义迭代优化算法, 使用的是随机梯度下降算法
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
4.训练模型
loss_history = []
# 第四步:训练模型,迭代训练
for epoch in range(num_epochs):
# 前向传播计算网络结构的输出结果
outputs = model(inputs)
# 计算损失函数
loss = criterion(outputs, targets)
# 反向传播更新参数,三步策略,归零梯度——>反向传播——>更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息和保存loss
loss_history.append(loss.item())
if (epoch+1) % 5 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
'''运行结果为:
Epoch [5/60], Loss: 33.1027
Epoch [10/60], Loss: 13.5878
Epoch [15/60], Loss: 5.6819
Epoch [20/60], Loss: 2.4788
Epoch [25/60], Loss: 1.1810
Epoch [30/60], Loss: 0.6551
Epoch [35/60], Loss: 0.4418
Epoch [40/60], Loss: 0.3552
Epoch [45/60], Loss: 0.3199
Epoch [50/60], Loss: 0.3055
Epoch [55/60], Loss: 0.2994
Epoch [60/60], Loss: 0.2968
'''
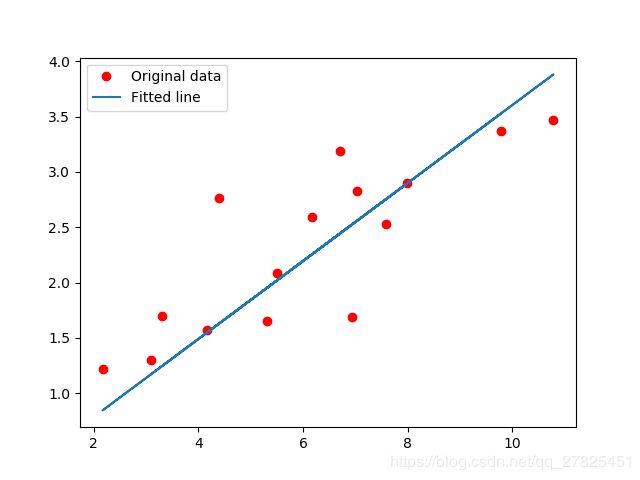
5.结果展示
# 第五步:结果展示。画出原y与x的曲线与网络结构拟合后的曲线
predicted = model(torch.from_numpy(x_train)).detach().numpy() #模型输出结果
plt.plot(x_train, y_train, 'ro', label='Original data') #原始数据
plt.plot(x_train, predicted, label='Fitted line') #拟合之后的直线
plt.legend()
plt.show()
# 画loss在迭代过程中的变化情况
plt.plot(loss_history, label='loss for every epoch')
plt.legend()
plt.show()
运行结果为:

自定义损失函数部分未完待续!!!
Pytorch完整训练流程
1.限定使用GPU的序号
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '3'
os.system('echo $CUDA_VISIBLE_DEVICES')
2、导入相关库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
from torch.autograd import Variable
import numpy as np
from Encoding import load_feature
3、自定义网络
class TransientModel(nn.Module):
def __init__(self):
super(TransientModel,self).__init__()
self.conv1 = nn.Conv2d(16, 8, kernel_size=1)
self.conv2 = nn.Conv2d(8, 4, kernel_size=1)
self.conv3 = nn.Conv2d(4, 2, kernel_size=1)
self.conv4 = nn.Conv2d(2, 1, kernel_size=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
return x
4、自定义损失函数Loss
class MyLoss(nn.Module):
def __init__(self):
super(MyLoss, self).__init__()
print '1'
def forward(self, pred, truth):
truth = torch.mean(truth,1)
truth = truth.view(-1,2048)
pred = pred.view(-1,2048)
return torch.mean(torch.mean((pred-truth)**2,1),0)
5、自定义数据读取
class MyTrainData(data.Dataset):
def __init__(self):
self.video_path = '/data/FrameFeature/Penn/'
self.video_file = '/data/FrameFeature/Penn_train.txt'
fp = open(self.video_file,'r')
lines = fp.readlines()
fp.close()
self.video_name = []
for line in lines:
self.video_name.append(line.strip().split(' ')[0])
def __len__(self):
return len(self.video_name)
def __getitem__(self, index):
data = load_feature(os.path.join(self.video_path,self.video_name[index]))
data = np.expand_dims(data,2)
return data
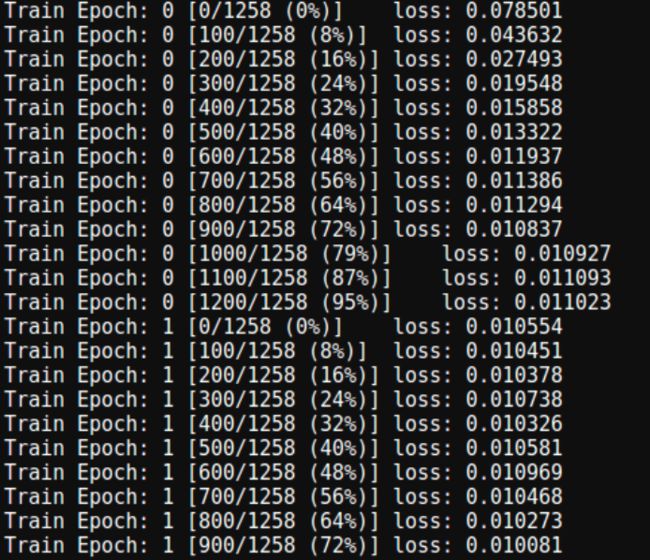
6、定义Train函数
def train(model, train_loader, myloss, optimizer, epoch):
model.train()
for batch_idx, train_data in enumerate(train_loader):
train_data = Variable(train_data).cuda()
optimizer.zero_grad()
output = model(train_data)
loss = myloss(output, train_data)
loss.backward()
optimizer.step()
if batch_idx%100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tloss: {:.6f}'.format(
epoch, batch_idx*len(train_data), len(train_loader.dataset),
100.*batch_idx/len(train_loader), loss.data.cpu().numpy()[0]))
7.训练
if __name__=='__main__':
# main()
model = TransientModel().cuda()
myloss= MyLoss()
train_data = MyTrainData()
train_loader = data.DataLoader(train_data,batch_size=1,shuffle=True,num_workers=1)
optimizer = optim.SGD(model.parameters(),lr=0.001)
for epoch in range(10):
train(model, train_loader, myloss, optimizer, epoch)
8、结果展示
完整代码
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '3'
os.system('echo $CUDA_VISIBLE_DEVICES')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
from torch.autograd import Variable
import numpy as np
from Encoding import load_feature
class TransientModel(nn.Module):
def __init__(self):
super(TransientModel,self).__init__()
self.conv1 = nn.Conv2d(16, 8, kernel_size=1)
self.conv2 = nn.Conv2d(8, 4, kernel_size=1)
self.conv3 = nn.Conv2d(4, 2, kernel_size=1)
self.conv4 = nn.Conv2d(2, 1, kernel_size=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
return x
class MyLoss(nn.Module):
def __init__(self):
super(MyLoss, self).__init__()
print '1'
def forward(self, pred, truth):
truth = torch.mean(truth,1)
truth = truth.view(-1,2048)
pred = pred.view(-1,2048)
return torch.mean(torch.mean((pred-truth)**2,1),0)
class MyTrainData(data.Dataset):
def __init__(self):
self.video_path = '/data/FrameFeature/Penn/'
self.video_file = '/data/FrameFeature/Penn_train.txt'
fp = open(self.video_file,'r')
lines = fp.readlines()
fp.close()
self.video_name = []
for line in lines:
self.video_name.append(line.strip().split(' ')[0])
def __len__(self):
return len(self.video_name)
def __getitem__(self, index):
data = load_feature(os.path.join(self.video_path,self.video_name[index]))
data = np.expand_dims(data,2)
return data
def train(model, train_loader, myloss, optimizer, epoch):
model.train()
for batch_idx, train_data in enumerate(train_loader):
train_data = Variable(train_data).cuda()
optimizer.zero_grad()
output = model(train_data)
loss = myloss(output, train_data)
loss.backward()
optimizer.step()
if batch_idx%100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tloss: {:.6f}'.format(
epoch, batch_idx*len(train_data), len(train_loader.dataset),
100.*batch_idx/len(train_loader), loss.data.cpu().numpy()[0]))
def main():
model = TransientModel().cuda()
myloss= MyLoss()
train_data = MyTrainData()
train_loader = data.DataLoader(train_data,batch_size=1,shuffle=True,num_workers=1)
optimizer = optim.SGD(model.parameters(),lr=0.001)
for epoch in range(10):
train(model, train_loader, myloss, optimizer, epoch)
if __name__=='__main__':
main()