机器翻译模型一多层LSTM__Pytorch实现
目录
1.机器翻译之Seq2Seq介绍
2.基于Pytorch的Seq2Seq实现
2.1数据准备
2.2模型建立
2.3训练
1.机器翻译之Seq2Seq介绍
Seq2Seq模型是一个序列到序列的模型,在NLP中被广泛应用于翻译。其网络的模型结构大致如下:
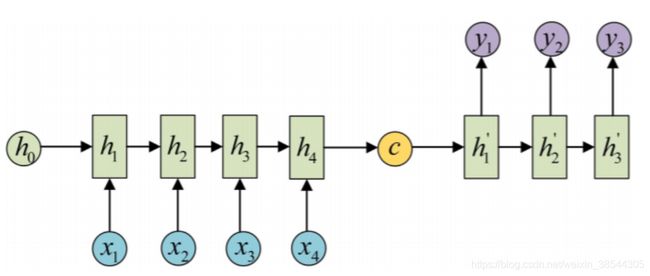
在机器翻译中,其将需要被翻译的语言序列在源端(编码器)经过RNN模型最终压缩为一个上下文向量(C),接着目标端(解码器)对上下文向量进行解码,将器输出分类映射到我们需要翻译的语言空间中。这里仅仅给出最初始的Seq2Seq模型图(attention机制的c则映射到解码器中的每个解码器,而非单单是第一个解码器)。由于传统的RNN模型会产生梯度消失或梯度爆炸的问题,因此RNN常用的模型常选LSTM或GRU。(只介绍LSTM,GRU是变种的LSTM,目的为了减少参数)
LSTM通过引入gate机制,减缓了梯度消失和梯度爆炸的问题。如结构如下:

首先,设置了3个门,分别为遗忘门,输入门,更新门。其计算公式均为:
![]()
我们知道,sigmoid函数的值为0~1之间,这可以可以将对应的输入与门进行按位相乘进行过滤。
对于遗忘门来说,前面的记忆不需要全部学习,因此,上一时刻的记忆 不需要全部保留,通过遗忘门会进行过滤。
不需要全部保留,通过遗忘门会进行过滤。
![]()
对于输入门来说或,我新学得的记忆也不需要全部记得清清楚楚,因为细节包含冗余。这一次学习的新记忆为(短期记忆):
![]()
经过输入门则是:
![]()
那么我们当前的记忆则不仅仅包含新学的记忆,也包括之前的记忆,那么当前记忆为(长期记忆):
![]()
这一步加法操作也是正是LSTM梯度不消失或者爆炸的原因,传统的RNN模型这里则是通过连乘的形式,则我们可以想象![]() 与
与![]() ,这就是传统RNN存在梯度消失或者爆炸的原因。
,这就是传统RNN存在梯度消失或者爆炸的原因。
对于输出门,我们有了当前的记忆以后,我们要根据当前的要求有选择性的输出,选择先经过tanh将其值规范到[-1,1](有放大特征的作用),后经过输出门进行选择。
则输出门的输出为:
![]()
我们可以发现,经过三个门过滤,最大的损失是什么?是之前的记忆,这也是LSTM的一个弊端,即当前记忆偏向于最新记忆,一旦序列过长,则长程依赖的关系会很弱。我们可以想象一下,还是这个图:
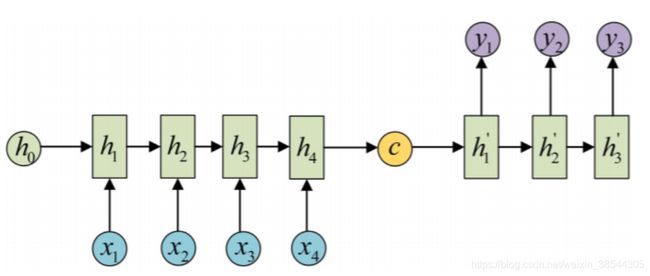
其中的上下文向量C保存最多的肯定是源端中4时刻的信息,而1时刻的信息也保存很少。而我们在翻译的时候,第一个翻译的词很可能就很依赖于源端1时刻的输入,但是此时C包含其信息甚少,而我们也可以想象,如果第一个词都翻译不好,其作为下一时间步的输入(目标端每一时间步的输出是下一时间步的输入),那么后面的质量也会大打折扣。具体过程如下:
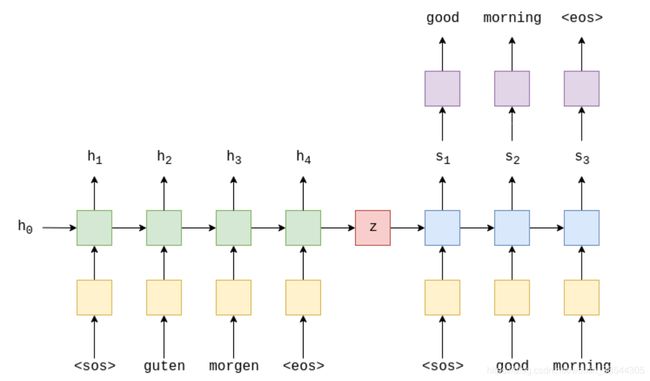
我们在嵌入层(黄色)后使用编码器(绿色)来创建上下文向量(红色)。然后,我们使用将上下文向量和输入到解码器(蓝色)并通过线性层(紫色)来生成目标句子。
针对这个问题,学术界提出各种各样的改进方法,后面我会慢慢学习总结,这里先给出最简单的:《Sequence to Sequence Learning with Neural Networks》这篇文章指出一种最简单训练技巧,即将我们源端序列倒序,即:
I love you的输入变成you love I。这样我们的上下文向量C保存最多的肯定是I,在解码器第一个翻译我的时候,也会比较准确。下面我们将着手实现:
2.基于Pytorch的Seq2Seq实现
工具:Jupyter
2.1数据准备
数据集采用pytorchtext自带的Multi30k数据集,选用其中德语和英语的翻译(分词比较容易)。而pytorchtext处理数据的一般流程无非就是,定义好Field,将数据集的数据经过Field处理,给Field建立词表,建立数据迭代器。
import spacy
import torch
from torchtext.datasets import Multi30k
from torchtext.data import Field,BucketIterator定义Field处理方式:
#创建分词器器
spacy_en=spacy.load("en_core_web_sm")#英语分词器
spacy_de=spacy.load("de_core_news_sm")#德语分词器
def en_seq(text):
return [word.text for word in spacy_en.tokenizer(text)]
def de_seq(text):
return [word.text for word in spacy_de.tokenizer(text)][::-1]#源端倒序
#源端的处理手段
SRC=Field(tokenize=de_seq,
init_token="",
eos_token="",
lower=True)
#目标端的处理手段
TRG=Field(tokenize=en_seq,
init_token="",
eos_token="",
lower=True) 将数据集经过Field处理,因为是pytorchtext内置数据集,所以处理起来也很容易,
#定义dataset数据集,这里将其数据经过fiels处理
train_data,valid_data,test_data=Multi30k.splits(exts=(".de",".en"),
fields=(SRC,TRG))
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of validation examples: {len(valid_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")这里也查看了训练样本,验证样本以及测试样本的规模,输出为:
Number of training examples: 29000
Number of validation examples: 1014
Number of testing examples: 1000查看一下每一个样本,主要也是观察是否源端是否逆序:
vars(train_data.examples[1])输出为:
{'src': ['.','antriebsradsystem','ein','bedienen','schutzhelmen','mit','männer',
'mehrere'],
'trg': ['several','men','in','hard','hats','are','operating','a',
'giant','pulley','system','.']}可以发现源端已经逆序。接下来为源端和目标端分别建立词表,要求每个词最少出现2次,否则为
SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)建立好词表以后,我们建立迭代索引,若batch_size=1的话,文本长度不相等也是无所谓的,但是batch_size>1的时候,就有有问题,同一批样本不一样长,那么我们在训练的时候,循环时间步到底设置多少,所以一般我们都会对句子进行pad操作补齐,幸运的是torchtext迭代器自动帮助pad填充,其中BucketIterator迭代器更是选择最合适的长度作为所有句子的固定长度,低于词长度的进行pad,高于此长度则进行裁剪。(这个固定长度是依据数据集里面所有的样本长度得出最合适的)
BATCH_SIZE = 128
cuda=torch.cuda.is_available()
train_iterator, valid_iterator, test_iterator=BucketIterator.splits(
(train_data,valid_data,test_data),
batch_size=BATCH_SIZE,
device=torch.device('cuda' if cuda else 'cpu')
)测试数据迭代器
for example in train_iterator:
break
print(example.src.device,example.trg.device,len(example))
print(example.src.shape,example.trg.shape)其输出为:
cuda:0 cuda:0 128
torch.Size([27, 128]) torch.Size([28, 128]我们发现输出的样本是[seq_len,batch_size],而非[batch_size,seq_len]。我的习惯是batch_size放前面,但是Pytorch机制默认的是seq_len放在前面,后面的LSTM也是一样的。针对这个问题,可以通过permute函数进行交换
example.src=example.src.permute(1,0)
example.trg=example.trg.permute(1,0)
print(example.src.shape,example.trg.shape)输出为:
torch.Size([128, 27]) torch.Size([128, 28])这里我们必须要知道填充的位置,即
TRG.vocab.stoi[""],SRC.vocab.stoi[""] 得到其索引均为1。
2.2模型建立
Seq2Seq模型主要就是两个部分,即分别是编码器,解码器。我们写3个模块,分别是encoder,decoder以及集两部分大成的Seq2Seq。其中源端与目标端的网络深度均为4层(原文也是4层)
import torch.nn as nnclass Encoder(nn.Module):
#src_vocab_size德语词汇表大小,emb_model词向量维度,hidden_size隐藏向量维度,n_layers lstm深度
def __init__(self,src_vocab_size,emb_model,hidden_size,n_layers,dropout):
super(Encoder,self).__init__()
self.embed=nn.Embedding(src_vocab_size,emb_model,padding_idx=1)
self.lstm=nn.LSTM(input_size=emb_model,hidden_size=hidden_size,num_layers=n_layers,batch_first=True,dropout=dropout)
def forward(self,src):
#src[batch_size,seq_len]
src=self.embed(src)
#src[batch_size,seq_len,emb_model]
output,(h_n,c_n)=self.lstm(src)
#output[batch_size,seq_len,hidden_size] 最后一层每个时间步的隐状态h_t
#h_n[batch_size,n_layers,hidden_size] 最后一个时间步每层的隐状态(实际上并非这样,Pytorch机制原因)
#c_n[batch_size,n_layers,hidden_size] 最后一个时间步每层的记忆c(实际上并非这样,Pytorch机制原因)
return output,(h_n,c_n)#output的意义不大,主要是(h_n,c_n),其作为上下文向量这里要重点提示一下的是:LSTM默认输入的是[seq_len,batch_size,embed]。若输入的是[batch_size,seq_len,embed],则需要将batch_first参数填写True。另一个值得注意的是LSTM的输出有3个变量,即output,(h_n,c_n),其中output是LSTM最后一层每个时间步的输出,h_n和_c_n为最后一个时间步每层的隐状态和记忆,其中经过batch_first以后,我们的输出是[batch_size,seq_len,hidden_size*n_direction]。但是h_n与c_n的shape均为[n_layers*n_direction,batch_size,hidden_size],其并未将batch_size放于首位,以下进行编码器模型的测试与这个注意点检验:
#测试,参数
emb_model=256
hidden_size=512
n_layers=4
dropout=0.5
src_vocab_size=len(SRC.vocab)#输入样本的维度
example.src.shape输出为:
torch.Size([128, 27])#建立源端模型
enModel=Encoder(src_vocab_size,emb_model,hidden_size,n_layers,dropout)
if(cuda):
enModel=enModel.cuda()
output,(h_n,c_n)=enModel(example.src)
#只有输入input和输出output的batch会在第一维,hn和cn是不会变的。使用的时候要注意,会很容易弄混。
output.shape,h_n.shape,c_n.shape输出为:
(torch.Size([128, 27, 512]),
torch.Size([4, 128, 512]),
torch.Size([4, 128, 512]))下面建立目标端,目标端的起始与源端几乎一样,不过与源端不一样的地方在于,目标端的输入不是特定的,其采用教学的形式,即要么自学(即上一时间步的输出是当前时间步的输入),要么教学(当前时间步的输入为目标端)。因此,在目标端中,我们无法一次性给定一个单词序列,而是一个一个单词的给入,即输入的seq_len=1。最后模型的输出我们需要将其映射到英语单词的向量空间中。还有一个值得需要提的就是lstm若不传入h和c则默认帮你创建一个全为0的h和c但是我们这里需要传入,传入的h和c不能以batch为开头!格式为[n_layers*n_direction,batch_size,hidden_size]。Pytorch为什么有了batch_first这里还不管,因为我们正常这两个参数用不到可能(个人猜测)
class Decoder(nn.Module):
#trg_vocab_size 目标端的词汇表大小
#emb_dim为词向量维度(我们将其设置与源端一样大小)
#hidden_size 为目标端隐层维度(将其设置为与源端一样大小)
#n_layers 网络层数(将其设置为一样大小)
def __init__(self,trg_vocab_size,emb_dim,hidden_size,n_layers,dropout):
super(Decoder,self).__init__()
self.emb=nn.Embedding(trg_vocab_size,emb_dim,padding_idx=1)
self.lstm=nn.LSTM(emb_dim,hidden_size,num_layers=n_layers,batch_first=True,dropout=dropout)
self.classify=nn.Linear(hidden_size,trg_vocab_size)
def forward(self,trg,h_n,c_n):
#trg为应该为[batch,seq_len],不过实际训练中是一个一个传入(要考虑是否采用强制教学),所以seq_len为1
#trg真正的输入维度为[batch]
#h_n与c_n是源端的上下文向量(若计算不指定,则默认为0(若Encoder编码中))
#维度均为:[n_layers,batch_size,hidden_size]
trg=trg.unsqueeze(1)
#trg[batch,1]
trg=self.emb(trg)
#trg[batch,1,emb]
output,(h_n,c_n)=self.lstm(trg,(h_n,c_n))#这里的lstm指定了h,c,因此其内部不会自己创建一个全为0的h,c
#output[batch,1,emb]
#h_i[1,batch,emb]
#c_i[1,batch,emb]
output=self.classify(output.squeeze())#output.squeeze()使得output[batch 1 emb]->[batch emb]
#output[batch trg_vocab_size]
return output,(h_n,c_n) #返回(h_n,c_n)是为了下一解码器继续使用测试:
#测试,参数
trg_vocab_size=len(TRG.vocab)Demodel=Decoder(trg_vocab_size,emb_model,hidden_size,n_layers,dropout)
if cuda:
Demodel=Demodel.cuda()
#查看目标端的shape
example.trg.shape结果为:
torch.Size([128, 28])我们每次的输入是一个单词,我们取其中某一列:
trg=example.trg[:,1]#假设这一次为强制教学
output,(h_n,c_n)=Demodel(trg,h_n,c_n)
h_n.shape,c_n.shape输出为:
(torch.Size([4, 128, 512]), torch.Size([4, 128, 512]), torch.Size([128, 5893]))下面建立Seq2Seq
import random#生成本次强制教学的概率我们用一个tensor保存每一个时间步映射到英语单词向量空间的输出(其实就是每一个Decode的输出),每一个输出所在概率最大的分类即为需要翻译的单词,我们需要遍历句子中的每一个单词。还有一个值得注意的就是,由于我们在句子开头设置的
class Seq2Seq(nn.Module):
def __init__(self,encoder,decoder):
super(Seq2Seq,self).__init__()
self.encoder=encoder
self.decoder=decoder
def forward(self,src,trg,teach_rate=0.5):
#src [bacth,seq_len]
#trg [bacth,seq_len]
#teach_radio 强制教学的阈值
batch_size=trg.shape[0]
trg_seqlen=trg.shape[1]
#保存每次输出的结果
outputs_save=torch.zeros(batch_size,trg_seqlen,trg_vocab_size)
if(cuda):
outputs_save=outputs_save.cuda()
#对源端进行编码
_,(h_n,c_n)=self.encoder(src)
#第一个输入到解码器中为
trg_i=trg[:,0]
#trg_i [batch]
for i in range(1,trg_seqlen):
output,(h_n,c_n)=self.decoder(trg_i,h_n,c_n)
#output[batch trg_vocab_size]
outputs_save[:,i,:]=output
#产生一个随机概率(即是否强制教学)
probability=random.random()
#获取时间步预测的结果
top=output.argmax(1)
#top[batch]
#下一时间步的输入
trg_i=trg[:,i] if probability>teach_rate else top
return outputs_save 测试:
#测试
model=Seq2Seq(enModel,Demodel)
if(cuda):
model=model.cuda()
outputs=model(example.src,example.trg)outputs.shape输出为:
torch.Size([128, 28, 5893])2.3训练
from torch.optim import Adamepochs=10
optim=Adam(model.parameters())
criterion = nn.CrossEntropyLoss(ignore_index = 1)#pad不参与损失函数的计算查看网络模型:
model输出:
Seq2Seq(
(encoder): Encoder(
(embed): Embedding(7854, 256, padding_idx=1)
(lstm): LSTM(256, 512, num_layers=4, batch_first=True, dropout=0.5)
)
(decoder): Decoder(
(emb): Embedding(5893, 256, padding_idx=1)
(lstm): LSTM(256, 512, num_layers=4, batch_first=True, dropout=0.5)
(classify): Linear(in_features=512, out_features=5893, bias=True)
)
)对网络参数进行初始化:-0.8,+0.8,这也是原文的配置
#参数初始化
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)分别建立训练和测试函数(写开),其中model.train()和model.eval()主要的作用在于在训练的时候我们dropout会随机丢弃神经元,而在测试阶段的时候,不在进行丢弃神经元。
def train(model,train_iter,optim,criterion):
model.train()#即dropout产生作用
epoch_loss=0
for i,example in enumerate(train_iter):
src=example.src.permute(1,0)
trg=example.trg.permute(1,0)
#src[batch seqlen]
#trg[batch seqlen]
optim.zero_grad()
output=model(src,trg)#output[batch trg_seqlen trq_vocab_size]
#不参与运算,pad也不参与运算(criterion已经设置了ignore)
output=output[:,1:,:].reshape(-1,trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output[batch*(trg_len-1),trg_vocab_size]
#trg[batch*(trg_len-1)]
loss=criterion(output,trg)
loss.backward()
optim.step()
epoch_loss+=loss.item()
return epoch_loss/len(train_iter) def evaluate(model,test_iter,criterion):
model.eval()#即dropout产生作用
epoch_loss=0
with torch.no_grad():
for i,example in enumerate(test_iter):
src=example.src.permute(1,0)
trg=example.trg.permute(1,0)
#src[batch seqlen]
#trg[batch seqlen]
#即无法在进行强制教学
output=model(src,trg,0)#output[batch trg_seqlen trq_vocab_size]
#不参与运算,pad也不参与运算(criterion已经设置了ignore)
output=output[:,1:].reshape(-1,trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output[batch*(trg_len-1),trg_vocab_size]
#trg[batch*(trg_len-1)]
loss=criterion(output,trg)
epoch_loss+=loss.item()
return epoch_loss/len(test_iter) import time,math统计每个迭代器的一个训练周期:
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs训练,我们的损失函数简单表示为:困惑度
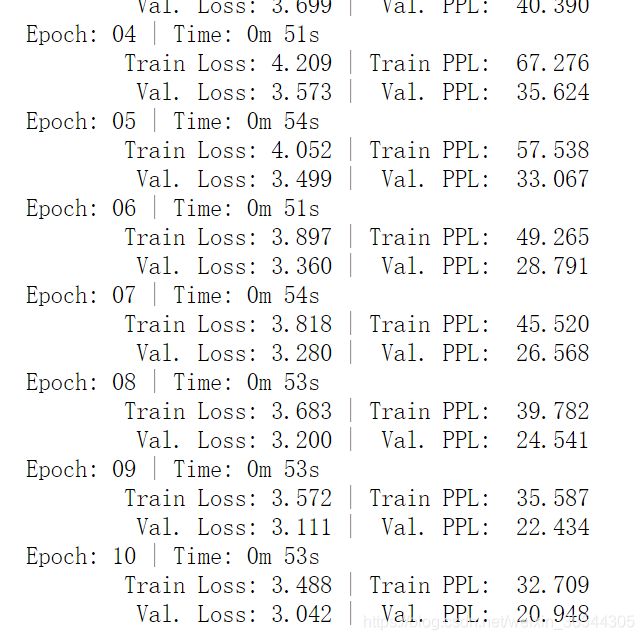
for epoch in range(epochs):
start_time=time.time()
train_loss=train(model,train_iterator,optim,criterion)
valid_loss=evaluate(model,valid_iterator,criterion)
end_time=time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')输出为:
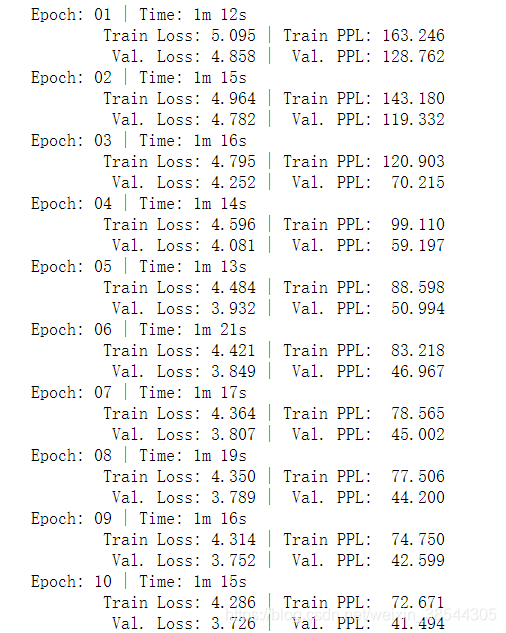
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')| Test Loss: 3.742 | Test PPL: 42.194 |原著是基于WMT14数据集,规模较大,因此设置了4层,其实这个数据集2层即可,收敛也很快,如下: