二分类的评价指标
评价指标
评价指标
在二分类任务中,评判分类模型好坏需要评判指标,接下来了解一下一些分类指标
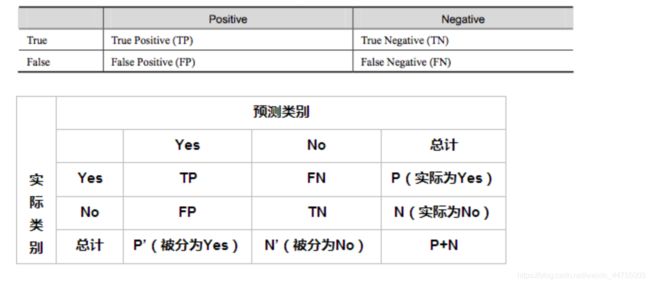
统计(混淆)矩阵
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
有了混淆矩阵的规定,接下来引入几个评价指标
精度(accuracy)
既可用于二分类任务,也可用于多分类任务,即分类正确的样本数占样本总数的比例
acc=(TP+TN)/(TP+FP+TN+FN)
错误率(error)
既可以用于二分类任务,也可用于多分类任务,即分类错误的样本数占总样本数的比例
E=(NP+FN)/(TN+TP+FN+FP)
对于分类任务而言,只知道分类任务中分类错误的占比和分类正确的占比并不够,正如错误率和正确率只能表示判别正确和判别错误的数量(而并不好将两个因素分开考虑)。正如有一车西瓜,其中有好瓜也有坏瓜,而如果关心的是挑出来的瓜中有多少是好瓜或者所有好瓜中有多少被挑出来了就需要新的评价指标。(更实际的例子是在互联网中,用户搜索的信息有多少是用户喜欢的,或者用户喜欢的信息中有多少是被搜索出来的)
查准率(precision)
查准率也称准确率用于解决之前挑出来的瓜中有多少是好瓜的问题而设计的评价指标
P=TP/(TP+FP)
查全率(recall)
查全率也称召回率用于解决之前有多少好瓜被挑出来的问题而设计的评价指标
R=TP/(TP+FN)
查准率与查全率是矛盾的度量,查准率高时,查全率一般都较低,相反可知。如果希望将好的瓜都挑出来,那么选瓜数量就会增加,如果都选上则查准率就会变低,反之,想要将挑选出来的瓜尽可能的挑出好瓜,那么必定选择最有把握的,必然会露掉一些好瓜。
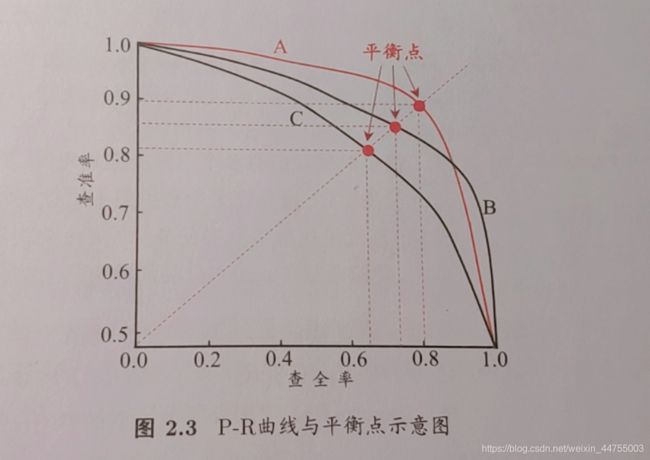
此图中A,B模型因为曲线高于C,因此比C模型的效果好,但是A,B有交叉,一般认为与坐标轴围成的面积大的模型效果好。
ROC与AUC
ROC全称“受试者工作特征”(Receiver Operating Characteristic),与P-R曲线类似,不同的是纵轴是“真正率" TPR,横轴是“假正率” FPR
TPR=TP/(TP+FN) //挑出来的好瓜占原来好瓜的比例
FPR=FP/(TN+FP) //挑出来的不好的瓜占原来不好的瓜的比例
由图中可以看出左图为理想的ROC曲线,而下方的阴影面积则记作AUC(Area Under ROC Curve),评判模型好坏的标准即是ROC曲线,高的曲线效果更好(理想点x(0,1)效果最好的点即为左上角的点),若两条曲线有交叉,AUC大的效果好。但是对于有限样例而言,并不可能达到左图的效果,作右图过程很简单:给定m+个正例和m-个反例,设前一个标记点坐标为(x,y),当前若为真,则对应坐标为(x,y+(1/m+)),若当前为假,则对应坐标为(x+(1/m-),y)。