SQL-一文get什么是CASE 表达式
写在前文
- 作者简介:大家好,我是小王♂️
- 个人主页:你隔壁的小王
- 欢迎点赞+收藏⭐️+留言
- 专栏:SQL♂️
♂️ 小伙伴们如果在学习过程中有不明白的地方,欢迎评论区留言提问!希望能和大家一起进步,共同成长!
目录
写在前文
CASE表达式基本使用规则
将已有编号方式转换为新的方式并统计
用一条 SQL 语句进行不同条件的统计
用 CHECK 约束定义多个列的条件关系
在 UPDATE 语句里进行条件分支
表之间的数据匹配
在 CASE 表达式中使用聚合函数
知识检验
CASE表达式基本使用规则
CASE 表达式有简单 CASE 表达式(simple case expression)和搜索 CASE 表达式(searched case expression)两种写法,如下所示。
-- 简单 CASE 表达式
CASE sex
WHEN ' 1 ' THEN ' 男 '
WHEN ' 2 ' THEN ' 女 '
ELSE ' 其他 ' END
-- 搜索 CASE 表达式
CASE WHEN sex = ' 1 ' THEN ' 男 '
WHEN sex = ' 2 ' THEN ' 女 '
ELSE ' 其他 ' END这两种写法的执行结果是相同的,“sex”列(字段)如果是 '1' ,那么结果为男;如果是 '2' ,那么结果为女。简单 CASE 表达式正如其名,写法简单,但能实现的事情比较有限。简单 CASE 表达式能写的条件,搜索CASE 表达式也能写,需要注意的是,在发现为真的 WHEN 子句时,CASE 表达式的真假值判断就会中止,而剩余的 WHEN 子句会被忽略。
-- 例如,这样写的话,结果里不会出现“第二”,因为在第一的时候出现了真值,并不会继续执行
CASE WHEN col_1 IN ( ' a ' , ' b ' ) THEN ' 第一 '
WHEN col_1 IN ( ' a ' ) THEN ' 第二 '
ELSE ' 其他 ' END注意事项:
1、统一各分支返回的数据类型
- CASE 表达式里各个分支返回的数据类型是否一致。某个分支返回字符型,而其他分支返回数值型的写法是不正确的。
2、不要忘了写 END
3、养成写 ELSE 子句的习惯
- 与 END 不同, ELSE 子句是可选的,不写也不会出错。不写 ELSE 子句时,CASE 表达式的执行结果是 NULL 。但是不写可能会造成“语法没有错误,结果却不对”这种不易追查原因的麻烦,所以最好明确地写上 ELSE 子句(即便是在结果可以为 NULL 的情况下。
将已有编号方式转换为新的方式并统计
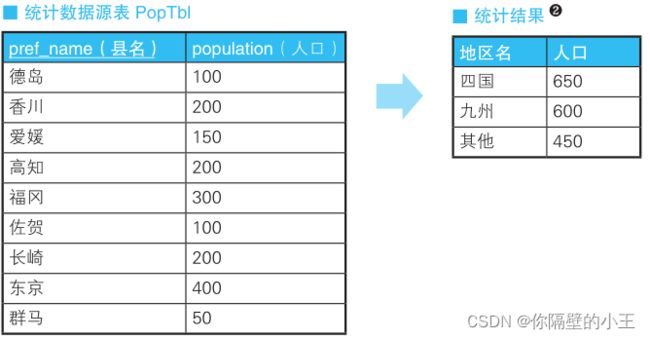
例如,现在有一张按照“‘1:北海道’、‘2:青森’、……、‘47:冲绳’”这种编号方式来统计都道府县 人口的表,我们需要以东北、关东、九州等地区为单位来分组,并统计人口数量。
-- 把县编号转换成地区编号 SELECT CASE pref_name WHEN ' 德岛 ' THEN ' 四国 ' WHEN ' 香川 ' THEN ' 四国 ' WHEN ' 爱媛 ' THEN ' 四国 ' WHEN ' 高知 ' THEN ' 四国 ' WHEN ' 福冈 ' THEN ' 九州 ' WHEN ' 佐贺 ' THEN ' 九州 ' WHEN ' 长崎 ' THEN ' 九州 ' ELSE ' 其他 ' END AS district, SUM(population) FROM PopTbl GROUP BY CASE pref_name WHEN ' 德岛 ' THEN ' 四国 ' WHEN ' 香川 ' THEN ' 四国 ' WHEN ' 爱媛 ' THEN ' 四国 ' WHEN ' 高知 ' THEN ' 四国 ' WHEN ' 福冈 ' THEN ' 九州 ' WHEN ' 佐贺 ' THEN ' 九州 ' WHEN ' 长崎 ' THEN ' 九州 ' ELSE ' 其他 ' END;这也写出的SQL必须在 SELECT 子句和 GROUP BY 子句这两处写一样的 CASE 表达式 ,较为麻烦,group by可以使用select中所定义的列,但是并不符合语法规范,因为执行的顺序是先group by 在进行select,所以在 Oracle、DB2、SQL Server 等数据库里采用这种写法时就会出错,在在 PostgreSQL 和 MySQL中,这个查询语句就可以顺利执行,虽然写出的语句简单可读性强,但是违反书写规范,谨慎使用!
用一条 SQL 语句进行不同条件的统计

常规写法:
-- 男性人口 SELECT pref_name, SUM(population) FROM PopTbl2 WHERE sex = ' 1 ' GROUP BY pref_name; -- 女性人口 SELECT pref_name, SUM(population) FROM PopTbl2 WHERE sex = ' 2 ' GROUP BY pref_name;但是这样查询出来的很麻烦,还需要后续组合
SELECT pref_name, -- 男性人口 SUM( CASE WHEN sex = ' 1 ' THEN population ELSE 0 END) AS cnt_m, -- 女性人口 SUM( CASE WHEN sex = ' 2 ' THEN population ELSE 0 END) AS cnt_f FROM PopTbl2 GROUP BY pref_name;总结来说:新手用 WHERE 子句进行条件分支,高手用 SELECT 子句进行条件分支。
用 CHECK 约束定义多个列的条件关系
CASE 表达式和 CHECK 约束是很般配的一对组合
假设某公司规定“女性员工的工资必须在 20 万日元以下”,而在这个公司的人事表中,这条无理的规定是使用 CHECK 约束来描述的,代码如下所示。
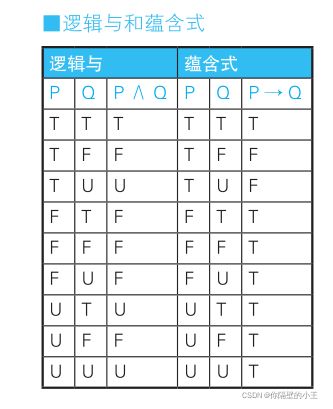
CONSTRAINT check_salary CHECK ( CASE WHEN sex = ' 2 ' THEN CASE WHEN salary <= 200000 THEN 1 ELSE 0 END ELSE 1 END = 1 )在这段代码里, CASE 表达式被嵌入到 CHECK 约束里,描述了“如果是女性员工,则工资是 20 万日元以下”这个命题。在命题逻辑中,该命题是叫作蕴含式(conditional)的逻辑表达式,记作 P → Q。逻辑与也是一个逻辑表达式,意思是“P 且 Q”,记作 P ∧ Q。用逻辑与改写的 CHECK 约束如下所示。
CONSTRAINT check_salary CHECK ( sex = ' 2 ' AND salary <= 200000 )但是这两种方式所表达的含义是不同的,如果在 CHECK 约束里使用逻辑与,该公司将不能雇佣男性员工。而如果使用蕴含式,男性也可以在这里工作。
在 UPDATE 语句里进行条件分支
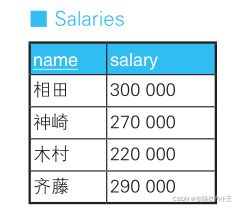
假设现在需要根据以下条件对该表的数据进行更新。
1. 对当前工资为 30 万日元以上的员工,降薪 10%。
2. 对当前工资为 25 万日元以上且不满 28 万日元的员工,加薪 20%。UPDATE Salaries SET salary = CASE WHEN salary >= 300000 THEN salary * 0.9 WHEN salary >= 250000 AND salary < 280000 THEN salary * 1.2 ELSE salary END;需要注意的是,SQL 语句最后一行的 ELSE salary 非常重要,必须写上。因为如果没有它,条件 1 和条件 2 都不满足的员工的工资就会被更新成 NULL 。
表之间的数据匹配
与 DECODE 函数等相比, CASE 表达式的一大优势在于能够判断表达式。也就是说,在 CASE 表达式里,我们可以使用 BETWEEN 、 LIKE 和 <、> 等便利的谓词组合,以及能嵌套子查询的 IN 和 EXISTS 谓词。因此, CASE表达式具有非常强大的表达能力。
-- 表的匹配 :使用 IN 谓词 SELECT course_name, CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200706) THEN ' ○ ' ELSE ' × ' END AS "6 月", CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200707) THEN ' ○ ' ELSE ' × ' END AS "7 月", CASE WHEN course_id IN (SELECT course_id FROM OpenCourses WHERE month = 200708) THEN ' ○ ' ELSE ' × ' END AS "8 月" FROM CourseMaster; -- 表的匹配 :使用 EXISTS 谓词 SELECT CM.course_name, CASE WHEN EXISTS (SELECT course_id FROM OpenCourses OC WHERE month = 200706 AND OC.course_id = CM.course_id) THEN ' ○ ' ELSE ' × ' END AS "6 月", CASE WHEN EXISTS (SELECT course_id FROM OpenCourses OC WHERE month = 200707 AND OC.course_id = CM.course_id) THEN ' ○ ' ELSE ' × ' END AS "7 月", CASE WHEN EXISTS (SELECT course_id FROM OpenCourses OC WHERE month = 200708 AND OC.course_id = CM.course_id) THEN ' ○ ' ELSE ' × ' END AS "8 月" FROM CourseMaster CM;无论使用 IN 还是 EXISTS ,得到的结果是一样的,但从性能方面来说,EXISTS 更好。

在 CASE 表达式中使用聚合函数
假设这里有一张显示了学生及其加入的社团的一览表。如表 StudentClub 所示,这张表的主键是“学号、社团 ID”,存储了学生和社团之间多对多的关系。
有的学生同时加入了多个社团(如学号为 100、200 的学生),有的学生只加入了某一个社团(如学号为 300、400、500 的学生)。对于加入了多个社团的学生,我们通过将其“主社团标志”列设置为 Y 或者 N 来表明哪一个社团是他的主社团;对于只加入了一个社团的学生,我们将其“主社团标志”列设置为 N。
接下来,我们按照下面的条件查询这张表里的数据。
1. 获取只加入了一个社团的学生的社团 ID。
2. 获取加入了多个社团的学生的主社团 ID。SELECT std_id, CASE WHEN COUNT(*) = 1 -- 只加入了一个社团的学生 THEN MAX(club_id) ELSE MAX(CASE WHEN main_club_flg = ' Y ' THEN club_id ELSE NULL END) END AS main_club FROM StudentClub GROUP BY std_id;新手用 HAVING 子句进行条件分支,高手用 SELECT 子句进行条件分支。

知识检验
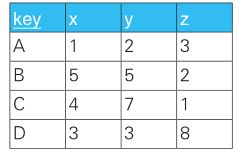
1、
从表里选出 x 和 y 二者中较大的值的情况。此时求得的结果应该如下所示。
--第一种方法 SELECT KEY , CASE WHEN x > y THEN x ELSE y END AS GREATEST FROM greatests --第二种方法,使用GREARSET函数 SELECT key , GREATEST(x,y) as greatest FROM greatests --只在Oracle 和 MySQL 数据库中生效2、请思考一个查询语句,使得结果按照 B-A-D-C 这样的指定顺序进行排列。
SELECT key FROM Greatests ORDER BY CASE key WHEN 'B' THEN 1 WHEN 'A' THEN 2 WHEN 'D' THEN 3 WHEN 'C' THEN 4 ELSE NULL END;