OpenCV实战——文本检测
OpenCV实战——文本检测
-
- tesseract的安装
- 代码实践
-
- 将图片中的内容识别打印,并绘制边框
- 单词(word)检测
- 只进行数字识别
tesseract的安装
首先说一下下官网的地址:下载地址
大家根据自己的操作系统(是32位还是64位,选择什么版本的,自己进行选择就好了)
我下载的是5.x版本的(大家可以用迅雷下载,确实快!)

然后找到它,双击:(我没找到中文,就English,其他的我也不懂是啥语言啊!!!)
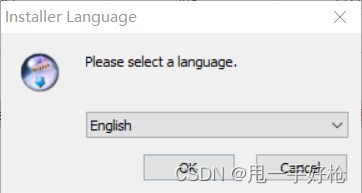
接下来是:

点击next
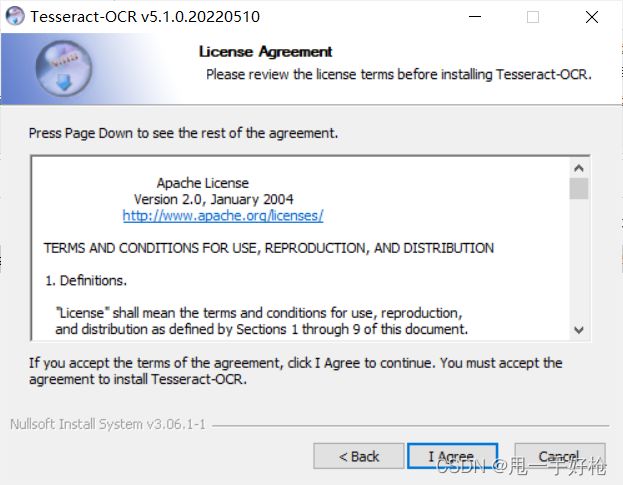
我也想不同意,但是没办法,就agree吧
接下来是选择角色,我选的是just for me,也没其他人用啊(大家根据自己需求即可)
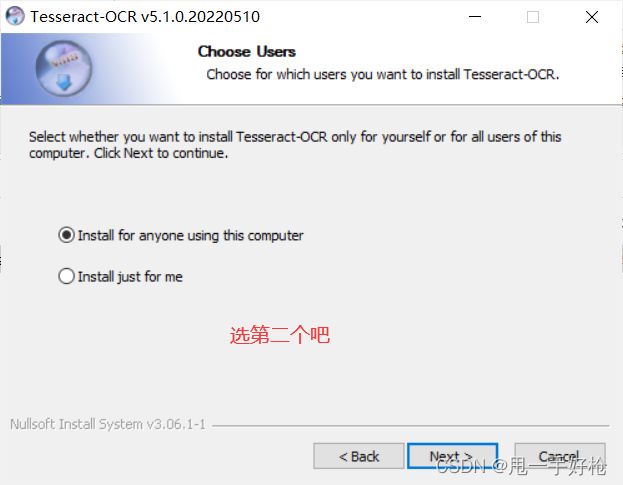
接下来是需要选择要下的内容,第一次下,我也不知道,就全部都点了吧,也不大:
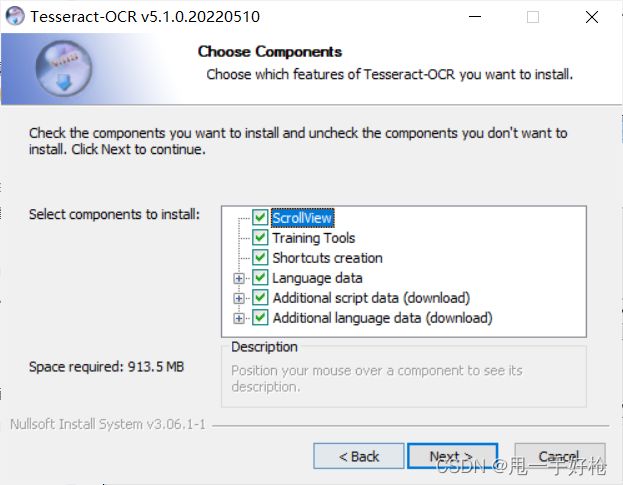
自己选择一下下载的位置(看自己需求,我建议不要都下载在C盘);
直接next:
等待下载:wait
下载完成:

搞一下环境路径:
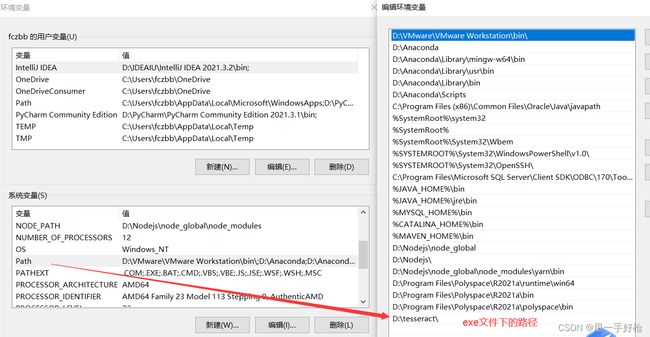
测试:

代码实践
将图片中的内容识别打印,并绘制边框
import cv2 as cv
import pytesseract as pt
# 指明tesseract_cmd命令,方便pytesseract调用
pt.pytesseract.tesseract_cmd = r'D:\tesseract\tesseract.exe'
# 这里使用绝对路径,我这里如果使用相对路径的话会报错,具体原因还在解决(之前的内容没遇到)
img = cv.imread(r'D:\Python\PythonProject\OpenCVProject\img\1.png')
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 展示图片中的内容
print(pt.image_to_string(img))
cv.imshow('test', img)
cv.waitKey(0)


打印识别图片内容后的各个字符框的信息
import cv2 as cv
import pytesseract as pt
# 指明tesseract_cmd命令,方便pytesseract调用
pt.pytesseract.tesseract_cmd = r'D:\tesseract\tesseract.exe'
# 这里使用绝对路径
img = cv.imread(r'D:\Python\PythonProject\OpenCVProject\img\1.png')
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 打印图片中内容的框的信息
print(pt.image_to_boxes(img))
cv.imshow('test', img)
cv.waitKey(0)
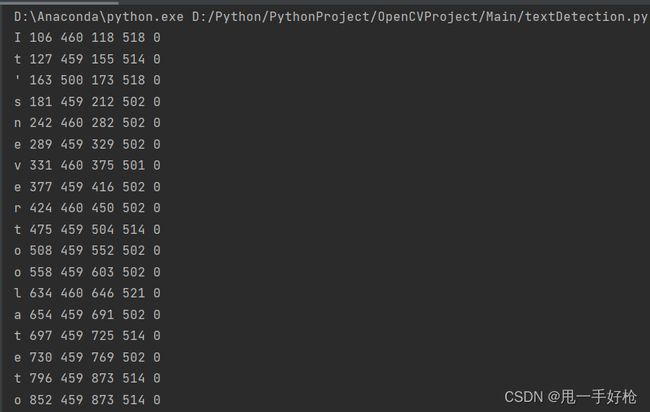
上述图片的信息从左到右依次是:框的左下角的x、y,框的宽度、高度
接下来就是绘制边框了
import cv2 as cv
import pytesseract as pt
# 指明tesseract_cmd命令,方便pytesseract调用
pt.pytesseract.tesseract_cmd = r'D:\tesseract\tesseract.exe'
# 这里使用绝对路径
img = cv.imread(r'D:\Python\PythonProject\OpenCVProject\img\1.png')
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 打印图片中内容的框的信息,并绘制边框
heightImg, weightImg, _ = img.shape
print(heightImg, weightImg)
boxes = pt.image_to_boxes(img)
# 以换行符来分割字符串
for b in boxes.splitlines():
print(b)
# 将字符串变成列表
b = b.split(' ')
# 处理绘制边框的数据
x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4])
# 绘制边框
cv.rectangle(img, (x, heightImg - y), (w, heightImg -h), (0, 0, 255), 2)
# 在图像上输出检测结果
cv.putText(img, b[0], (x, heightImg -y + 25), cv.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 2)
cv.imshow('textDetection', img)
cv.waitKey(0)

单词(word)检测
# 单词检测
import cv2 as cv
import pytesseract as pt
# 指明tesseract_cmd命令,方便pytesseract调用
pt.pytesseract.tesseract_cmd = r'D:\tesseract\tesseract.exe'
# 这里使用绝对路径
img = cv.imread(r'D:\Python\PythonProject\OpenCVProject\img\1.png')
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 打印图片中内容的框的信息,并绘制边框
heightImg, weightImg, _ = img.shape
boxes = pt.image_to_data(img)
print(boxes)
# 通过枚举类,将第一行的标题信息进行注释(我们不需要)
for x, b in enumerate(boxes.splitlines()):
if x != 0:
b = b.split()
# 如果说b的长度是12,说明是有预测结果的,就进行标注绘制框框
if len(b) == 12:
# 处理绘制边框的数据
x, y, w, h = int(b[6]), int(b[7]), int(b[8]), int(b[9])
# 绘制边框
cv.rectangle(img, (x, y), (w + x, h + y), (0, 0, 255), 2)
# 在图像上输出检测结果
cv.putText(img, b[11], (x, y), cv.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 2)
cv.imshow('textDetection', img)
cv.waitKey(0)

只进行数字识别
# 进行识别操作的时候进行配置即可
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pt.image_to_data(img, config=cong)
img = cv.imread(r'D:\Python\PythonProject\OpenCVProject\img\1.png')
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
# 打印图片中内容的框的信息,并绘制边框
heightImg, weightImg, _ = img.shape
# 配置,只识别数字
cong = r'--oem 3 --psm 6 outputbase digits'
boxes = pt.image_to_data(img, config=cong)
print(boxes)
# 通过枚举类,将第一行的标题信息进行注释(我们不需要)
for x, b in enumerate(boxes.splitlines()):
if x != 0:
b = b.split()
# 如果说b的长度是12,说明是有预测结果的,就进行标注绘制框框
if len(b) == 12:
# 处理绘制边框的数据
x, y, w, h = int(b[6]), int(b[7]), int(b[8]), int(b[9])
# 绘制边框
cv.rectangle(img, (x, y), (w + x, h + y), (0, 0, 255), 2)
# 在图像上输出检测结果
cv.putText(img, b[11], (x, y), cv.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 2)
cv.imshow('textDetection', img)
cv.waitKey(0)

下面的就不在重复赘述了
