【论文精读】Grounded Language-Image Pre-training(GLIP)
一. 背景
https://arxiv.org/abs/2112.03857
https://github.com/microsoft/GLIP

这篇论文做的任务是phrase grounding,属于visual grounding的一种。phrase grounding的任务是输入句子和图片,将句子中提到的物体都框出来。visual grounding其他任务和细节可以参考
https://zhuanlan.zhihu.com/p/388504127
GLIP既可以做目标检测也可以做grounding,
- 目标检测:
在扩增目标检测领域为SOTA,zero-shot效果较好,也可以做zero-shot目标检测任务。
与常规目标检测任务相比语义丰富。 - grounding:
与常规grounding任务相比可以做目标检测任务。
二、贡献
贡献
- 将目标检测和phrase grounding任务统一起来进行预训练
- 扩大视觉语义
- 迁移学习能力强
性能
- 27M关联数据上训练。在目标识别任务上有很强的零样本和小样本迁移性能
- Zero-shot:coco val上49.8AP,LVIS val上26.9AP
- 微调后:COCO val上60.8AP
- 下游13个目标检测任务时,1个样本的GLIP可以与Dynamic Head相匹敌
三、方法
3.1 方法1:检测和grounding任务统一

1. background:
对于检测数据集:
训练时输入标签名(person、hairdryer)、框、图片。
测试时输入图片,预测出框和标签名。
训练过程如下:

2. background as grounding:
groudning模型的输入是短语、短语中名词的框和图片。
将object模型转为grounding的办法:通过prompt的方式将标签名转化为短语。

如coco有80个标签,将80个标签用逗号连接,短语前加“Detect:”,来组成短句。
公式2变成公式3的过程中,T的大小会变化,从Nc变成NM
构建token:上图流程图中,M(sub-word tokens)总是比短语格式c多,原因有四个1)一些短语占了多个toeken位置,比如 traffic light。2)一些短语被分开成sub words,比如toothbrush分成了 tooth#, #brush。3)一些是添加的token,如逗号,Deteckt等,4)结尾会添加[NoObj]的token。在训练的时候,phrase是正例的话,多个subwords都是正例。测试时多个token的平均pro作为短语的probability。
3. detection和grounding联动:由上面的方法,可以用grounding模型来预训练检测任务,从而可以迁移GLIP模型做zero-shot的检测
3.2 方法2: deep fusion,视觉和语言联合

fusion部分公式如下:

O0是视觉backbone的feature, P0 是文本backbone的feature
X-MHA(cross-modality multi-head attention module)
L是DyHead中DyHeadModules个数,BERT Layer为新增。
attention部分在多模态中比较常见,比如co-attention、guided attention等。可以参考多模态中attention其他优化。
DeepFusion优点:
提高了phrase grounding效果
使得视觉特征language-aware
3.3 方法3: 用丰富的语义数据预训练
grounding数据集语义都很丰富,目标检测不超过2000个类别,但是grounding数据集如Flickr30K包括了4.4w不同的短语,量级不同。
如何扩增grounding数据:
- 在gold data(det+grounding)上训练教师GLIP
- 使用这个教师模型来预测24M web image-text数据,通过NLP解析名词短语,存在5840个不同名词短语
- 学生模型在gold data和伪标签grounding数据上训练
扩增效果:
学生模型效果比教师模型效果好,比如对于部分词汇,vaccine教师模型可能预测不出来,但是可以预测出a small vial,subwords对的,整体phrase都会是对的。那在给学生模型无监督数据时,可以将a small vial of vaccine标签整体给到学生模型作为学习标签。

四、实验结果
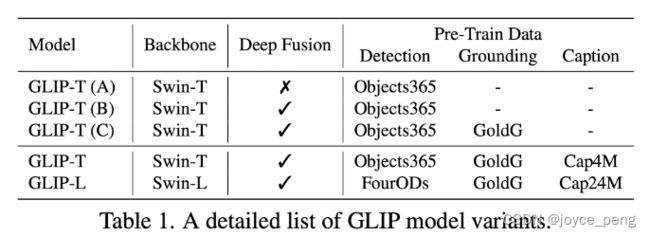
FourODs(2.66M数据)是4个检测数据集集合,包括objects365、OpenImages、VG数据集(除了coco)、ImageNetBox。
GoldG+ 数据集包括1.3M数据集,包括Flickr30K、VG caption、GQA。
GoldG 数据集是GoldG+去除了coco数据集
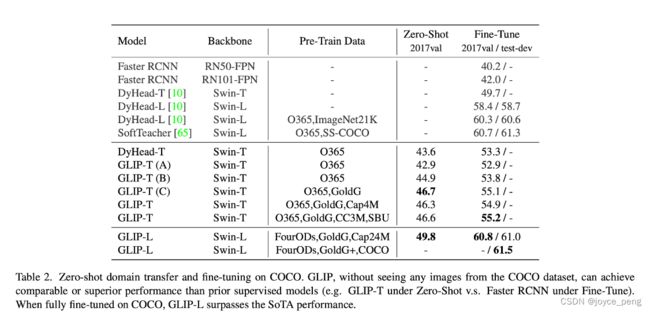
4.1 迁移效果在检测数据集上
zero-shot在coco上:
- 图文数据集没有带来提升
- C和B比提升较大
- Objects365包括了coco的80个
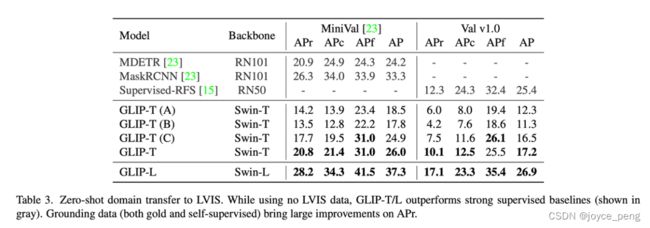
在LVIS上效果:
LVIS:大规模细粒度词汇级标记数据集,1000+类别,披萨里的菠萝丁也被标记
Gold grounding很有效(model C vs model B)
4.2 在grounding数据集上
Flick 30k:图文匹配grounding数据集,goldG中包含了该数据集

4.3 消融实验-检测数据集影响
O365: 0.66M
GoldG: 0.8M
FourODs: 2.66M
但是不是O365+GoldG效果反而更好

4.4 其他
如果定位不好,可以添加提示词帮助更好定位,下图添加了flat and round
