知识图谱-实体识别
一、信息抽取概述
- 输入: 领域知识本体(是个抽象的概念,外在的描述是本体的外在符号,语义层面的本体就是建立一种映射关系,将所有描述某类本体的符号都映射到这个本体上,建立本体集合,并去挖掘本体之间的深层联系,如属性-本体,子类-本体的关系)海量数据: 文本、垂直站点、百科、多模态数据
- 输出: 领域实例化知识,实体集合、事件集合、实体关系/属性、事件关系、过程知识。
- 主要技术:信息抽取
- 信息抽取来源: 网络文本信息(结构化数据,半结构数据,纯文本数据)
- 信息抽取研究方向: 从自然语言文本中抽取指定类型的实体、关系、事件等事实信息。
- 信息抽取主要任务: 实体识别,实体消歧,关系抽取(属性抽取),事件抽取,事件关系判别,过程知识抽取。
- 信息抽取发展(学术评测方式,推动发展): MUC(Message Understanding Conferernces, 1987-1997, 军用,任务: 命名实体识别,模版关系抽取), ACE(Automatic Content Extraction, 199-2008, 任务:命名实体识别, 关系抽取,事件抽取), TAC-KBP(Knowledge Base Population, 2009-至今, 任务: 实体连接,属性抽取,事件,事件关系抽取)。
- 信息抽取发展: 封闭语料–开放语料: 限定领域,新闻语料–web页面; 限定类别–开放类别: 有限类别的实体、关系、事件–维基百科条目; 文本内信息抽取–与真实世界关联。
二、信息抽取基础: 分词和词性标注
- 与模型深切相关
- 中文分词
- 词性标注(Part-of-speech(POS,词性) tagging(词性表标注)):消除词性兼类歧义(比如既是名词又是动词:爱好),确定当前上下文中名词、动词等的过程。
- 中文分词难点:
- 歧义切分(交集型歧义(ABC,AB,BC同时成词),组合型歧义(AB,A,B同时成词))
- 未登录词识别: 人名、地名、机构名
- 词性兼类(打: 动词(打水),介词(他打门缝里往外看),量词(一打铅笔))
- 中文分词方法
- 有/无词典切分(分词过程中使用词典的方法)
- 基于规则/基于统计,基于规则不需要标注训练语料,直接根据词典和规则进行分词;基于统计要标注语料,分为生成式分词和判别式分词。
- 基于词典分词方法
- 按照一定策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串择匹配成功
- 正向最大匹配法: 中医/治/偏头疼
- 反向最大匹配法: 中/医治/偏头疼
- 最短路径法:独立自主/和平/等/互利/的/原则;独立自主/和平等互利/的/原则。
- 优点: 程序简单,开发周期短,仅需很少语言资源,不用任何语法,句法。
- 缺点:歧义消解能力差,切分正确率不高。
- 统计法: 生成式方法
- 原理: 首先建立学习样本的生成模型,再利用模型对预测结果进行间接推理,不使用词典,使用分词语料库,分词的信息从语料库中学习
- 典型算法:隐马尔可夫模型: 关于时序的概率模型,双重随机过程。
- HMM: 包含因状态序列和观察输出序列,(状态序列: 词性; 观察序列:词; 状态数目N: 词性标记符号个数,北大语料库词性标记符号有106个; 输出符号数M: 每个状态可输出的不同词汇个数,如汉语介词有50个,连词120个; 求解目标: 分词结果,词性标注结果; 参数学习: 有监督直接根据数据进行统计得到,无监督EM算法求得)
- 优点: 语料库足够大情况下,提高准确率
- 缺点: 模型实现复杂,训练语料规模,覆盖领域不好把握。
- HMM在中文分词中的应用: 观察值是输入的句子,状态值为BEMS; 详细讲解链接:https://www.jianshu.com/p/0eee07a5bf38
- 统计法: 判别式方法
- 原理: 有限样本下,建立对于预测结果的判别函数,直接对预测结果进行判别;基于由字构词的分词理念,将分词问题转化为判别式分类问题。
- 典型方法:maxent, SVM,CRF,Perceptron, Neural network
- 流程: 把分词问题转化为确定句中每个字在词中位置问题,既序列标注任务。
- 每个字在词中的位置: 词首B,词中M,词尾E,独字S
- 最大熵模型
- 理论基础: 熵增原理,自然界的根本法则
- 事物是约束和自由的统一体;
- 在无外力的情况下,事物朝着最混乱的方向发展,有外力的方向下,事物总是在约束下正确最大的自由权。
- 最大熵理论: 在已知条件下,熵最大的事物,最可能接近它的真实状态。
- 任务: 研究某个随机事件,根据已知信息,预测其未来行为。
- 方法: 当无法获得随机事件的真实分布时,构造统计模型对随机事件进行模拟。
- 难点: 满足已知信息要求的模型可能有多个,用哪个进行预测?
- 对一个随机过程,如果没有任何观察量,即没有任何约束,则解为均匀分布。
- H ( ξ ) = − ∑ i = 1 n p i l o g p i H(\xi ) = -\sum_{i=1}^{n} p_ilogp_i H(ξ)=−i=1∑npilogpi
- 加上约束条件,则在满足约束的范围内均匀分布,在自然语言处理领域,标注的训练集可以作为约束条件。
- 设P(Y|X)为最大熵模型,则在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率:
P w ( y ∣ x ) = 1 Z w ( x ) e x p ( ∑ i = 1 n w i f i ( x , y ) ) P_w(y|x) = \frac{1}{Z_w(x)} exp(\sum_{i=1}^{n} w_if_i(x,y)) Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
Z w ( x ) Z_w(x) Zw(x)是归一化因子, w i w_i wi是一组参数(权重), f i f_i fi是每个参数对对应一个特征。
- 基于最大熵模型的中文分词(分词问题转化为分类问题)
-
任务: 采用最大熵模型对每个汉字标注BMES(4个类别)标记
-
特征模版: 假设当前字 C 0 C_0 C0,当前BMES标记是 T 0 T_0 T0
-
C n T 0 C_nT_0 CnT0(n=-1,-1,0,1,2)是上下文中的一个汉字和当前标记
-
C n C n + 1 T 0 C_nC_{n+1}T_0 CnCn+1T0 两组字和当前标记
-
D ( C 0 ) T 0 D(C_0)T_0 D(C0)T0: 当前字是否是数字,和当前标记
-
A ( C 0 ) T 0 A(C_0)T_0 A(C0)T0:当前字是否字母,和当前标记
-
生成最大熵训练样本:
-

-
参数训练: 对训练语料库中的每个汉字生成一个训练样本;把所有样本的列表送给最大熵模型的训练工具;最大熵模型的训练工具将学习到模型参数。
-
测试:对输入串中每一个汉字以及该汉字的每一个可能的标记,生成一个测试样本,这样对每个汉字生成量BMES四个样本。
-
训练和测试语料展示:

上述截图参考链接:https://blog.csdn.net/u010189459/article/details/38458559 -
搜索最优路径 : 有些边是非法的,比如M-B,E-M,E-E等,每条路径是路径上各节点标注概率P(标记|汉字)之积,边上没有转移概率(因为哪个到哪个都是确定的,不需要边上的概率);所有算法就是维特比算法。

-
标注最优路径

- 基于神经网络(Bi-LSTM+CRF) 的中文分词(也是分类问题)
- 动机:传统统计方法严重依赖于特征的设计,而手工提取特征费时费力,还会存在错误传递的问题;对一个句子的正确切分,要利用一些远距离信息。
- 将输入句子每个字都转化为向量表示,然后用双向LSTM提取特征,最后用条件随机场预测标签。
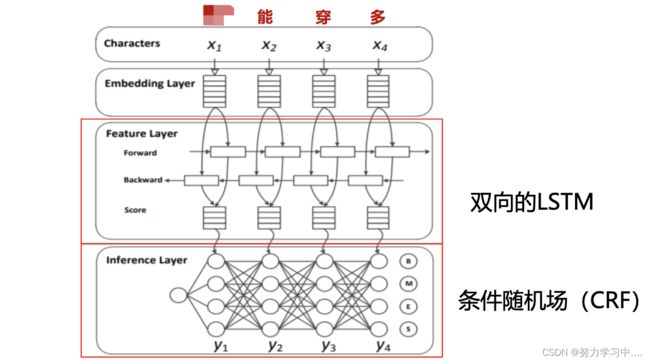
- 论文:Xinchi Chen, Long Short-Term Memory Neural Networks for Chinese Word Segmentation, EMNLP-2015
- 基于统计分词方法判别式
- 优点: 分词精度高;新词识别率较高;
- 缺点:训练速度慢,需要设计特征模版;需要人工标注的训练样本;性能与特征和语料紧密相关
- 词典+统计方法
- 基于统计方法对于出现次数较少的样本不能很好处理,比如稀有词、领域专有词;OOV(out-of-vocabulary)问题是监督学习最主要的问题。
- 统计模型从分词语料库中学习切分规律,擅长处理常用词;
- 词典中既有常见词也有不经常出现的词,将词典融入到神经网络模型中,使模型能更好的处理常见词、稀有词和领域专有词。
- 构造字特征向量,将每个字转成向量表示,并为每个字构造相应特征向量,双向LSTM提取特征,将两个特征链接在一起得到字级别表示;
- 构造词典特征向量: 利用N-gram 与词典匹配,如果该词在词典中出现,就填1,否则填0
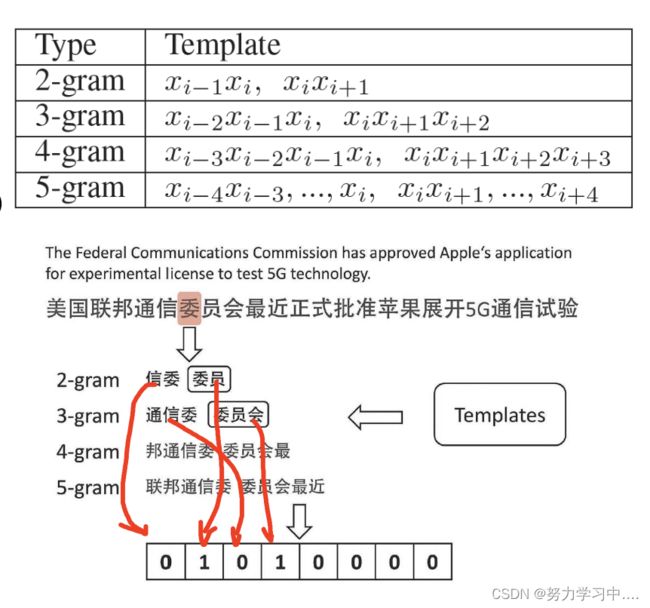
- 将字向量与词典向量拼接,使用CRF解码。
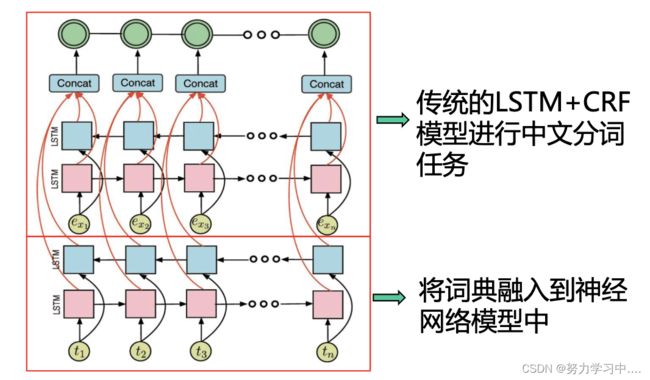
- 论文:Qi Zhang, Neural Networks Incorporating Dictionaries for Chinese Word Segmentation, AAAI-2018
- 可选的分词工具
- http://ictclas.nlpir.org/中科院计算所(ICTCLAS)
- http://www.openpr.org.cn中科院自动化所(Urheen)
- http://www.fnlp.org/复旦大学
- http://nlp.stanford.edu/software/tagger.shtml Stanford University
三、 命名实体识别
-
定义: 命名实体是指现实中具体或抽象的实体,如:人名、机构名等;还包含时间、日期、金钱等。
-
知识图谱是由数目众多的实体和实体之间的关系所构成的。
-
命名实体识别任务: 实体边界识别和实体类别标注
-
中文人名识别难点: 分布松散、特征不明显,缺乏可利用的启发标记;
姓:张、王、李、刘、诸葛、西门、范徐丽泰
名:李素丽,王杰、诸葛亮
前缀:老王,小李
后缀:王老,李总
姓:汉语姓氏大约有1000多个, 姓氏中使用频度最高的是“王”姓, “王, 陈, 李, 张, 刘”等5个大姓覆盖率达32%, 姓氏 频度表中的前 14个 高频度的姓氏覆盖率为50%,前400个姓氏覆盖率达99%。
名:人名的用字也比较集中。频度最高的前6个字覆盖率达10.35%, 前10个字的覆盖率达14.936%, 前15个字的覆盖率达19.695%, 前400个字的覆盖率达90%。
内部组合规律:姓+名,姓,名,前缀+姓,姓+后缀,姓+姓+名(海外已婚妇女)
身份词:
前:工人、教师、影星
后:先生、同志
前后:女士、教授、经理、小姐、总理
地名或机构名:
前:静海县大丘庄禹作敏
的字结构
前:年过七旬的王贵芝
动作词:
前:批评,逮捕,选举
后:说,表示,吃,结婚 -
中文地名识别: 绝大部分是两个字;经常与方位词和介词连用。
-
结构名识别:嵌套问题;用词广泛;长度变化大;动态变化。
-
音译名识别: 很难划分出结构,但有一些常见音节(斯基、斯坦),不同语言音律不尽相同,译出来差别大。
-
条件随机场(CRF)介绍
- 定义: 在给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。
- 假设输出随机变量构成马尔可夫随机场
- 应用: 不同类型的序列标注问题: 单个目标的,序列结构的标注;图结构的标注。
- 自然语言处理很多任务都可以转化为序列结构的标注问题。
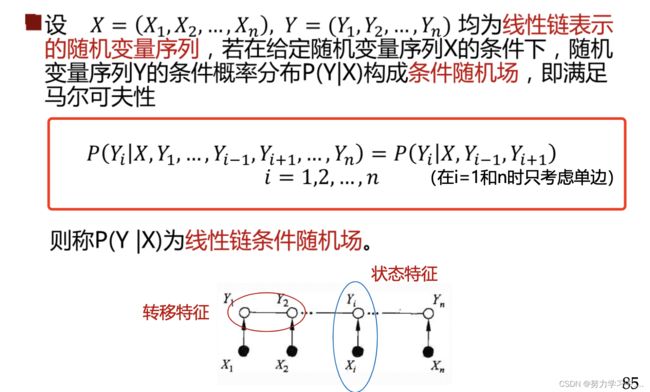
- 设X与Y是随机变量,P(Y|X)是在给定X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场,则称条件概率分布P(Y|X)为条件随机场。
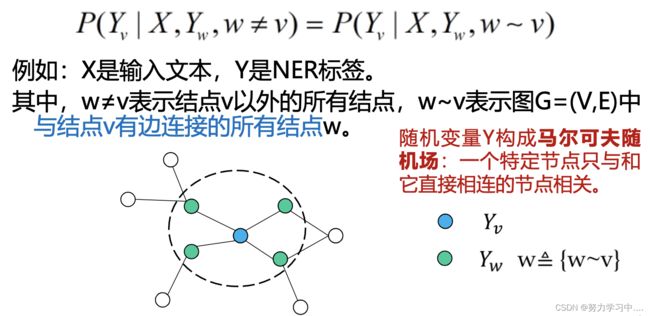
- 线性链条件随机场
- NER模型基本结构
- NER数据集格式

参考链接:https://seanwangjs.github.io/2021/10/21/bert-base-ner-implementation.html
- HMM ME CRF
- HMM是一种生成式模型,利用转移矩阵和生成矩阵建模相邻状态的转移概率和状态到观察的生成概率,无法利用复杂特征(只有两个矩阵建模)
- ME(最大熵模型)是一种判别式模型,可以使用任意的复杂特征(特征函数) ,但是ME只能建模观察序列和某一状态的关系,状态之间的关系无法得到充分使用。
- CRF 是一种判别式模型,既可以使用任意的复杂特征,(虽然每个位置只有一个矩阵,但矩阵的元素是由特征函数和权重计算得到,我们可以任意地定义特征函数,从而考虑各种特征),又可以建模观察序列和多个状态的关系,即考虑了状态之间的关系。
- CRF模型的参数训练: 对训练语料库中每句话生成一个实例,把所有实例的列表送给CRF模型的训练工具;CRF学习到模型的参数(每个转移特征和状态特征的权重)
- 汉语分词和实体识别联合模型
- 动机: 词边界能提供实体类别的有用信息,所以将词边界信息融入到命名实体识别中;汉语分词困难,与英语相比分词准确率低,先分词,后实体识别,分词时的误差会传递到实体识别中,所以将分词与实体识别联合训练。
- 首先,做分词,将分词阶段LSTM隐层输出得到的分词特征、字向量特征和传统NER特征融合 输入到CRF中,进行实体识别,其中分词和实体识别分别定义损失函数,最后将两个损失函数联合,实现两个任务联合学习。
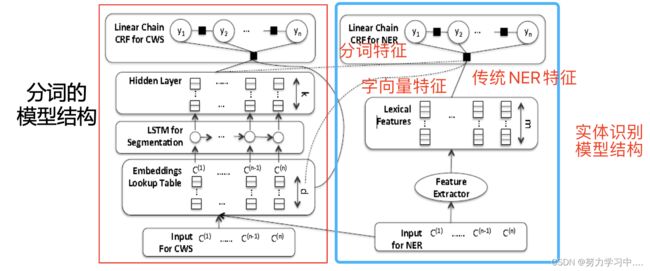
- 论文:Nanyun Peng, Improving Named Entity Recognition for Chinese Social Media with Word
Segmentation Representation Learning, ACL-2016
- 基于对抗训练的命名实体识别
- 模型结构: 该模型为实体识别任务和分词任务分别匹配一个私有的双向LSTM结构,用来提取这两个任务的私有特征,这两个任务也会共享一个双向LSTM,用来提取这两个任务的共有的特征,将私有特征和共有特征融合进行标签预测 。

- 第一步将句子中每个字都转化成向量表示;
- 第二步用命名实体识别和中文分词私有的双向LSTM提取特征,用它们共享的双向LSTM提取共享的特征;
- 第三步,用注意力机制来捕获长距离依赖;
- 第四步,用一个判别器来判断共享的LSTM提取的特征来自命名实体识别还是中文分词。
- 第五步,使用条件随机场进行解码。
- 论文:Pengfei Cao, Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism, EMNLP-2018
- 融入词典的命名实体识别
- 动机: 基于字级别预测的模型无法利用到词序列信息,而词序列信息非常重要,例如:“南京市长江大桥”,词信息“长江大桥”、“长江”和“大桥”,有助于消解人名歧义“江大桥;基于词级别预测的模型(先分词,再实体识别),虽然可以利用词序列信息,但是会引入分词的错误,造成误差积累。
- 提出一个Lattice LSTM 的模型:以字级别的LSTM+CRF模型为基础,通过Lattice LSTM表示句子中的单词,从而将潜在的词汇信息融入到基于字符的LSTM+CRF中。
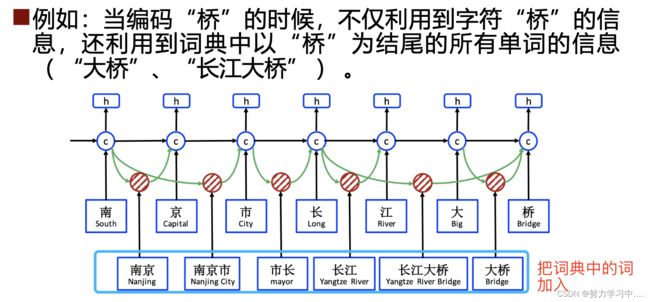
- 论文:Yue Zhang, Chinese NER Using Lattice LSTM, ACL-2018
- 可选的NER工具:
- http://ictclas.nlpir.org/中科院计算所(ICTCLAS)
- http://cognet.top/cogie中科院自动化所(Urheen)
- http://www.fnlp.org/复旦大学
- http://nlp.stanford.edu/software/tagger.shtml Stanford University
四、 细粒度实体识别
- 任务: 输入带实体边界标注的句子,输出实体的类别。
- 传统命名实体识别三大类,七小类不能满足需求,在知识图谱构建和很多自然语言处理任务中,细粒度的识别识别包含更多知识,有助于相应任务提升。
- 例如,产品名(如:华为Mate10)、疾病名(如:非典型肺炎)、赛事名(如:2018年世界杯),人可以细分为艺人、运动员、教师、工程师等,艺人又可以分为相声演员、影视演员、歌手、主持人等。
- 典型的细粒度实体类别分类
- 自动内容抽取会议(ACE)将实体分为7大类(人名、地名、机构名、武器、交通工具、行政区、设备设施)和45个小类;
- Ling 和Weld 构建了一个具有112个类别的细粒度命名实体体系;
- FreeBase中的实体类别达到上千种,且是动态增加的;
- 细粒度实体分类难点:
- 类别的制定:如何制定一个覆盖类别多且具有层次结构的类别体系;
- 语料的标注: 随着实体类别增多,语料标注难度和成本呈指数级增长;
- 更多的类别对传统实体识别方法带来了极大的挑战。
- 细粒度实体识别方法:
- 无监督方法: 规则抽取(人工制定模版,根据通用模版和指定类别去细化模版,得到初始种子,使用搜索引擎对模版进行扩展); 实体名的抽取(利用模板从互联网上抽取大规模的实体名);实体名的验证(使用验证规则并结合搜索引擎对实体名进行验证,将高置信度的实体名加入到知识库中)
- 有监督: 基于特征工程的传统方法(严重依赖手工提取的特征和外部资源,如词性标签,依存关系);基于神经网络的深度学习方法。
- 深度学习方法
- 模型结构: mention 模型:一个循环神经网络,用来学习mention中各个词之间的组合语义关系;上下文模型: 两个多层感知机,学习上下文特征;三个特征拼接起来一起预测。

- 该方法独立地处理文本和知识,忽略了知识库信息,而知识库可以提供丰富的实体关系信息。
- 论文:Li Dong, A Hybrid Neural Model for Type Classification of Entity Mentions, IJCAI-2015
- 深度学习方法
- 使用双向LSTM来提取上下文的特征,使用TranSE的方法在知识库中学习实体的向量表示,作为query向量与双向LSTM的输出做attention操作,得到上下文表示,然后将上下文表示和实体表示融合在一起进行预测。
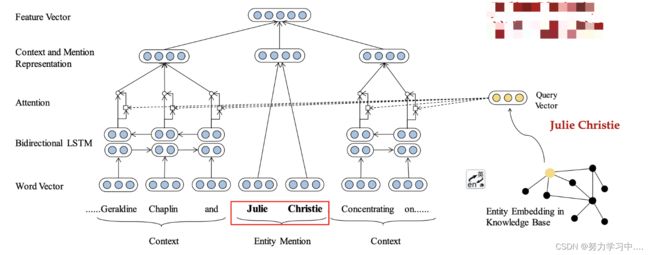 - 论文:Ji Xin, Improving Neural Fine-Grained Entity Typing with Knowledge Attention, AAAI-2018
- 论文:Ji Xin, Improving Neural Fine-Grained Entity Typing with Knowledge Attention, AAAI-2018
五、 多模态命名实体识别
- 在社交媒体和短视频平台上,不但存在文本信息,还存在着大量的图片信息、视频信息、音频信息。
- 相较于Wikipedia、新闻报导等文本形式,社交媒体和短
视频平台上的文本具有如下特点:
文本长度短(Twitter限制140个字,微博之前限制140
个字,现已取消)
文本表示不规范,例如“Looooooove”
各种语言、表情包混杂 - 仅利用单一的文本模态去推断命名实体的边界和标签,在社交媒体和短视屏这样的场景非常困难,需要借助其他模态的信息来共同推断。
- 多模态命名实体识别的挑战
- 利用何种模态的信息:语音、图像、视频
- 如何融合多种模态的信息:多种模态之间的联系
- 多模态数据中的噪声:引入多模态可能会同时引入噪声
- 数据集
- 文本+图像:Zhang 等人 与 Lu 等人在2018年分别在社交媒体上收集数据构建了Twitter2015与 Twitter2017文本+图像双模态实体识别英文数据集。
- 文本+语音:Sui等人在2021年构建了第一个文本-语音双模态实体识别中文数据集。
- 多模态命名实体识别方法(图片+文本)
- 动机:42%的推文都包含了一个或多个的图片,利用图片模态可以有效地推断出歧义实体的类别信息。

- 模型总体架构包含三个组件
利用Bi-LSTM 来建模文本信息;
利用VGG-NET来建模视觉信息;
利用Attention机制和Gate机制将视觉模态信息融入文本信息中。 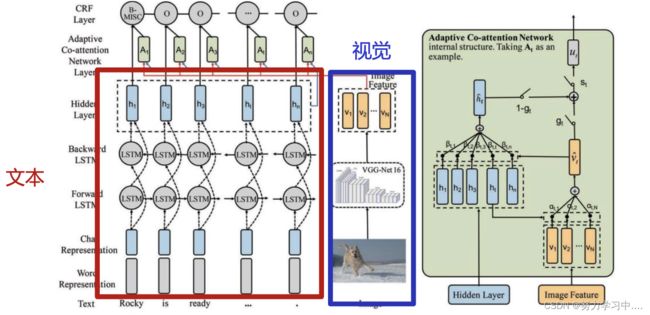
- 论文:Adaptive Co-attention Network for Named Entity Recognition in Tweets. AAAI 2018
- 多模态命名实体识别方法(音频+文本)
- 动机:与静态的图像不同,语音中包含的信息(停顿、音调、韵律等)对中文命名实体识别是非常有价值的,特别是在提供准确的词边界信息上。借助语音信息,可以推断出歧义实体的边界信息。
- 构建了第一个文本-语音双模态实体识别数据,不仅规模大,数据丰富,而且标注了细粒度的嵌套结构。同时提出了基于多任务学习的文本-语音多模态识别模型(Multi-Modal Multi-Task model,M3T)。
- 论文:A Large-Scale Chinese Multimodal NER Dataset with Speech Clues, ACL 2021
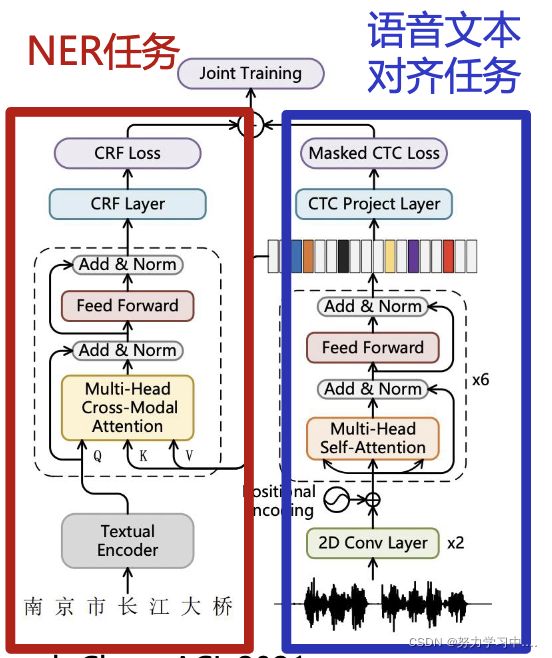
8. 多模态命名实体识别小结
- 训练语料受限
多模态的命名实体识别数据集构建,费时费力难以构建
社交媒体数据,文本格式不规范,噪声较大 - 多模信息融合存在挑战
多模信息的对齐比较难
引入其他模态帮助消歧的同时,可能会引入噪声
六、 开放域实体识别
- 不限定实体类别,不限定目标文本。
- 如一任务:给定某一类别的实体实例,从网页中抽取同一类别其他实体实例
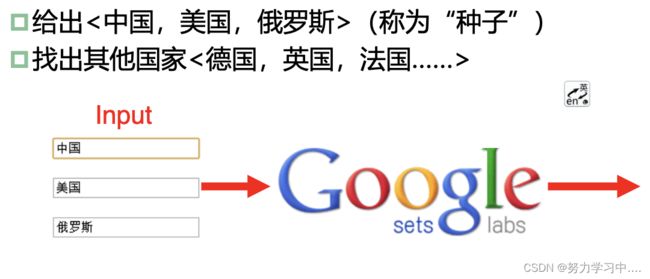
- 开放域实体抽取的主要方法
- 基本思路:种子词与目标词在网页中具有相同或者类似的上下文(Step1:种子词模板;Step2:模板更多同类实体)
- 处理实例扩展问题的主流框架

- 利用不同数据源(例如查询日志、网页文档、知识库文档等)的不同特点,设计方法
- 开放域实体抽取的主要方法: Query Log
- 通过分析种子实例在查询日志中的上下文学得模板,再利用模板找到同类别的实例

- 构造候选与种子上下文向量,计算相似度。
- 论文:Marius Paşca , Weakly-supervised discovery of named entities using web search queries, CIKM-2007
- 开放域实体抽取的主要方法: Web Page
- 处理列表型网页;在列表中,种子与目标实体具有相同的网页结构。

- 论文:Richard C. Wang , Language-Independent Set Expansion of Named Entities Using the Web, ICDM-2007
- 开放域实体抽取的主要方法: 融合多个数据源
- 针对不同数据源,选取不同特征分别进行实例扩展,对结果进行融合
6亿个网页
1年的查询日志
Wikipedia - 针对不同数据源选取不同的模板和特征
- 使用不同特征计算候选的置信度,结果融合
- 论文:Marco Pennacchiotti , Entity Extraction via Ensemble Semantics, EMNLP-2009
参考: 国科大-知识图谱课件