维吉尼亚密码破解(Python完整详细源码)
维吉尼亚密码破解(Python完整详细源码)
欢迎大家访问我的GitHub博客
https://lunan0320.github.io/
文章目录
- 维吉尼亚密码破解(Python完整详细源码)
-
- 1、写在前面
- 2、维吉尼亚密码原理
- 3、维吉尼亚密码破解代码
1、写在前面
关于维吉尼亚密码破解
希望大家弄明白原理,不要只要代码
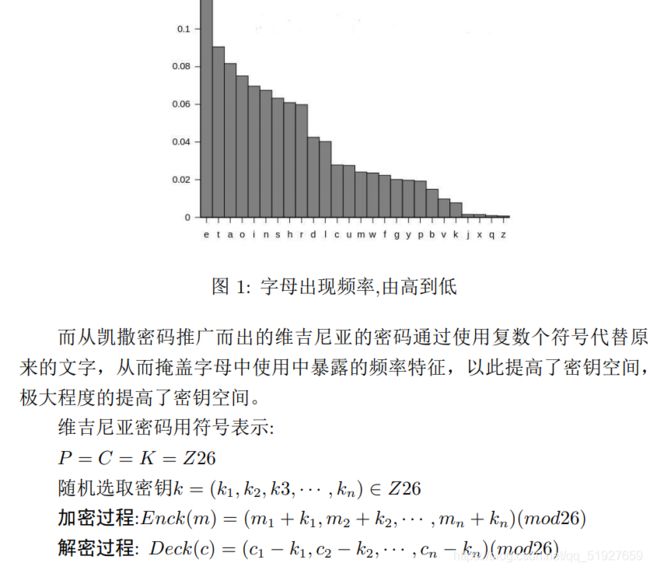
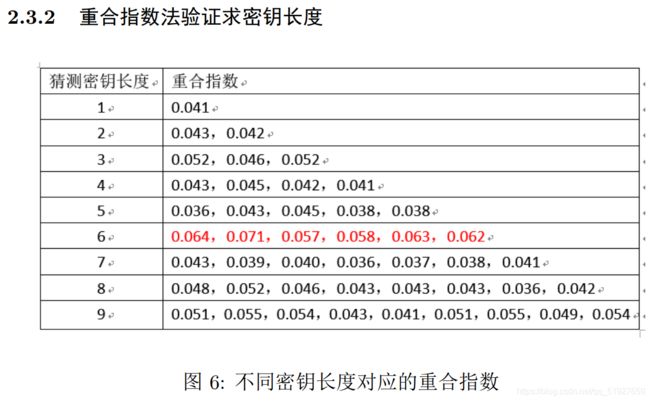
这里因为latex写的报告拷贝出现乱码,就把我们实验报告中的原理部分以图片形式分享出来,供大家学习。


2、维吉尼亚密码原理









3、维吉尼亚密码破解代码
import vigenerecipher
import string
import re
def gcd(a,b):
if a<b:
a,b=b,a
if a%b==0:
return b
else:
return gcd(b,a%b)
def findstr(Ctext,str_):
interval_list=[]
loc=0
array_locs=[]
while loc<len(Ctext):
loc=Ctext.find(str_,loc)
if loc==-1:
break
array_locs.append(loc)
loc=loc+1
index=0
while index+1<len(array_locs):
interval=array_locs[index+1]-array_locs[index]
print("间隔:",interval)
interval_list.append(interval)
index=index+1
interval_len=gcd(interval_list[0],interval_list[1])
print("当重复值为",str_,"时,两两之间距离的最大公因数:",interval_len,"\n")
return interval_len
def find_repeat(Ciphertext,repeat_list):
while len(Ciphertext)>200:
Ciphertext=list(Ciphertext)
Ciphertext.pop(1)
Ciphertext=''.join(Ciphertext)
list1=re.findall(r'.{3}',Ciphertext)
list2=[0]*len(list1)
for i in range(len(list1)):
for j in range(len(list1)):
if(list1[i]==list1[j]):
list2[i]=list2[i]+1
max_len=max(list2)
a=list2.index(max(list2))
if list1[a] not in repeat_list:
if max_len==3:
repeat_list.append(list1[a])
print("重复次数次数:",max_len)
print("重复值:",list1[a])
print("\n")
def check_len(Ciphertext,interval_len):
ListCiphertext=list(Ciphertext)
Keylength=1
while Keylength<interval_len+1:
#指数初始化为0
CoincidenceIndex = 0
#使用切片分组
for i in range(Keylength):
Numerator = 0
PresentCipherList = ListCiphertext[i::Keylength]
#使用集合去重,计算每一子密文组重合指数
for Letter in set(PresentCipherList):
Numerator += PresentCipherList.count(Letter) * (PresentCipherList.count(Letter)-1)
CoincidenceIndex += Numerator/(len(PresentCipherList) * (len(PresentCipherList)-1))
#求各子密文组的拟重合指数的平均值
Average=CoincidenceIndex / Keylength
Keylength += 1
#均值>0.6即可退出循环
if Average > 0.06:
break
Keylength -= 1
print("经重合指数验证后,密钥长度最可能为:",Keylength,"\n")
return Keylength
def keyword(Ciphertext,keylength):
ListCiphertext = list(Ciphertext)
#标准数据来源于课本
Standard = {'A':0.082,'B':0.015,'C':0.028,'D':0.043,'E':0.127,'F':0.022,'G':0.020,'H':0.061,'I':0.070,'J':0.002,'K':0.008,'L':0.040,'M':0.024,'N':0.067,'O':0.075,'P':0.019,'Q':0.001,'R':0.060,'S':0.063,'T':0.091,'U':0.028,'V':0.010,'W':0.023,'X':0.001,'Y':0.020,'Z':0.001}
while True:
KeyResult = []
for i in range(keylength):
# 使用切片分组
PresentCipherList = ListCiphertext[i::keylength]
#初始化重合指数最大值为0,检验移动位数对应字符以*代替
QuCoincidenceMax = 0
KeyLetter = "*"
#遍历移动的位数
#m是密钥对应的英文字母
for m in range(26):
#初始化当前移动位数的重合互指数为0
QuCoincidencePresent = 0
#遍历计算重合指数:各个字符的频率*对应英文字符出现的标准频率---的和
for Letter in set(PresentCipherList):
#fi/n
LetterFrequency = PresentCipherList.count(Letter) / len(PresentCipherList)
# 标准频率
#ord(Letter) - 65是将letter对应的字母化为26内的数值,然后与m运算,得到的k是对应的明文字母
k = chr( ( ord(Letter) - 65 - m ) % 26 + 65 )
StandardFrequency = Standard[k]
#计算重合互指数,累加遍历26个英文字母
QuCoincidencePresent = QuCoincidencePresent + LetterFrequency * StandardFrequency
#保存遍历过程中重合指数的最大值,同时保存对应应对的位数,即对应key的字符
if QuCoincidencePresent > QuCoincidenceMax:
QuCoincidenceMax = QuCoincidencePresent
#m是26个英文对应的位置,从0开始,+65是因为A在ascii中是65
KeyLetter = chr( m +65 )
print("第",i+1,"个密钥字母为:",KeyLetter,"对应的重合互指数为:",QuCoincidenceMax)
#保存当前位置key的值,退出循环,进行下一组子密文移动位数的尝试
KeyResult.append( KeyLetter )
#列表转为字符串
Key = "".join(KeyResult)
break
return Key
if __name__ == '__main__':
Ciphertext = input("输入密文:").upper()
repeat_list=[]
find_repeat(Ciphertext,repeat_list)
print("kasisiki测试法:\n重复列表",repeat_list)
for m in repeat_list:
interval_len=findstr(Ciphertext,m)
key_len=check_len(Ciphertext,interval_len)
KeyResult = keyword(Ciphertext,key_len)
print("密钥最可能为:" , KeyResult,"\n")
#已知秘钥可用python自带维吉尼亚解密
ClearText = vigenerecipher.decode( Ciphertext,KeyResult )
print("解密结果为:" , ClearText)