pytorch学习笔记1
一、环境安装:
Anaconda+pytorch+cuda+pycharm
CUDA 各个版本下载地址: https://developer.nvidia.com/cuda-toolkit-archive
Pytorch各个版本命令行安装: Previous PyTorch Versions | PyTorch
踩坑:注意换镜像、修改C:\Users\用户名.condarc (删除default,去掉https后面s)
插入----
Anaconda 各个版本下载地址: Index of / (anaconda.com)
电脑:https://github.com/dodois/Doisnet
1.创建一个名称为python34的虚拟环境并指定python版本为3.4(这里conda会自动找3.4中最新的版本下载)
conda create -n python34 python=3.4 或 conda create --name python34 python=3.4
2.切换环境
activate learn
3.查看所有环境
conda env list
# 创建一个名为python34的环境,指定Python版本是3.4(不用管是3.4.x,conda会为我们自动寻找3.4.x中的最新版本)
conda create --name python34 python=3.4
# 安装好后,使用activate激活某个环境
activate python34 # for Windows
source activate python34 # for Linux & Mac
# 激活后,会发现terminal输入的地方多了python34的字样,实际上,此时系统做的事情就是把默认2.7环境从PATH中去除,再把3.4对应的命令加入PATH
# 此时,再次输入
python --version
# 可以得到`Python 3.4.5 :: Anaconda 4.1.1 (64-bit)`,即系统已经切换到了3.4的环境
# 如果想返回默认的python 2.7环境,运行
deactivate python34 # for Windows
source deactivate python34 # for Linux & Mac
# 删除一个已有的环境
conda remove --name python34 --all
4.安装第三方包
输入
conda install requests
或者
pip install requests
来安装requests包.
5.卸载第三方包
输入
conda remove requests
或者
pip uninstall requests
6.查看环境包信息
要查看当前环境中所有安装了的包可以用
conda list
7.命令总结
//导入导出环境
//如果想要导出当前环境的包信息可以用
conda env export > environment.yaml
//将包信息存入yaml文件中.
//当需要重新创建一个相同的虚拟环境时可以用
conda env create -f environment.yaml
//其实命令很简单对不对, 我把一些常用的在下面给出来, 相信自己多打两次就能记住
activate // 切换到base环境
activate learn // 切换到learn环境
conda create -n learn python=3 // 创建一个名为learn的环境并指定python版本为3(的最新版本)
conda env list // 列出conda管理的所有环境
conda list // 列出当前环境的所有包
conda install requests //安装requests包
conda remove requests //卸载requets包
conda remove -n learn --all // 删除learn环境及下属所有包
conda update requests //更新requests包
conda env export > environment.yaml // 导出当前环境的包信息
conda env create -f environment.yaml // 用配置文件创建新的虚拟环境
8.Jupyter Notebook工作空间更换: https://blog.csdn.net/weixin_45399121/article/details/105754980
单词:
fully connect feedforward network 全连接前馈网络
neuron 神经元
Deep = many hidden layers
matrix 矩阵
softmax函数:归一化指数函数
sigmoid:激活函数
convolutional neural network 卷积神经网络
backpropagation 反向传播
toolkit 工具包
—插入
二、函数详解:
- 凸函数:convex(有专门讲怎么优化的课程,待学)
- 插播一首好听的歌曲: https://www.kugou.com/mvweb/html/mv_5219864.html
(1)Tensor(张量)
1.one_hot编码不能体现语言的相关性。
2.关键词解析:
-
dimension:几维(几行几列)
-
shape/size:具体的数据呈现 a.shape直接shape得到[2,3]
a. size(0)得到2 a. size(1)得到3
a. shape[0]得到2 a. shape[1]得到3
3.标量dimension(维度为0):
pytorch 0.3版本之前没有这个标量,采用维度为1,长度为1的张量表示
Loss用的最多的就是dimension为0 的张量,即标量。
将1.0 2.2 这样的数据带进tensor() 就会生成dimension为0的tensor。
4.dimension(维度为1)的张量:
Bias用的最多的是dimension为1 的张量。
Linear input用的最多的是dimension为1 的张量。
将1.0 2.2 这样的数据带进tensor([]) 就会生成dimension为1的tensor。
5.dimension(维度为2)的张量:
Linear input batch(批处理线性数据)用的最多的是dimension为2的张量。
6.dimension(维度为3)的张量:
RNN(循环神经网络) input batch(批处理文字数据)用的最多的是dimension为3的张量。
7.dimension(维度为4)的张量:
CNN[batch,color,height,width]
CNN(卷积神经网络) input batch(批处理图片数据)用的最多的是dimension为4的张量。
import torch
import numpy as np
# 声明一个两行三列的矩阵
a=torch.randn(2,3)
# 进行合法化检验
print(isinstance(a,torch.FloatTensor))
# cpu上的时候返回false
print(isinstance(a,torch.cuda.FloatTensor))
# 搬运到cuda上面,返回true
a=a.cuda()
print(isinstance(a,torch.cuda.FloatTensor))
# dimension为0的标量
b=torch.tensor(2.2)
print(b.shape)
print(b)
print(len(b.shape))
print(b.dim())
print(b.size())
# dimension为1的张量
print(torch.tensor([1.1]))
print(torch.tensor([1.1,2.2]))
print(torch.FloatTensor(1))
print(torch.FloatTensor(2))
data = np.ones(2) # 用numpy生成,然后转成tensor
print(data)
data = torch.from_numpy(data)
print(data,data.dtype)
# dimension为2的张量
a = torch.randn(2,3)
print(a)
print(a.shape)
print(a.size(0))
print(a.size(1))
print(a.shape[0])
print(a.shape[1])
# dimension为3的张量
a = torch.randn(1,2,3)
print(a)
print(a.shape)
print(a[0])
# dimension为4的张量
a = torch.randn(2,3,28,28)
print(a)
print(a.numel()) # 占的内存大小
print(a.dim()) # 维度大小
print(a.shape) # 全部信息
(2)Tensor创建
import numpy as np
import torch
# 由numpy创建,然后导入Tensor
a = np.array([2,3.3])
print(torch.from_numpy(a))
b = np.ones([2,3])
print(torch.from_numpy(b))
# tensor()接收现有数据 Tensor()和FloatTensor()接收维度信息,也可以接收数据(必须用list表示,尽量少用)
print(torch.tensor([2,3.3]))
print(torch.Tensor(2,3))
print(torch.FloatTensor(2,4))
# 养成一般初始化tensor的好习惯,不然生成的数据有问题,容易出现奇怪的bug,如果直接使用,数据一定要跟着覆盖
a = torch.empty(1)
print(a)
print(torch.Tensor(2,3))
print(torch.IntTensor(2,3))
print(torch.FloatTensor(2,3))
# pytorch默认tensor()是float,可以自行设置改成别的,强化学习中一般都是使用DoubleTensor,计算精确度会高一点
print(torch.tensor([1.2,2]).type())
torch.set_default_tensor_type(torch.DoubleTensor)
print(torch.tensor([1.2,2]).type())
# 随机初始化tensor rand(生成0-1的均匀随机数) rand_like(生成和某一个tensor差不多的) randint(min,max,[d1,d2])
a = torch.rand(3,3)
print(a)
b = torch.rand_like(a)
print(b)
c = torch.randint(1,10,[3,3])
print(c)
# 正态分布randn(均值为0,方差为1)
print(torch.randn(3,3))
# 自定义正态分布normal()生成长度为10,维度为1
# 长度为10,在0附近的值 方差从1到0以0.1的速度减小
print(torch.normal(mean=torch.full([10],0),std=torch.arange(1,0,-0.1)))
# full()函数生成一样值的张量
print(torch.full([2,3],6))
# dimension为0
print(torch.full([],7))
# dimension为1,长度为1
print(torch.full([1],8))
# arrange(min,max,等差值(默认为0))函数生成等差数列的张量
print(torch.arange(1,10,2))
# linspace()生成范围内等分的张量 start起始数 end结束数 steps几等份
print(torch.linspace(start=0,end=10,steps=4))
# logspace()生成10的start次方到10的end次方,steps表示分成多少个数
print(torch.logspace(start=0,end=-1,steps=1000))
# ones()生成全部为1的张量
print(torch.ones(3,3))
# zeros()生成全部为1的张量
print(torch.zeros(3,3))
# eye()生成主对角线全部为1的张量
print(torch.eye(5,5))
# randperm()随机打散数据排序
a = torch.rand(2,3)
b = torch.rand(2,2)
print(a)
print(b)
idx = torch.randperm(2)
print(idx)
print(idx)
print(a[idx])
print(b[idx])
(3)索引与切片(Index and slice)
import torch
# 基本索引用法
a = torch.rand(4,3,28,28)
print(a[0].shape)
print(a[0,0].shape)
print(a[0,0,2,4])
# 初级索引用法 空冒号可以省略,代表读取全部
print(a[:2].shape) # 查询一级从0到2但是不包括2的全部消息
print(a[:2,:1,:,:].shape) # 查询一级从0到2但是不包括2、二级从0到1通道但是不包括1的全部信息
print(a[:2,1:,:,:].shape) # 查询一级从0到2但是不包括2、二级从1通道到结束通道但是包括1的全部信息
print(a[:2,-1:,:,:].shape) # 查询一级从0到2但是不包括2、二级从-1一个通道到结束通道的全部信息
# 中级索引用法 隔行采样 start开始行:end结束行:空多少采样
print(a[:,:,0:28:2,0:28:2].shape)
print(a[:,:,::2,::2].shape)
# 高级索引用法
# 0:代表选第一级(batch) torch.tensor([0,2]):代表选第索引为0和2的两张图片
print(a.index_select(0,torch.tensor([0,2])).shape)
# 1:代表选第二级(color) torch.tensor([1,2]):代表选第索引为1和2的两色域
print(a.index_select(1,torch.tensor([1,2])).shape)
# 2:代表选第三级(height) torch.arange(8):代表选第索引从0到7的8行
print(a.index_select(2,torch.arange(8)).shape)
# 3:代表选第四级(width) torch.arange(9):代表选第索引从0到8的9行
print(a.index_select(3,torch.arange(9)).shape)
# 更高级索引用法(使代码优雅,不熟练可以不用) ...代表任何空着的参数,三个点的使用你要自己能看出来是缺啥,不能你自己都不知道,则不行
print(a[...].shape)
print(a[1,...].shape)
print(a[:,1,...].shape)
print(a[...,:2].shape)
# masked_select()掩码查询数据,会将数据打平,即变成维度为1,长度不定的张量
x = torch.randn(3,4)
print(x)
print(torch.masked_select(x,x.ge(0.5)))
print(torch.masked_select(x,x.ge(0.5)).shape)
# take()利用打平后的索引进行查询
print(torch.take(x,torch.tensor([0,2,5])))
(4)维度变换
import torch
'''
view()保证变换前后的Before_prod(a,size)=After_prod(a,size)
要满足物理意义 适合线性全连接层输入(二维信息)
将重点关注的单独列出来,其他的合并,即根据对数据的理解进行适当view()操作
注意:数据的存储/维度顺序不要弄乱
'''
a = torch.rand(4,1,28,28)
# view()
print(a.view(4,1*28*28).shape)
print(a.view(4*1*28,28).shape)
print(a.view(4*1,28,28).shape)
# unsqueeze(index) 注意索引范围能取的值:[-a.dim()-1,a.dim()+1)
# 索引为正:在索引位置前增加一个组
# 索引为负:在索引位置后增加一个组
print(a.unsqueeze(1).shape)
# 演示增加维度,索引位置不同,加[]位置就不同
b = torch.tensor([1,2,3,4])
print(b)
print(b.unsqueeze(1)) # 增加维度
print(b.unsqueeze(0)) # 增加维度
# 实例应用 要想bias作用在f上,必须先增加c的维度
c = torch.rand(32) # bias
f = torch.rand(4,32,14,14) # bias相当于给每个channel上的所有像素增加一个偏置
x1=c.unsqueeze(0) # 第一步
print(x1.shape)
x2=x1.unsqueeze(2) # 第二步
print(x2.shape)
x3=x2.unsqueeze(3) # 第三步
print(x3.shape)
# 利用上面的x3学习squeeze() 直接squeeze()会压缩所有级shape为1的级 如果有索引,其shape不为1,则不变
print(x3.squeeze().shape)
print(x3.squeeze(0).shape)
print(x3.squeeze(1).shape)
print(x3.squeeze(2).shape)
print(x3.squeeze(3).shape)
# expand(不会主动复制内存数据)函数:将x3的各个级的shape增加到f(只支持各级处shape为1才能增加) **推荐**
print(x3.expand(4,32,14,14).shape)
print(x3.expand(-1,-1,14,14).shape) # 如果哪一个级不想改变,则写-1就行
# repeat(会主动复制内存数据)函数:将x3的各个级的shape复制(次数,次数,次数,次数)(支持各级处shape,不要求为1) **不推荐**
print(x3.repeat(4,1,14,14).shape)
print(x3.repeat(4,32,14,14).shape)
# t()转置 只适用2D,不适用3D、4D、1D
y = torch.rand(2,3)
print(y) # 转置前
print(y.t()) # 转置后
# transpose(适用所有Demension)交换维度 注意:数据的维度顺序必须和存储数据一样 contiguous()使得交换维度后数据依然连续
m = torch.rand(4,3,32,32)
print(m) # 交换前 [b,c,w,h]
print(m.transpose(1,3).contiguous().shape) # 一三维度交换后,使用contiguous()使得数据连续 [b,h,w,c]
print(m.transpose(1,3).contiguous().view(4,3*32*32).shape) # view()打平 [b,h*w*c]
print(m.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).shape) # view()还原:数据的维度顺序必须和存储数据一样 [b,h,w,c]
print(m.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3).shape) # 维度还原 [b,c,w,h]
m1=m.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3) # m1和m一样
print(torch.all(torch.eq(m,m1))) # 输出为True
m2=m.transpose(1,3).contiguous().view(4,3*32*32).view(4,3,32,32).transpose(1,3) # m2和m不一样
print(torch.all(torch.eq(m,m2))) # 报错
# [b,h,w,c]是numpy存储图片的格式,需要这一步才能导出numpy
# 所以要将tensor的[b,c,h,w] --> [b,h,w,c] 即[0,1,2,3] --> [0,2,3,1]
# transpose()太过繁琐,我们使用permute() 任意维度交换后,使用contiguous()使得数据连续
n = torch.rand(4,3,28,32)
print(n.permute(0,2,3,1).shape)
(5)自动扩展(Broadcast)
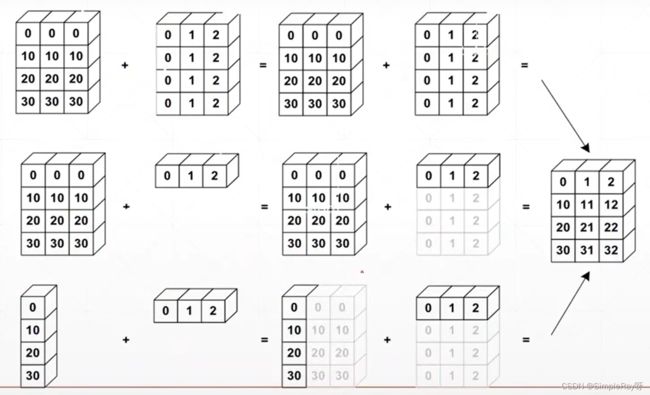
Broadcast是为了解决实际问题而来的,既可以省略内存消耗,又可以优化代码。
Broadcast适用场景:小维度指定(height,width),大维度随意(batch,channel)。
(先扩展维度(在合适位置),再扩展shape)。
在数学运算中自动执行。
(6)拼接与拆分(merge or split)

import torch
a = torch.rand(4,32,8)
b = torch.rand(5,32,8)
# cat([指定是哪些tensor做运算],dim=0(指定运算的维度是哪一维度))
# 要使用cat()函数只需要满足某一维度shape不同,并且有实际需求,例如同一班级不同学生成绩表合并
print(torch.cat([a,b],dim=0).shape)
a1 = torch.rand(4,3,32,32)
a2 = torch.rand(5,3,32,32)
print(torch.cat([a1,a2],dim=0).shape)
a2 = torch.rand(4,1,32,32)
print(torch.cat([a1,a2],dim=1).shape)
a1 = torch.rand(4,3,16,32)
a2 = torch.rand(4,3,16,32)
print(torch.cat([a1,a2],dim=2).shape)
# stack([指定是哪些tensor做运算],dim=0(指定在哪一维度前面加维度并根据实际情况生成shape))
# 要使用stack()函数只需要满足各个维度shape相同,并且有实际需求,例如不同班级不同学生成绩表分组(加一个维度表示组)
a = torch.rand(32,8)
b = torch.rand(32,8)
c = torch.rand(32,8)
print(torch.stack([a,b,c],dim=0).shape)
# split()函数一是拆分长度一样(直接给num) | 二是长度不一样(直接给[list]怎么分) 记得指定拆分维度
x = torch.stack([a,b],dim=0)
aa,bb = x.split(1,dim=0)
print(aa.shape)
print(bb.shape)
y = torch.rand(3,32,8)
aa,bb = y.split([2,1],dim=0)
print(aa.shape)
print(bb.shape)
# chunk()函数直接给定拆成多少份 记得指定拆分维度
aa,bb,cc = y.chunk(3,dim=0)
print(aa.shape)
print(bb.shape)
print(cc.shape)
三、相关操作
(1)数学运算(Mathematical operations)
import torch
# Broadcst的存在,使得b会自动增加维度和维度上的shape,进行运算
# + — * / 四种运算可以用四个函数add()、sub()、mul()、div()替代 推荐使用重载运算符更加简洁
a = torch.rand(3,4)
b = torch.rand(4)
print(a+b)
# 矩阵乘法matmul() 推荐使用(mm()和@尽量不用)
x1 = torch.full([2,2],3)
x2 = torch.ones(2,2)
print(x1)
print(x2)
print(torch.matmul(x1,x2))
# 二维矩阵乘法
a = torch.rand(4,784)
# 前面写的是channel-out(出去的shape) 后面写的是channel-in(进去的shape)
b = torch.rand(512,784)
# 注意t()只适合2维,高维转置要用transpose()
print(torch.matmul(a,b.t()).shape)
# 高维矩阵乘法
a = torch.rand(4,3,28,64)
b = torch.rand(4,3,64,32)
# 多维度matmul()函数是自动运算后面两维度
print(torch.matmul(a,b).shape)
c = torch.rand(4,1,64,32)
# 满足Broadcast机制也是可以运算的
print(torch.matmul(a,c).shape)
a = torch.full([2,2],3)
# pow(多少次方就写几)
print(a.pow(2))
# a的平方
aa = a**2
# sqrt() 开二次方
print(aa.sqrt())
# rsqrt() 倒数
print(aa.rsqrt())
# 等价开二次方
print(aa**(0.5))
# 以e为底,矩阵为幂
a = torch.exp(torch.ones(2,2))
print(a)
# 开log次方,就是把a放进log()里面
print(torch.log(a))
# floor(向上取整) ceil(向下取整) trunc(取整数部分) frac(取小数部分) round(四舍五入得整数)
a = torch.tensor(3.14)
b = torch.tensor(3.51)
print(a.floor(),a.ceil(),a.trunc(),a.frac(),a.round(),b.round())
# max(最大梯度) median(平均梯度) clamp(10(比10大的梯度)) clamp(0,10(0-10的梯度))
grad = torch.rand(2,3)*15
print(grad.max(),grad.median())
print(grad.clamp(10))
print(grad)
print(grad.clamp(0,10))
(2)统计属性(Statistical properties)
import torch
# norm(代表求第几范数,dim=在哪一个维度求) 1:求和 2:每一个平方后求和再开平方
a = torch.full([8],1)
b = a.view(2,4)
c = a.view(2,2,2)
print(a)
print(b)
print(c)
print(a.norm(1),b.norm(1),c.norm(1))
print(a.norm(2),b.norm(2),c.norm(2))
print(b.norm(1,dim=1),b.norm(2,dim=1))
print(c.norm(1,dim=0),c.norm(2,dim=0))
# min(最小值) max(最大值) mean(平均值) prod(元素累乘)
a = torch.arange(8).view(2,4).float()
print(a)
print(a.min(),a.max(),a.mean(),a.prod())
# argmax(最大值索引) argmin(最小值索引) 这两个默认会把数据打平再给索引值,如果不想则可以给定维度
print(a.argmax(),a.argmin())
a = torch.randn(4,10) #求每一行最大的值的索引
print(a)
print(a.argmax(dim=1))
# 给max()配置维度,则可以输出元素值(支撑值)和元素值(支撑值)的索引值 keepdim=True保持原来的维度,会自动broadcast
print(a.max(dim=1))
print(a.max(dim=1,keepdim=True))
print(a.argmax(dim=1,keepdim=True))
# topk(想得到的最大的几个数,求哪一维度,largest=False(不填默认为true,改成false求最小的几个)):可以输出元素值(支撑值)和元素值(支撑值)的索引值
# kthvalue(想得到的最小的第几个数,求哪一维度):可以输出元素值(支撑值)和元素值(支撑值)的索引值
a = torch.randn(4,10)
print(a)
print(a.topk(3,dim=1))
print(a.topk(3,dim=1,largest=False))
print(a.kthvalue(8,dim=1))
# 比较操作
print(a>0,a.gt(0),a!=0,torch.eq(a,a))
(3)高阶操作(High order operation)
import torch
# where(判断条件,条件满足选择a,条件不满足选择b) 高度并行
cond = torch.rand(2,2)
print(cond)
a = torch.full([2,2],0)
b = torch.full([2,2],1)
print(a,b)
print(torch.where(cond>0.5,a,b))
# gather(标签向量,操作维度,索引根据)函数根据索引,将符合要求的元素值(支撑值)进行替换标记
prob = torch.randn(4,10)
print(prob)
idx = prob.topk(3,dim=1)
print(idx)
print(idx[1])
idx = idx[1]
label = torch.arange(10)+100
print(label)
print(torch.gather(label.expand(4,10),dim=1,index=idx.long()))
print(idx.long())
四、相关概念
(1)梯度(Gradient)
- 梯度有长度(len 在当前点增长的快慢)和方向(dir 在当前点的一个增长方向)。
- 梯度更新公式的确定根据实际情况而定。
- 介绍:ResNet56(he kaiming) 鞍点(一个维度的最小值,另一个维度的最大值) 局部最小值
- 影响搜索的因素:初始点(initialization status) 学习率(learning rate) 动量(momentum:怎么逃离局部最小值)
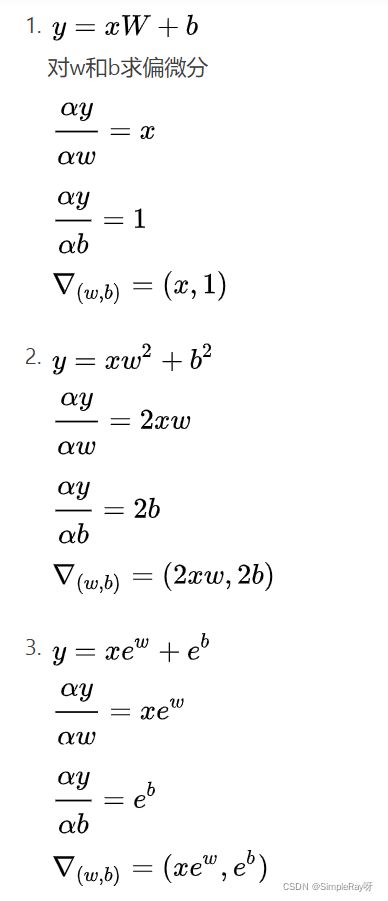

(2)激活函数与Loss的梯度
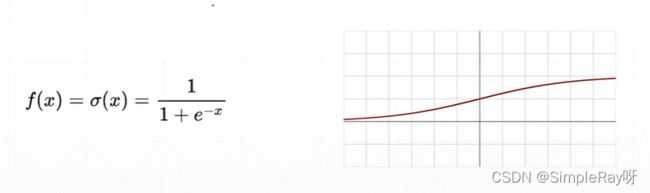
1.Sigmoid()激活函数:
- 优点:连续光滑,值压缩在0-1之间,可以用作输出层,输出表示概率 。
- 缺点:两端极限导数趋于0,容易出现梯度离散现象。
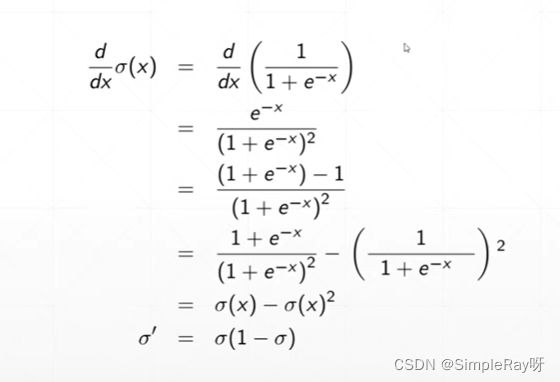
import torch
from torch.nn import functional as F
z = torch.linspace(-100,100,10)
print(z)
# 通用这种方式
print(z.sigmoid())
# 已经弃用了
print(F.sigmoid(z))
2.Tanh()激活函数:
- 多用于RNN(循环神经网络

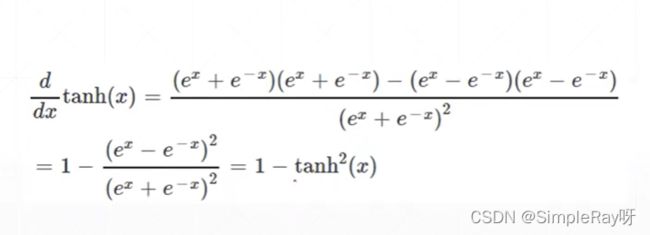
import torch
a = torch.linspace(-1,1,10)
print(a)
print(a.tanh())
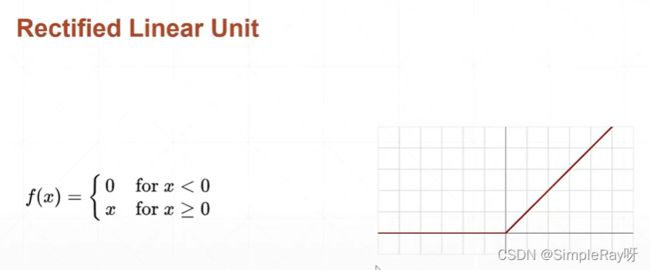
3.Rectified Linear Unit (RELU())激活函数:修正线性单元
- 优点:梯度不变可以避免梯度离散和梯度爆炸。
import torch
from torch.nn import functional as F
# Relu函数
a = torch.linspace(-1,1,10)
print(a)
print(a.relu())
print(F.relu(a))
4.Mean Squared Error(均方差)以及MSE梯度求导方式:
- 通用公式1:
l o s s = ∑ 1 n [ y − f ( x , w , b ) ] 2 loss = \sum_1^n[y-f(x,w,b)]^2 loss=1∑n[y−f(x,w,b)]2
- 通用公式2:(L2norm()函数是每一项相减的平方的和再开平方,所以用norm()时候要平方)
L 2 − n o r m = ∣ [ y − ( x w + b ) ] ∣ 2 L2-norm = |[y-(xw+b)]|_2 L2−norm=∣[y−(xw+b)]∣2
l o s s = n o r m ( y − ( x w + b ) ) 2 loss = norm(y-(xw+b))^2 loss=norm(y−(xw+b))2
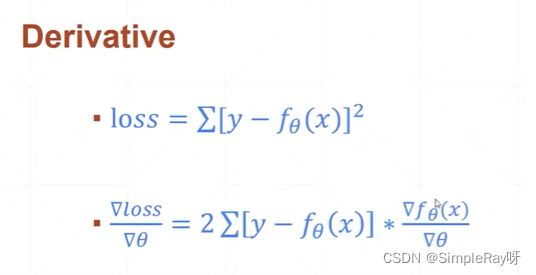
import torch
# MSE均方差求解:学习pytorch的自动求导
x = torch.ones(1) # 声明初始化x
w = torch.full([1],2) # 声明一个维度为1,长度为1的w 默认w是不具备求导机制的,需要手动设置需要导数信息
mse = F.mse_loss(torch.ones(1),x*w) # (预测值,label)
print(mse)
w.requires_grad_() # 使得w具有求导机制,也可以开始创建时候设置好: w = torch.tensor([1],requires_grad=True)
mse = F.mse_loss(torch.ones(1),x*w) #这是一个动态建图过程,将所有loss计算形成图,用自动求导找最低点
print(torch.autograd.grad(mse,[w]))
- 查看梯度的两种方法:

'''
第一种 torch.autograd.grad(mse,[w]) 这个是生成一个梯度[list]
'''
x = torch.ones(1)
w = torch.full([1],2)
mse = F.mse_loss(torch.ones(1),x*w)
print(mse)
w.requires_grad_()
mse = F.mse_loss(torch.ones(1),x*w)
print(torch.autograd.grad(mse,[w]))
'''
第二种 backward() 反向求解已经计算过的loss梯度,可直接调用查看梯度,会将其梯度值附加在每一个成员变量上面
'''
x = torch.ones(1)
w = torch.full([1],2)
mse = F.mse_loss(torch.ones(1),x*w)
print(mse)
w.requires_grad_()
mse = F.mse_loss(torch.ones(1),x*w)
mse.backward()
print(w.grad)
5.Softmax()激活函数:
- 所有的输出值和为1,用于分类问题,输出值间的差距更大(大的相对更大,小的相对更小)。



# Softmax()函数
a = torch.rand(3)
a.requires_grad_()
print(a)
p = F.softmax(a,dim=0)
# 不加retain_graph=True,默认只保存导数,不保存图,加了之后可以保存图,方便下次调用求导
print(torch.autograd.grad(p[1],[a],retain_graph=True))
print(torch.autograd.grad(p[1],[a]))
(3)感知机(Perceptron)
1.单层感知机:

-
输入X(右上角是第几层,右下角是第几个节点)
权值W(右上角是第几层,右下角i是上一层节点编号j是这一层节点编号)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iv2L9Dlx-1645457358188)(E:\storage\Typora_camera/感知器.png)]
-
单层感知机求导过程代码实现:
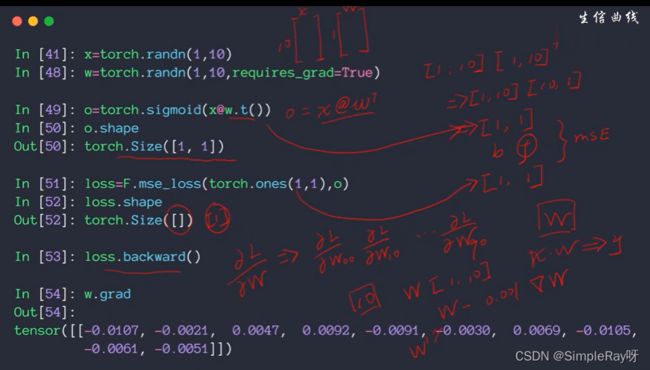
import torch
from torch.nn import functional as F
# Single-layer perceptron(单层感知机求导,梯度求解)
x = torch.randn(1,10)
print(x)
w = torch.randn(1,10,requires_grad=True)
print(w)
o = torch.sigmoid(x@w.t()) # 为了只有一个输出,单层,实质是求和操作
print(o,o.shape)
loss = F.mse_loss(torch.ones(1,1),o)
print(loss,loss.shape)
loss.backward()
print(w.grad)
-->
tensor([[ 0.1603, -0.9209, -1.5525, 0.9775, -1.7036, 0.2006, 0.5388, 0.1566,
0.6754, 1.5297]])
tensor([[ 0.6522, -0.0858, -0.3519, 1.1445, 1.5553, 1.4747, 0.3618, 0.0294,
-0.1192, -0.0952]], requires_grad=True)
tensor([[0.3701]], grad_fn=<SigmoidBackward>) torch.Size([1, 1])
tensor(0.3968, grad_fn=<MeanBackward0>) torch.Size([])
tensor([[-0.0471, 0.2705, 0.4560, -0.2871, 0.5004, -0.0589, -0.1583, -0.0460,
-0.1984, -0.4493]])
2.多层感知机:
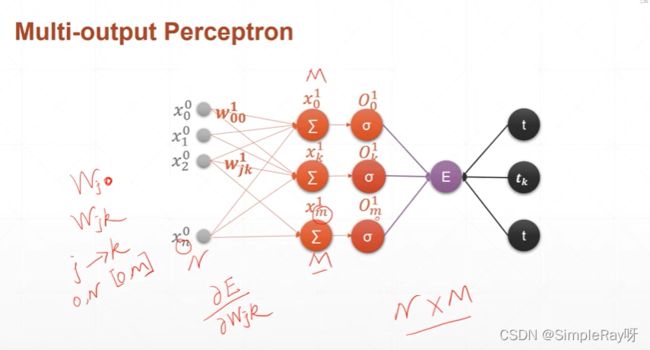
-
多层感知机求导过程:
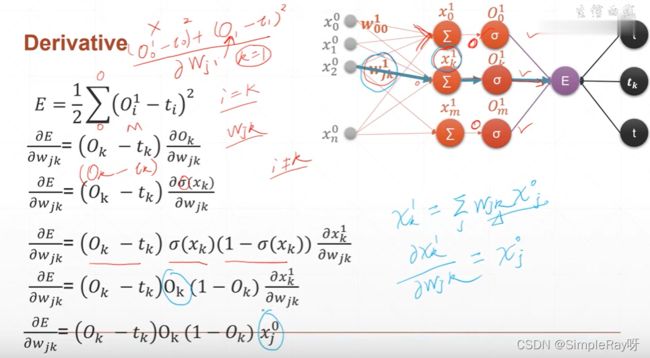
-
多层感知机求导过程代码实现:

# Multi-layer perceptron(单层感知机求导,梯度求解)
x = torch.randn(1,10)
w = torch.randn(2,10,requires_grad=True)
print(x)
print(w)
o = torch.sigmoid(x@w.t()) # 为了只有多个输出,多层,实质是求和操作
print(o,o.shape)
loss = F.mse_loss(torch.ones(1,2),o)
print(loss,loss.shape)
loss.backward()
print(w.grad)
-->
tensor([[ 0.5127, 1.9123, 0.0381, -0.3692, -0.4895, 1.4399, -1.4613, -0.4398,
1.2693, 1.1908]])
tensor([[ 0.3445, 1.7399, 0.8805, 0.0370, -0.9269, 0.2442, 0.3352, -0.1175,
1.3719, -1.0904],
[ 0.0079, 1.4492, 0.3104, 0.3695, 0.9918, 0.6654, 1.9503, 0.3700,
0.0901, -0.2590]], requires_grad=True)
tensor([[0.9871, 0.4792]], grad_fn=<SigmoidBackward>) torch.Size([1, 2])
tensor(0.1357, grad_fn=<MeanBackward0>) torch.Size([])
tensor([[-8.4825e-05, -3.1639e-04, -6.3114e-06, 6.1089e-05, 8.0984e-05,
-2.3824e-04, 2.4177e-04, 7.2772e-05, -2.1001e-04, -1.9702e-04],
[-6.6638e-02, -2.4856e-01, -4.9582e-03, 4.7992e-02, 6.3621e-02,
-1.8716e-01, 1.8993e-01, 5.7170e-02, -1.6498e-01, -1.5478e-01]])
(4)链式法则(Chain rule)
- 概念:

- 链式法则实际应用实例图:
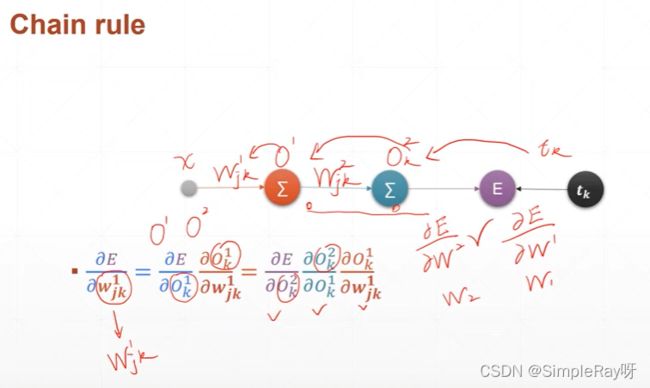
- 链式法则代码示例:
import torch
# 声明变量
x = torch.tensor(1.)
w1 = torch.tensor(2.,requires_grad=True)
b1 = torch.tensor(1.)
w2 = torch.tensor(2.,requires_grad=True)
b2 = torch.tensor(1.)
# 定义相关函数
y1 = x*w1+b1
y2 = y1*w2+b2
# 单独求导
dy2_dy1 = torch.autograd.grad(y2,[y1],retain_graph=True)
dy1_dw1 = torch.autograd.grad(y1,[w1],retain_graph=True)
dy2_dw1 = torch.autograd.grad(y2,[w1],retain_graph=True)
# 链式法则得出结果
print(dy2_dy1*dy1_dw1) #不支持这样的运算,理解就行
# torch自带函数得出结果
print(dy2_dw1)
(5)MLP(Multi-layer perceptron)反向传播
- 公式推导:
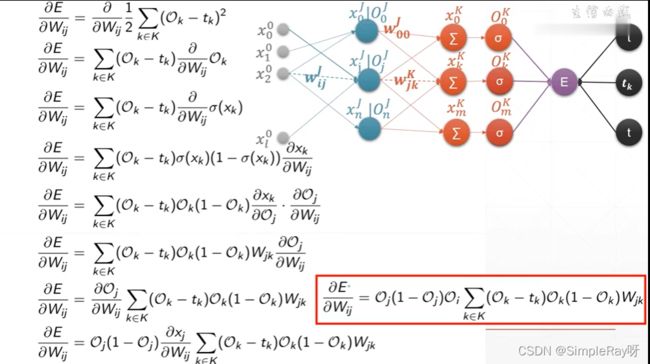
- 公式简化:
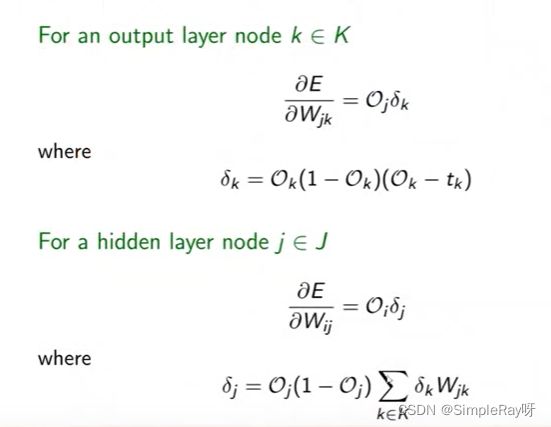
- 反向计算每一层导数再用链式法则更新梯度:
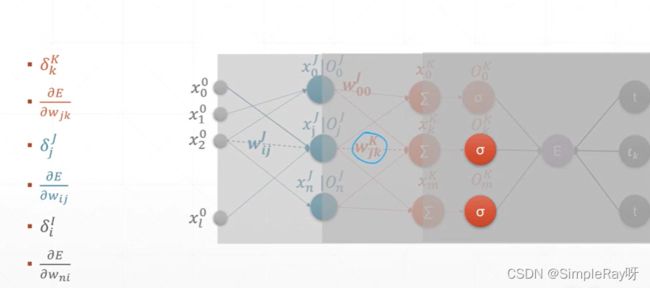
(6)优化问题实战(Himmelblau function)
-
代码解析

-
代码实现
import torch
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 声明函数
def himmelblau(x):
return (x[0]**2+x[1]-11)**2+(x[0]+x[1]**2-7)**2
# 定义参数
x = np.arange(-6,6,0.1)
y = np.arange(-6,6,0.1)
print('x,y range:',x.shape,y.shape)
# meshgrid()把x,y范围传进去会生成两张平面图片,记录x(参数一,参数二),y(参数一,参数二)的位置
X,Y = np.meshgrid(x,y)
print(X)
print('X,Y maps:',X.shape,Y.shape)
Z = himmelblau([X,Y])
# 绘制3D图
fig = plt.figure('自定义图片名字')
ax = fig.gca(projection='3d')
ax.plot_surface(X,Y,Z)
ax.view_init(60,-30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# 初始化开始的点,并且声明可以对其求导
x = torch.tensor([4.,0.],requires_grad=True)
# 定义优化器
optimizer = torch.optim.Adam([x],lr=1e-3)
# 进行优化求解
for step in range(20000):
# 求解预测值
pred = himmelblau(x)
# 梯度清零
optimizer.zero_grad()
# 求导
pred.backward()
# 更新梯度
optimizer.step()
# 打印输出
if step % 2000 == 0:
print('step {} : x = {}, f(x) = {}'.format(step,x.tolist(),pred.item()))
(7)Logistic Regression
- 为什么不最大化准确度?(why not maximize accurary?)

- why call Logistic Regression?

(8)熵(Entropy)
- 熵:值越大,代表越稳定,没有惊喜度;反过来,代表不稳定,惊喜度很大。
- 指代一个分布H§

- 代码实现求熵:
import torch
# 彩票抽奖案例
a = torch.full([4],1/4)
print(a)
print(a*torch.log2(a))
# 执行交叉熵公式,求出熵
print(-(a*torch.log2(a)).sum())
a = torch.tensor([0.1,0.1,0.1,0.7])
# 执行交叉熵公式,求出熵
print(-(a*torch.log2(a)).sum())
a = torch.tensor([0.001,0.001,0.001,0.999])
# 执行交叉熵公式,求出熵
print(-(a*torch.log2(a)).sum())
(9)交叉熵(Cross entropy)
- 指代两个分布H(p,q)
- 注意:它是紧跟softmax()后的,F调用cross_entropy()则会自动调用softmax()+log()+null_loss()操作。

- 交叉熵越小,可信度越高:二分类问题就是用交叉熵表示可信度

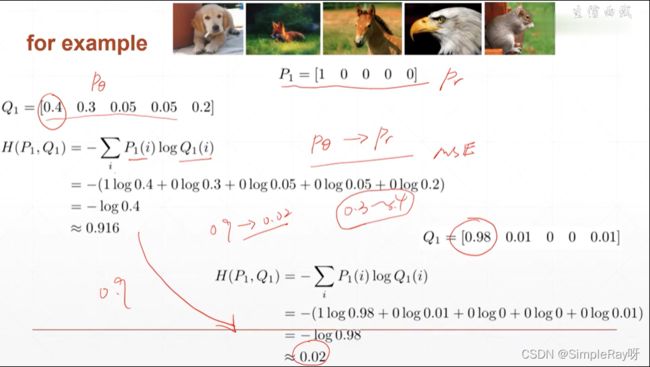
- 代码实现求交叉熵:
import torch
from torch.nn import functional as F
# cross_entrory 交叉熵
# cross_entropy()函数直接求
x = torch.randn(1,784)
w = torch.randn(10,784)
logits = x@w.t()
print(logits)
print(F.cross_entropy(logits,torch.tensor([3])))
# softmax()+log()+null_loss()三部曲求
x = torch.randn(1,784)
w = torch.randn(10,784)
logits = x@w.t()
pred = F.softmax(logits,dim=1)
print(pred)
pred_log = torch.log(pred)
print(pred_log)
print(F.nll_loss(pred_log,torch.tensor([3])))
(10)多分类问题实战
# 代码由YCR写于2021/11/24
import torch
from torch.nn import functional as F
import torch.nn as nn
import torchvision
batch_size = 200
learning_rate = 0.01
epochs = 10
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('../data',train=True,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('../data',train=True,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=True)
# 定义参数
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
# 定义函数
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
# 定义优化器
optimizer = torch.optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon = nn.CrossEntropyLoss()
# 训练
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
logits = forward(data)
loss = criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
test_loss = 0
correct = 0
for data,target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss+=criteon(logits,target).item()
pred = logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
test_loss/=len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f},Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss,correct,len(test_loader.dataset),
100. * correct / len(test_loader.dataset)
))
(11)激活函数与GPU加速
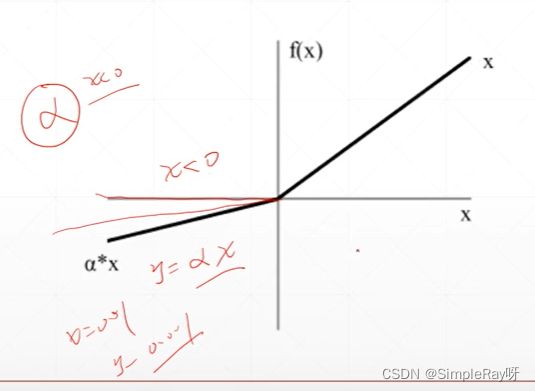
Leaky_Relu:

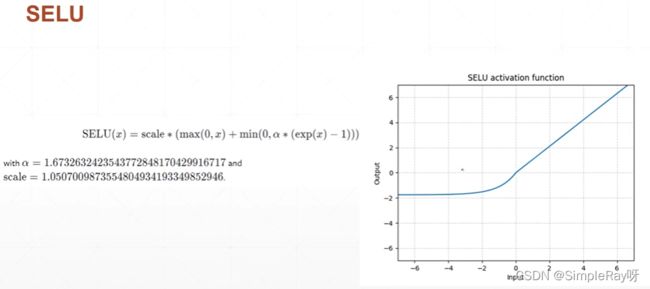
selu:
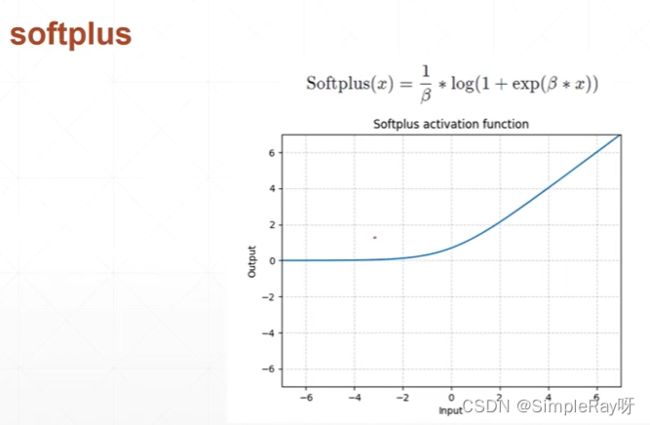
Softplus:
调用GPU:
# 定义设备,cuda后面跟的数字代表是第几个显卡,可前往任务管理器中去看显卡编号
device = torch.device('cuda:0')
# 将网络搬运到gpu上去运行,还是返回一样类型的数据回来
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(),lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1,28*28)
# 推荐使用data.to(device)
# data2=data.to(device) data2为GPU类型,data为CPU类型
data,target = data.to(device),target.cida()
argmax: 取最大值所在的索引(可取softmax()之前的,也可以是之后的,因为softmax()不改变单调性)
argmin: 取最小值所在的索引(可取softmax()之前的,也可以是之后的,因为softmax()不改变单调性)
max: 取最大值所在的索引(只可以取softmax()之后的)
(12)TensorboardX和Visdom
TensorboardX: 要给tensor做呈现,先转化到cpu上面,再转化成numpy数据,才能赋值给TensorboardX。
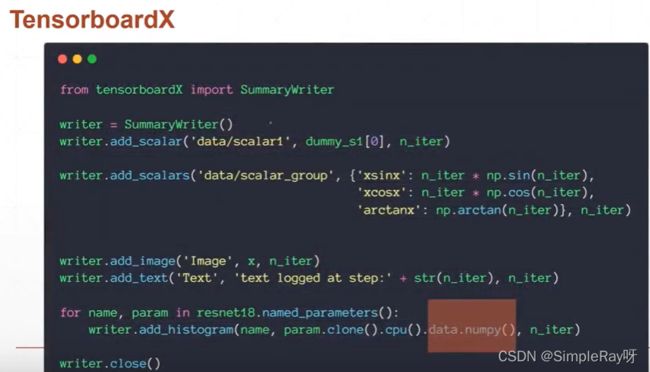
Visdom: 原生接收tensor,运行效率更高,TensorboardX会写入文件一些东西。
# 代码由YCR写于2022/2/19
from visdom import Visdom
# 创建实例
viz = Visdom()
'''一条线'''
# 创建直线,将最新数据添加上去line([Y],[X],win(小窗口唯一标识符),env(大窗口唯一标识符),opts(命名窗口名字))
viz.line([0.],[0.],win='train_loss',opts=dict(title='train loss'))
# 非image(tensor)数据穿的还是numpy数据(loss.item()),golbal_step(X参数),update='append'(新点添加在现有直线后面)
viz.line([loss.item()],[golbal_step],win='train_loss',update='append')
'''多条线'''
# line([[y1,y2]],[x],win(小窗口唯一标识符),env(大窗口唯一标识符),opts(命名窗口名字,定义两条线的名字))
viz.line([[0.0,0.0]],[0.],win='test',opts=dict(title='test loss&acc',legend=['loss','acc']))
viz.line([[test_loss,correct / len(test_loader.dataset)]],[golbal_step],win='train_loss',update='append')
'''呈现图片'''
# visdom可以直接将image的tensor数据展现出来
viz.image(data.view(-1,1,28,28),win='x')
#
viz.text(str(pred.detach().cpu().numpy()),win='pred',opts=dict(title='pred'))
(13)过拟合和欠拟合
欠拟合(表达能力很弱):实际训练出来的模型还达不到真实生活需要。
过拟合(表达能力很强):实际训练出来的模型比真实生活太过头了。
过拟合的检测方法:
- 将原始数据分为Train_set和Test_set(防止过拟合,边训练边检测,寻找到恰到好处的模型参数)
- 将原始数据分为Train_set和Val_set(防止过拟合,边训练边检测,寻找到恰到好处的模型参数)和Test_set(真是交给用户时测试数据)
# 代码由YCR写于2022/2/20 时间:9:12
import torch
from torch import optim
from torch.nn import functional as F
import torch.nn as nn
import torchvision
from visdom import Visdom
batch_size = 200
learning_rate = 0.01
epochs = 10
viz = Visdom()
# 定义训练集
train_db = torchvision.datasets.MNIST('../data',train=True,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,),(0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,shuffle=True)
# 定义测试集
test_db = torchvision.datasets.MNIST('../data',train=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,),(0.3081,))
]))
test_loader = torch.utils.data.DataLoader(
test_db,
batch_size=batch_size,shuffle=True)
# 使用random_split()函数,将上面划分的训练集分成新的训练集和校验集(用来找寻最好的模型参数)
print('train:',len(train_db),'test:',len(test_db))
train_db,val_db = torch.utils.data.random_split(train_db,[50000,10000])
print('db1:',len(train_db),'db2:',len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size,shuffle=True)
# 编写网络模型
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.model = nn.Sequential(
nn.Linear(784,200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self,x):
x = self.model(x)
return x
# 使用GPU加速运算
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(),lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
# 训练
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
test_loss = 0
correct = 0
for data,target in val_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss+=criteon(logits,target).item()
pred = logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
# 数据使用visdom呈现,还没写好,待完善。
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc', legend=['loss', 'acc']))
viz.line([[float(test_loss), float(100.*correct / len(val_loader.dataset))]], [100], win='train_loss', update='append')
test_loss/=len(val_loader.dataset)
print('\nVAL set:Average loss:{:.4f},Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss,correct,len(val_loader.dataset),
100. * correct / len(val_loader.dataset)
))
# 交付时候进行模型验证
test_loss = 0
correct = 0
for data,target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss+=criteon(logits,target).item()
pred = logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
test_loss/=len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f},Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss,correct,len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
防止过拟合:
正则化(Regularization),可以使得贝塔值接近于0,防止网络模型将噪声点太过放大而影响实际的模型, 以增大训练误差为代价来减少测试误差的所有策略 。
常见的两种正则化:


# L1-regularization:pytorch不支持,需要手动配置
regularization_loss = 0
for param in model.parameters():
regularization_loss+=torch.sum(torch.abs(param))
classify_loss = criteon(logits,target)
loss = classify_loss + 0.01*regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
#L2-regularization:
'''
(1)通过设置weight_decay,也就是w,会迫使二范数介于0,会使网络复杂度降低很多。
(2)若没有过拟合设置会导致网络性能下降,有过拟合可以使网络复杂度降低(test的表现会好一些)。
'''
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(),lr=learning_rate,weight_decay=0.01)
criteon = nn.CrossEntropyLoss().to(device)
(14)防止overfitting
方案一:动量
# SGD中添加momentum就可以很方便的使用动量
optimizer = torch.optim.SGD(model.parameters(),args.lr,
momentum=args.momentum,weight_decay=args.weight_decay)
# loss达到一个plateau(平原),维持超过了耐心值,就需要做一个min的衰减
scheduler = ReduceLROnPlateau(optimizer,'min')
for epoch in xrange(args.start_epoch,args.epochs):
train(train_loader,model,criterion,optimizer,epoch)
result_avg,loss_val = validate(val_loader,model,criterion,epoch)
scheduler.step(loss_val)
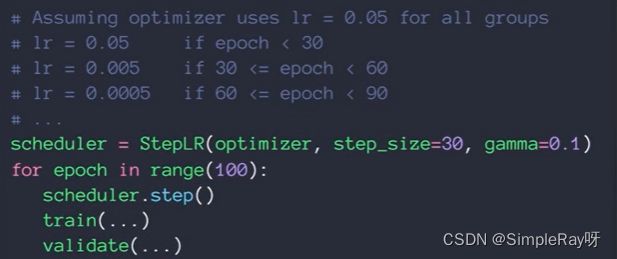
方案二:学习率衰减
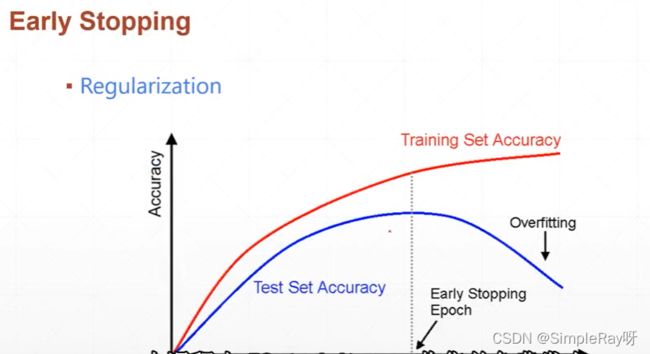
方案三:提前终止训练(根据经验值和模型预估值确定终止那个点)
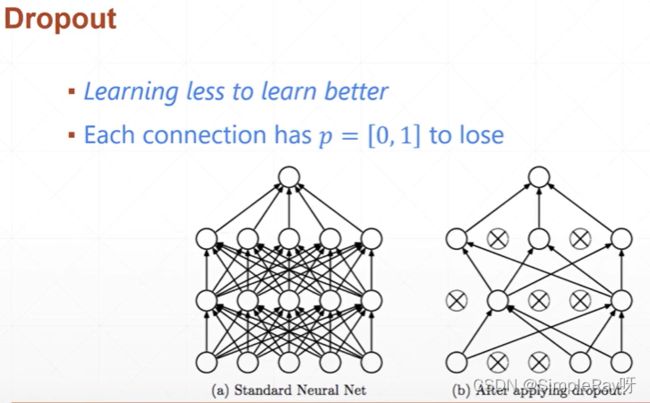
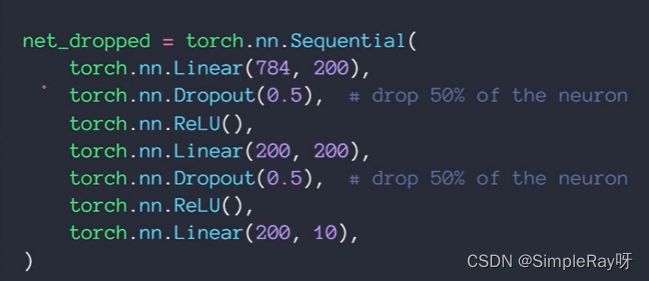
方案四:dropout(概率性丢掉一些W参数,而不是L2正则化将二范数逼近0)
- train可以概率性丢掉一些连接
- test的时候不能,net_dropped.eval(),将连接全部用上,否则表现会有差别