【强烈推荐】YOLOv7部署加速590%,BERT部署加速622%,这款开源自动化压缩工具必须收藏!...
导读
众所周知,计算机视觉技术(CV)是企业人工智能应用比重最高的领域之一。为降低企业成本,工程师们一直在探索各类模型压缩技术,来产出“更准、更小、更快”的AI模型部署落地。而在自然语言处理领域(NLP)中,随着模型精度的不断提升,模型的规模也越来越大,例如以BERT、GPT为代表的预训练模型等,这成为企业NLP模型部署落地的拦路虎。
本文为大家介绍一个低成本、高收益的AI模型自动压缩工具(ACT, Auto Compression Toolkit),无需修改训练源代码,通过几十分钟量化训练,保证模型精度的同时,极大的减小模型体积,降低显存占用,提升模型推理速度,助力AI模型的快速落地。
使用ACT中的基于知识蒸馏的量化训练方法训练YOLOv7模型,与原始的FP32模型相比,INT8量化后的模型减小75%,在NVIDIA GPU上推理加速5.89倍。使用ACT中的非结构化稀疏和蒸馏方法训练PP-HumanSeg模型,与压缩前相比在ARM CPU上推理加速达1.49倍。
表1 自动压缩工具在CV模型上的压缩效果和推理加速

利用ACT中的结构化稀疏和蒸馏量化方法训练ERNIE3.0模型,与原始的FP32对比,INT8量化后的模型减小185%,在NVIDIA GPU上推理加速6.37倍。
表2 自动压缩工具在NLP模型上的压缩效果和推理加速

本文将从以下6个方面进一步技术解读,全文大约3900字,预计阅读时长5分钟。
一
四步YOLOv7自动压缩实战
二
四步BERT自动压缩实战
三
模型的推理部署
四
直播课报名
五
自动压缩技术解读
六
未来工作展望
感谢大家Star关注:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
加入自动压缩技术交流群
 入群福利
入群福利
获取自动化压缩详解本次升级内容的直播课链接
获取压缩团队整理的重磅学习大礼包,包括:
深度学习课程
压缩方向顶会论文合集
压缩历次发版直播课程视频
百度最高奖获得者:模型压缩架构师培训课资料

 入群方式
入群方式
扫码关注公众号,填写问卷进入微信群
直播前,福利公布到群公告

01
四步YOLOv7自动压缩实战
1.准备预测模型:导出ONNX模型。
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
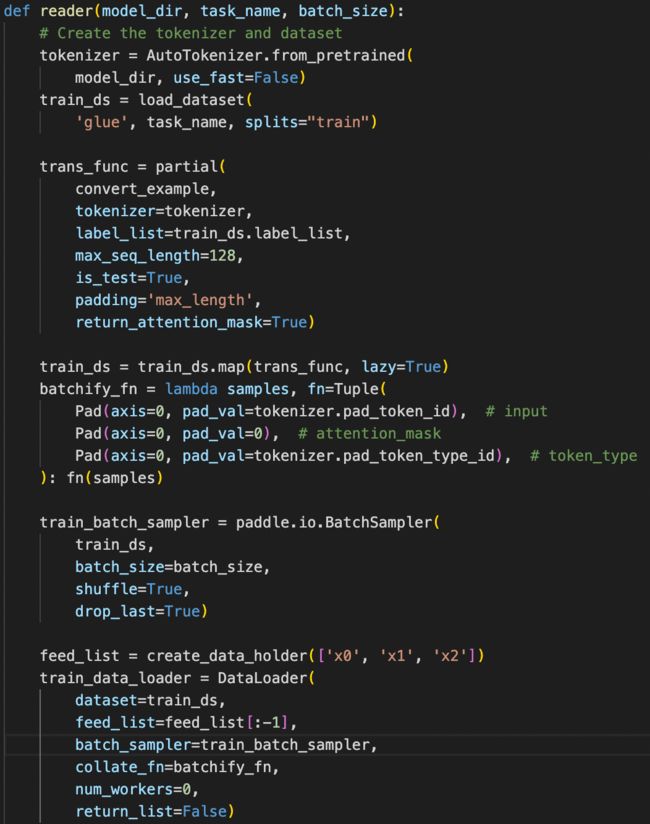
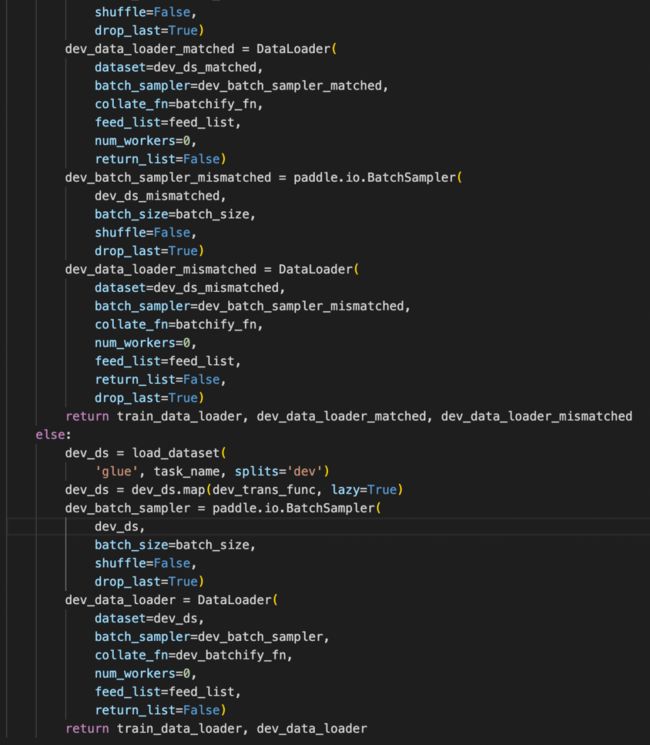
python export.py --weights yolov7-tiny.pt --grid2.准备训练数据&定义DataLoader:准备COCO或者VOC格式的数据。定义数据预处理模块。其中,数据预处理Reader的设置如下:
train_dataset = paddle.vision.datasets.ImageFolder(
global_config['image_path'], transform=yolo_image_preprocess)
train_loader = paddle.io.DataLoader(
train_dataset,
batch_size=1,
shuffle=True,
drop_last=True,
num_workers=0)3.定义配置文件:定义量化训练的配置文件,Distillation表示蒸馏参数配置,Quantization表示量化参数配置,TrainConfig表示训练时的训练轮数、优化器等设置。具体超参的设置可以参考ACT超参设置文档。
Distillation: # 蒸馏参数设置
alpha: 1.0 # 蒸馏loss所占权重
loss: soft_label
Quantization: # 量化参数设置
use_pact: true # 是否使用PACT量化算法
activation_quantize_type: 'moving_average_abs_max' # 激活量化方式,选择'moving_average_abs_max'即可
quantize_op_types: # 需要量化的OP类型,可以是conv2d、depthwise_conv2d、mul、matmul_v2等
- conv2d
- depthwise_conv2d
TrainConfig: # 训练的配置
train_iter: 3000 # 训练的轮数
eval_iter: 1000 # 训练中每次评估精度的间隔轮数
learning_rate: 0.00001 # 训练学习率
optimizer_builder: # 优化器设置
optimizer:
type: SGD
weight_decay: 4.0e-054.开始压缩:两行代码就可以开始ACT量化训练。启动ACT时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的eval_callback。
from paddleslim.auto_compression import AutoCompression
ac = AutoCompression(
model_dir=global_config["model_dir"],
model_filename=global_config["model_filename"],
params_filename=global_config["params_filename"],
save_dir=FLAGS.save_dir,
config=all_config,
train_dataloader=train_loader,
eval_callback=eval_function)
ac.compress()02
四步BERT自动压缩实战
1.准备预测模型
Paddle模型可跳过该步骤,直接进行压缩;PyTorch模型,使用以下两种任一方法,完成模型转换后,即可开始模型压缩工作。
使用PyTorch2Paddle(在X2Paddle工具箱中)直接将PyTorch动态图模型转为飞桨静态图模型;(以下代码使用该方法)
使用ONNX2Paddle将PyTorch动态图模型保存为ONNX格式后再转为飞桨静态图模型。
import torch
import numpy as np
# 将PyTorch模型设置为eval模式
torch_model.eval()
# 构建输入,
input_ids = torch.zeros([batch_size, max_length]).long()
token_type_ids = torch.zeros([batch_size, max_length]).long()
attention_msk = torch.zeros([batch_size, max_length]).long()
# 进行转换
from x2paddle.convert import pytorch2paddle
pytorch2paddle(torch_model,
save_dir='./x2paddle_cola/',
jit_type="trace",
input_examples=[input_ids, attention_msk, token_type_ids])2.准备训练数据&定义DataLoader。本案例默认以GLUE数据进行自动压缩实验,PaddleNLP会自动下载对应数据集。

3.定义配置文件。如果自动压缩针对Transformer encoder结构的模型没有指定具体的压缩策略的话,会自动选择结构化剪枝和量化进行压缩。如果想单独设置某一种压缩策略,可以参考的具体的超参设置ACT超参设置文档。
### 训练配置
train_config = {
"epochs": 3, ### 压缩训练epoch数量
"eval_iter": 855, ### 训练多少轮数进行一次测试
"learning_rate": 1.0e-6, ### 压缩训练过程中的学习率
"optimizer_builder": { ### 优化器配置
"optimizer": {"type": "AdamW"},
"weight_decay": 0.01 ### 权重衰减值
},
"origin_metric": 0.6006 ### 压缩前模型精度,用来确认转换过来的模型和实现的dataloader是否正确
}4.开始压缩。两行代码就可以开始ACT量化训练。启动ACT时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的eval_callback。
### 调用自动压缩接口
ac = AutoCompression(
model_dir='./x2paddle_cola',
model_filename='model.pdmodel',
params_filename='model.pdiparams',
save_dir=save_dir,
config={'TrainConfig': train_config}, #config,
train_dataloader=train_dataloader,
eval_callback=eval_function,
eval_dataloader=eval_dataloader)
ac.compress()以上是精简后的关键代码,如果想快速体验,可以根据
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_huggingface中的示例文档及代码进行体验。
训练完成后会在save_dir路径下产出model.pdmodel和model.pdiparams文件。至此,完成了模型训练压缩工作,推理部署参考下一节内容。
03
模型的推理部署
基于压缩训练后的模型,开发者可以直接使用FastDeploy推理部署套件完成部署落地。在使用FastDeploy部署时,开发者可以根据需要,使用一行代码切换Paddle Inference、Paddle Lite、TensorRT、OpenVINO、ONNX Runtime和RKNN等不同后端,来实现不同硬件的部署落地。
04
直播报名
想了解AI模型压缩策略,了解更多自动压缩工具的算法和能力,快快扫码加群关注我们的直播间吧!
直播时间: 2022年11月7日(下周一)和11月8日(下周二)20:30-21:30,欢迎大家扫码报名。

05
自动压缩技术解读
1
研发模型自动压缩工具的动机和思考
模型剪枝是模型压缩的重要手段,在实际使用中有如下2点困难:
1) 直接使用剪枝损失比较大,无法满足精度要求
结构化剪枝是裁剪掉网络中不重要的神经元。虽然剪枝后会重新训练,但通常比较难恢复预训练模型中的一些信息,导致剪枝后模型的精度下降。如果加上预训练数据进行重新训练,会大大增加剪枝的成本。
2) 模型剪枝需要修改训练代码,操作复杂,技术门槛高
结构化剪枝包括以下3步:
根据规则计算神经元的重要性;
根据重要性对模型神经元进行剪枝;
重新训练剪枝后的模型。
这些步骤需要开发者在原本的训练代码中直接调用剪枝的相关接口,并进行分步操作。通常项目工程相当复杂,修改训练代码技术复杂度高、时间成本高昂。
模型量化是提升模型推理速度的手段之一,实际使用中有如下3点困难:
1)模型激活值分布不均匀,导致量化误差大
过度训练是导致模型激活值分布不均匀的原因之一。例如在YOLOv6s迭代过程中,为了让模型更好地收敛,通常需要延长模型训练周期。但随之也会带来一些隐患,比如模型在COCO数据集上出现了过拟合,某些层的数值分布极端化,这些状况增加了量化的噪声。我们分析了YOLOv6s每层Conv的量化精度,发现某些层精度下降的特别严重,由此导致了YOLOv6s模型离线量化后在验证集上的精度下降了10%,无法达到业务要求。
2)任务复杂度高,模型精度受量化误差的影响大
任务复杂度越高,模型量化带来的精度损失越大。目标检测融合了目标定位和目标分类两种任务,整体的复杂度相对较高,因此它的精度受量化的影响更大。普通的离线量化无法改变模型激活值的数值分布,只会让量化scale适应该分布。遇到数值分布不均匀的激活值,离线量化的量化误差会很大。
3)量化训练需修改训练代码,复杂度高,技术门槛高
相比离线量化(Post Training Quantization),量化训练能减少离线量化精度掉点的程度。量化训练方法在训练过程中,不断地调整激活的数值分布,使激活的分布更适合量化。但是,量化训练使用成本比较高,体现在以下两方面,一方面是人力成本高,为了实现量化训练,需要修改模型的组网和训练代码,插入模拟量化操作。另一方面为时间成本高,训练时需要加载完整训练集做训练。
2
模型自动压缩工具-结构化剪枝和量化解析
ACT支持对NLP模型的压缩算法自动组合。ACT会对模型结构进行判断,如果是Transformer类型的模型的话,自动选择『结构化剪枝』和『量化』进行串行压缩。以上2个模块的具体技术解析如下:
1) 结构化剪枝技术包含以下4个步骤:
构造教师模型:加载推理模型,并且在内存中复制一份推理模型作为教师模型。
构造结构化剪枝模型:对原始模型的参数和注意力头进行重要性重排序,把重要参数和注意力头排在参数的前侧,然后对模型进行结构化剪枝,按照比例减掉不重要的参数和注意力头。结构化剪枝之后的模型作为学生模型,进行压缩训练。
添加蒸馏loss:自动分析模型结构,寻找最后一个包含有可训练参数的算子的输出作为蒸馏结点。
蒸馏训练:使用原始模型的输出,来监督结构化剪枝后模型的输出,进行结构化剪枝的训练,完成整体的压缩流程。
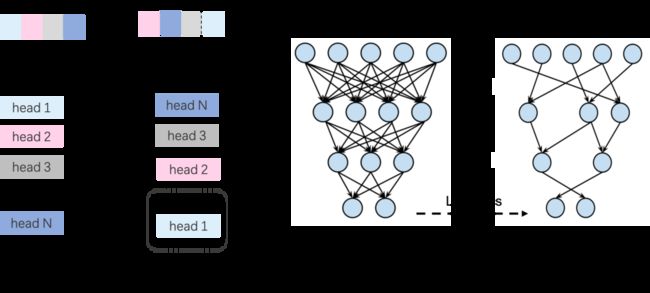
图 结构化剪枝+蒸馏实现剪枝操作
2) 量化技术:
量化策略自动选择:ACT包含离线量化和量化训练两种量化策略,在对NLP模型进行量化的时候会对量化策略进行自动选择。先运行少量离线量化,如果精度损失大,则转为使用蒸馏量化训练对模型进行量化压缩。如果精度损失小,则使用离线量化超参搜索进行量化。
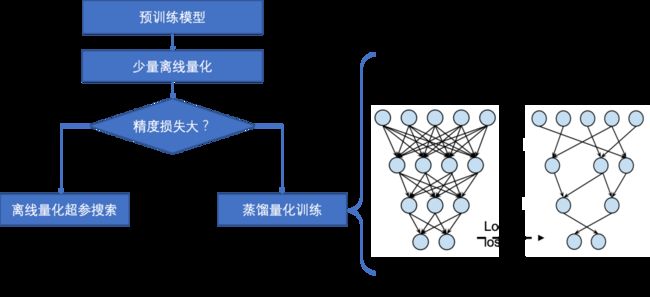
图 NLP模型中的量化策略
蒸馏量化训练具体步骤包括如下3步(CV任务多使用该技术):
a) 构造教师模型:加载推理模型文件,并将推理模型在内存中复制一份,作为知识蒸馏中的教师模型,原模型则作为学生模型。
b) 添加loss:自动地分析模型结构,寻找适合添加蒸馏loss的层,一般是最后一个带可训练参数的层。比如,检测模型head有多个分支的话,会将每个head最后一个conv作为蒸馏节点。
c) 蒸馏训练:教师模型通过蒸馏 loss 监督原模型的稀疏训练或量化训练,完成模型压缩的过程。
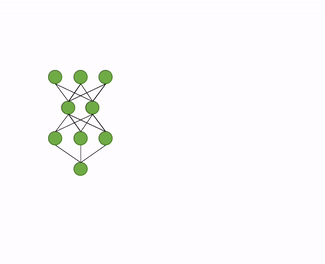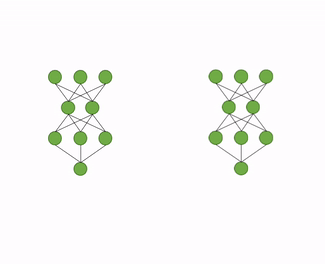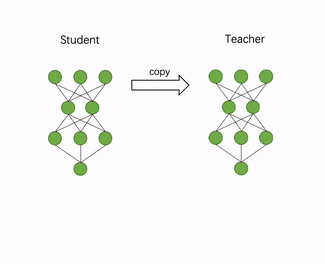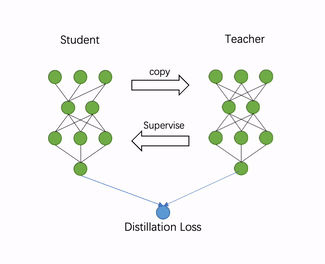
图 量化蒸馏训练技术动图
ACT还支持更多功能,包括离线量化超参搜索、算法自动组合和硬件感知等,来满足CV和NLP模型的各类压缩需求。功能详情以及ACT在更多场景的应用,请参见自动压缩工具首页介绍。
这么好的项目,欢迎大家点star鼓励并前来体验!
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
06
未来工作展望
ACT自动化压缩工具将支持更多AI模型(Transformer、FastSpeech2等)的自动化压缩。我们将继续升级ACT能力,进一步降低压缩后的精度损失,提升压缩效率,在更多场景下验证结构化剪枝、非结构化稀疏的功能,带来极致的压缩加速体验。ACT自动化压缩工具将支持完善更多的部署方法,包括Paddle Inference、Paddle Lite和ONNX Runtime等FastDeploy中的各种后端推理引擎,进一步助力AI模型的工程落地。
【表格指标说明】
测试环境与补充说明:表格中mAPval指模型对应论文中的指标,譬如YOLOv5是在COCO测试集测试,MobileNetV3是在Imagenet数据集上测试。
【更多精彩直播推荐】