文本摘要生成任务
Keras 文本摘要生成任务,前面部分是代码解析,后面部分是 原理讲解。
1.代码讲解
2.uniflm 原理讲解
3.beam search 原理讲解
1.代码讲解
首先安装bert4keras==0.2.0
!pip install bert4keras==0.2.0
引入所用的包
from tqdm import tqdm
import os, json, codecs
from bert4keras.bert import load_pretrained_model
from bert4keras.utils import SimpleTokenizer, load_vocab
from keras.layers import *
from keras import backend as K
from keras.callbacks import Callback
from keras.optimizers import Adam
import pandas as pd
设置参数
config_path = 'seq2seq_config.json'
min_count = 32
max_input_len = 450
max_output_len = 32
batch_size = 4
steps_per_epoch = 1000
epochs = 10000
简单查看一下数据集
df = pd.read_csv('data/train_tiny.csv')
df.head()

构造生成器
def read_text():
df = pd.read_csv('data/train_tiny.csv')
text = df['text'].values
summarization = df['summary'].values
for t, s in zip(text, summarization):
if len(s) <= max_output_len:
yield t[:max_input_len], s
简单查看一下生成器
f = read_text()
next(f)

重新构造词典,减小词典大小, 原词典太大,影响运行速度。
if os.path.exists(config_path):
chars = json.load(open(config_path, encoding='utf-8'))
else:
chars = {}
for a in tqdm(read_text(), desc='构建字表中'):
for b in a:
for w in b:
chars[w] = chars.get(w, 0) + 1
chars = [(i, j) for i, j in chars.items() if j >= min_count]
chars = sorted(chars, key=lambda c: - c[1])
chars = [c[0] for c in chars]
json.dump(
chars,
codecs.open(config_path, 'w', encoding='utf-8'),
indent=4,
ensure_ascii=False
)
导入bert model
config_path = 'chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = 'chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = 'chinese_L-12_H-768_A-12/vocab.txt'
重新构建分词器
# 读取词典
_token_dict = load_vocab(dict_path)
# keep_words是在bert中保留的字表
token_dict, keep_words = {}, []
for c in ['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[unused1]']:
token_dict[c] = len(token_dict)
keep_words.append(_token_dict[c])
for c in chars:
if c in _token_dict:
token_dict[c] = len(token_dict)
keep_words.append(_token_dict[c])
# 建立分词器
tokenizer = SimpleTokenizer(token_dict)
为每个batch 加上padding
def padding(x):
"""padding至batch内的最大长度
"""
ml = max([len(i) for i in x])
return np.array([i + [0] * (ml - len(i)) for i in x])
def data_generator():
while True:
X, S = [], []
for a, b in read_text():
# token的下标 segment embedding
x, s = tokenizer.encode(a, b)
X.append(x)
S.append(s)
if len(X) == batch_size:
X = padding(X)
S = padding(S)
yield [X, S], None
X, S = [], []
model = load_pretrained_model(
config_path,
checkpoint_path,
seq2seq=True,
keep_words=keep_words, # 只保留keep_words中的字,精简原字表
)
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:131: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:133: The name tf.placeholder_with_default is deprecated. Please use tf.compat.v1.placeholder_with_default instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
WARNING:tensorflow:From F:\nlp\7月\新建文件夹\项目1项目2\摘要\翻译、摘要4\code4 - 副本\bert4keras\bert.py:301: The name tf.matrix_band_part is deprecated. Please use tf.linalg.band_part instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:174: The name tf.get_default_session is deprecated. Please use tf.compat.v1.get_default_session instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:181: The name tf.ConfigProto is deprecated. Please use tf.compat.v1.ConfigProto instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:186: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:190: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:199: The name tf.is_variable_initialized is deprecated. Please use tf.compat.v1.is_variable_initialized instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:206: The name tf.variables_initializer is deprecated. Please use tf.compat.v1.variables_initializer instead.
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
Input-Token (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Input-Segment (InputLayer) (None, None) 0
__________________________________________________________________________________________________
Embedding-Token (Embedding) (None, None, 768) 2817024 Input-Token[0][0]
__________________________________________________________________________________________________
Embedding-Segment (Embedding) (None, None, 768) 1536 Input-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Token-Segment (Add) (None, None, 768) 0 Embedding-Token[0][0]
Embedding-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Position (PositionEmb (None, None, 768) 393216 Embedding-Token-Segment[0][0]
__________________________________________________________________________________________________
Embedding-Dropout (Dropout) (None, None, 768) 0 Embedding-Position[0][0]
__________________________________________________________________________________________________
Embedding-Norm (LayerNormalizat (None, None, 768) 1536 Embedding-Dropout[0][0]
__________________________________________________________________________________________________
Input-Mask (Lambda) (None, None) 0 Input-Token[0][0]
__________________________________________________________________________________________________
Attention-Mask (Lambda) (None, None, None) 0 Input-Segment[0][0]
__________________________________________________________________________________________________
Encoder-1-MultiHeadSelfAttentio (None, None, 768) 2362368 Embedding-Norm[0][0]
Embedding-Norm[0][0]
Embedding-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-1-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-1-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-1-MultiHeadSelfAttentio (None, None, 768) 0 Embedding-Norm[0][0]
Encoder-1-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-1-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-1-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-1-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-1-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-1-FeedForward-Dropout ( (None, None, 768) 0 Encoder-1-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-1-FeedForward-Add (Add) (None, None, 768) 0 Encoder-1-MultiHeadSelfAttention-
Encoder-1-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-1-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-1-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-2-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-1-FeedForward-Norm[0][0]
Encoder-1-FeedForward-Norm[0][0]
Encoder-1-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-2-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-2-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-2-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-1-FeedForward-Norm[0][0]
Encoder-2-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-2-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-2-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-2-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-2-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-2-FeedForward-Dropout ( (None, None, 768) 0 Encoder-2-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-2-FeedForward-Add (Add) (None, None, 768) 0 Encoder-2-MultiHeadSelfAttention-
Encoder-2-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-2-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-2-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-3-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-2-FeedForward-Norm[0][0]
Encoder-2-FeedForward-Norm[0][0]
Encoder-2-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-3-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-3-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-3-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-2-FeedForward-Norm[0][0]
Encoder-3-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-3-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-3-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-3-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-3-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-3-FeedForward-Dropout ( (None, None, 768) 0 Encoder-3-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-3-FeedForward-Add (Add) (None, None, 768) 0 Encoder-3-MultiHeadSelfAttention-
Encoder-3-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-3-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-3-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-4-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-3-FeedForward-Norm[0][0]
Encoder-3-FeedForward-Norm[0][0]
Encoder-3-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-4-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-4-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-4-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-3-FeedForward-Norm[0][0]
Encoder-4-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-4-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-4-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-4-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-4-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-4-FeedForward-Dropout ( (None, None, 768) 0 Encoder-4-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-4-FeedForward-Add (Add) (None, None, 768) 0 Encoder-4-MultiHeadSelfAttention-
Encoder-4-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-4-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-4-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-5-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-4-FeedForward-Norm[0][0]
Encoder-4-FeedForward-Norm[0][0]
Encoder-4-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-5-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-5-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-5-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-4-FeedForward-Norm[0][0]
Encoder-5-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-5-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-5-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-5-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-5-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-5-FeedForward-Dropout ( (None, None, 768) 0 Encoder-5-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-5-FeedForward-Add (Add) (None, None, 768) 0 Encoder-5-MultiHeadSelfAttention-
Encoder-5-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-5-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-5-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-6-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-5-FeedForward-Norm[0][0]
Encoder-5-FeedForward-Norm[0][0]
Encoder-5-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-6-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-6-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-6-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-5-FeedForward-Norm[0][0]
Encoder-6-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-6-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-6-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-6-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-6-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-6-FeedForward-Dropout ( (None, None, 768) 0 Encoder-6-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-6-FeedForward-Add (Add) (None, None, 768) 0 Encoder-6-MultiHeadSelfAttention-
Encoder-6-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-6-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-6-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-7-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-6-FeedForward-Norm[0][0]
Encoder-6-FeedForward-Norm[0][0]
Encoder-6-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-7-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-7-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-7-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-6-FeedForward-Norm[0][0]
Encoder-7-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-7-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-7-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-7-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-7-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-7-FeedForward-Dropout ( (None, None, 768) 0 Encoder-7-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-7-FeedForward-Add (Add) (None, None, 768) 0 Encoder-7-MultiHeadSelfAttention-
Encoder-7-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-7-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-7-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-8-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-7-FeedForward-Norm[0][0]
Encoder-7-FeedForward-Norm[0][0]
Encoder-7-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-8-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-8-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-8-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-7-FeedForward-Norm[0][0]
Encoder-8-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-8-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-8-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-8-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-8-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-8-FeedForward-Dropout ( (None, None, 768) 0 Encoder-8-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-8-FeedForward-Add (Add) (None, None, 768) 0 Encoder-8-MultiHeadSelfAttention-
Encoder-8-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-8-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-8-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-9-MultiHeadSelfAttentio (None, None, 768) 2362368 Encoder-8-FeedForward-Norm[0][0]
Encoder-8-FeedForward-Norm[0][0]
Encoder-8-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-9-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-9-MultiHeadSelfAttention[
__________________________________________________________________________________________________
Encoder-9-MultiHeadSelfAttentio (None, None, 768) 0 Encoder-8-FeedForward-Norm[0][0]
Encoder-9-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-9-MultiHeadSelfAttentio (None, None, 768) 1536 Encoder-9-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-9-FeedForward (FeedForw (None, None, 768) 4722432 Encoder-9-MultiHeadSelfAttention-
__________________________________________________________________________________________________
Encoder-9-FeedForward-Dropout ( (None, None, 768) 0 Encoder-9-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-9-FeedForward-Add (Add) (None, None, 768) 0 Encoder-9-MultiHeadSelfAttention-
Encoder-9-FeedForward-Dropout[0][
__________________________________________________________________________________________________
Encoder-9-FeedForward-Norm (Lay (None, None, 768) 1536 Encoder-9-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-10-MultiHeadSelfAttenti (None, None, 768) 2362368 Encoder-9-FeedForward-Norm[0][0]
Encoder-9-FeedForward-Norm[0][0]
Encoder-9-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-10-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-10-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-10-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-9-FeedForward-Norm[0][0]
Encoder-10-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-10-MultiHeadSelfAttenti (None, None, 768) 1536 Encoder-10-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-10-FeedForward (FeedFor (None, None, 768) 4722432 Encoder-10-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-10-FeedForward-Dropout (None, None, 768) 0 Encoder-10-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-10-FeedForward-Add (Add (None, None, 768) 0 Encoder-10-MultiHeadSelfAttention
Encoder-10-FeedForward-Dropout[0]
__________________________________________________________________________________________________
Encoder-10-FeedForward-Norm (La (None, None, 768) 1536 Encoder-10-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-11-MultiHeadSelfAttenti (None, None, 768) 2362368 Encoder-10-FeedForward-Norm[0][0]
Encoder-10-FeedForward-Norm[0][0]
Encoder-10-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-11-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-11-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-11-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-10-FeedForward-Norm[0][0]
Encoder-11-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-11-MultiHeadSelfAttenti (None, None, 768) 1536 Encoder-11-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-11-FeedForward (FeedFor (None, None, 768) 4722432 Encoder-11-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-11-FeedForward-Dropout (None, None, 768) 0 Encoder-11-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-11-FeedForward-Add (Add (None, None, 768) 0 Encoder-11-MultiHeadSelfAttention
Encoder-11-FeedForward-Dropout[0]
__________________________________________________________________________________________________
Encoder-11-FeedForward-Norm (La (None, None, 768) 1536 Encoder-11-FeedForward-Add[0][0]
__________________________________________________________________________________________________
Encoder-12-MultiHeadSelfAttenti (None, None, 768) 2362368 Encoder-11-FeedForward-Norm[0][0]
Encoder-11-FeedForward-Norm[0][0]
Encoder-11-FeedForward-Norm[0][0]
Input-Mask[0][0]
Attention-Mask[0][0]
__________________________________________________________________________________________________
Encoder-12-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-12-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-12-MultiHeadSelfAttenti (None, None, 768) 0 Encoder-11-FeedForward-Norm[0][0]
Encoder-12-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-12-MultiHeadSelfAttenti (None, None, 768) 1536 Encoder-12-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-12-FeedForward (FeedFor (None, None, 768) 4722432 Encoder-12-MultiHeadSelfAttention
__________________________________________________________________________________________________
Encoder-12-FeedForward-Dropout (None, None, 768) 0 Encoder-12-FeedForward[0][0]
__________________________________________________________________________________________________
Encoder-12-FeedForward-Add (Add (None, None, 768) 0 Encoder-12-MultiHeadSelfAttention
Encoder-12-FeedForward-Dropout[0]
__________________________________________________________________________________________________
Encoder-12-FeedForward-Norm (La (None, None, 768) 1536 Encoder-12-FeedForward-Add[0][0]
__________________________________________________________________________________________________
MLM-Dense (Dense) (None, None, 768) 590592 Encoder-12-FeedForward-Norm[0][0]
__________________________________________________________________________________________________
MLM-Norm (LayerNormalization) (None, None, 768) 1536 MLM-Dense[0][0]
__________________________________________________________________________________________________
MLM-Proba (EmbeddingDense) (None, None, 3668) 3668 MLM-Norm[0][0]
==================================================================================================
Total params: 88,863,572
Trainable params: 88,863,572
Non-trainable params: 0
__________________________________________________________________________________________________
# 交叉熵作为loss,并mask掉输入部分的预测
# 目标tokens
y_in = model.input[0][:, 1:]
y_mask = model.input[1][:, 1:]
# 预测tokens,预测与目标错开一位
y = model.output[:, :-1]
cross_entropy = K.sparse_categorical_crossentropy(y_in, y)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
model.add_loss(cross_entropy)
model.compile(optimizer=Adam(1e-5))
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\backend\tensorflow_backend.py:3341: The name tf.log is deprecated. Please use tf.math.log instead.
WARNING:tensorflow:From D:\Anaconda\envs\jianbo\lib\site-packages\keras\optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
用beam search 找到最优的句子
def generate_best_sentece(s, topk=2):
"""beam search解码
每次只保留topk个最优候选结果;如果topk=1,那么就是贪心搜索
"""
token_ids, segment_ids = tokenizer.encode(s[:max_input_len])
# 候选答案id
target_ids = [[] for _ in range(topk)]
# 候选答案分数
target_scores = [0] * topk
# 强制要求输出不超过max_output_len字
for i in range(max_output_len):
_target_ids = [token_ids + t for t in target_ids]
_segment_ids = [segment_ids + [1] * len(t) for t in target_ids]
# 直接忽略[PAD], [UNK], [CLS]
_probas = model.predict([_target_ids, _segment_ids])[:, -1, 3:]
# 取对数,方便计算
_log_probas = np.log(_probas + 1e-6)
# 每一项选出topk
_topk_arg = _log_probas.argsort(axis=1)[:, -topk:]
_candidate_ids, _candidate_scores = [], []
for j, (ids, sco) in enumerate(zip(target_ids, target_scores)):
# 预测第一个字的时候,输入的topk事实上都是同一个,
# 所以只需要看第一个,不需要遍历后面的。
if i == 0 and j > 0:
continue
for k in _topk_arg[j]:
_candidate_ids.append(ids + [k + 3])
_candidate_scores.append(sco + _log_probas[j][k])
_topk_arg = np.argsort(_candidate_scores)[-topk:]
for j, k in enumerate(_topk_arg):
target_ids[j].append(_candidate_ids[k][-1])
target_scores[j] = _candidate_scores[k]
ends = [j for j, k in enumerate(target_ids) if k[-1] == 3]
if len(ends) > 0:
k = np.argmax([target_scores[j] for j in ends])
return tokenizer.decode(target_ids[ends[k]])
# 如果max_output_len字都找不到结束符,直接返回
return tokenizer.decode(target_ids[np.argmax(target_scores)])
def show():
s1 = '今天湖南沅江市检察院对陆勇涉嫌“妨害信用卡管理“和”销售假药”案做出最终决定,认为其行为不构成犯罪,决定不起诉。陆勇因给千余网友分享购买仿制格列卫的印度抗癌药渠道被称“抗癌药代购第一人”,后被检方起诉。'
s2 = '在淘宝网上淘名牌服装、箱包的高仿品,很多消费者已经习以为常。日前,浙江省杭州市西湖区人民法院近日开庭审理了一起淘宝网上销售高仿箱包的案件,公诉方指控被告人施某涉嫌犯有销售假冒注册商标的商品罪>>>'
s3 = '根据国务院疫情风险等级查询客户端小程序显示,东城区天坛街道,海淀区永定路街道、青龙桥街道,朝阳区十八里店,大兴区庞各庄镇、黄村镇、大兴天宫院街道、观音寺街道,丰台南苑街道、卢沟桥乡、大红门街道,石景山八宝山街道,已上调为疫情中风险地区。'
for s in [s1, s2, s3]:
print('生成摘要:', generate_best_sentece(s))
print()
class Evaluate(Callback):
def __init__(self):
super().__init__()
self.lowest = 1e10
def on_epoch_end(self, epoch, logs=None):
# 保存最优
if logs['loss'] <= self.lowest:
self.lowest = logs['loss']
model.save_weights('./best_model3.weights')
# 演示效果
show()
model.fit_generator(
data_generator(),
steps_per_epoch=steps_per_epoch,
epochs=epochs,
callbacks=[evaluator]
)
测试一下模型生成的文本
show()
生成摘要: 湖南一网友代购抗癌药被购第一人被起诉
生成摘要: 网江海淘高仿箱包案指被告人涉嫌犯有假冒商标罪
生成摘要: 国务院疫情风险查询系户端查询
2.uniflm 原理讲解
Seq2Seq:
现在到我们的“重头戏”了:将Bert等Transformer架构跟Seq2Seq结合起来。为什么说重头戏呢?因为原则上来说,任何NLP问题都可以转化为Seq2Seq来做,它是一个真正意义上的万能模型。所以如果能够做到Seq2Seq,理论上就可以实现任意任务了。
将Bert与Seq2Seq结合的比较知名的工作有两个:MASS和UNILM,两者都是微软的工作,两者还都在同一个月发的~其中MASS还是普通的Seq2Seq架构,分别用Bert类似的Transformer模型来做encoder和decoder,它的主要贡献就是提供了一种Seq2Seq思想的预训练方案;真正有意思的是UNILM,它提供了一种很优雅的方式,能够让我们直接用单个Bert模型就可以做Seq2Seq任务,而不用区分encoder和decoder。而实现这一点几乎不费吹灰之力——只需要一个特别的Mask。
UNILM直接将Seq2Seq当成句子补全来做。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP]。经过这样转化之后,最简单的方案就是训练一个语言模型,然后输入“[CLS] 你 想 吃 啥 [SEP]”来逐字预测“白 切 鸡”,直到出现“[SEP]”为止,即如下面的左图:

不过左图只是最朴素的方案,它把“你想吃啥”也加入了预测范围了(导致它这部分的Attention是单向的,即对应部分的Mask矩阵是下三角),事实上这是不必要的,属于额外的约束。真正要预测的只是“白切鸡”这部分,所以我们可以把“你想吃啥”这部分的Mask去掉,得到上面的右图的Mask。
这样一来,输入部分的Attention是双向的,输出部分的Attention是单向,满足Seq2Seq的要求,而且没有额外约束。这便是UNILM里边提供的用单个Bert模型就可以完成Seq2Seq任务的思路,只要添加上述形状的Mask,而不需要修改模型架构,并且还可以直接沿用Bert的Masked Language Model预训练权重,收敛更快。这符合“一Bert在手,天下我有”的万用模型的初衷,个人认为这是非常优雅的方案。
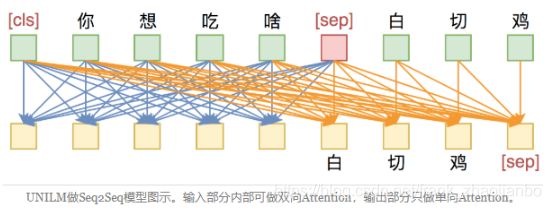
上述的这些Mask方案,已经被集成在bert4keras中,我们可以直接用bert4keras加载bert的预训练权重,并且调用上述Mask方案来做相应的任务。本项目就是一个利用UNILM的思路做一个快速收敛的Seq2Seq模型的例子。(参考资料:https://kexue.fm/archives/6933)
在bert4keras 源代码bert.py 文件中的 class Bert4Seq2seq 的compute_attention_mask就是实现上述Mask的方案
class Bert4Seq2seq(BertModel):
"""用来做seq2seq任务的Bert
"""
def __init__(self, *args, **kwargs):
super(Bert4Seq2seq, self).__init__(*args, **kwargs)
self.with_mlm = True
self.attention_mask = None
def compute_attention_mask(self, layer_id, segment_ids):
"""为seq2seq采用特定的attention mask
"""
if self.attention_mask is None:
def seq2seq_attention_mask(s):
# s表示的segment embedding 第一部分是0,第二部分是1[batch_size, seq_len]
# 序列长度
seq_len = K.shape(s)[1]
# [1, n_head, seq_len, seq_len]
ones = K.ones((1, self.num_attention_heads, seq_len, seq_len))
# 下三角矩阵 [1,n_head,seq_len,seq_len]
a_mask = tf.matrix_band_part(ones, -1, 0)
# [batch_size, seq_len] -> [batch_size, 1, 1, seq_len]
s_ex12 = K.expand_dims(K.expand_dims(s, 1), 2)
# [batch_size, seq_len] -> [batch_size, 1, seq_len, 1]
s_ex13 = K.expand_dims(K.expand_dims(s, 1), 3)
# [batch_size, 1, seq_len, seq_len]
a_mask = (1 - s_ex13) * (1 - s_ex12) + s_ex13 * a_mask
a_mask = K.reshape(a_mask, (-1, seq_len, seq_len))
return a_mask
self.attention_mask = Lambda(seq2seq_attention_mask,
name='Attention-Mask')(segment_ids)
return self.attention_mask
3.beam search 原理讲解
Beam search 算法在文本生成中用得比较多,用于选择较优的结果(可能并不是最优的)。接下来将以seq2seq机器翻译为例来说明这个Beam search的算法思想。
在机器翻译中,beam search算法在测试的时候用的,因为在训练过程中,每一个decoder的输出是有与之对应的正确答案做参照,也就不需要beam search去加大输出的准确率。
有如下从中文到英语的翻译:
中文:我 爱 学习,学习 使 我 快乐
英语:I love learning, learning makes me happy
在这个例子中,中文的词汇表是{我,爱,学习,使,快乐},长度为5。英语的词汇表是{I, love, learning, make, me, happy}(全部转化为小写),长度为6。那么首先使用seq2seq中的编码器对中文序列(记这个中文序列为XXX)进行编码,得到语义向量CCC。
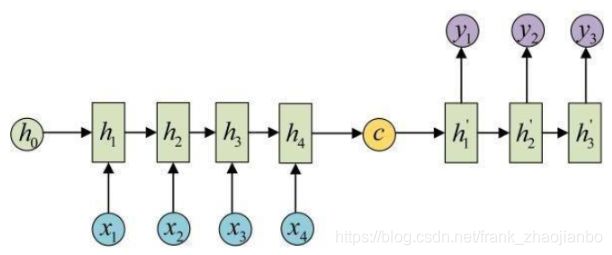
得到语义向量CCC后,进入解码阶段,依次翻译成目标语言。在正式解码之前,有一个参数需要设置,那就是beam search中的beam size,这个参数就相当于top-k中的k,选择前k个最有可能的结果。在本例中,我们选择beam size=3。
解码器的第一个输出y1,在给定语义向量C的情况下,首先选择英语词汇表中最有可能k个单词,也就是依次选择条件概率P(y1∣C)前3大对应的单词,比如这里概率最大的前三个单词依次是I,learning,happy。
接着生成第二个输出y2,在这个时候我们得到了那些东西呢,首先我们得到了编码阶段的语义向量C,还有第一个输出y1。此时有个问题,y1有三个,怎么作为这一时刻的输入呢(解码阶段需要将前一时刻的输出作为当前时刻的输入),答案就是都试下,具体做法是:
1.确定I为第一时刻的输出,将其作为第二时刻的输入,得到在已知(C,I)的条件下,各个单词作为该时刻输出的条件概率P(y2∣C,I),有6个组合,每个组合的概率为P(I∣C)P(y2∣C,I)。
2.确定learning为第一时刻的输出,将其作为第二时刻的输入,得到该条件下,词汇表中各个单词作为该时刻输出的条件概率P(y2∣C,learning),这里同样有6种组合;
3.确定happy为第一时刻的输出,将其作为第二时刻的输入,得到该条件下各个单词作为输出的条件概率P(y2∣C,happy),得到6种组合,概率的计算方式和前面一样。
这样就得到了18个组合,每一种组合对应一个概率值P(y1∣C)P(y2∣C,y1),接着在这18个组合中选择概率值top3的那三种组合,假设得到IloveI,Ihappy,learningmake。
接下来要做的重复这个过程,逐步生成单词,直到遇到结束标识符停止。最后得到概率最大的那个生成序列。其概率为:
![]()
以上就是Beam search算法的思想,当beam size=1时,就变成了贪心算法。
本项目的函数 generate_best_sentece 就是利用的beam search 原理选择最优的句子作为摘要
def generate_best_sentece(s, topk=2):
"""beam search解码
每次只保留topk个最优候选结果;如果topk=1,那么就是贪心搜索
"""
token_ids, segment_ids = tokenizer.encode(s[:max_input_len])
# 候选答案id
target_ids = [[] for _ in range(topk)]
# 候选答案分数
target_scores = [0] * topk
# 强制要求输出不超过max_output_len字
for i in range(max_output_len):
_target_ids = [token_ids + t for t in target_ids]
_segment_ids = [segment_ids + [1] * len(t) for t in target_ids]
# 直接忽略[PAD], [UNK], [CLS]
_probas = model.predict([_target_ids, _segment_ids])[:, -1, 3:]
# 取对数,方便计算
_log_probas = np.log(_probas + 1e-6)
# 每一项选出topk
_topk_arg = _log_probas.argsort(axis=1)[:, -topk:]
_candidate_ids, _candidate_scores = [], []
for j, (ids, sco) in enumerate(zip(target_ids, target_scores)):
# 预测第一个字的时候,输入的topk事实上都是同一个,
# 所以只需要看第一个,不需要遍历后面的。
if i == 0 and j > 0:
continue
for k in _topk_arg[j]:
_candidate_ids.append(ids + [k + 3])
_candidate_scores.append(sco + _log_probas[j][k])
_topk_arg = np.argsort(_candidate_scores)[-topk:]
for j, k in enumerate(_topk_arg):
target_ids[j].append(_candidate_ids[k][-1])
target_scores[j] = _candidate_scores[k]
ends = [j for j, k in enumerate(target_ids) if k[-1] == 3]
if len(ends) > 0:
k = np.argmax([target_scores[j] for j in ends])
return tokenizer.decode(target_ids[ends[k]])
# 如果max_output_len字都找不到结束符,直接返回
return tokenizer.decode(target_ids[np.argmax(target_scores)])
预测第一个字的时候,输入的topk事实上都是同一个,
# 所以只需要看第一个,不需要遍历后面的。
if i == 0 and j > 0:
continue
for k in _topk_arg[j]:
_candidate_ids.append(ids + [k + 3])
_candidate_scores.append(sco + _log_probas[j][k])
_topk_arg = np.argsort(_candidate_scores)[-topk:]
for j, k in enumerate(_topk_arg):
target_ids[j].append(_candidate_ids[k][-1])
target_scores[j] = _candidate_scores[k]
ends = [j for j, k in enumerate(target_ids) if k[-1] == 3]
if len(ends) > 0:
k = np.argmax([target_scores[j] for j in ends])
return tokenizer.decode(target_ids[ends[k]])
# 如果max_output_len字都找不到结束符,直接返回
return tokenizer.decode(target_ids[np.argmax(target_scores)])